







一、补充知识
Unicode编码转换为 utf-8 编码
把Unicode编码的u'xxx'转换为UTF-8编码的'xxx'可用encode('utf-8')方法:
>>> u'ABC'.encode('utf-8')
'ABC'
>>> u'中文'.encode('utf-8')
'\xe4\xb8\xad\xe6\x96\x87'
二、基础知识
电子邮件收发流程:

要编写程序来发送和接收邮件,本质上就是:
1)编写MUA把邮件发到MTA。使用的协议是SMTP:Simple Mail Transfer Protocol ;
2)编写MUA从MDA上收邮件。使用的协议有两种:POP:Post Office Protocol,目前版本是3,俗称POP3;IMAP:Internet Message Access Protocol,目前版本是4,优点是不但能取邮件,还可以直接操作MDA上存储的邮件,比如从收件箱移到垃圾箱,等等。
三、SMTP发邮件
值得注意的地方:
1)但凡含有中文必须用Header方法编码;
From: =?utf-8?b?UHl0aG9u54ix5aW96ICF?= <xxxxxx@163.com>
To: =?utf-8?b?566h55CG5ZGY?= <xxxxxx@qq.com>
Subject: =?utf-8?b?5p2l6IeqU01UUOeahOmXruWAmeKApuKApg==?=2)既包含中英文也包含地址的,要先用parseaddr(s)分离开中英文和地址,中英文用Header方法编码,地址直接用【补充知识】中的方法解码,然后用formataddr()方法把重新编码后的二者整合起来,作为MIMEText()的From、To 或 Subject (这三者都是MIMEText()的组成部分,不区分大小写(如from、to 、 subject也可以),但不能添加删改字母(如fromx就不可以,MIMEText()无法识别)).设置方法__setitem__
例1(无附件):
# -*- coding:utf-8 -*-
from email.utils import parseaddr, formataddr
from email.header import Header
def _format_addr(s): #s是Unicode编码
name,addr=parseaddr(s)
#解析地址,如从u'python爱好者<addr>'中分离为两个元素(是Unicode编码)组成的tuple:(u'python爱好者',u'addr')
#注意:addr一定要用<>括起来,否则无法识别和分离
return formataddr((Header(name,'utf-8').encode(),addr.encode('utf-8') if isinstance(addr,unicode) else addr))
#formataddr是parseaddr的逆运算
#如果包含中文必须需要通过Header对象进行编码(而不能直接用utf-8编码)
#name中有可能有中文,而addr中不可能有中文,故需要用parseaddr将二者分离,把前者Header编码,后者utf-8编码即可,再用formataddr把二者整合起来
#经过Header对象编码的文本,包含utf-8编码信息和Base64编码的文本
#输入Email地址和口令,用于验证是否是己方用户
from_addr=raw_input('input your addr:')
password=raw_input('password:')
#输入服务器地址:己方的服务器地址
smtp_addr=raw_input('SMTP server:')
#输入收件人地址
to_addr=raw_input('to:')
#email模块用于写信
from email.mime.text import MIMEText
msg=MIMEText('hello.send by python','plain','utf-8')
#对应的参数分别为:邮件正文、MIME的subtype、编码规范
msg['From']=_format_addr(u'python爱好者<%s>' %from_addr)
msg['To']=_format_addr(u'管理员<%s>' %to_addr)
msg['Subject']=Header(u'python写的邮件','utf-8').encode()
#有中文,且无需分离,故直接用Header编码即可
#smtplib模块用于发信
import smtplib
server=smtplib.SMTP(smtp_addr,25)#SMTP的默认端口是25
server.set_debuglevel(1)
server.login(from_addr,password)
server.sendmail(from_addr,[to_addr],msg.as_string())
#收信人可以多个,所以是个list,as_string()把MIMEText对象变成str
server.quit()
补充:什么叫maintype和subtype,如image就是maintype,而png,jpg,jpeg等就是subtype.
