







reference:http://blog.csdn.NET/marising/article/details/6543943
在信息检索、分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常重要,因此最近根据网友的博客做了一个汇总。
准确率、召回率、F1
信息检索、分类、识别、翻译等领域两个最基本指标是召回率(Recall Rate)和准确率(Precision Rate),召回率也叫查全率,准确率也叫查准率,概念公式:
召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数
图示表示如下:
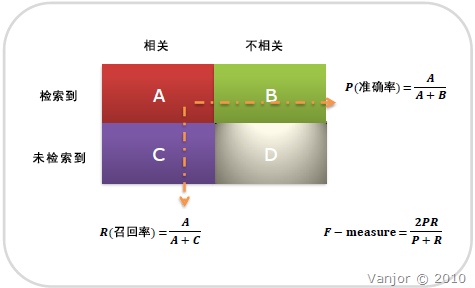
注意:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。一般情况,用不同的阀值,统计出一组不同阀值下的精确率和召回率,如下图:
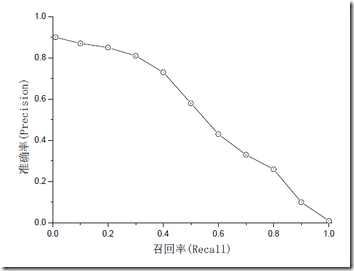
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。
所以,在两者都要求高的情况下,可以用F1来衡量。
- F1 = 2 * P * R / (P + R)
公式基本上就是这样,但是如何算图1中的A、B、C、D呢?这需要人工标注,人工标注数据需要较多时间且枯燥,如果仅仅是做实验可以用用现成的语料。当然,还有一个办法,找个一个比较成熟的算法作为基准,用该算法的结果作为样本来进行比照,这个方法也有点问题,如果有现成的很好的算法,就不用再研究了。
AP和mAP(mean Average Precision)
mAP是为解决P,R,F-measure的单点值局限性的。为了得到 一个能够反映全局性能的指标,可以看考察下图,其中两条曲线(方块点与圆点)分布对应了两个检索系统的准确率-召回率曲线
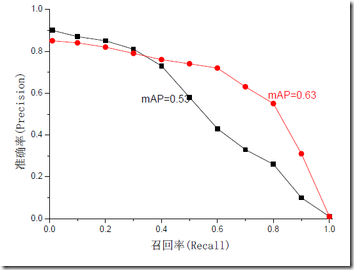
可以看出,虽然两个系统的性能曲线有所交叠但是以圆点标示的系统的性能在绝大多数情况下要远好于用方块标示的系统。
从中我们可以 发现一点,如果一个系统的性能较好,其曲线应当尽可能的向上突出。
更加具体的,曲线与坐标轴之间的面积应当越大。
最理想的系统, 其包含的面积应当是1,而所有系统的包含的面积都应当大于0。这就是用以评价信息检索系统的最常用性能指标,平均准确率mAP其规范的定义如下:(其中P,R分别为准确率与召回率)
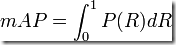 即map实质上指的是pr曲线下的围成的面积大小
即map实质上指的是pr曲线下的围成的面积大小
PR曲线指的是Precision Recall曲线,翻译为中文为查准率-查全率曲线。PR曲线在分类、检索等领域有着广泛的使用,来表现分类/检索的性能。
例如,要从一个样本S中分出标签为L的样本,假设样本S中标签确实为L的集合为SL,分类器将样本标签分为L的集合为SLC,SLC中标签确实为L的集合为SLCR。那么,
查准率(Precision Ratio)= SLCR/SLC
查全率(Recall Ratio)= SLCR/SL
如果是分类器的话,通过调整分类阈值,可以得到不同的P-R值,从而可以得到一条曲线(纵坐标为P,横坐标为R)。通常随着分类阈值从大到小变化(大于阈值认为标签为L),查准率减小,查全率增加。比较两个分类器好坏时,显然是查得又准又全的比较好,也就是的PR曲线越往坐标(1,1)的位置靠近越好。
按此顺序逐个把样本作为整理进行预测,则每次可以计算
出当前的查全率、查准率,以P(查准率)为纵轴,R(查全率)为横轴作图,就得到了P-R曲线P-R图直观的显
示出学习器在样本总体上的查全率、查准率,在进行比较时,若一个学习器的P-R曲线被另一个完全包住,则可
断言后者优于前者,如图1,A优于C;如果两个学习器的P-R曲线发生了交叉,如A和B,则难以一般性的断言两
者孰优孰劣,只能在具体的P或R条件下进行比较。然而,在很多情形下,人们往往仍希望把学习器A和B比个高低,
这时一个比较合理的判断依据是比较曲线下面积的大小,它在一定程度上表征了学习器在P和R上取得相对“双高”
的比例,但这个值不太容易估算,因此人们设计了一些综合考虑P和R的度量。
平衡点(BEP)就是这样一个度量,是P=R时的取值,基于BEP,可任务A优于B。
以召回率(真正率)为y轴,以特异性(假正率)为x轴,我们就直接得到了RoC曲线。从召回率和特异性的定
义可以理解,召回率越高,特异性越小,我们的模型和算法就越高效。也就是画出来的RoC曲线越靠近左上越
好。如下图左图所示。从几何的角度讲,RoC曲线下方的面积越大越大,则模型越优。所以有时候我们用RoC
曲线下的面积,即AUC(Area Under Curve)值来作为算法和模型好坏的标准。

