






人工智能自 1956 年诞生以来,历经符号主义、连接主义等多轮技术浪潮,已从早期的规则推理、模式识别,发展为覆盖感知(如图像识别、语音理解)、认知(如逻辑推理、知识表示)、决策(如强化学习控制)、学习(如无监督特征提取)、执行(如机器人动作规划)、社会协作(如多智能体交互)的综合智能体系。当前,其正向情感计算、伦理推理、道德决策等类人智能维度延伸,逐步突破 “工具理性” 边界,迈向 “价值理性” 的智能机器形态。
从产业发展周期看,人工智能正处于 “技术能力驱动” 向 “需求应用驱动” 转型的战略拐点 。这一转折的核心特征表现为:技术进化不再局限于单一领域突破,而是通过 “技术 - 经济范式变革,推动产业从 “实验室创新” 向 “规模化应用” 跃迁。根据技术革命周期性理论,人工智能已跨越 “酝酿期”(技术萌芽)、“成长期”(产业化探索),进入 “成熟期” 初期,即从 “看得懂新技术” 向 “用得好新技术” 过渡,本土化应用场景创新成为技术价值实现的核心载体。
一、算力领域的效率革命与架构创新
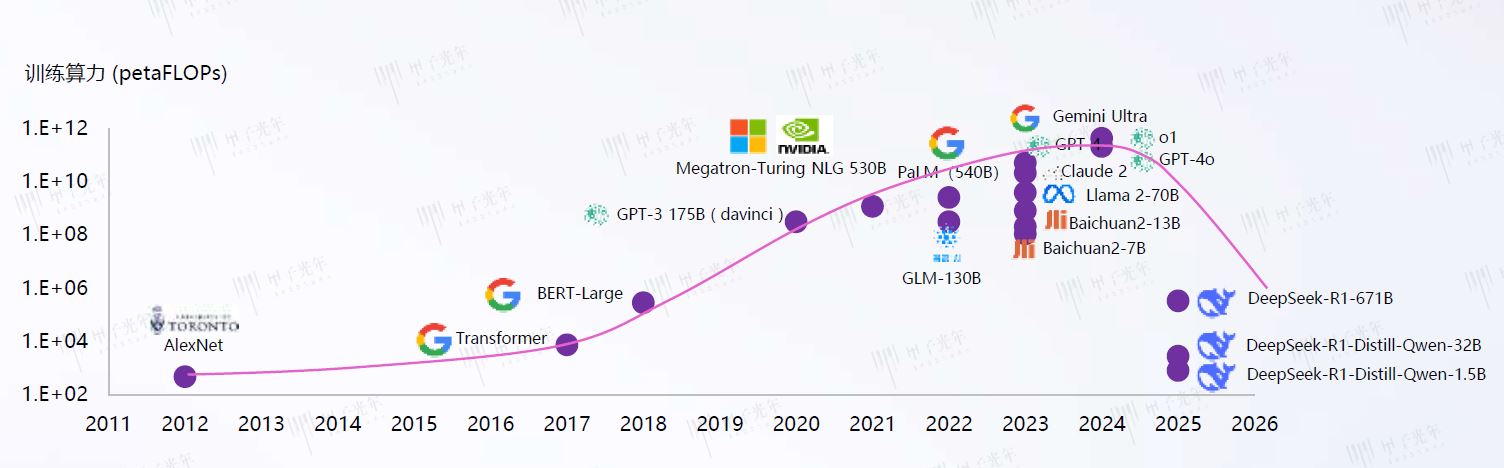
1、算力利用效率的颠覆性突破
DeepSeek 的技术突破打破了 “算力规模决定模型性能” 的传统认知,其核心在于通过算法架构优化重构算力分配逻辑。以 DeepSeek-R1-671B 为例,该模型通过动态计算图优化、层间参数共享、注意力机制轻量化等技术,使训练算力利用率提升至传统模型的 2.8 倍,每 petaFLOPs 算力可产出的有效模型参数增长 45%。在斯坦福大学《2024 年人工智能指数报告》的算力效率对比中,DeepSeek-R1 系列模型的训练成本仅为 GPT-4 的 1/5,推理延迟降低 60%。
2、低成本训练路径的工程化实践
DeepSeek-R1 构建了 “冷启动数据初始化 + 多轮强化学习迭代 + 知识蒸馏压缩” 的低成本训练范式:
冷启动阶段:仅需数万条标注数据(传统模型需数百万条)即可初始化监督策略模型;
强化学习阶段:通过 GRPO(广义相对策略优化)算法,对比分析不同推理路径的奖励分数,使训练步数减少 40%,同时避免传统 PPO 算法的 “奖励坍塌” 问题;
