







线性表-链表
线性表:每一个元素有一个前驱和一个后继,就是前面有一个节点,后面有一个节点,在一条线上。

假设内存有100M,随着程序的运行,一块一块被分配出去了。

现在在100M的内存上,内存都被进程在运行过程中分配走了
内存是一块一块分配出去,但是不是紧挨着一个一个释放
因为每一块内存都有它所属的应用的一些业务,业务执行完了,这块内存没有用了,才释放。假如说这块40M的内存所属的业务执行的周期比较长,所以释放比较慢,假如红色的这块内存和绿色的内存的业务执行完了,这两块内存就都释放掉了,交还给系统了,这就是堆内存的碎片。

实际上,我们这个内存剩余的空间,总共有20+10=30M空闲的内存空间,但是,现在如果我们这个进程运行过程中,需要一个线性表来存储一组数组,需要25M的连续开辟的空间的数组,我们就不能分配一块25M的连续空间了,数组是要求内存是绝对连续的。
在malloc堆内存的时候,是连续分配的,但是因为各块内存块的业务执行的周期长短不同,导致释放各自的内存块不是挨个释放的,有几个内存块释放了,有几个内存块还没有释放,从而产生了内存碎片化。
碎片化导致空闲的内存没有办法连到一块,内核会进行一些内存碎片的处理。
总之,此时我们在内存碎片比较多的情况下去开辟大内存数组,往往是开辟失败的。整个空闲的空间是有,但是连续的大的空间不一定有。
此时,就有了链表存在的意义了。
链表里的每个元素节点都是独立分配的,独立new出来的节点
可以在20M的空闲内存空间分配一些,在10M的空闲内存空间分配一些,总共可以凑够存放25M的节点空间。

链表里的每个节点是独立分配的,怎么从这个节点找到下一个节点?
每个节点(Node)存储的是数据域和指针域, 数据域存储元素的值,指针域存储下一个节点的地址



单链表,最后一个节点的地址域是nullptr。
Node的类型:


单链表的节点定义
单链表:只能从当前节点跳到下一个节点,只能往后遍历,但是不能跳到上一个节点。

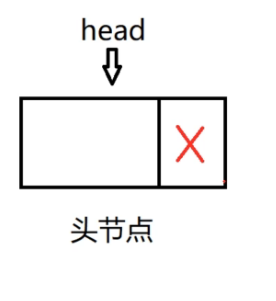
我们在实际写单链表的代码中,经常会给单链表初始化一个东西:头节点
head指针指向头节点,头节点的地址域初始化为空,当我们新增加1个节点,也就是链表中的第一个节点,会把第一个节点的地址写到头节点的地址域,这样就把两个节点连起来了。

哪怕这个链表是空的,但是都有一个头结点,这样方便操作
//节点类型
struct Node
{
Node(int data = 0) :data_(data), next_(nullptr) {}
int data_;
Node* next_;
};
单链表的构造函数和析构函数
public:
Clink()
{
//给head_初始化指向头节点
head_ = new Node();
}
~Clink()
{
//节点的释放
Node* p = head_;
while (p != nullptr)
{
head_ = head_->next_;
delete p;
p = head_;
}
head_ = nullptr;
}
private:
Node* head_;//指向链表的头节点
头节点没有存储有效的元素,不是链表的有效信息,其数据域不用存储什么有效的元素。
单链表尾插法
每次插入元素,都放在链表的尾部
1、先找到当前链表的末尾节点

我们现在要把新生成的20这个节点插到尾部去,也就是68的后面
我们要先找到68
我们只能从入口:头节点开始遍历,依次向后找,找到尾节点,尾节点的特征是:地址域是nullptr

