







KMP算法讲解1

有很多部分匹配的情况下,KMP算法最合适,体现优势
在布鲁特-福斯算法的基础上,进行如下改进:每当匹配过程中出现相比较的字符不相等时,不需要回溯主串字符的位置指针,而是利用已经得到的“部分匹配”的结果,将模式串向右“滑动”尽可能远的距离,再继续进行比较。
KMP 算法是一种改进的字符串匹配算法,由 D.E.Knuth,J.H.Morris 和 V.R.Pratt同时发现,因此人们称它为克努特——莫里斯——普拉特操作(简称 KMP 算法)。
KMP 算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是实现一个 next()函数,函数本身包含了模式串的局部匹配信息。时间复杂度 O(m+n)。

图解过程
给定主串“ABCDABCDABBABCDABCDABDD”,子串“ABCDABD”。
1、第一趟比较,先 A,然后比较 BCDABD。

2、第二趟比较,由于前一趟比较到字符 D 时,不匹配,KMP 算法要求主串不回退位置。所以要子串进行相应的处理,从主串的位置找子串之前可以匹配的“子串”。
图示如下:

所找到的“子串”为“AB”,应当是可以匹配的最长子串。所以从原子串的 AB 后
进行后面的比较。直至下一个不匹配,即 D。

3、第三趟比较,从原子串中去找之前可以匹配的最长子串,即 AB。


然后再以此往后进行比较 CDABD,由于第一个 C 就不匹配就只能结束本趟,再去找可以匹配最长子串。
没有最长子串,那就从原子串的第一个重新开始比较。
4、第四趟比较,第一个字符就不匹配,之前就没有最长子串。下一个从原子串的第一个位置开始比较。

5、第五趟比较,依次可以比较 ABCDAB。

直至最后一个字符 D,不匹配。

6、第六趟比较,在前一趟的基础上找最长子串,即为 AB,从原子串的这个位置后开始比较。

一直往后比较,直至原子串中的所有字符都被比较后,说明找到了匹配的子串的位置。

求找可匹配的最长子串的解决办法
字符串的前缀:是指从字符串第一个字符开始,到最后一个字符之前(不包含最后一个字符)结束的可能情况。
字符串的后缀:是指从字符串第一个字符之后(不含第一个字符)开始,到最后一个字符结束的可能情况。

-1 表示不存在,0 表示存在且长度为 1,1 表示存在且长度为 2,……。
给定子串“ABCDABD”,可能的“子串”情况如下

最长公共子串就是这个子串的前缀的所有情况和后缀的所有情况中比对,有没有相同的最长的串

比如说,如果我们比对,找到子串最后一个位置D和主串的位置不相同的话,
我们就回退一下,看“ABCDAB"当中有没有可以局部匹配的信息
最长公共串是AB
2个长度,然后我们把子串的第2+1个元素后移到当前比对失败的元素的位置上,然后开始和主串比较。
如果比到不相同了,就看此时比对好的子串的部分的除去当前和主串不一样的元素,前面的部分进行看,有没有最长公共子串,然后把子串的第(最长公共子串的长度+1)的元素后移到当前比对失败的元素的位置上。
如果没有最长子串,那就从在当前位置把子串从头进行和主串当前位置往后比较。
/****************************************************************
* 函数名称:getNext
* 功能描述:得到模式串中的局部匹配信息
* 参数说明:next, 局部匹配信息的结果数组
* sub, 模式串
* 返 回 值:void
*****************************************************************/
void getNext(int *next, const char *sub)
{
next[0] = -1;//一开始初始化为0 ,代表没有公共子串
int k = -1;//表示回退的个数,即最长公共子串的长度-1
int len = strlen1(sub);
for (int i = 1; i < len; i++)//对next数组进行赋值
{
while (sub[k+1]!=sub[i] && k>-1)
{//如果下一个不相同,往前回溯,等于前一个值 。
k = next[k];
}
if (sub[k+1] == sub[i])
{
k = k + 1;//第一次肯定相同,但是只有1个元素,没有公共子串 next[0]=-1
}
next[i] = k;
}
}