图1 P-R曲线

图2 ROC曲线
ROC和AUC
ROC和AUC是评价分类器的指标,上面第一个图的ABCD仍然使用,只是需要稍微变换。
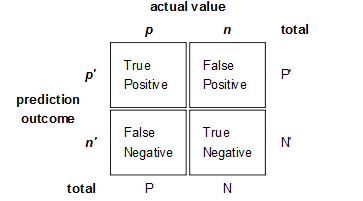
回到ROC上来,ROC的全名叫做Receiver Operating Characteristic。
ROC关注两个指标
True Positive Rate ( TPR ) = TP / [ TP + FN] ,TPR代表能将正例分对的概率
False Positive Rate( FPR ) = FP / [ FP + TN] ,FPR代表将负例错分为正例的概率
在ROC 空间中,每个点的横坐标是FPR,纵坐标是TPR,这也就描绘了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off。ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve。我们知道,对于二值分类问题,实例的值往往是连续值,我们通过设定一个阈值,将实例分类到正类或者负类(比如大于阈值划分为正类)。因此我们可以变化阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC curve经过(0,0)(1,1),实际上(0, 0)和(1, 1)连线形成的ROC curve实际上代表的是一个随机分类器。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。如图所示。

用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。
于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的Performance。
AUC计算工具:
http://mark.goadrich.com/programs/AUC/
P/R和ROC是两个不同的评价指标和计算方式,一般情况下,检索用前者,分类、识别等用后者。
参考链接:
http://www.vanjor.org/blog/2010/11/recall-precision/
http://bubblexc.com/y2011/148/
http://wenku.baidu.com/view/ef91f011cc7931b765ce15ec.html
http://blog.csdn.net/wangran51/article/details/7579100
http://blog.csdn.NET/shaoxiaohu1/article/details/8998515
最近一直在做相关推荐方面的研究与应用工作,召回率与准确率这两个概念偶尔会遇到,
知道意思,但是有时候要很清晰地向同学介绍则有点转不过弯来。

召回率和准确率是数据挖掘中预测、互联网中的搜索引擎等经常涉及的两个概念和指标。
召回率: Recall,又称“查全率”——还是查全率 好记,也更能体现其实质意义。
准确率: Precision,又称“精度” 、“正确率”。
以检索为例,可以把搜索情况用下图表示:
|
相关
|
不相关
| |
|
检索到
|
A(tp)
|
B(fp)
|
|
未检索到
|
C(tn)
|
D(fn)
|
Ture/False: 想要的/不想要的
Positive / Negative: 检索到 /未检索到
A:检索到的,相关的 (搜到的也想要的) - True Positive
B:检索到的,但是不相关的 (搜到的但没用的)False Positive
C:未检索到的,但却是相关的 (没搜到,然而实际上想要的)True Negative
D:未检索到的,也不相关的 (没搜到也没用的)False Negative
如果我们希望:被检索到的内容越多越好,
即 真正搜到的 / 真正搜到的也是想要的 以及 没有搜到的也是想要的 的总数
真正检索到占总groudtruth的数目(true positive / true positive+true negative [ground truth num] )
这是追求“查全率”(tp/tp+tn) Recall,即A/(A+C),越大越好。
举个例子: 如衣服检索中,我们在全部图片数据库中每张图片的groud truth总数加起来就是 tp+tn
然后我们的模型正确检索到的数据 就是tp 查全率就是 tp/tp+tn
如果我们希望:检索到的文档中,真正想要的、也就是相关的越多越好,不相关的越少越好,
即 真正搜到的 / 真正搜到的也是想要的 以及 真正搜到但是不想要 的总数->
真正检索到占总检索到的数目 (true positive / true positive+false positive [ground truth num] )
这是追求“准确率”(tp/tp+fp)Precision,即A/(A+B),越大越好。
举个例子: 如衣服检索中,我们对全部图片数据库中每张图片使用自己的模型进行检索到的总数中 加起来就是 tp+fp
然后自己模型真正检索到的就是tp 查准率就是 tp/tp+fp