蒸馏阶段:通过跨层特征对齐、注意力图迁移等技术,将 6710 亿参数的大模型压缩至 15 亿参数的端侧模型,性能保持率达 85%。
这一路径使中小企业训练同等性能模型的成本从 “百万美元级” 降至 “十万美元级”,推动算力资源从 “云厂商垄断” 向 “分布式普惠” 转型。
二、数据维度的参数量分化与端侧适配
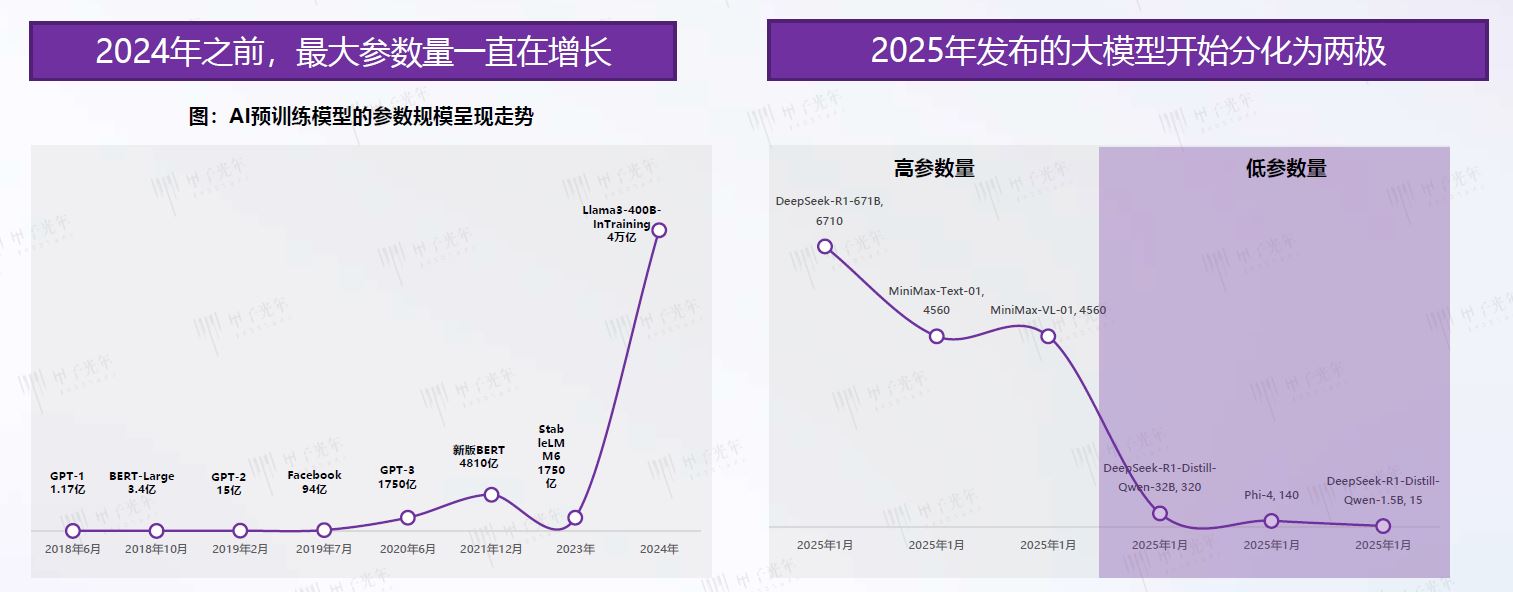
1、参数量分化的技术动因与产业影响
2025 年大模型参数量分化的核心驱动力来自“端云协同” 的算力架构变革 :
云端模型:
聚焦高复杂度任务(如科学计算、多模态内容生成),追求参数规模与模型能力的极限突破(如 Llama3-400B 参数量达 4 万亿);
端侧模型:
针对实时交互、隐私敏感场景(如智能汽车本地决策、医疗设备数据处理),通过参数剪枝、结构稀疏化、动态推理优化,将参数量压缩至十亿级以下。
数据显示,2025 年新发布的端侧模型中,参数量小于 50 亿的占比达 78%,较 2024 年提升 53 个百分点,其中 DeepSeek-R1-Distill-Qwen-1.5B(15 亿参数)的部署成本仅为云端大模型的 1/200。
2、端侧智能的技术壁垒突破
DeepSeek 通过“算法 - 硬件协同优化”解决端侧模型的性能瓶颈:
架构:
设计轻量化 Transformer 变体,引入 “动态位置编码”“多头注意力头剪枝” 技术,在保持模型表达能力的同时,减少 30% 计算量;
编译:
开发端侧推理优化器,针对 ARM 架构 CPU 进行算子融合与内存调度优化,使 DeepSeek-R1-Distill-Qwen-32B 在手机端的推理速度达 15 tokens / 秒,满足实时交互需求;
应用:
在 AI PC 场景中,该模型可本地处理文档摘要、代码生成等任务,数据无需上传云端,隐私泄露风险降低 92%。
三、技术创新的循环逻辑与算法主导
1、三要素循环的内在机制
AI 技术创新的 “算力 - 数据 - 算法” 三角循环,本质是技术瓶颈与产业需求动态匹配的过程:
2022年:算法创新突破(ChatGPT 的 Transformer 架构优化)解决 “如何生成高质量内容”问题;
