






一、项目说明
书法字形风格识别,该项目是我的导师为我指引的毕设项目,为了在自己的笔记本有限的硬件资源上实现,我将其拓展为了分布式,叠层网络实现大数据量识别,现已实现部分功能,到达初版设计,验证该方向的可行性,界面ui是自己随便写的,核心功能对书法字体的风格和字形的初步训练与识别已完成,能够对单字图片和多字图片进行识别,采用风格与字形分离识别,结构简单
项目界面:

界面所使用的图片均来自pixiv画师紺屋鴉江
简易功能流程:
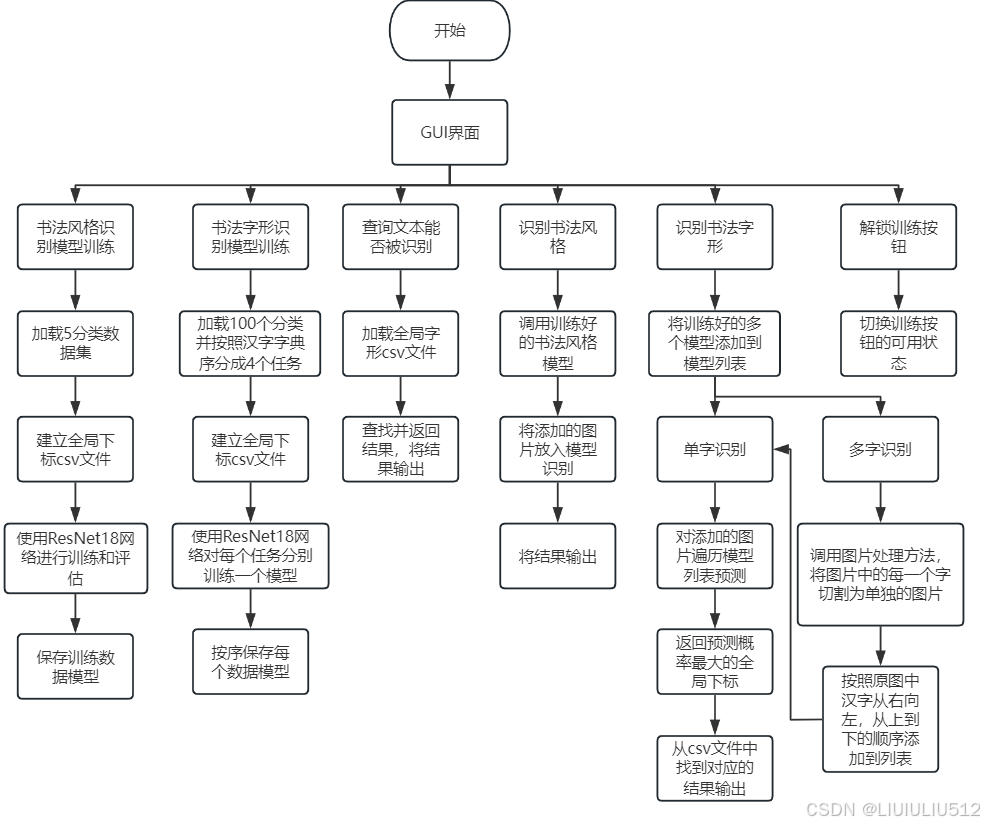
二、数据集
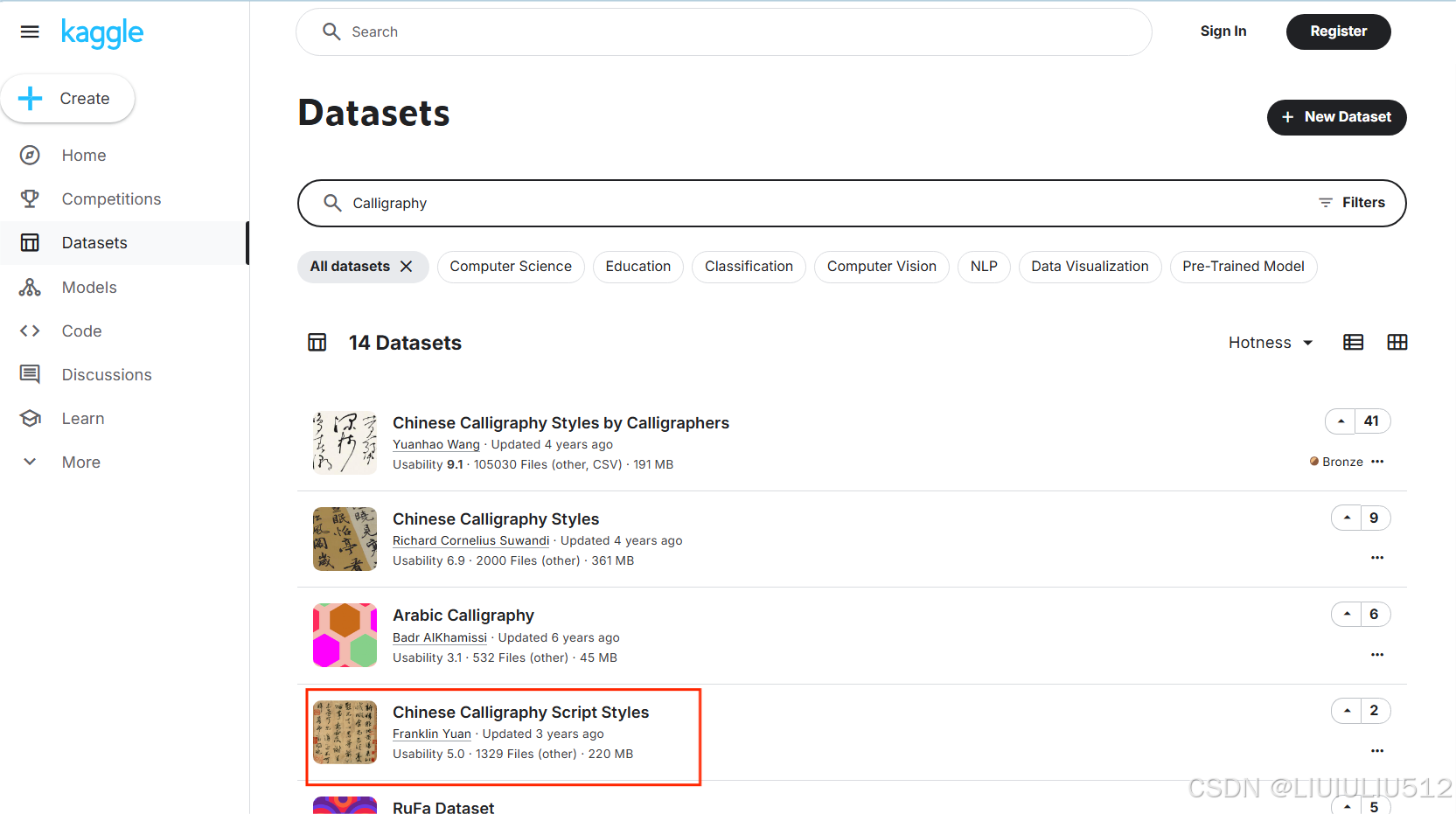
字体风格的数据集来自kaggle,其中包括草书,楷书,隶书,行书、篆书五类
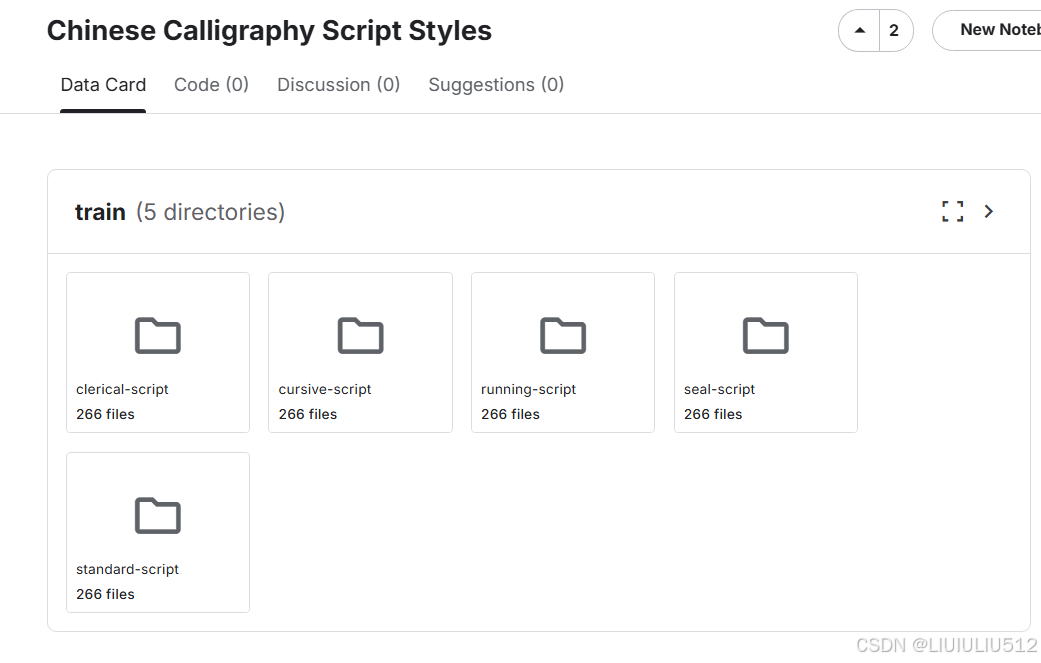

书法字形数据集来自TinyMind汉字书法识别挑战赛,共100个汉字类别,目前初版就先使用100个类,等到后期模型完善了再加大数据量,目前已爬取1000个汉字类,数据爬虫这块我会单独写一篇文章

三、代码
1.书法风格识别(CalligraphyStyleRecognition.py)
import csv
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, models, transforms
from tqdm import tqdm
from PIL import Image
num_class = 5
num_epochs = 10
batch_size = 32
lr = 0.001
# 训练数据存放地址
train_data_pth = 'E:/Chinese Calligraphy Script Styles/train'
# 全局下标映射的csv文件
csv_file = 'book_style.csv'
# 模型存放文件
model_save_pth = 'resnet18_book_style.pth'
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 引入resnet18网络模型
def create_resnet18():
model = models.resnet18(pretrained=True)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, num_class)
return model
def train_and_save_mode():
train_dataset = datasets.ImageFolder(root=train_data_pth, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 建立标签索引
class_to_idx = train_dataset.class_to_idx
class_dict = {}
for key, val in class_to_idx.items():
class_dict[val] = key
with open(csv_file, 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
for idx, label in class_dict.items():
writer.writerow([idx, label])
model = create_resnet18().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
# 使用tqdm显示进度条
with tqdm(train_loader, unit="batch") as tepoch:
for inputs, labels in tepoch:
tepoch.set_description(f"Epoch {epoch + 1}/{num_epochs}")
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
tepoch.set_postfix(loss=running_loss / len(train_loader), accuracy=100. * correct / total)
# 保存模型
torch.save(model.state_dict(), model_save_pth)
# 加载全局下标映射
def load_class_mapping():
class_to_idx = {}
with open(csv_file, mode='r', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
idx = int(row[0])
class_name = row[1]
class_to_idx[idx] = class_name
return class_to_idx
def load_model():
if not os.path.isfile(model_save_pth):
return False
else:
model = models.resnet18().to(device)
model.fc = nn.Linear(model.fc.in_features, num_class)
model.load_state_dict(torch.load(model_save_pth))
model.eval() # 设置模型为评估模式
return model
def predict_image(image, model):
# image = Image.fromarray(image_array) # 打开图像
image = transform(image).unsqueeze(0) # 预处理并增加批次维度
image = image.to(device)
model = model.to(device)
with torch.no_grad(): # 禁用梯度计算
output = model(image)
_, predicted = torch.max(output, 1) # 获取预测类别
return predicted.item() # 返回类别索引
# 对外调用的字形识别方法
def book_style_predict(image_array):
class_dict = load_class_mapping()
trained_model = load_model()
if not trained_model:
return False
else:
img = Image.fromarray(image_array)
predicted_class = predict_image(img, trained_model)
print(f'【书法风格识别结果】: {class_dict[predicted_class]}')
return True
# 对外调用的训练方法
def train_style():
train_and_save_mode()
# if __name__ == '__main__':
# train_and_save_mode()其中注释掉的if __name__中是可以单独取消注释不通过图形界面直接运行的
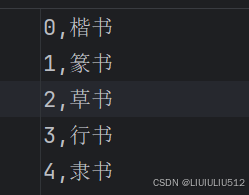
全局下标映射book_style.csv
2.书法字形识别(CalligraphyFontRecognition.py)
import csv
import shutil