我们会定义1个指针p,指向头节点,判断

头节点的next域不为空,p指向p的next,

以此类推下去。
当p到达第3个节点的时候,判断其next是nullptr,即当前指向的节点就是尾节点,跳出循环体

2、生成新节点
3、把新节点的地址挂在尾节点的next域

链表如果原来是没有有效节点的话:不会进入while循环。头节点的next存储新生成的节点的地址。
//链表尾插法 O(n) head_:头节点 tail_:尾节点
void InsertTail(int val)
{
//先找到当前链表的末尾节点
Node* p = head_;
while (p->next_ != nullptr)
{
p = p->next_;
}
//生成新节点
Node* node = new Node(val);
//把新节点挂在尾节点的后面
p->next_ = node;
}
单链表头插法
把新生成的节点插在原来的第一个有效节点的位置,原来第一个有效节点就变成第二个有效节点了,原来第二个有效节点就变成第三个有效节点了
1、生成1个新节点
2、头节点的next域不能再存储原来的第一个有效节点的地址了,一个存储45这个节点的地址了。

3、把新节点的next地址域存储原来的第一个有效节点的地址(所以我们要先通过把head->next,即原来的第一个有效节点的地址先赋值给新生成节点的next域,然后再把头节点的next域指向新生成的节点)



新生成的节点的地址域肯定是nullptr,因为构造的初始化就是nullptr
上面代码思路在只有头节点的空链表头插也行得通
先修改新增加的节点,再修改原来链表中头节点的地址域
//链表的头插法 O(1)
void InsertHead(int val)
{
Node* node = new Node(val);
node->next_ = head_->next_;
head_->next_ = node;
}
头插法每次插的都是第一个节点,也就是头插法插出来的链表,在输出的时候和我们输入的顺序是相反的 O(1)
尾插法每次插的都是当前链表的末尾,也就是尾插法插出来的链表,在输出的时候和我们输入的顺序是一样的 O(n)(while循环,从头节点开始一个一个找,遍历一遍,找到尾节点)
实际上,我们在参加的时候,为了提高尾插法的效率,我们一般会定义2个指针,1个指针指向头节点,1个指针指向尾节点
这样在进行尾插法的时候就可以直接指向尾节点
单链表打印
//链表打印
void Show()
{
Node* p = head_->next_;//p指向了第一个有效节点
while (p != nullptr)
{
cout << p->data_ << " ";
//从第一个有效节点打印到最后一个节点
p = p->next_;
}
cout << endl;
}
注意:
如果我们要寻找的是尾节点,采用p->next判断为不为空。
如果我们要打印全部节点,采用p判断为不为空就可以了。
删除值为val的第一个节点

比如说我们现在要删除52这个节点,
1、我们要做的第一件事是遍历链表,从头结点开始搜索下去,找到52这个节点。(因为头节点不存放有效数据,所以我们定义p=head->next,从第一个有效节点开始遍历寻找)

2、判断

3、找到了52这个节点了,现在要删除它
删除的步骤:
1.把当前要删除节点的前一个节点的next指向当前要删除节点的下一个节点。


2.delete p;

当p指针指向了待删除的节点,下一个节点的地址怎么访问?不就在当前要删除的节点的next域吗?现在要修改的是待删除节点的前一个节点的next域,因为是单链表,所以只能向后遍历,不能向前回退。而且链表中每一个节点是单独new出来的,内存是不连续的,不能p- -访问哦!
所以我们还要定义一个指针指向待删除节点的前驱节点。

q指针永远跟在p指针指向的节点的前面那个节点
p往后走,q跟着往后走。

此时,进行52这个节点的删除操作就好办了


//链表节点的删除 删除链表中值为val的第一个节点
void Remove(int val)
{
Node* q = head_;
Node* p = head_->next_;
while (p != nullptr)
{
if (p->data_ == val)//找到了
{
//删除一个节点本身的操作是O(1)
q->next_ = p->next_;
delete p;
return;
}
else
{
q = p;
p = p->next_;
}
}
}
删除链表中所有值为val的节点
在前面所述,我们delete52这个元素节点后,如果想继续循环删除的话,q依然指向的是有效的节点,但是p被delete了,而while是判断p为不为空,来遍历节点的。p现在是野指针了,p存储的地址对应的堆内存已经还给内存了,如果想继续循环删除的话,我们要把p指向q->next就可以了