/****************************************************************
* 函数名称:searchKMP
* 功能描述:KMP算法的模式匹配
* 参数说明:src, 主串
* sub, 模式串
* 返 回 值:-1表示没有找到匹配的模式串,非-1的值,表示在主串中的位置
*****************************************************************/
int searchKMP(const char *src, const char *sub)
{
int slen = strlen1(src);
int tlen = strlen1(sub);
//得到next
int *next = (int *)malloc(sizeof(int)*tlen);
getNext(next, sub);
//模式匹配
int k = -1;
for (int i = 0; i < slen; i++)
{
//判断当前要不要回退
while (k>-1 && sub[k+1] != src[i])
{//回溯
k = next[k];
}
if (src[i] == sub[k+1])
{
++k;
}
if (k == tlen - 1)
{
free(next);
next = NULL;
return i - tlen + 1;
}
}
free(next);
next = NULL;
return -1;
}

代码实现
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
void GetNext(const char *p, int *next)//获取k的值
{
next[0] = -1;
next[1] = 0;
int lenp = strlen(p);
int i = 1;
int k = 0;
while (i + 1 < lenp)
{
if (k == -1 || p[i] == p[k])
{
next[++i] = ++k;
/*
next[i + 1] = k + 1;
i++;
k++;
*/
}
else
{
k = next[k];
/*
if (k == -1)
{
next[i + 1] = k+1;
i++;
k++;
}
*/
}
}
}
// 时间复杂度O(n+m) 空间复杂度O(m)
int KMP(const char *s, const char *p, int pos)//KMP算法的实现
{
int lens = strlen(s);
int lenp = strlen(p);
if (s == NULL || p == NULL || lenp > lens) return -1;
int i = pos;
int j = 0;
int *next = (int *)malloc(sizeof(int) * lenp);
assert(next != NULL);
GetNext(p, next);
while (i < lens && j < lenp)
{
if (j == -1 || s[i] == p[j])
{
i++;
j++;
}
else
{
j = next[j];
/*
if (j == -1)
{
i++;
j++;
}
*/
}
}
free(next);
if (j == lenp)
{
return i - j;
}
return -1;
}
int main()
{
const char *s = "ababcabcdabcde";
const char *p = "abcd";
printf("%d\n", KMP(s, p, 6));
return 0;
}
BF算法的缺点和KMP算法讲解2
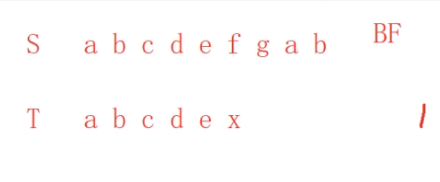

第2,3,4,5次的比较是纯属浪费时间,因为肯定不相等。
因为原本对应的abcde是相等的,现在进行第二次比较的时候回到主串的第2个位置开始比较下去,肯定是不相等的。
因为BF算法对我们在字符比较失败之前的比对成功的字符信息没有存储,每次就是回退到原来比较的位置上后一个位置开始重新比较。
我们应该在第1步比较失败后,不应该动i,主串位置不动,让子串跳到第6步比较的位置开始比较。