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
from PIL import Image
from tqdm import tqdm
import os
import random
# 设置超参数
num_epochs = 10
batch_size = 32
learning_rate = 0.001
num_classes_per_model = 25 # 每个模型处理的类别数量
num_models = 4 # 总模型数量
threshold = 0.90 # 多模型阈值期望
num_img_per_class = 400
csv_file = 'class_mapping.csv'
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 图像转换
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整图像大小
transforms.ToTensor(), # 转换为 Tensor
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 标准化
])
# 清理临时目录
def clean_temp_directories(data_dir, num_models):
for i in range(num_models):
temp_dir = os.path.join(data_dir, f'temp_model_{i}')
if os.path.exists(temp_dir):
shutil.rmtree(temp_dir)
print(f"Temporary directory {temp_dir} has been deleted.")
else:
print(f"Temporary directory {temp_dir} does not exist.")
# 创建全部分类csv标签映射文件
def create_csv_file(all_classes):
with open(csv_file, mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
for idx, class_name in enumerate(all_classes):
writer.writerow([idx, class_name])
print(f'Class mapping saved to {csv_file}')
# 读取全局的CSV文件,获取类别名称和全局下标的映射
def load_class_mapping():
class_to_idx = {}
with open(csv_file, mode='r', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
idx = int(row[0])
class_name = row[1]
class_to_idx[class_name] = idx
return class_to_idx
# 数据预处理
def get_data_loaders(data_dir, num_classes_per_model, batch_size, temp_dir):
all_classes = sorted(os.listdir(data_dir)) # 所有分类文件夹
create_csv_file(all_classes)
# all_class_to_idx = load_class_mapping()
loaders = []
for i in range(num_models):
classes = all_classes[i * num_classes_per_model:(i + 1) * num_classes_per_model]
# 创建临时目录,用于只包含这些类别的训练数据
tep_dir = os.path.join(temp_dir, f'temp_model_{i}')
os.makedirs(tep_dir, exist_ok=True)
# 将相关类别复制或链接到临时目录
for cls in classes:
src_folder = os.path.join(data_dir, cls)
dst_folder = os.path.join(tep_dir, cls)
os.symlink(src_folder, dst_folder) # 使用符号链接以避免复制大量数据
dataset = datasets.ImageFolder(root=temp_dir+f'/temp_model_{i}', transform=transform)
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)
loaders.append(loader)
return loaders
# 定义小规模 ResNet 网络
def create_resnet18(num_classes):
model = models.resnet18(pretrained=False)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, num_classes)
return model
# 训练和保存模型
def train_and_save_model(train_loader, num_classes, model_save_path, i):
model = create_resnet18(num_classes).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
torch.autograd.set_detect_anomaly(True)
model.train()
for epoch in range(num_epochs):
running_loss = 0.0
correct = 0
total = 0
progress_bar = tqdm(train_loader, desc=f"Mobel {i} is Training, Epoch {epoch + 1} - Training")
for inputs, labels in progress_bar:
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 更新损失和准确率
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
progress_bar.set_postfix(loss=running_loss / (len(progress_bar)), accuracy=100. * correct / total)
torch.save(model.state_dict(), model_save_path)
# 加载模型
def load_model():
models_list = []
for i in range(4):
if not os.path.isfile(f'MyModel/model_part_{i}.pth'):
return False
else:
model = models.resnet18().to(device)
num_classes = 25
model.fc = nn.Linear(model.fc.in_features, num_classes)
state_dict = torch.load(f'MyModel/model_part_{i}.pth')
