






 本文深入解析了Spark中Shuffle机制的核心组件mapOutputTracker的工作原理,包括mapOutputTracker的实现细节、MapOutputTrackerMaster的运行机制及Shuffle注册流程。
本文深入解析了Spark中Shuffle机制的核心组件mapOutputTracker的工作原理,包括mapOutputTracker的实现细节、MapOutputTrackerMaster的运行机制及Shuffle注册流程。
mapOutputTracker用于跟踪map任务的输出状态,此状态便于reduce任务定位map输出结果所在的节点地址,进而获取中间输出结果。每个map任务或者reduce任务都会有其唯一标识,分别为mapId和reduceId。每个reduce任务的输入可能是多个map任务的输出,reduce会到各个map任务所在的节点上拉取Block,这一过程叫做Shuffle。每次Shuffle都有唯一的标识shuffleId。
在开始介绍mapOutputTracker之前,先来介绍SparkEnv中用于注册RpcEndpoint或者查找RpcEndpoint的方法registerOrLookupEndpoint,其代码如下:
//org.apache.spark.SparkEnv
def registerOrLookupEndpoint(
name: String, endpointCreator: => RpcEndpoint):
RpcEndpointRef = {
if (isDriver) {
logInfo("Registering " + name)
rpcEnv.setupEndpoint(name, endpointCreator)
} else {
RpcUtils.makeDriverRef(name, conf, rpcEnv)
}
}根据上述代码,如果当前实例是Driver,则调用setupEndpoint方法向Dispatcher注册Endpoint。如果是Executor,则调用工具类RpcUtils的makeDriverRef方法向远端的NettyRpcEnv获取相关RpcEndpoint的RpcEndpointRef。
SparkEnv中创建mapOutputTracker的代码如下:
//org.apache.spark.SparkEnv
val mapOutputTracker = if (isDriver) {
new MapOutputTrackerMaster(conf, broadcastManager, isLocal)
} else {
new MapOutputTrackerWorker(conf)
}
mapOutputTracker.trackerEndpoint = registerOrLookupEndpoint(MapOutputTracker.ENDPOINT_NAME,
new MapOutputTrackerMasterEndpoint(
rpcEnv, mapOutputTracker.asInstanceOf[MapOutputTrackerMaster], conf))可以看到针对当前实例是Driver还是Executor,创建mapOutputTracker的方式有所不同:
- 如果当前应用程序是Driver,则创建MapOutputTrackerMaster,然后创建MapOutputTrackerMasterEndpoint,并且注册到Dispatcher中,注册名为MapOutputTracker
- 如果当前应用程序是Executor,则创建MapOutputTrackerWorker,并从远端Driver实例的NettyRpcEnv的Dispatcher中查找MapOutputTrackerMasterEndpoint的引用
无论是Driver还是Executor,最后都由mapOutputTracker的属性trackerEndpoint持有MapOutputTrackerMasterEndpoint的引用。
1 MapOutpuTracker的实现
无论是MapOutputTrackerMaster还是MapOutputTrackerWorker,它们都继承自抽象类MapOutputTracker。MapOutputTracker内部定义了任务输出跟踪器的规范,下面查看其提供的属性:
//org.apache.spark.MapOutputTracker
var trackerEndpoint: RpcEndpointRef = _
protected val mapStatuses: Map[Int, Array[MapStatus]]
protected var epoch: Long = 0
protected val epochLock = new AnyRef
private val fetching = new HashSet[Int]- trackerEndpoint:用于持有Driver上MapOutputTrackerMasterEndpoint的RpcEndpointRef
- mapStatus:用于维护各个map任务的输出状态。类型为Map[Int,Array[MapStatus]],其中key对应shuffleId,Array存储各个map任务对应的状态信息MapStatus。由于各个MapOutputTrackerWorker会向MapOutputTrackerMaster不断汇报map任务的状态信息,因此MapOutputTrackerMaster的mapStatues中维护的信息是最新最全的。MapOutputTrackerWorker的mapStatuses对于本节点Executor运行的map任务状态是及时更新的,而对于其它节点上的map任务状态则更像一个缓存,在mapStatuses不能命中时会向Driver的MapOutputTrackerMaster获取最新的任务状态信息
- epoch:用于Executor故障转移的同步标记。每个Executor在运行的时候会更新epoch,潜在的附加动作将清空缓存;当Executor丢失后增加epoch
