










这一节我们来介绍下Python中re模块为我们提供的一些属性。使用这些属性为正则匹配添加条件,可以有效的避免正则表达式复杂化。例如,在匹配时指定属性re.I,可以使模式子串的匹配不区分大小写.但是如果只使用正则表达式实现模式子串的匹配不区分大小写,这时,正则表达式的书写就会相对复杂。下面我们来一一介绍这些属性。
(1)属性re.S
上一节我们介绍了通配符"."可以表示任意字符,其实严格的说通配符"."可以匹配除换行符"\n"的任意字符.如下:
import re
r1=r"hello.world"
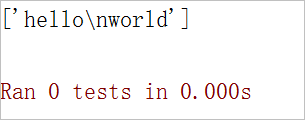
print(re.findall(r1,"hello\nworld"))打印结果如下:

可以看到返回的是空字符串,这说明r1="hello.world"中的通配符"."并不能匹配换行符"\n"。如果想让通配符"."能够匹配换行符"\n",就需要指定属性re.S。如下:
import re
r1=r"hello.world"
print(re.findall(r1,"hello\nworld",re.S))在调用re模块中的方法findall(pattern,string,flag)时,指定属性flag=re.S,就可以实现通配符"."匹配包括换行符"\n"的任意字符。打印结果如下:
(2)属性re.I
调用findall(pattern,string,flag)指定属性flag=re.I的作用就是,对正则表达式中的模式子串匹配时不区分大小写。例如r"hello",可以匹配到的模式子串有诸如"Hello","hello","hellO"等等。代码例子如下:
import re
r=r"hello"
print(re.findall(r,"HELLO",re.I))
print(re.findall(r,"Hello",re.I))
print(re.findall(r,"hello",re.I))如上,在对模式子串"hello"匹配时指定属性re.I,在主串中对其匹配时是不区分大小写的。代码打印结果如下:

(3)属性re.M
re.M适用于对多行字符串进行匹配,每一行都当做一个主串来匹配。先看下面这个例子:
import re
r1=r"^hello"
s="""
hello world
world hello
hello myGF
myGF hello
"""
print(re.findall(r1,s))如上,正则表达式r1匹配主串s是否以"hello"开头,若是则返回"hello",否则返回空字符。打印结果如下:

代码中s明明是以"hello"开头的字符串,那么返回的为什么却是空字符呢?在命令行中打印字符串s,可以看到s的字符串实质上如下:
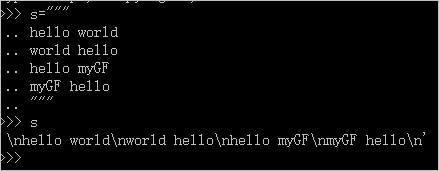
我们在使用""" """时来书写字符串时,虽然看起来简洁了许多,但无意间也增加了额外的换行符"\n",可以看到s='\nhello world\nworld hello\nhello myGF\nmyGF hello\n',s是以换行符开头的字符串,所以使用正则表达式r"^hello"在主串s中匹配时返回为空字符。
解决这一问题的方法,就是在匹配模式子串时指定flag=re.M。这样一来在匹配时就会一行一行的进行匹配,每一行都会匹配一次。如下代码:
import re
r1="^hello"
s="""
hello world
world hello
hello myGF
myGF hello
"""
print(re.findall(r1,s,re.M))代码打印结果如下:

可以看到,在指定属性re.M后,对s中的每行字符串都匹配是否以"hello"开头,得到的结果如上。
(4)分组()
在正则表达式中,使用的是()来表示一个分组,那么什么是分组呢?其实分组在正则表达式中就像是划分块,把一个正则表达式划分几个小块,以达到我们匹配的目的。如下,是一个分组的例子:
import re
r1="\w{3}@\w+(\.com|\.cn)"
print(re.match(r1,"asd@asd.com"))
print(re.match(r1,"asd@asd.cn"))
print(re.match(r1,"asd@asd.org"))
如上r1是一个对邮箱字符串匹配的正则表达式,r1="\w{3}@\w+(\.com|\.cn)",\w表示匹配一个数字或者字母字符,r1匹配的是一个3位字符(数字或字母)开始,中间为字符"@",后接若干字符(数字或者字母),最后以".com"或者".cn"结尾的邮箱字符串。形如,"123@zhangsan.com"。打印结果如下:

当一个正则表达式中含有分组时,使用findall(pattern,string)方法返回的是分组中的正则表达式匹配到的子串,利用这个特性,我们可以通过分组来获取我们想要得到的数据。
如下代码:
import re
s="""
name=zhangsan
name=lisi
name=wangwu
asd-hihihj
zxc4asd
"""
r1=r"name=.+"
print(re.findall(r1,s))
如上,正则表达式r1=r"name=.+",r1匹配到的子串为字符串"name="开始,".+"表示后接若干字符,是形如"name=zhangsan"这样的子串。代码打印结果如下:

而当我们需要获取是"zhangsan"这样的名字字符串数据时,使用分组将我们需要的数据括起来,调用re模块的findall(pattern,string)方法,返回的就是分组中的正则匹配到的子串。代码如下:
import re
s="""
name=zhangsan
name=lisi
name=wangwu
asd-hihihj
zxc4asd
"""
r1=r"name=(.+)"
print(re.findall(r1,s))代码打印结果如下:

如上,r1=r"name=(.+)",将需要获取的数据使用()括起来。通过打印结果可以看到,使用r1="name=(.+)"进行匹配时,再调用findall(pattern,string)返回的并不是正则表达式r1所匹配到的子串,而是分组中的正则匹配到的子串。
介绍了这么多节正则表达式,下一节我们使用正则表达式来做一个爬虫的小项目,敬请期待。















 2482
2482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