model.load_state_dict(state_dict)
model.eval() # 设置模型为评估模式
models_list.append(model)
return models_list
# 加载测试数据
def load_test_data(data_dir, num_classes, num_images_per_class, temp_dir):
shutil.rmtree(temp_dir)
all_classes = os.listdir(data_dir)
selected_classes = sorted(random.sample(all_classes, num_classes))
all_class_to_idx = load_class_mapping()
for class_name in selected_classes:
class_dir = os.path.join(data_dir, class_name)
images = os.listdir(class_dir)
selected_images = random.sample(images, num_images_per_class)
# 在临时目录中为每个类创建对应的目录
class_temp_dir = os.path.join(temp_dir, class_name)
os.makedirs(class_temp_dir)
for img_name in selected_images:
src_folder = os.path.join(class_dir, img_name)
dst_folder = os.path.join(class_temp_dir, img_name)
os.symlink(src_folder, dst_folder)
dataset = datasets.ImageFolder(root=temp_dir, transform=transform)
index_list = []
for label in dataset.classes:
for i in range(num_images_per_class):
index_list.append(all_class_to_idx[label])
dataset.class_to_idx[label] = all_class_to_idx[label]
dataset.targets = index_list
dataloader = DataLoader(dataset, batch_size=num_images_per_class, shuffle=False)
return dataloader, selected_classes
# 模拟模型的预测过程
def predict_image(models_list, image):
max_probs = []
preds = []
with torch.no_grad():
for i, model in enumerate(models_list):
output = model(image)
probs = torch.nn.functional.softmax(output, dim=1) # 计算类别概率
max_prob, pred = torch.max(probs, 1) # 获取最大概率和对应的类别
# 全局下标
pred += i * num_classes_per_model
max_probs.append(max_prob.item())
preds.append(pred.item())
# 输出调试信息
# for idx, (prob, pred) in enumerate(zip(max_probs, preds)):
# print(f"Model {idx}: Predicted {pred} with probability {prob:.4f}")
# 返回预测概率最大且超过阈值的类别
best_pred = -1 # 最大概率下标
best_prob = -1 # 最大概率
for i, prob in enumerate(max_probs):
if prob > threshold and prob > best_prob:
best_prob = prob
best_pred = preds[i]
return best_pred
def test_models(models_list, data_loader, selected_classes, class_idx=0):
total_correct = 0
total_images = 0
models_list = [model.to(device) for model in models_list]
for images, labels in tqdm(data_loader, desc=f"Testing"):
class_correct = 0
class_total = 0
labels = [data_loader.dataset.class_to_idx[selected_classes[class_idx]]] * int(len(data_loader.dataset.targets) / len(data_loader.dataset.classes))
labels = torch.tensor(labels)
images = images.to(device)
labels = labels.to(device)
for i in range(len(images)):
image = images[i].unsqueeze(0) # 添加 batch 维度
label = labels[i].item()
# 使用4个模型测试图像
pred = predict_image(models_list, image)
print(f"True label: {selected_classes[class_idx]} (Index: {label}), Predicted label: {pred}")
if pred == label:
class_correct += 1
class_total += 1
# 计算并显示该类的正确率
class_accuracy = class_correct / class_total if class_total > 0 else 0
print(f"Accuracy for class {selected_classes[class_idx]}: {class_accuracy:.2f}")
class_idx += 1
total_correct += class_correct
total_images += class_total
# 计算并显示总正确率
total_accuracy = total_correct / total_images if total_images > 0 else 0
print(f"\nOverall accuracy: {total_accuracy:.2f}")
# 训练和测试主流程
def main(data_dir, temp_dir):
# clean_temp_directories(temp_dir, num_models)
# loaders = get_data_loaders(data_dir, num_classes_per_model, batch_size, temp_dir)
#
# for i, loader in enumerate(loaders):
# model_save_path = f'MyModel/model_part_{i}.pth'
# train_and_save_model(loader, num_classes_per_model, model_save_path, i)
#
# clean_temp_directories(temp_dir, num_models)
models_list = load_model()