例2(有附件):
编码流程如下:

</pre><pre># -*- coding:utf-8 -*-
from email.utils import parseaddr, formataddr
from email.header import Header
def _format_addr(s):
name,addr=parseaddr(s)
return formataddr((Header(name,'utf-8').encode(),addr.encode('utf-8') if isinstance(addr,unicode) else addr))
#输入Email地址和口令,用于验证是否是己方用户
from_addr=raw_input('input your addr:')
password=raw_input('password:')
#输入服务器地址:己方的服务器地址
smtp_addr=raw_input('SMTP server:')
#输入收件人地址
to_addr=raw_input('to:')
#
#email模块用于写信
#
from email.mime.text import MIMEText
from email.mime.base import MIMEBase
from email.mime.multipart import MIMEMultipart
msg=MIMEMultipart()
msg['from']=_format_addr(u'python爱好者<%s>' %from_addr)
msg['to']=_format_addr(u'管理员<%s>' %to_addr)
msg['subject']=Header(u'python写的邮件','utf-8').encode()
#添加邮件正文(多个MIMEText不能同时存在,若同时存在,只有第一个有效,其他的作为附件出现)
msg.attach(MIMEText('你好', 'plain', 'utf-8'))
#对应的参数分别为:邮件正文、MIME的subtype、编码规范
#msg.attach(MIMEText('<html><body><h1>Hello</h1></body></html>', 'html', 'utf-8'))
#把图片添加到正文:【img src="cid:0"】呼应下文 mine.add_header('Content-ID', '<0>')
#通过改变cid:n中n的数值,可以添加多个图片到正文,当然Content-ID也要改
#msg.attach(MIMEText('<html><body><h1>Hello</h1><p><img src="cid:0"></p></body></html>', 'html', 'utf-8'))
from email import encoders
#添加附件
with open('test.txt','rb') as f:
mine=MIMEBase('text','txt',filename='test.txt')
# 加上必要的头信息:
mine.add_header('Content-Disposition', 'attachment', filename='test.txt')
mine.add_header('Content-ID', '<0>')
#把附件的内容读进来
mine.set_payload(f.read())
#用base64编码
encoders.encode_base64(mine)
#添加
msg.attach(mine)
#
#smtplib模块用于发信
#
import smtplib
server=smtplib.SMTP(smtp_addr,25)#SMTP的默认端口是25
server.set_debuglevel(1)
server.login(from_addr,password)