- epochLock:用于保证epoch变量的线程安全性
- fetching:shuffle获取集合。数据类型为HashSet[Int],用来记录当前Executor正在从哪些map输出的位置拉取数据
1.1 询问方法askTracker
askTracker方法用于向MapOutputTrackerMasterEndpoint发送消息,并期望在超时时间之内得到回复
//org.apache.spark.MapOutputTracker
protected def askTracker[T: ClassTag](message: Any): T = {
try {
trackerEndpoint.askWithRetry[T](message)
} catch {
case e: Exception =>
logError("Error communicating with MapOutputTracker", e)
throw new SparkException("Error communicating with MapOutputTracker", e)
}
}根据上述代码,askTracker通过调用NettyRpcEndpointRef的askWithRetry方法实现。
1.2 发送方法sendTracker
sendTracker方法用于向MapOutputTrackerMasterEndpoint发送消息,并期望在超时时间之内获得的返回值为true
//org.apache.spark.MapOutputTracker
protected def sendTracker(message: Any) {
val response = askTracker[Boolean](message)
if (response != true) {
throw new SparkException(
"Error reply received from MapOutputTracker. Expecting true, got " + response.toString)
}
}1.3 getStatuses
getStatuses方法可以根据shuffleId获取MapStatus(即map状态信息)的数组,其实现代码如下:
//org.apache.spark.MapOutputTracker
private def getStatuses(shuffleId: Int): Array[MapStatus] = {
val statuses = mapStatuses.get(shuffleId).orNull
if (statuses == null) {
logInfo("Don't have map outputs for shuffle " + shuffleId + ", fetching them")
val startTime = System.currentTimeMillis
var fetchedStatuses: Array[MapStatus] = null
fetching.synchronized {
while (fetching.contains(shuffleId)) {
try {
fetching.wait()
} catch {
case e: InterruptedException =>
}
}
fetchedStatuses = mapStatuses.get(shuffleId).orNull
if (fetchedStatuses == null) {
fetching += shuffleId
}
}
if (fetchedStatuses == null) {
logInfo("Doing the fetch; tracker endpoint = " + trackerEndpoint)
try {
val fetchedBytes = askTracker[Array[Byte]](GetMapOutputStatuses(shuffleId))
fetchedStatuses = MapOutputTracker.deserializeMapStatuses(fetchedBytes)
logInfo("Got the output locations")
mapStatuses.put(shuffleId, fetchedStatuses)
} finally {
fetching.synchronized {
fetching -= shuffleId
fetching.notifyAll()
}
}
}
logDebug(s"Fetching map output statuses for shuffle $shuffleId took " +
s"${System.currentTimeMillis - startTime} ms")
if (fetchedStatuses != null) {
return fetchedStatuses
} else {
logError("Missing all output locations for shuffle " + shuffleId)
throw new MetadataFetchFailedException(
shuffleId, -1, "Missing all output locations for shuffle " + shuffleId)
}
} else {
return statuses
}
}其执行步骤如下:
- 1)从当前MapOutputTracker的mapStatuses缓存中获取MapStatus数组,若没有就进入第2步,否则直接返回得到的MapStatus数组
- 2)如果shuffle获取集合(即fetching)中已经存在要取的shuffleId(这说明已经有其它线程对此shuffleId的数据进行远程拉取了) ,那么就等待其它线程获取。等待会一直持续,直到fetching中不存在要取的shuffleId(这说明其它线程对此shuffleId的数据进行远程拉取的操作已经结束),并再次从mapStatuses缓存中获取MapStatus数组,此时如果获取到MapStatus数组,则继续第5步