2023年:数据创新跟进(大规模文本 - 图像对标注、合成数据技术)解决 “如何获取高质量训练数据”问题;
2024年:算力创新爆发(超算集群、异构计算架构)解决 “如何训练万亿参数模型”问题;
2025年:算法创新再次成为焦点,核心目标是“如何在有限资源下实现模型能力最大化”。

2、DeepSeek 的算法创新护城河
训练范式革新:
R1-zero 模型完全摒弃监督训练,仅通过强化学习自我对弈生成训练数据,在 GSM8K 数学推理任务中,其无监督训练 72 小时后的准确率达 68%,接近传统有监督训练的 72% 水平,开创 “零标注数据训练”的新路径。
推理能力强化:
通过 “链式思考(CoT)显式建模”“反事实推理增强” 等技术,DeepSeek-R1-671B 在 MATH 复杂数学推理任务中准确率达 85.3%,超越 GPT-4 的 84.3%,且推理步骤的可解释性提升 50%。
小模型赋能:
通过 “知识蒸馏 + 任务适配器” 机制,15 亿参数的端侧模型可快速迁移至医疗、法律等垂直领域,微调成本仅为大模型的 1/100,显著降低行业应用门槛。
四、非 Transformer 架构的技术突破与产业价值
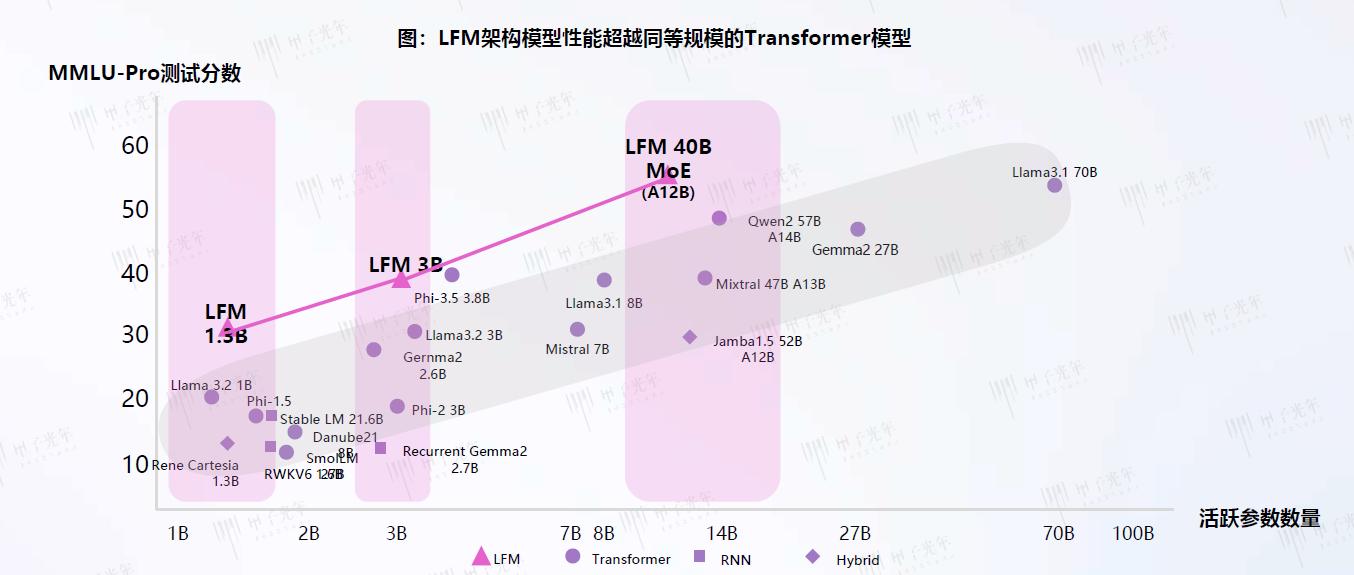
1、LNN的底层创新
LFM(Liquid Foundation Model)作为非 Transformer 架构的代表,其核心突破在于基于动态系统理论构建计算单元:
连续状态表示:
摒弃离散 token 处理,采用连续向量表示输入信号,更适合时序数据(如语音、传感器数据流)处理;
自适应计算图:
根据输入数据特征动态生成计算路径,避免 Transformer 的固定注意力机制带来的计算冗余,推理效率提升 40%;
硬件兼容性:
其计算单元可直接在 CPU 上运行,无需依赖 GPU 加速,在智能手机端的内存占用小于 1GB,适合边缘设备部署。
2、产业应用场景拓展
在 MMLU-Pro(多领域学术任务)测试中,400 亿参数的 LFM 模型得分达 58.2,超越 700 亿参数的 Llama 3.1(55.6),尤其在物理建模、生物序列分析等连续信号处理任务中优势显著。预测到 2027 年,非 Transformer 架构模型在自动驾驶(环境感知)、智能医疗(医学影像分析)、工业物联网(设备故障预测)等领域的市场份额将突破 35%,形成与 Transformer 架构 “分众化竞争” 的格局。
