









手写体识别问题可以追溯到20世纪20年代,当时提出了统计方法可能是最佳的选择,手写体的识别在生活中会有很多的地方应用,例如:邮局里信件堆积如山,因此需要借助自动化手段识别邮政编码,实现自动化和高效地分拣邮件。
实现手写体识别也有其他的方法,比如使用OCR(光学字符识别),通过将手写文档读入,然后识别文字后生成电子文档,但是这种识别的效率不高,但是如果将OCR结合着大数据和机器学习肯定会将准确率达到一个新的高度,本篇文章只是基于BP神经网络实现了一个简单的手写数字识别系统,性能也不是很好,但是这是一个起点,从这里出发可以做出很多有趣的事物,比如商品识别、语言翻译、游戏AI、图片还原等等。
简介
首先说明几个概念,首先机器学习就是通过大量数据训练一个能够识别多种模式的系统。训练系统用的数据集合称为训练集,如果训练集的每个数据条目都打上目标输出数据(标签),则该方法称作监督学习,不打标签的就是非监督学习。机器学习中有多种算法都是能够实现手写字符识别的,本文中就是基于神经网络实现该系统。
神经网络:由能够相互通信的节点构成,赫布理论解释了人体的伸进网络是如何通过改变自身的结构和神经连接的强度来记忆某种模式的。而人工智能终端神经网络与此类似。
在下面的图中,最左边一列蓝色节点是输入节点,最右列节点是输出节点,中间是隐藏节点。该结构是分层的,隐藏的部分有时候也会分为多个隐藏层,如果使用的层数非常的多就是平常说的深度学习。
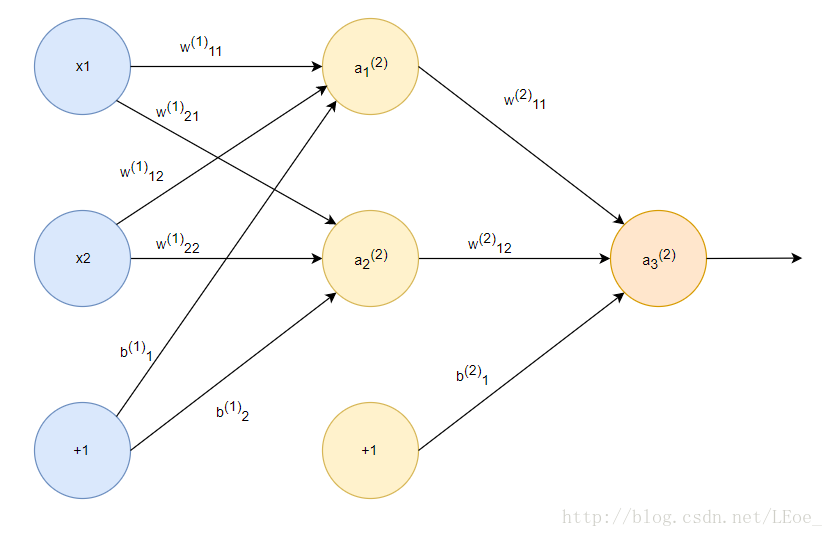
其中每一层(除了输入层)的节点由前一层的节点加权相加加偏置向量并经过激活函数得到,公式如下:
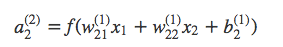
其中f是激活函数,b是偏置向量
这一类拓扑结构的神经网络称作前馈神经网络,因为该结构中不存在回路。有输出反馈给输入的神经网络称作递归神经网络(RNN)。在本课程中我们使用前馈神经网络中经典的BP神经网络来实现手写识别系统。
神经网络属于监督学习,那么就三件事情,决定模型参数,通过数据集训练学习,训练好后就能到分类工具/识别系统用了。
数据集可以分为三部分:训练集、验证集、测试集。训练集是系统通过对比正确答案和自己的解答不断学习改良自己。测试集可以看做是一次性的比对,没有正确答案。验证集就是多个测试中选择最好的,验证集决定模型参数。
系统构成
OCR系统分为五个部分:
- 客户端(ocr.js)
- 服务器(server.py)
- 用户接口(ocr.html)
- 神经网络(ocr.py)
- 神经网络设计脚本(neural_network_design.py)
目录结构:

用户接口(ocr.html)是一个html页面,用户在画板上写数字,之后点击选择训练或是预测。
客户端(ocr.js)将收集到的手写数字组合成一个数组发送给服务器端(server.py)处理,服务器调用神经网络模块(ocr.py),它会在初始化时通过已有的数据集训(data.csv、dataLabels.csv)练一个神经网络,神经网络的信息会被保存在nn.json中,等之后再一次启动时使用。
最后,神经网络设计脚本(neural_network_design.py)是用来测试不同隐藏节点数下的性能,决定隐藏节点数用的。
下面的完整的代码我已上传到GitHub中:https://github.com/HinWill/Identify
用户接口(ocr.html ocr.js)
需要给予用户输入数据、预测、训练的接口。在 ocr.html 中.
