







介绍:
首先先来介绍下webmagic这个爬虫框架,这个框架是大佬黄义华开源的爬虫框架,用起来非常的顺手, 跟之前用python中的scrapy框架一样,层次非常清晰,可扩展性也是非常的好。文档也比较齐全,并且现在还在一直更新。
优点就说这些,但是也有一些不足,在我学习的过程中,遇到了一些问题,比如就是没有关于登录的例子,并且没有google出相关的内容,这里是自己摸索的出的一种方法。
在使用爬虫的过程中,有的网站的信息必须是要登录后才能查看的,这里就拿世纪佳缘网作为例子,来进行一个登陆的测试。
首先在没有用户登陆的情况下,我们是看不到世纪佳缘网上用户的一些经济信息的,如下图所示:
这是登陆后的页面,就可以看到用户的经济方面的信息了,同时使用chrome看到页面的cookie信息。
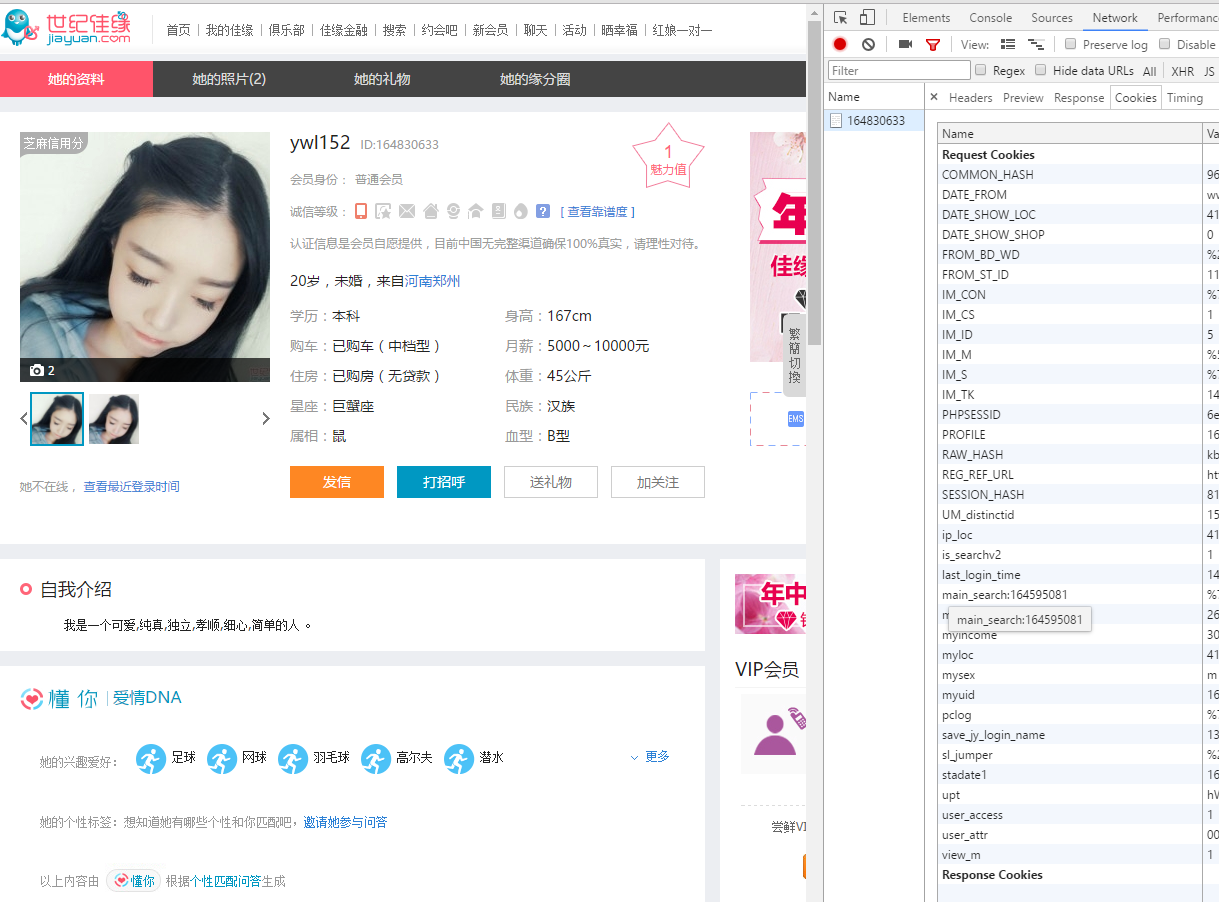
如果我想要爬取到这些信息,肯定是要进行登陆才可以的,这里就要获取到cookie的信息,webmagic中整合了Selenium这个模拟浏览器,来帮助我们进行登陆并,但是效率会有点慢,也可以使用phantomjs。
首先先引入webmagic对Selenium的整合jar包,这里使用的是maven管理。
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-selenium</artifactId>
<version>0.5.2</version>
</dependency>从上面的图可以看到cookie的信息非常的多,而登录需要的cookie就在其中,而且每个页面中的cookie也不是一样,我们不可能一个个去试,最要命的是webmagic中的site 没有 scrapy中的setCookies()函数,一次只能添加一个cookie信息。要想添加全部的cookie信息,就要使用下面的方法.
因为要模拟浏览器,所以要下载个当前浏览器的驱动,我使用的chrome
这是驱动的下载地址http://download.csdn.net/detail/leoe_/9903768,如果使用的是其他的浏览器,可以自行去搜索下,让后把驱动放在 C:\Windows\System32 文件下就可以了。
废话不多说,上代码,如果没有接触过webmagic和Selenium可以先了解下,再去运行下面的代码。
package org.will.WebMagic;
import java.util.List;
import java.util.Set;
import org.openqa.selenium.By;
import org.openqa.selenium.Cookie;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class Miai implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(0).setTimeOut(3000);
//用来存储cookie信息
private Set<Cookie> cookies;
@Override
public void process(Page page) {
//获取用户的id