data_loader, selected_classes = load_test_data(data_dir, 20, 10, temp_dir)
test_models(models_list, data_loader, selected_classes)
clean_temp_directories(temp_dir, 1)
# 对外暴露的书法字形识别函数
def train_font():
# 训练的数据集
data_dir = 'E:/My Chinese Calligraphy Styles/train'
# 临时目录,用于存储各个模型的训练数据
temp_dir = 'E:/My Chinese Calligraphy Styles/temp'
clean_temp_directories(temp_dir, num_models)
loaders = get_data_loaders(data_dir, num_classes_per_model, batch_size, temp_dir)
for i, loader in enumerate(loaders):
model_save_path = f'MyModel/model_part_{i}.pth'
train_and_save_model(loader, num_classes_per_model, model_save_path, i)
clean_temp_directories(temp_dir, num_models)
# 对外暴露的书法字形预测函数
def book_font_predict(image_array):
models_list = load_model()
if not models_list:
return False
else:
models_list = [model.to(device) for model in models_list]
image = Image.fromarray(image_array)
image = transform(image).unsqueeze(0)
image = image.to(device)
pred = predict_image(models_list, image)
if pred == -1:
print("无法识别")
else:
class_dict = load_class_mapping()
key = next(k for k, v in class_dict.items() if v == pred)
print(f'【书法字形识别结果】: {key}, index: {pred}')
return True
# if __name__ == "__main__":
# data_dir = 'E:/My Chinese Calligraphy Styles/train'
# temp_dir = 'E:/My Chinese Calligraphy Styles/temp'
# main(data_dir, temp_dir)
# print("训练模型测试执行完成")
class_mapping.csv, 按照Unicode 编码的字典序排序,这个全局下标是我喜欢用中文做分类文件夹名,而网络模型在训练时会自动为每个类别分配下标,这个点会在训练出多个模型进行识别时出问题,比如我的模型1训练100个字中的前25个,模型2训练25-50个,后面依次类推,不做全局下标的话,4个模型识别出来的全是0-25区间的下标,对此,需要在模型识别给出最大概率下标后将其转为全局下标,可以详看predict_image(models_list, image)这个函数

其中训练的4个模型就是分布式,现在对图片的预测结果只是取其中预测最大的概率,后续会使用叠层模式,目前单个模型测试的准确率有90+%,但是将4个模型组合后准确率只有70+%,我目前看知网最新的论文中有叠层网络这个解决方法,但还未尝试
temp_dir这个临时目录中只存储了每个模型所需要训练的数据,使用了os.symlink符号连接,避免了真实复制大量训练数据
3.多字图片处理(ImageTransition.py)
import cv2
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
# 一英寸(2.54厘米,相当的一个硬币)200像素
plt.rcParams['figure.dpi'] = 200
def extract_characters_from_image(image_path):
image = Image.open(image_path).convert('RGB')
image = np.array(image)
# 将RGB模式转换为BGR模式
image = image[:, :, ::-1]
# image = cv2.imread(image_path)
# 获取图像的高度和宽度
height, width, _ = image.shape
# 提取图像四周的边缘像素区域
top_edge = image[0:5, :] # 顶部5行
bottom_edge = image[-5:, :] # 底部5行
left_edge = image[:, 0:5] # 左边5列
right_edge = image[:, -5:] # 右边5列
# 分别计算横向(top和bottom)与纵向(left和right)的平均颜色
mean_color_top_bottom = np.mean(np.concatenate((top_edge, bottom_edge), axis=0), axis=(0, 1))
mean_color_left_right = np.mean(np.concatenate((left_edge, right_edge), axis=0), axis=(0, 1))
# 最终的平均颜色为横向和纵向平均颜色的平均值
mean_color = (mean_color_top_bottom + mean_color_left_right) / 2
mean_color = [int(c) for c in mean_color]
# 添加边框
border_size = 10 # 根据需要调整
# 添加边框,边框颜色为计算得到的平均颜色
image_with_border = cv2.copyMakeBorder(
image,
top=border_size,
bottom=border_size,
left=border_size,
right=border_size,
borderType=cv2.BORDER_CONSTANT,
value=mean_color
)
gray = cv2.cvtColor(image_with_border, cv2.COLOR_BGR2GRAY)
_, black_img = cv2.threshold(gray, 100, 255, cv2.THRESH_BINARY_INV)
# 开运算的主要作用是去除小的噪声点,同时保持原图像中较大物体的形状和大小。它是先进行腐蚀操作,然后再进行膨胀操作。
# 开运算 适合去除噪声,保留物体形状。
# 闭运算 适合填补孔洞,连接物体。
# 腐蚀
kernel = np.ones((3, 3), dtype=np.int8)