我们再看一个例子:
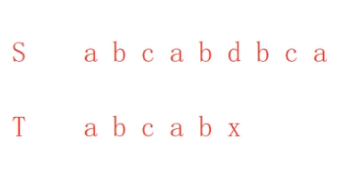




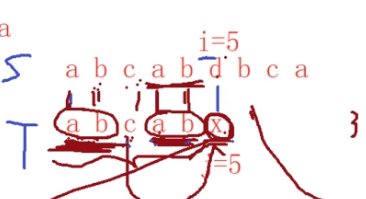
比较失败,把j重置为2
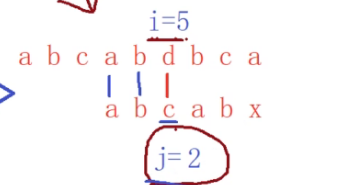
x的前缀:
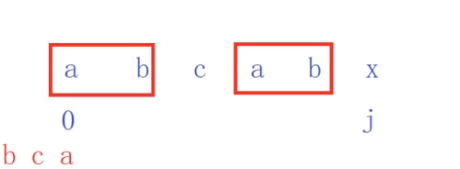
我们给出这么一个范围:
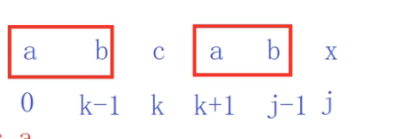
x的前面字符串的前后缀位置关系:
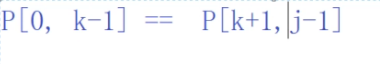


求出:前后缀的长度是2 k=2
所以当d和x比对失败后,此时i不变,然后就是把子串中j=k=2的字符后移到当前比对失败的x的位置上


next数组
下面2个字符串比较
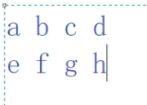
如果第一次比较就失败了,next[0]=-1
此时主串i也要往后加1下。
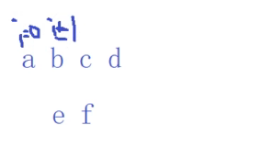


如果第一个比对就失败了,k=-1
如果前面字符串有公共的前后缀(最长公共子串),就返回k值(最长公共子串的长度)
如果没有公共子串,k=0
我们看例子1
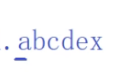
a是第一个字符,k=-1
b前面只有1个字符,就没有公共子串了,k=0
c前面只有2个字符,也没有公共子串,k=0
d前面,e前面,x前面都没有公共子串,k都是k=0
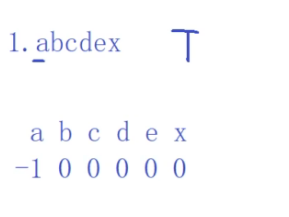

第一次比较的时候,x字符和主串的f字符比对出现失败了,i保证是不会回溯的,我们就看x的next数组这个值是多少,是0,保持i不动,j=0
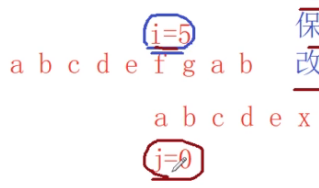
因为x前面的字符串没有公共子串,所以k=0
我们看例子2
我们给子串比对失败的前面的串写next数组

子串的第一个元素a,k=-1
b前面只有1个元素a,没有公共子串,k=0
c前面只有2个元素ab,没有公共子串,k=0
a前面有3个元素abc,但是没有公共子串,k=0
b前面是:abca,公共子串是a,P0到P0,根据
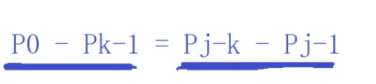
j=4,k=1,
x前面是abcab,k=2
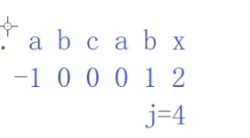

当我们第一次比较失败了,i5j的时候,i不变,此时查看next数组中x字符对应的k值,是2,更新j=2,进行比较下去
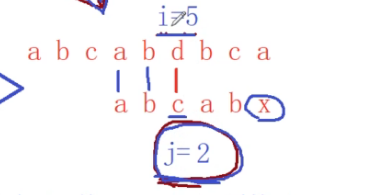
KMP算法代码实现2

k是从0加上来的,j也是一直往后加

当打箭头的两个位置的值相同的话,
k和j是从前面加过来的
0->k-1和j-k->j-1一直判断是相同的,然后到k,j了,不相同了,j就要记录前面字符串的最长公共子串了,就是k的值

k往前退,退到前面k前面的最长公共子串的前缀串的后面那个位置

这种情况就是k退到0了


KMP算法的优化
待优化情况1:

如果按照之前讲的KMP方法

这一步也是没有并要的。
j和首元素都是g是相同,g和上面对应的d不相同,你移到后面,此时g和d肯定也是不相同的,没必要比较。
待优化情况2:

C和F比对失败,查看next数组C对应的k值是2,更新j=2

之前是ABC,C和F比对失败
现在又还是ABC,C和F比对。
这样比较就没有意思了

说明前面的ABC和后面的ABC是一样的,当前C与F比对失败了,前面的移过来,也肯定是C与F比对,肯定也失败。
此时C在next数组就不记录2了,这个公共子串就不要了,k回退
也就是说公共串不需要AB这么长

AB这个公共子串长度在k记录,现在我们不要这么长,我们把要那个小一点的公共子串(k前面的字符串的最长公共子串)就好啦,next[j]=next[k]。

情况1的处理结果:


再举个例子:


package com.fixbug;
import java.util.Arrays;
/**
* 描述:
*
* @Author shilei
*/
public class KMP {
public static void main(String[] args) {
String S = "goodgoogle";
String T = "google";
int index = kmp(S, T);
System.out.println("index:" + index);
}
/**
* KMP算法代码实现
* @param S
* @param T
* @return
*/
private static int kmp(String S, String T) {
int i = 0;
int j = 0;
int[] next = getNext(T);
while(i < S.length() && j < T.length()){
if(j == -1 || S.charAt(i) == T.charAt(j)){
i++;
j++;
} else {
//i = i-j+1;
//j = 0;
j = next[j];
}
}
if(j == T.length()){
return i - j;
} else {
return -1;
}
}
private static int[] getNext(String T)
{
int[] next = new int[T.length()];
int j = 0;//j表示子串T的下标
int k = -1;//k表示子串T每一个字符对应的k值
next[0] = k;//#1 第一个字符,k是-1 ,主串和子串比较的第一个位置就不一样了,主串的i也要后移
while (j < T.length()-1)
{
if(k == -1 || T.charAt(k) == T.charAt(j))
{//#2 有公共子串
k++;
j++;
//对KMP算法的优化,例如ABCABC(0) ABCABD(2)
if(T.charAt(k) == T.charAt(j))
{
next[j] = next[k];//回退,不要那么长的公共子串
} else
{
next[j] = k;//#3 j前面没有公共子串,next[j] = 0
}
}
else
{
//k != -1说明有公共前后缀 T.charAt(k) != T.charAt(j) 表示公共前后缀结束了
k = next[k];//k往前退,退到k前面的最长公共子串的前缀子串的后面那个位置
}
}
return next;
}
}
int * getNext(string T)
{
int* next = new int[T.size()];
int j = 0;//j表示子串T的下标
int k = -1;//k表示子串T每一个字符对应的k值
next[0] = k;//#1 第一个字符,k是-1 ,主串和子串比较的第一个位置就不一样了,主串的i也要后移
while (j < T.size() - 1)
{
if (k == -1 || T.at(k) == T.at(j))
{ //#2 有公共子串
k++;
j++;
//对KMP算法的优化,例如ABCABC(0) ABCABD(2)
if (T.at(k) == T.at(j))
{
next[j] = next[k];//回退,不要那么长的公共子串
}
else
{
next[j] = k;//#3 j前面没有公共子串,next[j] = 0
}
}
else
{
//k != -1说明有公共前后缀 T.charAt(k) != T.charAt(j) 表示公共前后缀结束了
k = next[k];//k往前退,退到k前面的最长公共子串的前缀子串的后面那个位置
}
}
return next;
}
/*
* KMP算法代码实现
*/
int kmp(string S, string T)
{
int i = 0;
int j = 0;
int* next = getNext(T);
while (i < S.size() && j < T.size())
{
if (j == -1 || S.at(i) == T.at(j))
{
i++;
j++;
}
else
{
//i = i-j+1;
//j = 0;
j = next[j];
}
}
if (j == T.length())
{
return i - j;
}
else
{
return -1;
}
}
int main()
{
string S = "goodgoogle";
string T = "google";
int index = kmp(S, T);
cout << "index:" << index << endl;
return 0;
}
















 510
510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