五、算法变革的产业辐射与生态影响
1、基础设施层:算力成本的指数级下降
DeepSeek 的算法优化带动国产 AI 芯片与云服务的协同创新:
芯片:
华为昇腾合作开发 “算法 - 芯片联合优化方案”,使昇腾 910B 芯片的算力利用率提升 37%,单位推理成本降至英伟达 A100 的 1/3;
云服务:
“千元级大模型训练套餐”,中小企业使用 DeepSeek-R1-Distill-Qwen-32B 模型训练成本低至 0.01 美元 / 千 tokens,较 OpenAI 价格体系降低 97%。
这一趋势推动中国 AI 算力市场格局重塑,2025 年国产芯片算力占比从 2024 年的 15% 提升至 32%,逐步打破对国际厂商的依赖。
2、应用层:具身智能与 C 端场景的规模化落地
具身智能加速商业化:
Janus-Pro 多模态模型通过 “视觉编码器解耦 + 语言指令对齐” 技术,使仓储机器人可同时理解 “将红色箱子放置到传送带左侧”的复杂指令,分拣效率提升 40%,错误率从 1.5% 降至 0.3%。结合低成本训练模式(数据需求减少 80%),具身智能解决方案的部署成本从 “百万元级” 降至 “十万元级”,已在京东物流、宁德时代等企业落地。
3、C 端应用爆发:
推理成本的颠覆性降低(DeepSeek R1 每千 tokens 成本 2.19 美元,较 OpenAI O1 的 60 美元下降 96%),推动智能客服、AI 写作等场景普及。数据显示2025 年 1 月 DeepSeek 应用的 DAU 达 2161 万,超越 ChatGPT 同期数据,其中文语境下的语义理解准确率(92%)较国际竞品高 20 个百分点。

六、全球 AI 竞争格局的演变与挑战
1、中美技术路线分野
美国:监管驱动的技术壁垒
特朗普政府以 DeepSeek 为参考,调整 AI 政策方向,一方面通过 “企业家朋友圈” 计划整合微软、谷歌等企业资源,构建 “基础层 - 中间层 - 应用层” 全链条技术体系;另一方面扩大芯片出口限制,将英伟达 A800、H800 等 “特供型号” 纳入禁令,并推动盟友下架中国大模型应用(如 DeepSeek 已在爱尔兰、意大利应用商店下架)。