- 3)如果fetchingg中不存在要取的shuffleId,那么当前线程需要将shuffleId加入fetching,以表示已经有线程对此shuffleId的数据进行远程拉取了
- 4)调用askTracker方法向MapOutputTrackerMasterEndpoint发送GetMapOutputStatuses消息,以获取map任务的状态信息。MapOutputTrackerMasterEndpoint接收到GetMapOutputStatuses消息后,将GetMapOutputStatuses消息转换为GetMapOutputMessage消息,再放了mapOutputRequests队列。异步线程MessageLoop从队列中取出GetMapOutputMessage,将请求的map任务状态信息序列化后返回给请求方。请求方接收到map任务状态信息后,调用MapOutputTracker的deserializeMapStatuses方法对map任务状态进行反序列化操作,然后放入本地的mapStatuses缓存中。这次拉取可能成功,也可能失败,所以拉取结束后无论如何都需要将shuffleId从fetching中移除,并唤醒那些在fetching的锁上等待的线程,以便这些线程能够获取自己需要的MapStatus数组。如果拉取成功则继续第5步。
- 5)返回得到的MapStatus数组。
注意:由于多个线程可能会并发访问fetching,因此使用fetching的锁进行同步控制,以确保程序在并发下的安全性。
1.4 getMapSizesByExecutorId
getMapSizesByExecutorId方法可通过shuffleId和reduceId获取存储了reduce所需的map中间输出结果的BlockManager的BlockManagerId,以及map中间输出结果每个Block块的BlockId与大小,其代码如下:
//org.apache.spark.MapOutputTracker
def getMapSizesByExecutorId(shuffleId: Int, reduceId: Int)
: Seq[(BlockManagerId, Seq[(BlockId, Long)])] = {
getMapSizesByExecutorId(shuffleId, reduceId, reduceId + 1)
}
def getMapSizesByExecutorId(shuffleId: Int, startPartition: Int, endPartition: Int)
: Seq[(BlockManagerId, Seq[(BlockId, Long)])] = {
logDebug(s"Fetching outputs for shuffle $shuffleId, partitions $startPartition-$endPartition")
val statuses = getStatuses(shuffleId)
// Synchronize on the returned array because, on the driver, it gets mutated in place
statuses.synchronized {
return MapOutputTracker.convertMapStatuses(shuffleId, startPartition, endPartition, statuses)
}
}上述代码中MapOutputTracker的convertMapStatuses方法用于将Array[MapStatus]转换为Seq[(BlockManagerId, Seq[(BlockId, Long)])]。
1.5 getStatistics
getStatistics方法用于获取shuffle依赖的各个map输出Block大小的统计信息,其实现代码如下:
//org.apache.spark.MapOutputTracker
def getStatistics(dep: ShuffleDependency[_, _, _]): MapOutputStatistics = {
val statuses = getStatuses(dep.shuffleId)
statuses.synchronized {
val totalSizes = new Array[Long](dep.partitioner.numPartitions)
for (s <- statuses) {
for (i <- 0 until totalSizes.length) {
totalSizes(i) += s.getSizeForBlock(i)
}
}
new MapOutputStatistics(dep.shuffleId, totalSizes)
}
}1.6 updateEpoch
当Executor运行出现故障时,Master会再分配其它Executor运行任务,此时会调用updateEpoch方法更新纪元,并且清空mapStatuses
//org.apache.spark.MapOutputTracker
def updateEpoch(newEpoch: Long) {
epochLock.synchronized {
if (newEpoch > epoch) {
logInfo("Updating epoch to " + newEpoch + " and clearing cache")
epoch = newEpoch
mapStatuses.clear()
}
}
}2 MapOutputTrackerMaster的实现原理
通常而言,我们所说的mapOutputTracker都是指MapOutputTrackerMaster,而不是MapOutputTrackerWorker。MapOutputTrackerWorker将map任务的跟踪信息,通过MapOutputTrackerMasterEndpoint的RpcEndpointRef发送给MapOutputTrackerMaster,由MapOutputTrackerMaster负责整理和维护所有的map任务的输出跟踪信息。MapOutputTrackerMasterEndpoint位于MapOutputTrackerMaster内部,二者只存在于Driver上。
