






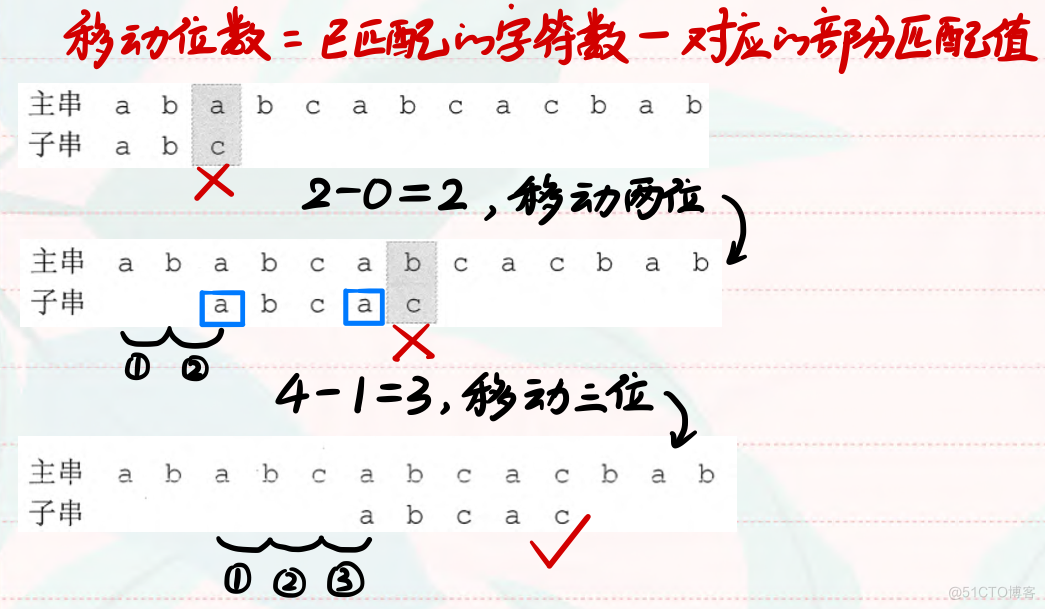
在暴力匹配中,每趟匹配失败都是模式后移一位再从头开始比较。而某趟已匹配相等的字符序列是模式的某个前缀,这种频繁的重复比较相当于模式串在不断地进行自我比较,这就是低效率的根源。
理解KMP算法
KMP算法,全称为Knuth-Morris-Pratt算法,是一种字符串匹配算法,用于在一个文本串S中查找一个模式串P的出现位置。相较于传统的暴力匹配算法,KMP算法具有更高的效率。
KMP算法的核心思想是利用已经匹配过的信息,避免不必要的回溯。它通过构建一个辅助数组next[],记录模式串中每个位置之前最长的相同前缀和后缀的长度。在进行匹配时,当出现不匹配的情况时,通过查找next数组得到一个新的起始位置,从而避免重复匹配已经比较过的部分。
具体KMP算法流程
- 预处理模式串P,构建next数组。
- 设置两个指针i和j,分别指向文本串S和模式串P的起始位置。
- 逐个比较S[i]与P[j]的字符:
- 若匹配成功,则i和j同时后移。
- 若匹配失败,根据next数组找到一个新的j值,使得P[0...j-1]与S[i-j+1...i-1]相等。
- 重复步骤3直至达到文本串或模式串的末尾。
- 若找到匹配,返回匹配的起始位置;否则,返回-1。
通过利用next数组的信息,KMP算法将匹配时间复杂度降低至O(n+m),其中n为文本串的长度,m为模式串的长度。
KMP算法的关键是构建next数组,它用于记录模式串中每个位置之前最长的相同前缀和后缀的长度。
前缀后缀的最大公共元素长度
- 前缀:即从第一个字母开始往后看到最后一个字母(不包括)为止的字符串的以第一个字母开头的子串,如 "abab" 的前缀有a,ab,aba
- 后缀:即从最后一个字母开始往前看到第一个字母(不包括)为止的字符串的以最后一个字符为末尾的子串,如"abab" 的后缀有b,ab,bab
- 最大公共子串长度:也就是前缀和后缀拥有的相同子串的最大长度,以"abab"为例:
模式串各个子串 | 前缀 | 后缀 | 最大公共元素长度 |
a | 空 | 空 | 0 |
ab | a | b | 0 |
aba | a,ab | a,ba | 1 |
abab | a,ab,aba | b,ab,bab | 2 |
例如模式串”abcac“与“ababcabcacbab”进行匹配
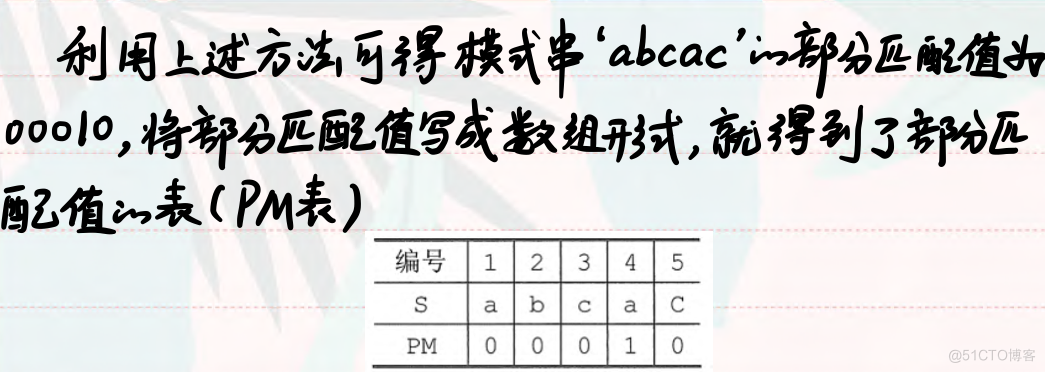
KMP算法求next数组

function getNextArray(pattern):
n := pattern.length
next := new Array of size n
next[0] := -1 // 初始化next数组第一个元素为-1
i := 0 // 模式串指针
j := -1 // next数组指针
while i < n - 1 do:
if j == -1 or pattern[i] == pattern[j] then:
i := i + 1
j := j + 1
next[i] := j
else:
j := next[j]
return next根据上述伪代码,next数组的求解过程如下:
- 首先,我们初始化next数组的第一个元素next[0]为-1。
- 然后,使用两个指针i和j分别指向模式串的字符位置和next数组的位置。循环遍历模式串的字符。
- 如果j等于-1或者当前位置的字符与j位置的字符相等,则将i和j分别后移,并且将next[i]设置为j的值。
- 如果当前位置的字符与j位置的字符不相等,则将j更新为next[j],继续匹配。
- 循环结束后,即可得到完整的next数组。
最终返回的next数组即为KMP算法所需的结果,需要注意的是,next数组中的值不包括当前位置的字符。即next[i]表示模式串中从0到i-1的子串的最长相同前缀和后缀长度。
继续接上一节子串abcac的next求解如下:

算法推演如下:


KMP算法在字符串匹配中有着广泛的应用。它能有效地解决大规模文本搜索、DNA序列匹配等问题,提高了字符串匹配的效率。对于需要频繁进行字符串匹配的应用场景,使用KMP算法能够显著减少计算时间,提升算法性能。














 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









