






背景
随着电子邮件的广泛应用,恶意邮件(如钓鱼邮件、勒索软件、垃圾邮件等)已成为网络安全的主要威胁之一。攻击者通过伪装成合法发件人、植入恶意附件或嵌入恶意链接,诱导用户泄露敏感信息或执行恶意代码。根据 2023年 Verizon 数据泄露调查报告,36% 的数据泄露事件涉及钓鱼邮件,而企业每年因恶意邮件导致的经济损失高达数十亿美元。
传统的恶意邮件检测方法(如基于黑名单、关键词过滤、简单启发式规则)已难以应对日益复杂的攻击手段。现代恶意邮件常采用 社交工程(Social Engineering)、动态链接(URL重定向) 和 零日漏洞利用 等技术,绕过静态检测机制。因此,需要结合机器学习(ML)的技术,构建更智能的恶意邮件识别系统。
主要思想
使用Python语言,结合Numpy、Pandas、NLTK和Scikit-learn等常用数据科学和自然语言处理工具,旨在构建一个垃圾邮件分类器。通过正则表达式和NLTK库对邮件文本进行清理和预处理,包括移除HTML标签、非字母字符、停用词,并进行词干化。然后,利用TfidfVectorizer将文本转换为数值特征向量,采用朴素贝叶斯分类器(MultinomialNB)进行训练和评估。最终,模型和特征提取器通过joblib保存,方便后续应用。整个过程展示了文本数据处理、特征提取、模型训练和评估的完整流程,目标是有效地分类垃圾邮件。
具体代码
(1)下载数据集
-
来源:Enron 公司公开的邮件数据,包含正常邮件(Ham)和垃圾邮件(Spam)。
-
下载方式:Enron Email Dataset
(2) 加载邮件数据
def load_emails(directory):
emails = []
for filename in os.listdir(directory):
path = os.path.join(directory, filename)
with open(path, 'rb') as f:
# 解析邮件原始内容
msg = email.message_from_binary_file(f, policy=policy.default)
text = ""
if msg.is_multipart():
for part in msg.walk():
if part.get_content_type() == 'text/plain':
text += part.get_payload(decode=True).decode('utf-8', errors='ignore')
else:
text = msg.get_payload(decode=True).decode('utf-8', errors='ignore')
emails.append(text)
return emails(3)文本预处理
def preprocess_text(text):
# 移除HTML标签
text = re.sub(r'<[^>]+>', '', text)
# 移除非字母字符
text = re.sub(r'[^a-zA-Z]', ' ', text)
# 转换为小写并分词
words = text.lower().split()
# 移除停用词并词干化
words = [stemmer.stem(word) for word in words if word not in stop_words]
return ' '.join(words)(4)整体代码
import os
import email
import re
from email import policy
import numpy as np
import joblib
import pandas as pd
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.naive_bayes import MultinomialNB
from sklearn.utils import compute_class_weight
def load_emails(directory):
emails = []
for filename in os.listdir(directory):
path = os.path.join(directory, filename)
with open(path, 'rb') as f:
# 解析邮件原始内容
msg = email.message_from_binary_file(f, policy=policy.default)
text = ""
if msg.is_multipart():
for part in msg.walk():
if part.get_content_type() == 'text/plain':
