







float和double
存储的是近似值,因为有精度这一说。


在32位编译器或者64位编译器,都是4,8

float和double的内存存储
浮点数怎么存?
1、把小数点左边的整数部分和小数点右边的小数部分分别转成二进制
方法1:


方法2:


比较浮点数的大小,这样写是错误的:

因为浮点数存储的是近似值,所以这样比较不准确!!!
举个例子:10.65

尽头是:乘完只剩下整数部分了。但是上面这样就无限循环起来了!!!

但是float和double定义的类型的大小是有限的,不可能去存储这种没完没了的内容,所以只能存储0.65的近似值。
所以在浮点数比较的时候,要加上精度的控制!!!
2、


小数点左边的那个1不用存储,因为大家都一样啊。

指数:因为要表示正数的指数和负数的指数
所以我们要加上127,正数就是比127大,负数就是比127小
127的二进制是0111 1111
如果指数是3,就是给0111 1111加3次1
底数:我们算出来的二进制是什么就存什么进去,然后后面补上0,凑够23位:

因为10.65,小数部分0.65变成二进制是无穷无尽的,所以我们只能存近似值。

我们打开调试来看看:
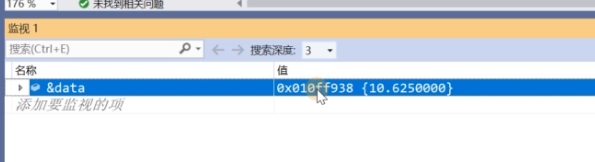
我们在内存上看看:

左边这一列,显示的是内存的地址,从上到下,地址是从低到高
同一行:16进制下,2个数字表示1个字节。
同一行的地址,从左向右是低到高


我们的系统都是小端模式

所以我们在写的时候,肯定是右边是低字节,左边是高字节,所以小端模式下,我们把低地址的数据写在右边。(低地址,低字节)

我们把16进制转成2进制表示如下:

我们把结果和前面分析的比对看看,是不是一样的:

分析10.65
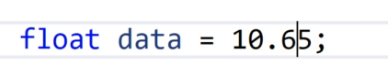
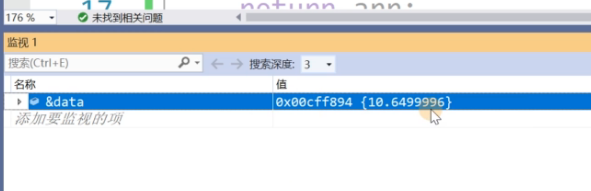

转成2进制


double精度更高

浮点数的精度问题和常见错误

底数存储的是在内存中最大的有效位数(float:2^23, double:2^52)。

float最大支持的有效数字位数是7位。double是16位。



感觉好像是一样,我们控制一下输出的位数:

这就区分开了,有效数字的位数是不一样的!


进不去if语句,因为C/C++编译器做运算的时候,要保证类型是一致的。
在比较运算的时候,关系运算符的左边是float类型,右边是double类型,所以左边的float肯定要转成double类型,float只能表示7位有效位,硬转成16位的话,后边的数字就不可控了!!!
到底如何比较呢?
下一篇博客叙述!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