erosion = cv2.erode(black_img, kernel)
# cv2.imshow('test', erosion)
# cv2.waitKey(3000)
# 膨胀
kernel = np.ones((10, 10), dtype=np.int8)
dilation = cv2.dilate(erosion, kernel, iterations=2)
# cv2.imshow('test', dilation)
# cv2.waitKey(3000)
# 闭运算
closing = cv2.morphologyEx(dilation, cv2.MORPH_CLOSE, kernel)
# cv2.imshow('test', closing)
# cv2.waitKey(3000)
# 边缘检测
edges = cv2.Canny(closing, 30, 200)
# cv2.imshow('edges', edges)
# cv2.waitKey(3000)
# 查找轮廓,contours:这是一个列表, h:这是层次结构信息, cv2.RETR_EXTERNAL 表示只检测最外层的轮廓,忽略所有嵌套在内部的轮廓
contours, h = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
img_copy = image_with_border.copy()
# 设置容差值,判断字符是否在同一行
tolerance = 1000
# 截取的字符图像列表
chars = []
for c in contours:
x, y, w, h = cv2.boundingRect(c)
tolerance = min(tolerance, w)
char_img = img_copy[y:y+h, x:x+w]
chars.append((char_img, x, y, w, h))
cv2.rectangle(img_copy, (x, y), (x+w, y+h), (0, 255, 0), 3)
# img_copy = cv2.resize(img_copy, (0, 0), fx=0.5, fy=0.5)
# cv2.imshow('test', img_copy)
# cv2.waitKey(3000)
# 首先按x坐标进行逆序排序,再按y坐标排序
chars = sorted(chars, key=lambda item: -item[1])
sorted_chars = []
current_line = []
for i, (char_img, x, y, w, h) in enumerate(chars):
if i == 0:
current_line.append((char_img, x, y, w, h))
continue
_, prev_x, prev_y, _, _ = chars[i-1]
if abs(x - prev_x) < tolerance:
current_line.append((char_img, x, y, w, h))
else:
current_line.sort(key=lambda item: item[2])
sorted_chars.extend(current_line)
current_line = [(char_img, x, y, w, h)]
if current_line:
current_line.sort(key=lambda item: item[2])
sorted_chars.extend(current_line)
for img in sorted_chars:
cv2.imshow("sorted_char", img[0])
cv2.waitKey(1000)
# 提取字符图像
sorted_char_images = [char_img for char_img, _, _, _, _ in sorted_chars]
return sorted_char_images
# image_pth = "E://pycharm_python/GraduationProject/data/楷体/Snipaste_2022-10-21_16-23-35.png"
# image_pth = 'test.jpg'
# characters = extract_characters_from_image(image_pth)
#
# for i, char_img in enumerate(characters):
# cv2.imshow(f'char_{i}', char_img)
# cv2.waitKey(1000)
#
# cv2.destroyAllWindows()
多字体图片识别,将图片中的字体按照从上到下,从右到左的顺序依次切割出来,然后再依次单张字形识别
效果:

部分思路来自实战项目(一)利用opencv实现毛笔字检测
4.Gui界面(Gui.py)
import csv
import io
import sys
import tkinter as tk
from tkinter import filedialog, messagebox
from PIL import Image, ImageTk, ImageEnhance
from CalligraphyFontRecognition import load_class_mapping, book_font_predict, train_font
from CalligraphyStyleRecognition import book_style_predict, train_style
from ImageTransition import extract_characters_from_image
import numpy as np
class GUI():
book_dict = load_class_mapping()
def __init__(self):
self.root = tk.Tk()
self.root.config(bg="#FFF0F5") # 淡紫色
self.root.title("书法风格字形识别")
self.root.attributes('-alpha', 1)
w = 1000
h = 700
self.root.geometry(f'{w}x{h}+500+300')
#===============================================================
# 背景图片展示及输出框
background_img = Image.open('Output_BG.jpg')
background_img = background_img.resize((w, h))
background_img = background_img.crop((250, 0, 750, 700))
# 图片透明度
alpha = 1
enhancer = ImageEnhance.Brightness(background_img.convert('RGBA'))
background_img = enhancer.enhance(alpha)
self.background_img = ImageTk.PhotoImage(background_img)
# 输出窗口
self.background_canvas = tk.Canvas(self.root, width=500, height=700)