为便于理解MapOutputTrackerMaster的实现原理,先分析它的各个属性:
//org.apache.spark.MapOutputTracker
private var cacheEpoch = epoch
private val minSizeForBroadcast =
conf.getSizeAsBytes("spark.shuffle.mapOutput.minSizeForBroadcast", "512k").toInt
private val shuffleLocalityEnabled = conf.getBoolean("spark.shuffle.reduceLocality.enabled", true)
protected val mapStatuses = new ConcurrentHashMap[Int, Array[MapStatus]]().asScala
private val cachedSerializedStatuses = new ConcurrentHashMap[Int, Array[Byte]]().asScala
private val maxRpcMessageSize = RpcUtils.maxMessageSizeBytes(conf)
private val cachedSerializedBroadcast = new HashMap[Int, Broadcast[Array[Byte]]]()
private val shuffleIdLocks = new ConcurrentHashMap[Int, AnyRef]()
private val mapOutputRequests = new LinkedBlockingQueue[GetMapOutputMessage]
private val threadpool: ThreadPoolExecutor = {
val numThreads = conf.getInt("spark.shuffle.mapOutput.dispatcher.numThreads", 8)
val pool = ThreadUtils.newDaemonFixedThreadPool(numThreads, "map-output-dispatcher")
for (i <- 0 until numThreads) {
pool.execute(new MessageLoop)
}
pool
}- cacheEpoch:对MapOutputTracker的epoch的缓存
- minSizeForBroadcast:用于广播的最小大小。可以使用spark.shuffle.mapOutput.minSizeForBroadcast属性配置,默认为512KB。minSizeForBroadcast必须小于maxRpcMessageSize。
- shuffleLocalityEnabled:是否为reduce任务计算本地性的偏好。可以使用spark.shuffle.reduceLocality.enabled属性进行配置,默认为true。
- mapStatuses:用于存储shuffledId与Array[MapStatus]的映射关系。由于Mapstatus维护了map输出Block的地址BlockManagerId,所以reduce任务知道从何处获取map任务的中间输出。
- cachedSerializedStatuses:用于存储shuffledId与序列化后的状态的映射关系。其中key对应shuffleId,value为对MapStatus序列化后的字节数组
- maxRpcMessageSize:最大的Rpc消息的大小。此属性可以通过spark.rpc.message.maxRpcMessageSize属性进行配置,默认为128MB。minSizeForBroadcast必须小于maxRpcMessageSize,maxRpcMessageSize实际通过调用RpcUtils的maxMessageSizeBytes方法获得。
- cachedSerializedBroadcast:用于缓存序列化的广播变量,保持与achedSerializedStatuses的同步。当需要移除shuffleId在cachedSerializedStatues中的状态数据时,此缓存中的数据也会被移除。
- shuffledIdLocks:每个shuffledId对应的锁。当shuffle过程开始时,会有大量的关于同一个shuffle的请求,使用锁可以避免对同一shuffle的多次序列化。
- mapOutputRequests:使用阻塞队列来缓存GetMapOutputMessage(获取map任务输出)的请求
- threadpool:用于获取map输出的固定大小的线程池。此线程池提交的线程都以后台线程运行,且线程名以map-output-dispatcher为前缀,线程池大小可以使用spark.shuffle.mapOutput.dispatcher.numThreads属性配置,默认大小为8。
2.1 MapOutputTrackerMaster的运行原理
在创建MapOutputTrackerMaster的最后,会创建对map输出请求进行处理的线程池threadpool,其代码如下:
//org.apache.spark.MapOutputTracker
private val threadpool: ThreadPoolExecutor = {
val numThreads = conf.getInt("spark.shuffle.mapOutput.dispatcher.numThreads", 8)
val pool = ThreadUtils.newDaemonFixedThreadPool(numThreads, "map-output-dispatcher")
for (i <- 0 until numThreads) {