server.sendmail(from_addr,[to_addr],msg.as_string())
server.quit()
四、POP3收邮件
收取邮件就是编写一个MUA作为客户端,从MDA上把邮件获取到用户的电脑或者手机上。
SMTP发送的是经过编码后的一大段文本,与之类似的是,POP3协议收取的不是一个已经可以阅读的邮件本身,而是邮件的原始文本。
要把POP3收取的文本变成可以阅读的邮件,还需要用email模块提供的各种类来解析原始文本,变成可阅读的邮件对象。
所以,
发邮件分两步:1)用email编码邮件;2)用smtplib把编码邮件上传到MTA服务器。
收取邮件分两步:1)用poplib把邮件的原始文本下载到本地;2)用email解析原始文本,还原为邮件对象。
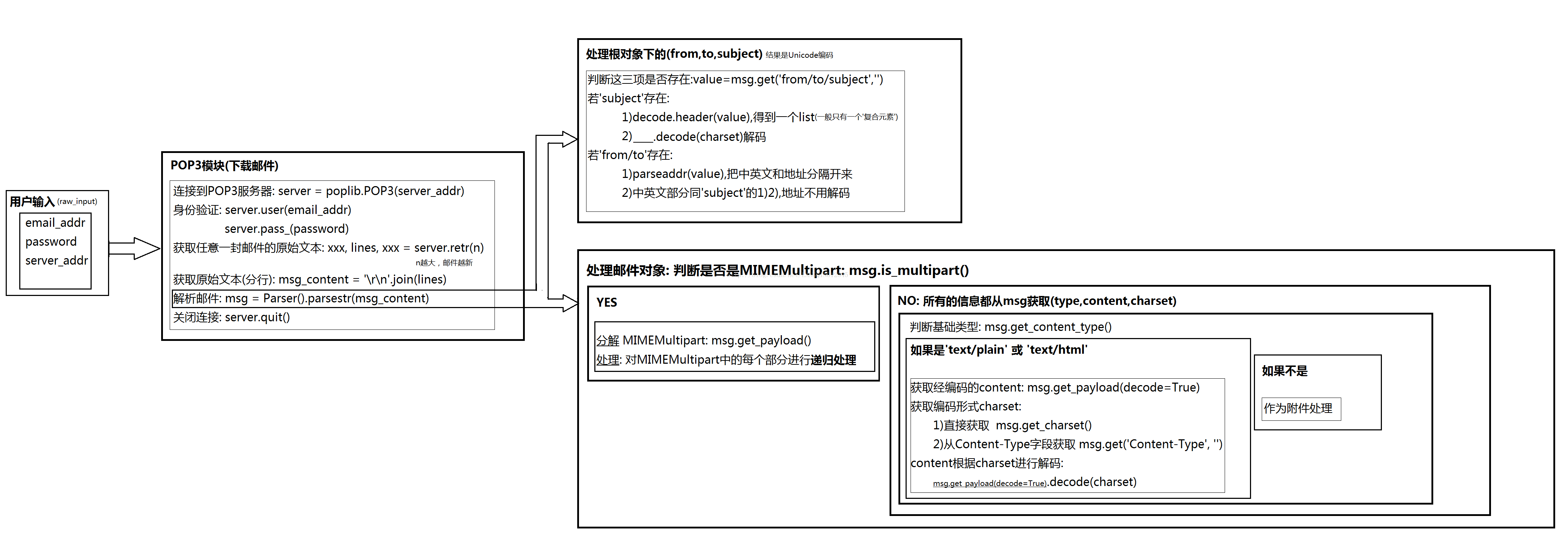
# -*- coding:utf-8 -*-
import poplib
# 输入邮件地址, 口令和POP3服务器地址:
email = raw_input('Email: ')
password = raw_input('Password: ')
pop3_server = raw_input('POP3 server: ')
# 连接到POP3服务器:
server = poplib.POP3(pop3_server)
# 身份认证:
server.user(email)
server.pass_(password)
resp, lines, octets = server.retr(14) #14表示邮件索引,数字越大,邮件越新
# lines存储了邮件的原始文本的每一行,可以获得整个邮件的原始文本:
msg_content = '\r\n'.join(lines) #分行
import email
from email.parser import Parser
from email.header import decode_header
from email.utils import parseaddr
# 解析邮件:
msg = Parser().parsestr(msg_content)
for n,part in enumerate(msg.get_payload()):
print '%s' %n
# 关闭连接:
server.quit()
要想解析邮件,先得弄清楚邮件的结构:
Message
+- MIMEBase
+- MIMENonMultipart
+- MIMEMultipart
+- MIMEMessage
+- MIMEText
+- MIMEImagemsg = Parser().parsestr(msg_content)
for n,part in enumerate(msg.get_payload()):
print '%s' %n而for n,part in enumerate(msg.get_payload()),如果msg是MIMEMultipart对象,msg.get_payload()可以把MIMEMultipart对象分解:n是MIMEMultipart子对象的编号(如SMTP例子中,MIMEText就是0号子对象,附件就是1号子对象,part 代表相应的object)
结果:

print '\n\n',msg.get('from', '')
print '\n\n',msg.get('to', '')
print '\n\n',msg.get('subject', '')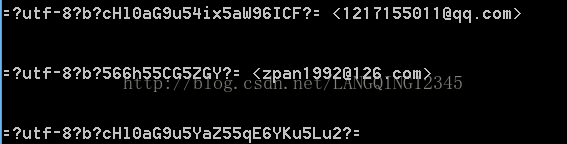
得到的结果恰好是在SMTP中header编码后的结果。当然如果没有某一项,自然也就没有get结果(如邮件没有subject这一项,那么msg.get('subject', '')的结果就为空!!!)