手写输入等主要的客户端逻辑主要在ocr.js中实现
画布的设定为20*20:
var ocrDemo = {
CANVAS_WIDTH: 200,
TRANSLATED_WIDTH: 20,
PIXEL_WIDTH: 10, // TRANSLATED_WIDTH = CANVAS_WIDTH / PIXEL_WIDTH在画布上加入网格辅助输入和查看:
drawGrid: function(ctx) {
for (var x = this.PIXEL_WIDTH, y = this.PIXEL_WIDTH;
x < this.CANVAS_WIDTH; x += this.PIXEL_WIDTH,
y += this.PIXEL_WIDTH) {
ctx.strokeStyle = this.BLUE;
ctx.beginPath();
ctx.moveTo(x, 0);
ctx.lineTo(x, this.CANVAS_WIDTH);
ctx.stroke();
ctx.beginPath();
ctx.moveTo(0, y);
ctx.lineTo(this.CANVAS_WIDTH, y);
ctx.stroke();
}
},使用一维数组来存储手写输入,也可以使用二维数组,更加直观。
0代表黑色(背景色),1代表白色(笔刷色),手写输入与存储的代码:
onMouseMove: function(e, ctx, canvas) {
if (!canvas.isDrawing) {
return;
}
this.fillSquare(ctx,
e.clientX - canvas.offsetLeft, e.clientY - canvas.offsetTop);
},
onMouseDown: function(e, ctx, canvas) {
canvas.isDrawing = true;
this.fillSquare(ctx,
e.clientX - canvas.offsetLeft, e.clientY - canvas.offsetTop);
},
onMouseUp: function(e) {
canvas.isDrawing = false;
},
fillSquare: function(ctx, x, y) {
var xPixel = Math.floor(x / this.PIXEL_WIDTH);
var yPixel = Math.floor(y / this.PIXEL_WIDTH);
//在这里存储输入
this.data[((xPixel - 1) * this.TRANSLATED_WIDTH + yPixel) - 1] = 1;
ctx.fillStyle = '#ffffff'; //白色
ctx.fillRect(xPixel * this.PIXEL_WIDTH, yPixel * this.PIXEL_WIDTH,
this.PIXEL_WIDTH, this.PIXEL_WIDTH);
},
下面完成在客户端点击训练键时触发的函数。
当客户端的训练数据到达一定数量时,就一次性传给服务器端给神经网络训练用:
train: function() {
var digitVal = document.getElementById("digit").value;
// 如果没有输入标签或者没有手写输入就报错
if (!digitVal || this.data.indexOf(1) < 0) {
alert("Please type and draw a digit value in order to train the network");
return;
}
// 将训练数据加到客户端训练集中
this.trainArray.push({"y0": this.data, "label": parseInt(digitVal)});
this.trainingRequestCount++;
// 训练数据到达指定的量时就发送给服务器端
if (this.trainingRequestCount == this.BATCH_SIZE) {
alert("Sending training data to server...");
var json = {
trainArray: this.trainArray,
train: true
};
this.sendData(json);
// 清空客户端训练集
this.trainingRequestCount = 0;
this.trainArray = [];
}
},
接着完成在客户端点击测试键(也就是预测)时触发的函数:
test: function() {