“召回率”与“准确率”虽然没有必然的关系(从上面公式中可以看到),在实际应用中,是相互制约的。
要根据实际需求,找到一个平衡点。
往往难以迅速反应的是“召回率”。我想这与字面意思也有关系,从“召回”的字面意思不能直接看到其意义。
“召回”在中文的意思是:把xx调回来。“召回率”对应的英文“recall”,
recall除了有上面说到的“order sth to return”的意思之外,还有“remember”的意思。
Recall:the ability to remember sth. that you have learned or sth. that has happened in the past.当我们问检索系统某一件事的所有细节时(输入检索query查询词),
Recall指:检索系统能“回忆”起那些事的多少细节,通俗来讲就是“回忆的能力”。
“能回忆起来的细节数” 除以 “系统知道这件事的所有细节”,就是“记忆率”,
也就是recall——召回率。简单的,也可以理解为查全率。
根据自己的知识总结的,定义应该肯定对了,在某些表述方面可能有错误的地方。
假设原始样本中有两类,其中:
1:总共有 P个类别为1的样本,假设类别1为正例。
2:总共有N个类别为0 的样本,假设类别0为负例。
经过分类后:
3:有 TP个类别为1 的样本被系统正确判定为类别1,FN 个类别为1 的样本被系统误判定为类别 0,
显然有P=TP+FN;
4:有 FP 个类别为0 的样本被系统误判断定为类别1,TN 个类别为0 的样本被系统正确判为类别 0,
显然有N=FP+TN;
那么:
精确度(Precision):
P = TP/(TP+FP) ; 反映了被分类器判定的正例中真正的正例样本的比重
召回率(Recall),也称为 True Positive Rate:
R = TP/(TP+FN) = 1 - FN/T; 反映了被正确判定的正例占总的正例的比重
准确率(Accuracy)
A = (TP + TN)/(P+N) = (TP + TN)/(TP + FN + FP + TN);
反映了分类器统对整个样本的判定能力——能将正的判定为正,负的判定为负
转移性(Specificity,不知道这个翻译对不对,这个指标用的也不多),
也称为 True NegativeRate
S = TN/(TN + FP) = 1 – FP/N; 明显的这个和召回率是对应的指标,
只是用它在衡量类别0 的判定能力。
F-measure or balanced F-score
F = 2 * 召回率 * 准确率/ (召回率+准确率);这就是传统上通常说的F1 measure,
另外还有一些别的F measure,可以参考下面的链接
上面这些介绍可以参考:
http://en.wikipedia.org/wiki/Precision_and_recall
同时,也可以看看:http://en.wikipedia.org/wiki/Accuracy_and_precision
为什么会有这么多指标呢?
这是因为模式分类和机器学习的需要。判断一个分类器对所用样本的分类能力或者在不同的应用场合时,
需要有不同的指标。 当总共有个100 个样本(P+N=100)时,假如只有一个正例(P=1),
那么只考虑精确度的话,不需要进行任何模型的训练,直接将所有测试样本判为正例,
那么 A 能达到 99%,非常高了,但这并没有反映出模型真正的能力。另外在统计信号分析中,
对不同类的判断结果的错误的惩罚是不一样的。举例而言,雷达收到100个来袭 导弹的信号,
其中只有 3个是真正的导弹信号,其余 97 个是敌方模拟的导弹信号。假如系统判断 98 个
(97 个模拟信号加一个真正的导弹信号)信号都是模拟信号,那么Accuracy=98%,
很高了,剩下两个是导弹信号,被截掉,这时Recall=2/3=66.67%,
Precision=2/2=100%,Precision也很高。但剩下的那颗导弹就会造成灾害。
因此在统计信号分析中,有另外两个指标来衡量分类器错误判断的后果:
漏警概率(Missing Alarm)
MA = FN/(TP + FN) = 1 – TP/T = 1 - R; 反映有多少个正例被漏判了
(我们这里就是真正的导弹信号被判断为模拟信号,可见MA此时为 33.33%,太高了)
虚警概率(False Alarm)
FA = FP / (TP + FP) = 1 – P;反映被判为正例样本中,有多少个是负例。
统计信号分析中,希望上述的两个错误概率尽量小。而对分类器的总的惩罚旧
是上面两种错误分别加上惩罚因子的和:COST = Cma *MA + Cfa * FA。
不同的场合、需要下,对不同的错误的惩罚也不一样的。像这里,我们自然希望对漏警的惩罚大,
因此它的惩罚因子 Cma 要大些。
