






xpath定位
xpath常用函数
child 选取当前节点的所有子节点
parent 选取当前节点的父节点
descendant 选取当前节点的所有后代节点
ancestor 选取当前节点的所有先辈节点
descendant-or-self 选取当前节点的所有后代节点及当前节点本身
ancestor-or-self 选取当前节点所有先辈节点及当前节点本身
preceding-sibling 选取当前节点之前的所有同级节点
following-sibling 选取当前节点之后的所有同级节点
preceding 选取当前节点的开始标签之前的所有节点
following 选去当前节点的开始标签之后的所有节点
self 选取当前节点
attribute 选取当前节点的所有属性
namespace 选取当前节点的所有命名空间节点
节点层级[分隔符]
| nodename | 选取此节点的所有子节点。 |
|---|---|
| / | 从根节点选取 |
| // | 从当前节点选择开始匹配,不考虑它们的位置 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
对于一些既没id又没属性标识,同时其他属性都是动态的情况就很难通过简单的方式进行定位
Contains函数
contains函数,我们可以提取匹配特定文本的所有元素
sibling函数
通过sibling函数我们可以提取指定元素的所有同级元素,即获取目标元素的所有兄弟节点
测试链接参考
https://book.douban.com/

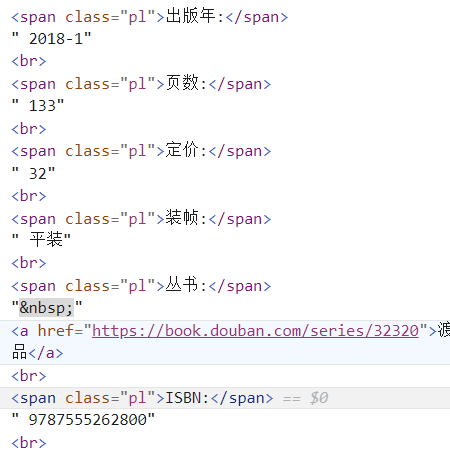
在示例图中的文字属性没有直接的标签标识,这时需要用到following
contains:
book_put_date = '/'.join(new_root.xpath('//span[contains(text(),"出版年")]/following::text()[1]'))
book_price = '/'.join(new_root.xpath('//span[contains(text(),"定价")]/following::text()[1]'))
ISBN = '/'.join(new_root.xpath('//span[contains(text(),"ISBN")]/following::text()[1]'))
#following::text()锁定文字标签后边伴随的文字
sibling:
ISBN = '/'.join(new_root.xpath('//span[contains(text(),"ISBN")]'))
# 锁定ISBN这个文字标签的同级文字
#返回结果应该为:出版年,页数......的同级文字
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