page.putField("", page.getHtml().xpath("//div[@class='member_info_r yh']/h4/span/text()"));
//获取用户的详细信息
List<String> information = page.getHtml().xpath("//ul[@class='member_info_list fn-clear']//li/div[@class='fl pr']/em/text()").all();
page.putField("information = ", information);
}
//使用 selenium 来模拟用户的登录获取cookie信息
public void login()
{
WebDriver driver = new ChromeDriver();
driver.get("http://login.jiayuan.com/?channel=200&position=204&pre_url=http%3A%2F%2Fsearch.jiayuan.com%2Fv2%2F");
driver.findElement(By.id("login_email")).clear();
//在******中填你的用户名
driver.findElement(By.id("login_email")).sendKeys("*******");
driver.findElement(By.id("login_password")).clear();
//在*******填你密码
driver.findElement(By.id("login_password")).sendKeys("*******");
//模拟点击登录按钮
driver.findElement(By.id("login_btn")).click();
//获取cookie信息
cookies = driver.manage().getCookies();
driver.close();
}
@Override
public Site getSite() {
//将获取到的cookie信息添加到webmagic中
for (Cookie cookie : cookies) {
site.addCookie(cookie.getName().toString(),cookie.getValue().toString());
}
return site.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1");
}
public static void main(String[] args){
Miai miai = new Miai();
//调用selenium,进行模拟登录
miai.login();
Spider.create(miai)
.addUrl("http://www.jiayuan.com/164830633")
.run();
}
}
这是代码运行的结果:已经可以爬下来用户的全部信息了。

可以结合代码自己找个页面试试,代码中有注释,这只是我想到的一种登录的方法,我也是刚学习这个框架,如果有什么不对请指出来,或者有更好的方法也可以分享下。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