self.background_canvas.create_image(0, 0, image=self.background_img, anchor="nw")
self.background_canvas.place(x=500, y=0)
# 添加提示文字
self.background_canvas.create_text(10, 10, anchor="nw", text="这是输出栏", fill="white", font=("Arial", 14),
tags="hint")
self.background_canvas.create_text(10, 30, anchor="nw", text="=================", fill="white",
font=("Arial", 14), tags="hint")
# 用于跟踪创建的文本位置
self.text_y = 50
# 重定向标准输出到 Canvas 上显示
sys.stdout = CanvasText(self.background_canvas, self.text_y, max_height=700)
clear_button = tk.Button(self.root, text="清空输出栏", command=self.clear_text)
clear_button.place(x=90, y=550)
#===================================================================
# 书法风格展示画板
book_style_dict = self.load_class_mapping('book_style.csv')
style_list = list(book_style_dict.keys())
self.style_canvas = tk.Canvas(self.root, bg="#B2DFEE", relief="ridge", bd=2)
self.style_canvas.place(x=20, y=10, width=450, height=50)
self.scrollbar = tk.Scrollbar(self.root, orient=tk.HORIZONTAL, command=self.style_canvas.xview)
self.scrollbar.place(x=20, y=60, width=450, height=15)
self.style_canvas.configure(xscrollcommand=self.scrollbar.set)
style_str = "当前能够识别的书法风格:"
for sty in style_list:
style_str += sty + " "
style_text = self.style_canvas.create_text(0, 0, anchor="nw", text=style_str, font=("黑体", 14), fill="Black")
bbox = self.style_canvas.bbox(style_text)
self.style_canvas.coords(style_text, 0, 12)
self.style_canvas.configure(scrollregion=bbox)
#==================================================================
# 书法字形展示画板
book_font_dict = self.load_class_mapping('class_mapping.csv')
font_str = "当前能够识别的书法字形:\n"
for key, val in book_font_dict.items():
font_str += '(' + str(val) + ':' + key + ')' + ' '
tip2_canvas = tk.Canvas(self.root, bd=2, relief="sunken")
tip2_canvas.place(x=20, y=80, width=450, height=200)
scrollbar = tk.Scrollbar(self.root, orient='vertical', command=tip2_canvas.yview)
scrollbar.place(x=470, y=80, height=200)
# 在Canvas上创建一个框架
book_frame = tk.Frame(tip2_canvas)
tip2_canvas.create_window((0, 0), window=book_frame, anchor='nw')
message = tk.Message(book_frame, text=font_str, width=450, bg="#B2DFEE", font=("宋体", 14), fg="Black")
message.pack()
# 更新Canvas的滚动区域
book_frame.update_idletasks()
tip2_canvas.config(scrollregion=tip2_canvas.bbox('all'))
tip2_canvas.config(yscrollcommand=scrollbar.set)
#=================================================================
# 图片上传功能
# 上传图片功能
self.add_img_frame = tk.Frame(self.root, bg="white", relief=tk.RAISED, borderwidth=1)
self.add_img_frame.place(x=20, y=290, width=200, height=250)
add_icon = Image.open('add.png')
add_icon = add_icon.resize((100, 100))
add_icon = ImageTk.PhotoImage(add_icon)
self.add_icon = tk.Label(self.add_img_frame, image=add_icon, bg='white')
self.add_icon.pack(pady=30)
self.add_text = tk.Label(self.add_img_frame, text="点击添加图片", bg='white', font=("黑体", 14))
self.add_text.pack()
self.add_img_frame.bind("<Button-1>", self.add_image)
self.add_icon.bind("<Button-1>", self.add_image)
self.add_text.bind("<Button-1>", self.add_image)
# 创建删除图片按钮
self.delete_button = tk.Button(self.root, text='删除图片', command=self.delete_image)
self.delete_button.place(x=20, y=550)
self.image_label = None
self.image_path = None
#==================================================================
# 字形查询功能
# 查询字体是否存在
input_label = tk.Label(self.root, text="查询文本是否能够识别:", font=("黑体", 14))