text += part.get_payload(decode=True).decode('utf-8', errors='ignore')
else:
text = msg.get_payload(decode=True).decode('utf-8', errors='ignore')
emails.append(text)
return emails
def preprocess_text(text):
# 移除HTML标签
text = re.sub(r'<[^>]+>', '', text)
# 移除非字母字符
text = re.sub(r'[^a-zA-Z]', ' ', text)
# 转换为小写并分词
words = text.lower().split()
# 移除停用词并词干化
words = [stemmer.stem(word) for word in words if word not in stop_words]
return ' '.join(words)
# 加载数据
easy_ham = load_emails("20030228_easy_ham/easy_ham")
spam = load_emails("20030228_spam/spam")
nltk.download('stopwords')
stemmer = PorterStemmer()
stop_words = set(stopwords.words('english'))
easy_ham_clean = [preprocess_text(email) for email in easy_ham]
spam_clean = [preprocess_text(email) for email in spam]
# 创建DataFrame
df_ham = pd.DataFrame({"text": easy_ham_clean, "label": 0}) # 0=正常邮件
df_spam = pd.DataFrame({"text": spam_clean, "label": 1}) # 1=垃圾邮件
data = pd.concat([df_ham, df_spam], ignore_index=True)
# print(data)
# 数据预处理
# 文本特征提取(TF-IDF)
vectorizer = TfidfVectorizer(stop_words='english', max_features=5000)
X = vectorizer.fit_transform(data['text'])
y = data['label']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = MultinomialNB(alpha=0.1)
model.fit(X_train, y_train)
# 保存模型
joblib.dump(model, 'spam_classifier.pkl')
joblib.dump(vectorizer, 'tfidf_vectorizer.pkl')
模型评估
(1)使用交叉验证评估模型
scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')
# 输出每次折叠的评分和平均评分
print("每次折叠的准确率:", scores)
print("平均准确率:", scores.mean())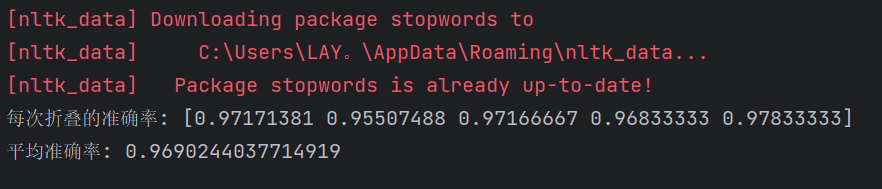
(2)单次训练评估模型
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))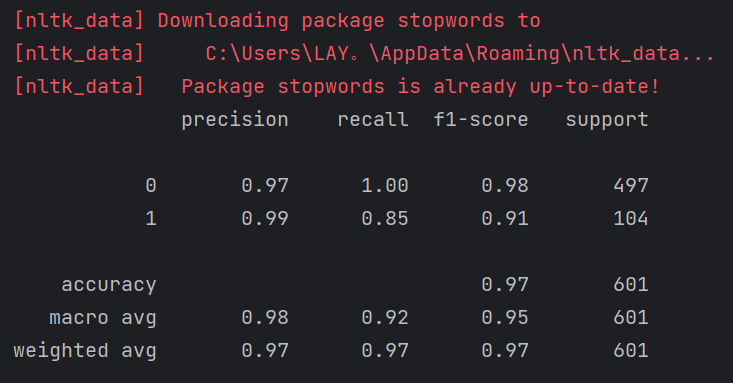
(3)模型调参
params = {'alpha': [0.1, 1.0, 0.01]} # 朴素贝叶斯的平滑参数
grid = GridSearchCV(MultinomialNB(), params, cv=5)
grid.fit(X_train, y_train)
print("最佳参数:", grid.best_params_)结果分析
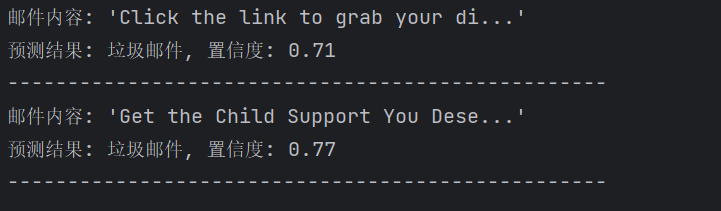
根据结果,置信度值在0.7-0.8之间,说明模型的预测存在一定的不确定性。为改进识别准确性,可以从多个方面入手。首先,确保获取完整的邮件内容,避免截断,以便模型可以更好地分析文本。其次,考虑使用多种特征(如发件人信息、发送时间、附件等)进行判断,提升模型的鲁棒性。同时,优化模型的置信度阈值,调整分类标准,以减少误判。定期更新垃圾邮件数据集并结合不同的机器学习方法,也能显著提升分类效果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