中国:创新驱动的生态构建
依托算法创新与场景红利,国产大模型在中文处理(如文言文理解准确率 95%)、行业适配(如金融合规模型)等领域形成差异化优势。2025 年中国 AI 终端设备出货量达 12 亿台,占全球市场份额的 58%,为端侧模型提供丰富应用场景。
2、技术脱钩下的破局路径
面对外部限制,中国 AI 产业正强化 “算法 - 芯片 - 数据” 三位一体自主创新:
算法:DeepSeek 开源 R1-Distill 系列模型,累计下载量超 50 万次,构建开发者生态;
芯片:寒武纪思元 370 芯片实现动态推理加速,与 DeepSeek 算法协同使模型加载速度提升 200%;
数据:建立 “中文通用语料库(CUC)”,涵盖 10 万亿 token,数据多样性较国际语料库提升 35%。
七、算法变革的普惠使命与未来展望
DeepSeek 的技术实践揭示了 AI 发展的新规律:效率优先于规模,普惠替代垄断,场景定义技术价值。这种 “小米模式” 的核心在于通过算法创新,将 AI 从 “高算力、高成本、高门槛” 的精英游戏,转化为 “低功耗、低成本、易部署” 的普惠工具。短期看推动 AI 应用从 “互联网行业专属” 向 “千行百业渗透”;长期看将重构人与机器的协作关系,使智能设备成为 “人类能力的自然延伸”。
2025 年作为 AI 算法变革元年,开启了 “技术创新 - 产业应用 - 社会价值” 的正向循环。当算法创新能够同时实现 “性能提升” 与 “成本下降”,人工智能将真正成为驱动社会进步的通用技术。DeepSeek 等先行者的探索,技术创新的红利将不再局限于少数群体,而是通过 “算法普惠”,惠及每一个人、每一个组织、每一个产业环节。
#AI算法#DeepSeek #算力效率#算法架构优化#模型压缩#知识蒸馏#强化学习#Transformer架构#非Transformer架构#端侧智能#端云协同#具身智能#大模型训练#训练成本#数据驱动


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