pool.execute(new MessageLoop)
}
pool
}根据代码,创建threadpool线程池的步骤如下:
- 1)获取此线程池的大小numThread。此线程池的大小默认为8,也可以使用spark.shuffle.mapOutput.dispatcher.numThread属性配置
- 2)创建线程池。此线程池是固定大小的线程池,并且启动的线程都以后台线程方式运行,且线程名以map-output-dispatcher为前缀
- 3)启动与线程池大小相同的线程,每个线程执行的任务都是MessageLoop
- 4)返回此线程池的引用
上述线程池threadpool的创建与《Spark执行环境——RPC环境》介绍的消息调度器Dispatcher内的线程池threadpool从命名和方式上非常相似,而且此处启动的任务也是MessageLoop。不过这里的MessageLoop并非是Dispatcher中的MessageLoop,而MapOutputTrackerMaster的内部类。MapOutputTrackerMaster中的MessageLoop也实现了Java的Runnable接口,其实现代码如下:
//org.apache.spark.MapOutputTracker
private class MessageLoop extends Runnable {
override def run(): Unit = {
try {
while (true) {
try {
val data = mapOutputRequests.take()
if (data == PoisonPill) {
// Put PoisonPill back so that other MessageLoops can see it.
mapOutputRequests.offer(PoisonPill)
return
}
val context = data.context
val shuffleId = data.shuffleId
val hostPort = context.senderAddress.hostPort
logDebug("Handling request to send map output locations for shuffle " + shuffleId +
" to " + hostPort)
val mapOutputStatuses = getSerializedMapOutputStatuses(shuffleId)
context.reply(mapOutputStatuses)
} catch {
case NonFatal(e) => logError(e.getMessage, e)
}
}
} catch {
case ie: InterruptedException => // exit
}
}
}根据上述代码,MessageLoop在循环过程中不断对新的消息进行处理。每次的循环中的逻辑如下:
- 1)从mapOutputRequests中获取GetMapOutputMessage。由于mapOutputRequests是个阻塞队列,所以当mapOutputRequests中没有GetMapOutputMessage时,MessageLoop线程会被阻塞。GetMapOutputMessage是个样例类,包含了shuffleId和RpcCallContext两个属性,RpcCallContext用于服务端回复客户端,其实现如下:
//org.apache.spark.MapOutputTracker
private[spark] case class GetMapOutputMessage(shuffleId: Int, context: RpcCallContext)- 2)如果取到的GetMapOutputMessage是个PoisonPill(英译为“毒药”),那么此MessageLoop线程将退出(通过return语句)。这个有个动作,谅是将PoisonPill重新放入到mapOutputRequests中,这是因为threadpool线程池极有可能不止一个MessageLoop线程,为了让大家都“毒发身亡”,还需要把“毒药”放回到receivers中,这样其它“活着”的线程就会再次误食“毒药”,达到所有MessageLoop线程都结束的效果。
- 3)如果取到的GetMapOutputMessage不是“毒药”,那么调用getSerializedMapOutputStatuses方法获取GetMapOutputMessage携带的shuffleId所对应的序列任务状态信息
- 4)调用RpcCallContext的回调方法reply,将序列化的map任务状态信息返回给客户端(即其它节点的Executor)
MessageLoop任务执行的第3步调用了getSerializedMapOutputStatuses方法获取序列化任务状态信息,其具体实现如下:
//org.apache.spark.MapOutputTracker
def getSerializedMapOutputStatuses(shuffleId: Int): Array[Byte] = {
var statuses: Array[MapStatus] = null
var retBytes: Array[Byte] = null
var epochGotten: Long = -1
def checkCachedStatuses(): Boolean = {
epochLock.synchronized {
if (epoch > cacheEpoch) {
cachedSerializedStatuses.clear()
clearCachedBroadcast()
cacheEpoch = epoch
}
cachedSerializedStatuses.get(shuffleId) match {
case Some(bytes) =>
retBytes = bytes
true
case None =>
logDebug("cached status not found for : " + shuffleId)