if (this.data.indexOf(1) < 0) {
alert("Please draw a digit in order to test the network");
return;
}
var json = {
image: this.data,
predict: true
};
this.sendData(json);
},
最后,我们需要处理在客户端接收到的响应,这里只需处理预测结果的响应:
receiveResponse: function(xmlHttp) {
if (xmlHttp.status != 200) {
alert("Server returned status " + xmlHttp.status);
return;
}
var responseJSON = JSON.parse(xmlHttp.responseText);
if (xmlHttp.responseText && responseJSON.type == "test") {
alert("The neural network predicts you wrote a \'"
+ responseJSON.result + '\'');
}
},
onError: function(e) {
alert("Error occurred while connecting to server: " + e.target.statusText);
},
最后整个客户端的效果如下:

服务器端(server.py)
服务器端由Python标准库BaseHTTPServer 实现,我们接受从客户端发来的训练或是预测请求,使用POST报文,由于逻辑简单,这两种请求就发给一个URL
实现神经网络(ocr.py)
这里使用的方向传播算法来训练神经网络,算法背后的原理推导可以看这里的:反向传播神经网络入门
这里简单的介绍下算法的三个步骤:
第一步:初始化神经网络
一般将所有权值和偏置量置为(-1,1)范围内的随机数,在这里,使用(-0.06,0.06)这个范围,输入层到隐藏层的权值存储在矩阵theta1中,偏置量存在input_layer_bias中,隐藏层到输出层则分别存在theta2与hidden_layer_bis中。
创建随机阵的代码如下,这里输出的矩阵是以size_out为行,size_in为列。一般待处理的输入放在右边,处理操作(矩阵)放在左边,所以这里的size_in在左边
def _rand_initialize_weights(self, size_in, size_out):
return [((x * 0.12) - 0.06) for x in np.random.rand(size_out, size_in)]初始化权值矩阵和偏置向量:
self.theta1 = self._rand_initialize_weights(400, num_hidden_nodes)
self.theta2 = self._rand_initialize_weights(num_hidden_nodes, 10)
self.input_layer_bias = self._rand_initialize_weights(1,
num_hidden_nodes)
self.hidden_layer_bias = self._rand_initialize_weights(1, 10)这里说明一下会用到的每一个矩阵/向量及其形状:
y0 输入 1 * 400
theta1 输入-隐藏层权值矩阵 隐藏层节点数 * 400
input_layer_bias 输入-隐藏层偏置向量 隐藏层节点数 * 1
y1 隐藏层 隐藏层节点数 * 1
theta2 隐藏-输出层权值矩阵 10 * 隐藏层节点数
hidden_layer_bias 隐藏-输出层偏置向量 10 * 1
y2 输出层 10 * 1第二步:前向传播
前向传播就是输入数据通过一层一层计算到达输出层得到输出结果,输出层会有10个节点分别代表0~9,哪一个节点的输出值最大就作为我们预测的结果,一般用sigmoid函数作为激发函数
# sigmoid激发函数
def _sigmoid_scalar(self, z):
return 1 / (1 + math.e ** -z)这个函数长这个样子:
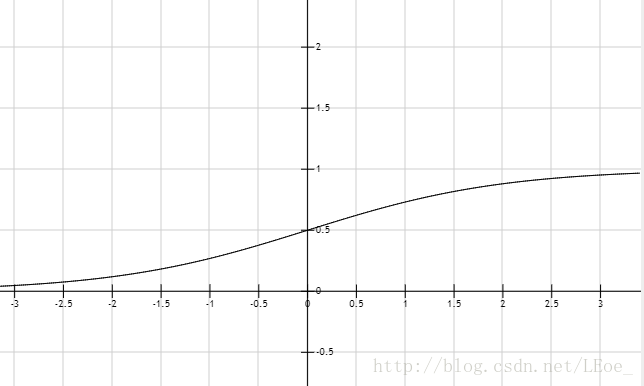
可以将实数范围的数字映射到(0,1),S型的形状很理想,因为导数可以直接得到。
使用numpy和vectorize能得到标量函数的向量化版本,这里可以直接处理向量:
self.sigmoid = np.vectorize(self._sigmoid_scalar)向前传播的代码:
y1 = np.dot(np.mat(self.theta1), np.mat(data['y0']).T)
sum1 = y1 + np.mat(self.input_layer_bias)
y1 = self.sigmoid(sum1)
y2 = np.dot(np.array(self.theta2), y1)
y2 = np.add(y2, self.hidden_layer_bias)
y2 = self.sigmoid(y2)
第三步:反向传播
这一步是训练的关键,它需要通过计算误差率后,系统根据误差改变网络的权值矩阵和偏置向量。通过训练数据的标签我们得到actual_vals用来和输出层相减得到误差率output_errors,输出层的误差只能用来改进上一层,要想改进上上一层就需要计算上一层的输出误差
actual_vals = [0] * 10
actual_vals[data['label']] = 1
output_errors = np.mat(actual_vals).T - np.mat(y2)
hidden_errors = np.multiply(np.dot(np.mat(self.theta2).T, output_errors),
self.sigmoid_prime(sum1))
其中sigmoid_prime的作用就是先sigmoid再求导数
更新权重矩阵与偏置向量:
self.theta1 += self.LEARNING_RATE * np.dot(np.mat(hidden_errors),
np.mat(data['y0']))
self.theta2 += self.LEARNING_RATE * np.dot(np.mat(output_errors),
np.mat(y1).T)
self.hidden_layer_bias += self.LEARNING_RATE * output_errors
self.input_layer_bias += self.LEARNING_RATE * hidden_errors
LEARNING_RATE是学习进步,这里设置为0.1是为了结果会更精准
def predict(self, test):
y1 = np.dot(np.mat(self.theta1), np.mat(test).T)
y1 = y1 + np.mat(self.input_layer_bias) # Add the bias
y1 = self.sigmoid(y1)
y2 = np.dot(np.array(self.theta2), y1)
y2 = np.add(y2, self.hidden_layer_bias) # Add the bias
y2 = self.sigmoid(y2)
results = y2.T.tolist()[0]
return results.index(max(results))实现神经网络设计脚本
神经网络设计脚本的功能就是决定神经网络使用的隐藏节点的数量,这里从5个节点开始增长,每次增加5个,到50个为止,打印性能进行比较,其中数据集为data.csv 、dataLabels.csv这两个在我的GitHub上,可以下载到本地。
运行脚本查看结果(注意每次初始化时的参数是随机的,训练顺序也是随机的,所以每个人的训练结果应该是不一样的):
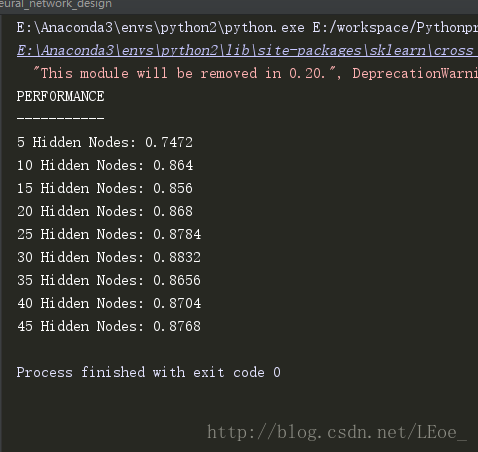
通过输出我们判断15个隐藏节点可能是最优的。从10到15增加了1%的精确度,之后需要再增加20个节点才能有如此的增长,但同时也会大大地增加了计算量,因此15个节点性价比最高。当然不追求性价比电脑性能也够用的话还是选择准确度最高的节点数为好。
实验结果:
打开服务器 server.py 在ocr.html上写一个数字:
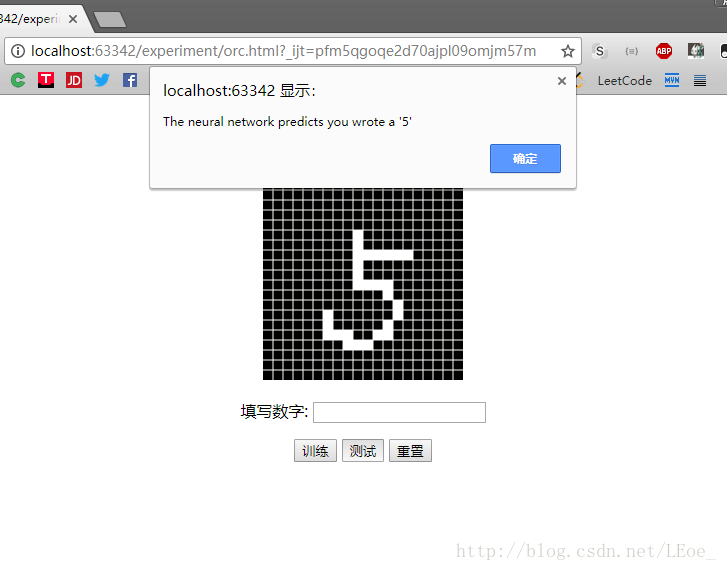
这个系统不仅可以分析数值或者是文本数据,还可以用来分析图像,甚至是由相机或者扫描仪生成的手写体图像
参考资料&延伸阅读
Optical Character Recognition (OCR)
Optical Character Recognition (OCR) 源代码
[反向传播神经网络极简入门](http://www.hankcs.com/ml/back-propagation-neural-network.html)
Error Backpropagation

















 2450
2450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