这样就可以继续向下遍历,删除元素了
//删除值为val的所有节点
void RemoveAll(int val)
{
Node* q = head_;
Node* p = head_->next_;
while (p != nullptr)
{
if (p->data_ == val)
{
q->next_ = p->next_;
delete p;
//对指针p进行重置
p = q->next_;
}
else
{
q = p;
p = p->next_;
}
}
}
单链表的析构


这个写法是错误的,因为p已经被delete,p指向的节点内存已经还给系统了,这个节点原先占用的内存很有可能马上被系统分配给其他的进程了。
就不能访问野指针指向的next了,内存非法访问了
所以,我们应该这样写:




~Clink()//析构函数
{
//节点的释放
Node* p = head_;
while (p != nullptr)
{
head_ = head_->next_;
delete p;
p = head_;
}
head_ = nullptr;//野指针置空
}
单链表的搜索

p为nullptr,跳出循环

单链表搜索必须是从头节点开始,一个一个遍历,搜索下去,是线性搜索,时间复杂度是O(n)
//搜索 list O(n)
bool Find(int val)
{
Node* p = head_->next_;//指向第一个有效的节点
while (p != nullptr)
{
if (p->data_ == val)
{
return true;
}
else
{
p = p->next_;
}
}
return false;
}
单链表总结
#include <iostream>
#include <stdlib.h>
#include <time.h>
using namespace std;
//节点类型
struct Node
{
Node(int data = 0) :data_(data), next_(nullptr) {}
int data_;
Node* next_;
};
//单链表代码实现
class Clink
{
public:
Clink()//构造函数
{
//给head_初始化指向头节点
head_ = new Node();
}
~Clink()//析构函数
{
//节点的释放
Node* p = head_;
while (p != nullptr)
{
head_ = head_->next_;
delete p;
p = head_;
}
head_ = nullptr;
}
public:
//链表尾插法 O(n) head_:头节点 tail_:尾节点
void InsertTail(int val)
{
//先找到当前链表的末尾节点
Node* p = head_;
while (p->next_ != nullptr)
{
p = p->next_;
}
//生成新节点
Node* node = new Node(val);
//把新节点挂在尾节点的后面
p->next_ = node;
}
//链表的头插法 O(1)
void InsertHead(int val)
{
Node* node = new Node(val);
node->next_ = head_->next_;
head_->next_ = node;
}
//链表节点的删除
void Remove(int val)
{
Node* q = head_;
Node* p = head_->next_;
while (p != nullptr)
{
if (p->data_ == val)//找到了
{
//删除一个节点本身的操作是O(1)
q->next_ = p->next_;
delete p;
return;
}
else
{
q = p;
p = p->next_;
}
}
}
//删除多个节点
void RemoveAll(int val)
{
Node* q = head_;
Node* p = head_->next_;
while (p != nullptr)
{
if (p->data_ == val)
{
q->next_ = p->next_;
delete p;
//对指针p进行重置
p = q->next_;
}
else
{
q = p;
p = p->next_;
}
}
}
//搜索 list O(n)
bool Find(int val)
{
Node* p = head_->next_;//指向第一个有效的节点
while (p != nullptr)
{
if (p->data_ == val)
{
return true;
}
else
{
p = p->next_;
}
}
return false;
}
//链表打印
void Show()
{
Node* p = head_->next_;//p指向了第一个有效节点
while (p != nullptr)
{
cout << p->data_ << " ";
p = p->next_;//从第一个有效节点打印到最后一个节点
}
cout << endl;
}
private:
Node* head_;//指向链表的头节点
};
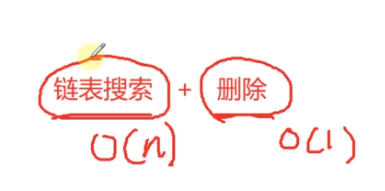

链表是不支持随机访问,下标访问的
数组在搜索的话,内存是连续的,代码输出方便,而且如果数组中的数据是有序的,可以进行二分搜索。
分布式设计:不同的方法设计,永远只能同时满足其中2个条件,不可能在分布式系统同时满足3个条件

















 3787
3787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