个人观点:虽然上述指标之间可以互相转换,但在模式分类中,
一般用 P、R、A 三个指标,不用MA和 FA。而且统计信号分析中,也很少看到用 R 的。
好吧,其实我也不是IR专家,但是我喜欢IR,最近几年国内这方面研究的人挺多的,google和百度的强势,也说明了这个方向的价值。当然,如果你是学IR的,不用看我写的这些基础的东西咯。如果你是初学者或者是其他学科的,正想了解这些科普性质的知识,那么我这段时间要写的这个"信息检索X科普"系列也许可以帮助你。(我可能写的不是很快,见谅)
至于为什么名字中间带一个字母X呢? 
为什么先讲Precision和Recall呢?因为IR中很多算法的评估都用到Precision和Recall来评估好坏。所以我先讲什么是"好人",再告诉你他是"好人"
查准与召回(Precision & Recall) T
先看下面这张图来理解了,后面再具体分析。下面用P代表Precision,R代表Recall
通俗的讲,Precision 就是检索出来的条目中(比如网页)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
下面这张图介绍True Positive,False Negative等常见的概念,P和R也往往和它们联系起来。
我们当然希望检索的结果P越高越好,R也越高越好,但事实上这两者在某些情况下是矛盾的。比如极端情况下,我们只搜出了一个结果,且是准确的,那么P就是100%,但是R就很低;而如果我们把所有结果都返回,那么必然R是100%,但是P很低。
因此在不同的场合中需要自己判断希望P比较高还是R比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析(我应该会在以后介绍)。
F1 Measure
前面已经讲了,P和R指标有的时候是矛盾的,那么有没有办法综合考虑他们呢?我想方法肯定是有很多的,最常见的方法应该就是F Measure了,有些地方也叫做F Score,都是一样的。
F Measure是Precision和Recall加权调和平均:
F = (a^2+1)P*R / a^2P +R
当参数a=1时,就是最常见的F1了:
F1 = 2P*R / (P+R)
很容易理解,F1综合了P和R的结果。
總之:
误检率: fp rate = sum(fp) / (sum(fp) + sum(tn))
查准率: precision rate = sum(tp) / (sum(tp) + sum(fp))
查全率: recall rate = sum(tp) / (sum(tp) + sum(fn))
漏检率:miss rate = sum(fn) / (sum(tp) + sum(fn)) -> (1-recall rate)
recall rate + miss rate = 1
FPPI/FPPW
FP(false positive):错误正例->分类结果为正例(行人),实际上是负例(没有行人)
Miss Rate:丢失率=测试集正例判别为负例的数目/测试集检索到想要的正例数加上未检测到不想要的 即是 全部groud truth的数量
与recall 对应等于 1-recall
目标检测中另外常用的评价标准则是FPPW和FPPI,详细应用可以参考这篇文章:
Pedestrian detection: A benchmark
两者都侧重考察FP(False Positive)出现的频率。
FPPW (False Positive per Window)
基本含义:给定一定数目N的负样本图像,分类器将负样本判定为“正”的次数FP,其比率FP/N即为FPPW。意义与ROC中的假阳率相同。FPPW中,一张图就是一个样本。
FPPI (False Positive per Image)
基本含义:给定一定数目N的样本集,内含N张图像,每张图像内包含或不包含检测目标。
每张图像均需要标定:
1.包含目标的个数;
2. 目标的准确位置L。
而后在每张图像上运行分类器,检测目标并得到位置p。然后,检查每张图像内的检测结果是否“击中”标定的目标:
a. 若图像内无目标,而分类器给出了n个“目标”检测结果,那么False Positive 次数 +n;
b. 若图像内有目标,则判断p是否击中L,判断标准参看上述文章(主要看p与L的重叠率)。若判断未击中,则False Positive 次数 +1。
最后 FPPI = (False Positive 次数)/N。(即平均每张图中 能 正确检索到的数目)
FPPI 相比于FPPW来说,更接近于分类器的实际应用情况。















 2289
2289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