statuses = mapStatuses.getOrElse(shuffleId, Array[MapStatus]())
epochGotten = epoch
false
}
}
}
if (checkCachedStatuses()) return retBytes
var shuffleIdLock = shuffleIdLocks.get(shuffleId)
if (null == shuffleIdLock) {
val newLock = new Object()
val prevLock = shuffleIdLocks.putIfAbsent(shuffleId, newLock)
shuffleIdLock = if (null != prevLock) prevLock else newLock
}
shuffleIdLock.synchronized {
if (checkCachedStatuses()) return retBytes
val (bytes, bcast) = MapOutputTracker.serializeMapStatuses(statuses, broadcastManager,
isLocal, minSizeForBroadcast)
logInfo("Size of output statuses for shuffle %d is %d bytes".format(shuffleId, bytes.length))
epochLock.synchronized {
if (epoch == epochGotten) {
cachedSerializedStatuses(shuffleId) = bytes
if (null != bcast) cachedSerializedBroadcast(shuffleId) = bcast
} else {
logInfo("Epoch changed, not caching!")
removeBroadcast(bcast)
}
}
bytes
}
}根据代码,getSerializedMapOutputStatuses方法的执行步骤如下:
- 1)调用checkCachedStatuses检查cachedSerializedStatuses中是否有shuffleId所对应的序列化的任务状态信息。如果有,则从cachedSerializedStatuses中获取序列化的任务状态信息后返回,否则进入第2步
- 2)从shuffledIdLocks中获取shuffleId对应的锁,如果没有,就新建一个对象作为锁放入shuffleIdLocks中
- 3)获取mapStatuses中缓存的MapStatus数组,然后调用MapOutputTracker的serializeMapStatuses方法将MapStatus数组序列化,最后调用BroadcastManager的newBroadcast方法将序列化MapStatus数组后产生的字节数组进行广播。serializeMapStatuses方法将返回序列化的MapStatus(即bytes)和广播对象bcast的对偶
- 4)如果当前epoch没有发生变化,将shuffleId与序列化的MapStatus之间的映射关系放入cacheSerializedStatuses,并将shuffleId与广播对象bcast之间的映射关系放入cachedSerializedBroadcast
- 5)如果当前epoch已经发生变化,则不需要对bytes和bcast进行缓存,同时调用removeBroadcast方法删除广播对象bcast
MapOutputTrackerMaster中的MessageLoop任务在不断地消费着阻塞队列mapOutputRequests中的GetMapOutputMessage,那么GetMapOutputMessage的来源在哪里?GetMapOutputMessage又是如何放入mapOutputRequests中的呢?MapOutputTrackerMaster中要将GetMapOutputMessage放入mapOutputRequests,主要通过调用MapOutputTrackerMaster的post方法,其实现代码如下:
//org.apache.spark.MapOutputTracker
def post(message: GetMapOutputMessage): Unit = {
mapOutputRequests.offer(message)
}MapOutputTrackerMasterEndpoint组件用于接收获取map中间状态和停止对map中间状态进行跟踪的请求,它实现了特质RpcEndpoint并重写了receiveAndReply方法,代码如下:
//org.apache.spark.MapOutputTracker
private[spark] class MapOutputTrackerMasterEndpoint(
override val rpcEnv: RpcEnv, tracker: MapOutputTrackerMaster, conf: SparkConf)
extends RpcEndpoint with Logging {
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case GetMapOutputStatuses(shuffleId: Int) =>
val hostPort = context.senderAddress.hostPort
logInfo("Asked to send map output locations for shuffle " + shuffleId + " to " + hostPort)
val mapOutputStatuses = tracker.post(new GetMapOutputMessage(shuffleId, context))
case StopMapOutputTracker =>
logInfo("MapOutputTrackerMasterEndpoint stopped!")
