










1.正则表达式
正则表达式是一种小型的,高度专业化的编程语言。Python中内嵌了正则表达式,当我们需要匹配一个字符串的时候,就用到了Python为我们提供的有关正则表达式处理的模块,比如re模块。
下面我们来介绍下正则表达式的使用和re模块。
2.正则表达式元字符
上面我们提到处理正则表达式的re模块,Python中的re模块为我们提供的一个较常用的处理正则表达式的方法就是findall(pattern,string),第一个参数pattern是正则表达式,第二个参数string是待匹配的字符串。
函数findall(pattern,string)和数据结构中的模式识别类似,不同的是findall(pattern,string)中的模式子串pattern更加灵活多变。下面举一个模式匹配的例子:
import re
s='abc'
print(re.findall(s,"aaabcaaabcaabc"))在使用re模块之前需要先导入re模块,然后才可以调用它为我们提供的函数。如上,s为一个模式子串,也是最简单的正则表达式,函数findall(pattern,string)会将string中所有与正则表达式pattern匹配的子串都找出来,并返回一个由子串组成的列表。打印结果如下:

如上结果,re.findall(s,"aaabcaaabcaabc")会将"aaabcaaabcaabc"中所有与"abc"匹配的子串找出来,并封装到列表中返回。
(1)[]
[]为正则表达式的一个元字符,所匹配到的是一个字符,下面介绍下如何使用[]来匹配字符串。
实例1:形如[abc],匹配'a','b','c'中的任一个字符,且[abc]匹配到的只能是一个字符。代码例子如下:
import re
s3='t[io]p'
print(re.findall(s3,"tip top trp tep typ tiop"))
如上正则表达式s3='t[io]p',可以匹配到模式子串"tip"或者"top",即[io]=="i"或者[io]=="o"。代码运行结果如下:

如上,函数findall(pattern,string)将"tip top trp tep typ tiop"中把匹配到s3的所有子串找到并返回。
实例2:形如[^abc]:匹配到非字符"a","b","c"的任意一个字符,即[^abc]=='d',[^abc]=='e',但[^abc]!="a"||"b"||"c",^在[]中的开始位置使用表示的是取非符号。代码例子如下:
import re
s4='t[^io]p'
print(re.findall(s4,"tip top trp tep typ tiop tp"))
如上,正则表达式s4='t[^io]p',首先s4匹配到的是一个长度为3的字符串,其次[^io]匹配到的为非"i"和"o"的任意一个字符,如可以匹配到"tup","thp",但是匹配不到"tip","top"。代码打印结果如下:

实例3:形如[a-z]表示的是一个从字符"a"到字符"z"的任意一个字符。代码例子如下:
import re
s="t[a-c]p"
print(re.findall(s,"tap tbp tcp tdp tp tiop tgp tbcp"))
如上代码,正则表达式s="t[a-c]p",首先s匹配到的是一个长度为3的字符串,其次[a-c]=="a"||"b"||"c",即s匹配到的模式子串只能是"tap","tbp","tcp",代码打印结果如下:

如果需要匹配的字符范围不只一个,那么多个字符范围依次写在[]中就可以了,如下代码:
import re
s9="x[1-9a-z]x"
print(re.findall(s9,"x1x x2x x3x x4x xax xbx xzx "))
如上s9="x[1-9a-z]x",[1-9a-z]有两个字符范围,分别是'1'-'9'和'a'-'z',可以匹配到的字符是所有的数字字符和小写字母字符。代码打印结果如下:

(2)^
以上我们提到,元字符^在[]中首位表示取非,当元字符^单独使用并作为正则表达式的首位字符时,表示的是查询^后的模式子串是否为待匹配主串的开始字符串,如"^abc"表示查询待匹配主串是否以模式子串"abc"作为开头,如果是,则返回模式子串"abc",否则返回空。
代码例子如下:
import re
s5="^hello"
print(re.findall(s5,"hello world,hello myGF"))
print(re.findall(s5,"world,hello myGF"))
如上,s5="^hello"表示查找待匹配子串的开始是否是"hello",如果是则返回模式子串"hello",如果不是则返回空。代码打印结果如下:

(3)$
元字符$在正则表达式的结尾使用, 表示的是查询待匹配主串是否以$前的模式子串结尾,如"abc$”表示查找待匹配字符串的结尾字符串是否是"abc",如果是则返回"abc",否则返回空。代码例子如下:
import re
s5="myGF$"
print(re.findall(s5,"hello world,hello myGF"))
print(re.findall(s5,"hello world,hello"))
如上,正则表达式s5="myGF$"表示查找待匹配主串的结尾字符串是否是"myGF",如果是返回"myGF",否则返回空。代码打印结果如下:

(4)注意事项
事项一:$在[]中使用的时候是无效的,$只是被当做一个普通字符来进行模式匹配。如[abc$]可以匹配到的字符有'a','b','c','$'。'$'被当做普通字符,与'a','b','c'一样处理。如下代码:
import re
s6="t[abc$]"
print(re.findall(s6,"ta"))
print(re.findall(s6,"tb"))
print(re.findall(s6,"tc"))
print(re.findall(s6,"t$"))
如上所示,s6='t[abc$]',可以匹配到的模式子串如下:"ta","tb","tc","t$"。运行结果如下:

事项二:元字符^在[]中使用,只有在^位于[]开头的情况下才表示取非的含义,在其他位置使用都会被当做普通字符来处理。代码如下:
import re
s7="t[a^bc]"
print(re.findall(s7,"ta tb tc t^ td"))
如上s7="t[a^bc]",^在[a^bc]的位置并不是首位字符,所以^会被当做普通字符"^"来处理,s7可以匹配到的模式子串为,"ta","t^","tb","tc"。代码打印结果如下:
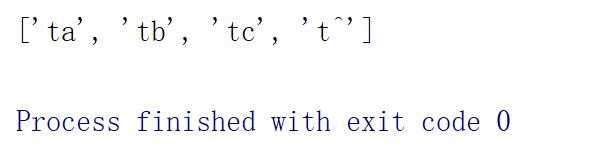
下一节我们会继续介绍正则表达式,敬请期待。















 2588
2588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