input_label.place(x=240, y=290)
self.input_entry = tk.Entry(self.root, font=("黑体", 14))
self.input_entry.place(x=240, y=330, width=210, height=40)
self.input_button = tk.Button(self.root, text="点击识别文本", command=self.exist_text)
self.input_button.place(x=240, y=390)
#====================================================================
# 模式选择
self.select_pattern = tk.IntVar()
self.rd1 = tk.Radiobutton(self.root, font=("黑体", 12), activeforeground="blue",
text="单字形模式", variable=self.select_pattern,
value=0, command=self.mode_radio)
self.rd1.place(x=240, y=430)
self.rd2 = tk.Radiobutton(self.root, font=("黑体", 12), activeforeground="red",
text="多字形模式", variable=self.select_pattern,
value=1, command=self.mode_radio)
self.rd2.place(x=350, y=430)
self.book_style_button = tk.Button(self.root, text="点击识别书法风格", command=self.book_style)
self.book_style_button.place(x=240, y=470)
self.book_font_button = tk.Button(self.root, text="点击识别手法字形", command=self.book_font)
self.book_font_button.place(x=240, y=510)
#==============================================================
# 模型训练
tip3_text = "非必要请勿点击训练按钮"
tip3_label = tk.Label(self.root, text=tip3_text, font=("黑体", 12), bd=2, relief="groove", bg="cyan")
tip3_label.place(x=265, y=550, width=190, height=30)
self.unlock_button = tk.Button(self.root, bg="Turquoise", text="解锁训练按钮", command=self.unclock_train)
self.unlock_button.place(x=170, y=550)
self.train_state = tk.DISABLED
self.train_style_button = tk.Button(self.root, text="训练风格模型", state=self.train_state, command=self.train_style)
self.train_style_button.place(x=370, y=470)
self.train_font_button = tk.Button(self.root, text="训练字形模型", state=self.train_state, command=self.train_font)
self.train_font_button.place(x=370, y=510)
#====================================================================
# 底图
low_image = Image.open("L-P.png")
low_image = low_image.resize((500, 110))
self.photo = ImageTk.PhotoImage(low_image)
self.low_image = tk.Label(self.root, image=self.photo)
self.low_image.place(x=0, y=590, width=500, height=110)
#===================================================================
self.root.mainloop()
def load_class_mapping(self, csv_file):
class_to_idx = {}
with open(csv_file, mode='r', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
idx = int(row[0])
class_name = row[1]
class_to_idx[class_name] = idx
return class_to_idx
def add_image(self, event):
file_path = filedialog.askopenfilename(filetypes=[("Image Files", "*.jpg;*.jpeg;*.png")])
if file_path:
self.image_path = file_path
self.display_image(file_path)
def display_image(self, file_path):
if self.image_label:
self.image_label.pack_forget()
image = Image.open(file_path)
image = image.resize((200, 250))
photo = ImageTk.PhotoImage(image)
self.image_label = tk.Label(self.add_img_frame, image=photo, bg='white')
self.image_label.image = photo
self.image_label.pack()
self.add_icon.pack_forget()
self.add_text.pack_forget()
def delete_image(self):
if self.image_label:
self.image_label.pack_forget()
self.image_label = None
self.add_icon.pack(pady=30)
self.add_text.pack()
self.image_path = None
else:
messagebox.showinfo("信息", "没有图片可删除")
def unclock_train(self):
if self.train_state == tk.DISABLED:
self.train_state = tk.NORMAL
self.train_style_button.config(state=self.train_state, bg="cyan")