context.reply(true)
stop()
}
}由上述代码可看到,MapOutputTrackerMasterEndpoint将接收两种类型的请求
- 获取map中间输出状态。当接收到GetMapOutputStatuses消息(主要由MapOutputTracker的getStatuses调用askTracker产生)后,将调用MapOutputTrackerMaster的post方法投递GetMapOutputMessage类型的消息
- 停止map中间输出的跟踪。首先回调RpcCallContext的reply方法向客户端返回true,然后调用MapOutputTrackerMaster的stop方法停止MapOutputTrackerMaster。
根据上面一系列的分析,可用下图表示MapOutputTrackerMaster的运行原理:
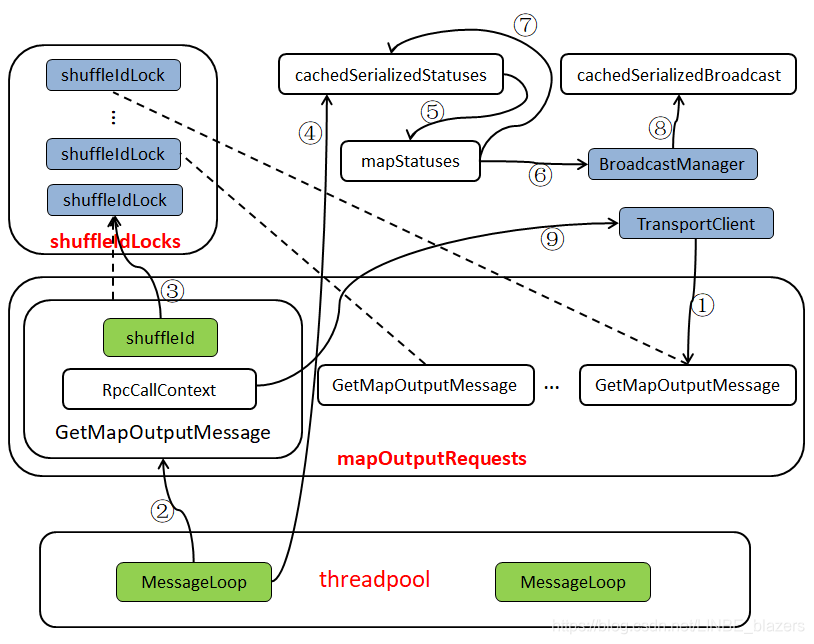
- 序号①:表示某个Executor调用MapOutputTrackerWorker的getStatuses方法获取某个shuffle的map任务状态信息,当发现本地的mapStatuses没有相应的缓存,则调用askTracker方法发送GetMapOutputStatuses消息。其中askTracker实际是通过MapOutputTrackerMasterEndpoint的NettyRpcEndpointRef向远端发送GetMapOutputStatuses消息,发送实现依托于NettyRpcEndpointRef持有的TransportClient。MapOutputTrackerMasterEndpoint在接收到GetMapOutputStatuses消息后,将GetMapOutputMessage消息放入mapOutputRequest队尾。
- 序号②:表示MessageLoop线程从mapOutputRequests队头取出GetMapOutputMessage
- 序号③:表示从shuffledIdLocks数组中取出与当前GetMapOutputMessage携带的shuffleId相对应的锁
- 序号④:表示首先从cachedSerializedStatuses缓存中获取shuffleId对应的序列化任务状态信息
- 序号⑤:表示当cachedSerializedStatuses中没有shuffleId对应的序列化任务状态信息,则获取mapStatuses中缓存的shuffleId对应的任务状态数组
- 序号⑥:表示将任务状态数组进行序列化,然后使用BroadcastManager对序列化的任务状态进行广播
- 序号⑦:表示将序列化的任务状态放入cachedSerializedStatuses缓存中
- 序号⑧:表示将广播对象放入cachedSerializedBroadcast缓存中
- 序号⑨:表示将获得的序列化任务状态信息,通过回调GetMapOutputMessage消息携带的RpcCallContext的reply方法回复客户端
2.2 Shuffle的注册
DAGScheduler在创建ShuffleMapStage的时候,将调用MapOutputTrackerMaster的containsShuffle方法,查看是否已经存在shuffleId对应的MapStatus。如果MapOutputTrackerMaster中未注册此shuffleId,那么调用MapOutputTrackerMaster的registerShuffle方法注册shuffleId。
containShuffle方法用于查找MapOutputTrackerMaster的cachedSerializedStatuses或mapStatuses中是否已经注册了shuffleId。其实现代码如下:
//org.apache.spark.MapOutputTracker
def containsShuffle(shuffleId: Int): Boolean = {
cachedSerializedStatuses.contains(shuffleId) || mapStatuses.contains(shuffleId)
}registerShuffle方法用于向MapOutputTrackerMaster的mapStatuses中注册shuffleId与对应的MapStatus的映射关系:
//org.apache.spark.MapOutputTracker
def registerShuffle(shuffleId: Int, numMaps: Int) {
if (mapStatuses.put(shuffleId, new Array[MapStatus](numMaps)).isDefined) {
throw new IllegalArgumentException("Shuffle ID " + shuffleId + " registered twice")
}
// add in advance
shuffleIdLocks.putIfAbsent(shuffleId, new Object())
}根据上述代码,注册shuffleId时,shuffleId在mapStatuses中对应的是以map任务数量作为长度的数组,此数组将用于保存MapStatus。注册了Shuffle,那么MapStatus是何时保存的呢?当ShuffleMapStage内的所有ShuffleMapTask运行成功后,将调用MapOutputTrackerMaster的registerMapOutputs方法。registerMapOutputs方法的实现如下:
//org.apache.spark.MapOutputTracker
def registerMapOutputs(shuffleId: Int, statuses: Array[MapStatus], changeEpoch: Boolean = false) {
mapStatuses.put(shuffleId, Array[MapStatus]() ++ statuses)
if (changeEpoch) {
incrementEpoch()
}
}根据上述代码,registerMapOutputs方法将把ShuffleMapStage中每个ShuffleMapTask的MapStatus保存到shuffleId在mapStatuses中对应的数组中。
整个Shuffle的注册流程可用下图表示:
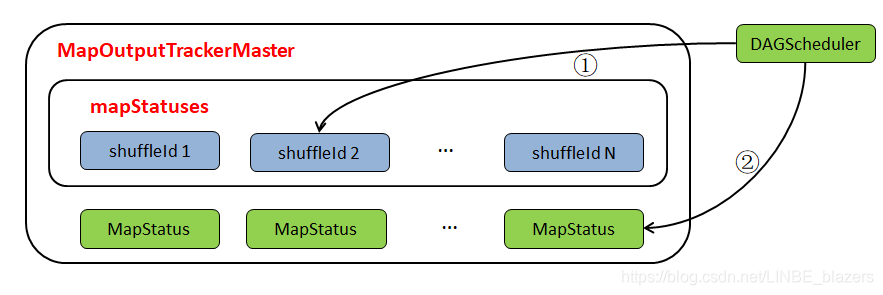
其处理步骤包括如下:
- 序号①:表示DAGScheduler在创建了ShuffleMapState后,调用MapOutputTrackerMaster的registerShuffle方法向mapStatuses缓存注册ShuffleId
- 序号②:表示DAGScheduler处理ShuffleMapTask的执行结果时,如果发现ShuffleMapTask所属的shuffleMapStage中每一个分区的ShuffleMapTask都执行成功了,那么将调用MapOutputTrackerMaster的registerMapOutputs方法,将ShuffleMapStage中每一个ShuffleMapTask的MapStatus保存到shuffleId对应的MapStatus数组中

















 4573
4573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