value1,value2=decode_header(msg.get('from', ''))
print value1,value2
value= decode_header(msg.get('subject', ''))
print value
显然,subject因为只有一项(没有内嵌地址项),所以得到只有一项的list,而from和to得到有两项的list。
如果再细分赋值,对于list中的每一项,前者是value,而后者是charset,即编码形式(如果编码形式是None,则无需经过decode()了,否则charset是什么,就要用什么来解码,即decode(charset))
拿decode_header(msg.get('from',‘’))为例,结果得到编码形式的utf-8编码(如上图),要想得到最初的文字形式(解码),还要把结果调用decode(),也就是说decode_header().decode()才是Header( ).encode() 完整的逆运算。经过这两步之后可以得到解码后(汉字形式)的utf-8结果。
当然对于内嵌地址项的from/to,还要用parseaddr分离开再分别解码。
最后补充一点:字符串与整数相乘相当于复制(任何字符串乘以整数0则得空字符串)——可用于分层打印(层次分明)

代码:
# -*- coding:utf-8 -*-
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
def guess_charset(msg):
# 先从msg对象获取编码,Return the Charset instance associated with the message’s payload.:
charset = msg.get_charset()
if charset is None:
# 如果获取不到,再从Content-Type字段获取:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8:].strip()
return charset
# indent用于缩进显示:
def print_info(msg, indent=0):
if indent == 0:
# 邮件的From, To, Subject存在于根对象上:
for header in ['from', 'to', 'subject']:
value = msg.get(header, '')
if value: #判断'from', 'to', 'subject'项目是否存在
if header=='Subject':
<span style="white-space:pre"> </span># 需要解码Subject字符串:
value = decode_str(value)
else:
<span style="white-space:pre"> </span># 需要解码Email地址:
hdr, addr = parseaddr(value)
name = decode_str(hdr)
value = u'%s <%s>' % (name, addr)
print('%s%s: %s' % (' ' * indent, header, value))
if (msg.is_multipart()):
# 如果邮件对象是一个MIMEMultipart,
# get_payload()返回list,包含所有的子对象:
for n, part in enumerate(msg.get_payload()):
print('%spart %s' % (' ' * indent, n))
print('%s--------------------' % (' ' * indent))
# 递归打印每一个子对象:
print_info(part, indent + 1)
else:
# 邮件对象不是一个MIMEMultipart,
# 就根据content_type判断:
content_type = msg.get_content_type()
if content_type=='text/plain' or content_type=='text/html':
# 获取经编码的内容:
content = msg.get_payload(decode=True)
#print content
#检测文本编码形式:
charset = guess_charset(msg)
if charset:
content = content.decode(charset)
print('%sText: %s' % (' ' * indent, content))
else:
# 不是文本,作为附件处理:
print('%sAttachment: %s' % (' ' * indent, content_type))
#
#
#下载邮件
#
#
import poplib
# 输入邮件地址, 口令和POP3服务器地址:
email = raw_input('Email: ')
password = raw_input('Password: ')
pop3_server = raw_input('POP3 server: ')
# 连接到POP3服务器:
server = poplib.POP3(pop3_server)
# 身份认证:
server.user(email)
server.pass_(password)
#获取内容
resp, lines, octets = server.retr(14)
# lines存储了邮件的原始文本的每一行,可以获得整个邮件的原始文本
msg_content = '\r\n'.join(lines)
#
#
#解析邮件
#
#
import email
from email.parser import Parser
from email.header import decode_header
from email.utils import parseaddr
# 解析邮件:
msg = Parser().parsestr(msg_content)
# 关闭连接:
server.quit()
if __name__=='__main__':
print_info(msg)













 7573
7573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