self.train_font_button.config(state=self.train_state, bg="cyan")
else:
self.train_state = tk.DISABLED
self.train_style_button.config(state=self.train_state, bg="#F0F0F0")
self.train_font_button.config(state=self.train_state, bg="#F0F0F0")
def exist_text(self):
text = self.input_entry.get()
text_list = list(text)
if len(text_list) > 0:
sure_dict = {}
for text in text_list:
if text in self.book_dict.keys():
sure_dict[text] = True
else:
sure_dict[text] = False
print(sure_dict)
else:
messagebox.showinfo("信息", "没有文本可用于识别")
def mode_radio(self):
# 0:单字图片 1:多字图片
print(f'选择模式:{self.select_pattern.get()}')
def book_style(self):
if self.image_label:
image = Image.open(self.image_path).convert('RGB')
image_array = np.array(image)
flag = book_style_predict(image_array)
if not flag:
messagebox.showinfo("信息", "没有可使用的模型,请先训练模型")
else:
messagebox.showinfo("信息", "没有图片可用于识别")
def book_font(self):
if self.image_label:
mode = self.select_pattern.get()
if mode == 0:
image = Image.open(self.image_path).convert('RGB')
image_array = np.array(image)
flag = book_font_predict(image_array)
if not flag:
messagebox.showinfo("信息", "没有可使用的模型,请先训练模型")
elif mode == 1:
characters = extract_characters_from_image(self.image_path)
for image_array in characters:
flag = book_font_predict(image_array)
if not flag:
messagebox.showinfo("信息", "没有可使用的模型,请先训练模型")
break
else:
messagebox.showinfo("信息", "没有图片可用于识别")
def train_style(self):
train_style()
def train_font(self):
train_font()
def clear_text(self):
self.background_canvas.delete("text") # 清空输出文本,但保留提示文字
sys.stdout.y = 50 # 重置Y位置
class CanvasText(io.StringIO):
def __init__(self, canvas, initial_y, max_height):
super().__init__()
self.canvas = canvas
self.y = initial_y
self.max_height = max_height
self.text_id = None
self.line_number = 0
self.total_height = 0
def write(self, string):
# 在 Canvas 上创建文本并逐行显示
if string.strip(): # 跳过空行
self.line_number += 1
full_string = f"{self.line_number}: {string}"
last_line = string # 避免每次刷新页面丢失输出
current_line = ""
for char in full_string:
test_line = current_line + char
test_id = self.canvas.create_text(10, self.y, anchor="nw", text=test_line, fill="white",
font=("Arial", 12), tags="text")
bbox = self.canvas.bbox(test_id)
self.canvas.delete(test_id)
if bbox[2] > self.canvas.winfo_width() - 20:
self.canvas.create_text(10, self.y, anchor="nw", text=current_line, fill="white",
font=("Arial", 12), tags="text")
self.y += (bbox[3] - bbox[1]) + 5
self.total_height += (bbox[3] - bbox[1]) + 5 # 累加每行高度
current_line = char
else:
current_line = test_line
# 输出剩余的部分
text_id = self.canvas.create_text(10, self.y, anchor="nw", text=current_line, fill="white",
font=("Arial", 12), tags="text")
bbox = self.canvas.bbox(text_id) # 获取文本的边界框,(x1, y1, x2, y2),左上角的坐标,右下角的坐标
line_height = (bbox[3] - bbox[1]) + 5
self.y += line_height # 更新 y 坐标以避免重叠
self.total_height += line_height
# 判断是否需要清除文本
if self.total_height >= self.max_height - 50:
self.canvas.delete("text")
self.y = 50
self.total_height = 0
self.line_number -= 1
# 重新输出被清除的行
self.write(last_line)
def flush(self):
pass
if __name__ == '__main__':
w = GUI()
利用python自带的tkinter库写的,比较的原始,为了美观我狠狠滴折腾
四、运行效果
查询‘福’是否能够被识别

识别其风格和字形

多字识别
 展示区域刷新
展示区域刷新


最后的碎碎念:人工智能领域还是挺好玩的,可惜我不想考研
swust, 22ldx

















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









