






目录
B+树搜索过程与B树的查询过程没有区别。但实际上有三点不一样:(B+Tree优
6)红黑树任意节点其左右子树最多相差2层红节点(自动相对平衡)
红黑树任意节点其左右子树最多相差2层红节点。所以大致上是平衡的。
数据结构:
程序 = 数据结构 + 算法 (一段逻辑性代码);
典型实例示例容器:
(1)ArrList, LinkedList,hashMap;
你了解过哪些数据结构:
这些数据结构的优缺点:
数组:
就是一块大内存空间中有一块块小的内存空间就和船底的隔板一样,我们将来就可以把数据存进去,他的优点查询快在于数据在每一块小空间,可以通过下标快速定位到要查询的位置,缺点在与增删慢,原因在于如果原数组的内存不够用,就会创建更大新的数组并把原数组的数据拷贝进新数组完成后还需要销毁原数组所以慢.
链表:
每一个链表都保存了前后节点的地址,增加或者删除都不会影响他的速度,不管增加或者删除他都会去找前面或者后面的节点相连,但是查询比较慢因为都需要遍历所有数据链,查两端除外.

队列:顺序消费先进先出,后进后出.
比如火车:

栈:
jvm,方法栈,方法执行都是方法栈中执行的,最先进入的后出,最后进入的先出.
杯子里放石头:
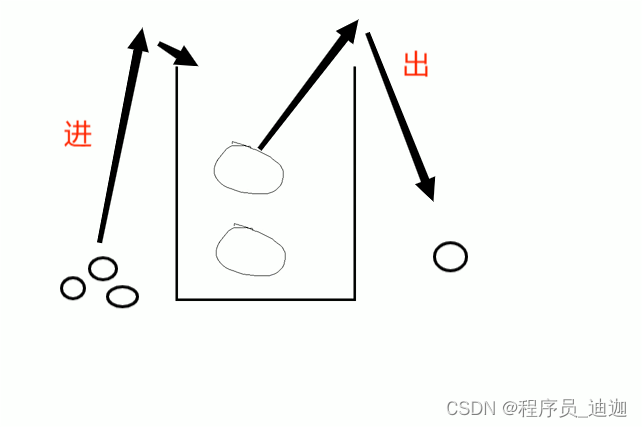
树: 实例,mysql使用的为B+Tree
二叉树:
特点:
(把每个蓝色圆球看作一个节点)由图可以看出三点:
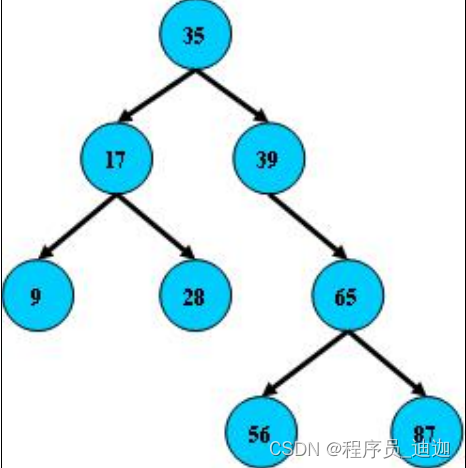
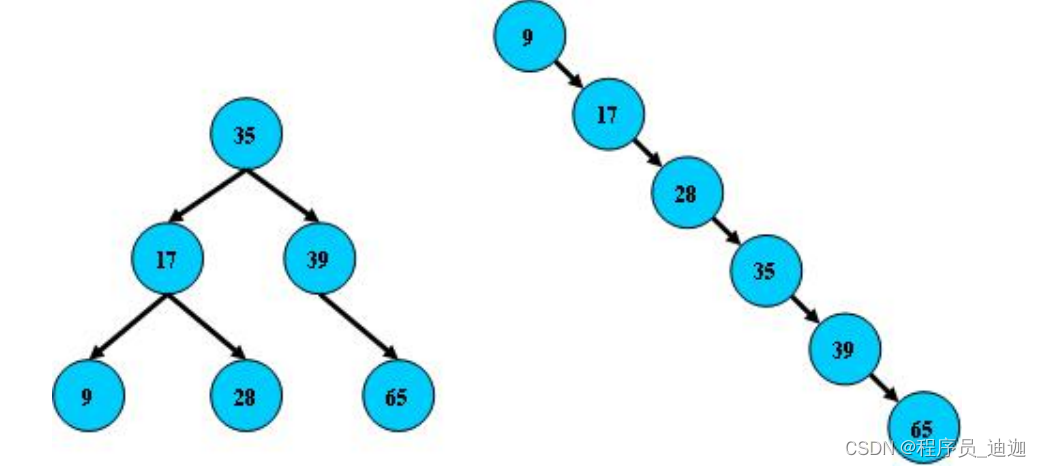
二叉树适合做磁盘存储吗:
假设:把本地磁盘(好处:在于可以保证持久性)现在把磁盘中的所有数据,都放到二叉树中作为存储,现在应用程序作为内存需要获取二叉树中数据的话,应该分层;一层一层的拿取二叉树中的数据,在结合二叉树的特点来说,一个主节点最多分两个子节点;那在面对百万级大数据量的情况下,树的层数会越来越高,我们把数据从二叉树中读取到应用内存中;使用的方法是以IO流的方式进行读取的,IO很浪费性能,随着树越来越高IO次数也会越大,性能也会越低,所以不适合做磁盘存储.
缺点:
①由于二叉树只有最多两个子节点,因此不适合存储大量的数据
②二叉树无法动态维护树的平衡,操作不当会造成树的倾斜
B-Tree:
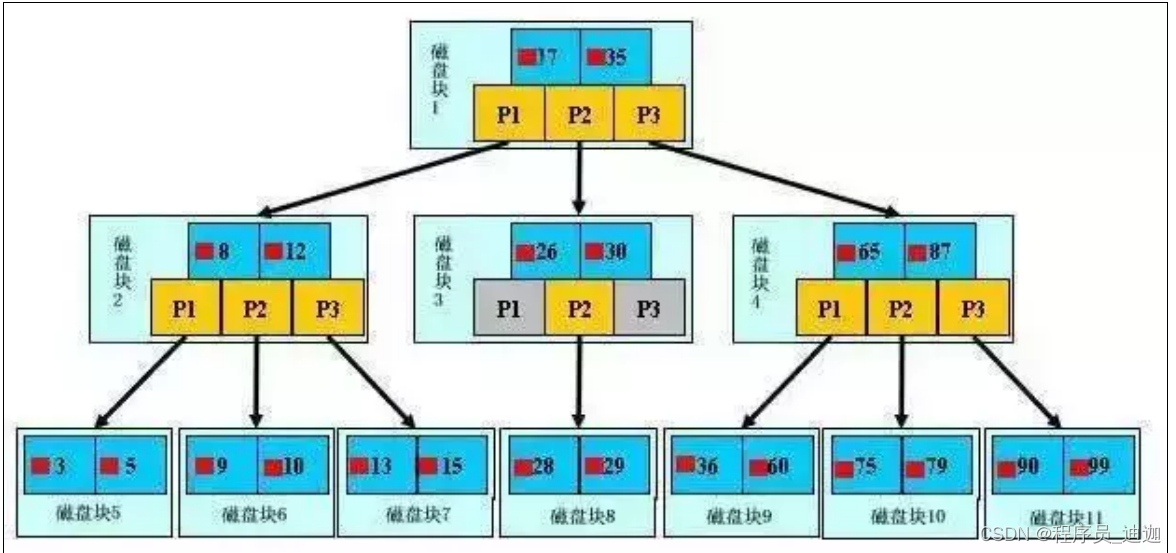
b-树的查找过程:
思考:
层数的降低,导致了IO次数的减少,保证了性能,适合做磁盘存储;但是从用户时间稳定度这个问题来讲的话,由上图来说明一个新问题的话;我们就是希望从根节点查询某个关键字哪个关键字是第一条也好,还是查哪个关键字向下查询一百万条是哪个关键字也好;查询到关键字时,查询的这两条关键字,返回给我们的时间是一样的都是0.5秒,不管查询远近时间都是相同的,但是B-Tree他做不到,B-Tree他的特点在于定位的位置是否在于我们进的节点上,如果很远就很耗费时间了,保证不了这个时间的稳定性距离越远,时间耗费的时间越长.
特点:
①他是由二叉树的基础之上演变而来,B树也叫多路搜索树
②B树的每个节点保存多个数据,这样的话我们可以在使用很少的io流次数的情况下就能够读取到数据
③B树适合磁盘存储
缺点:
①不适合范围查找
②B树查找元素存在最好和最坏的情况,因此树的时间复杂度很不稳定
B+Tree:
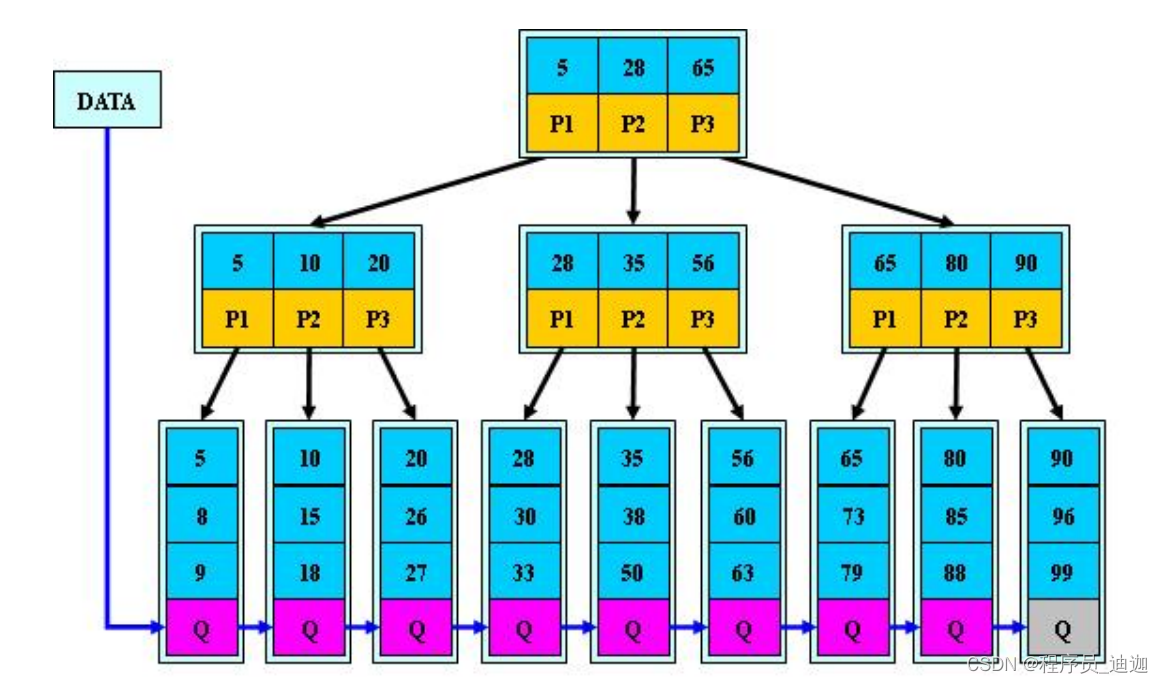
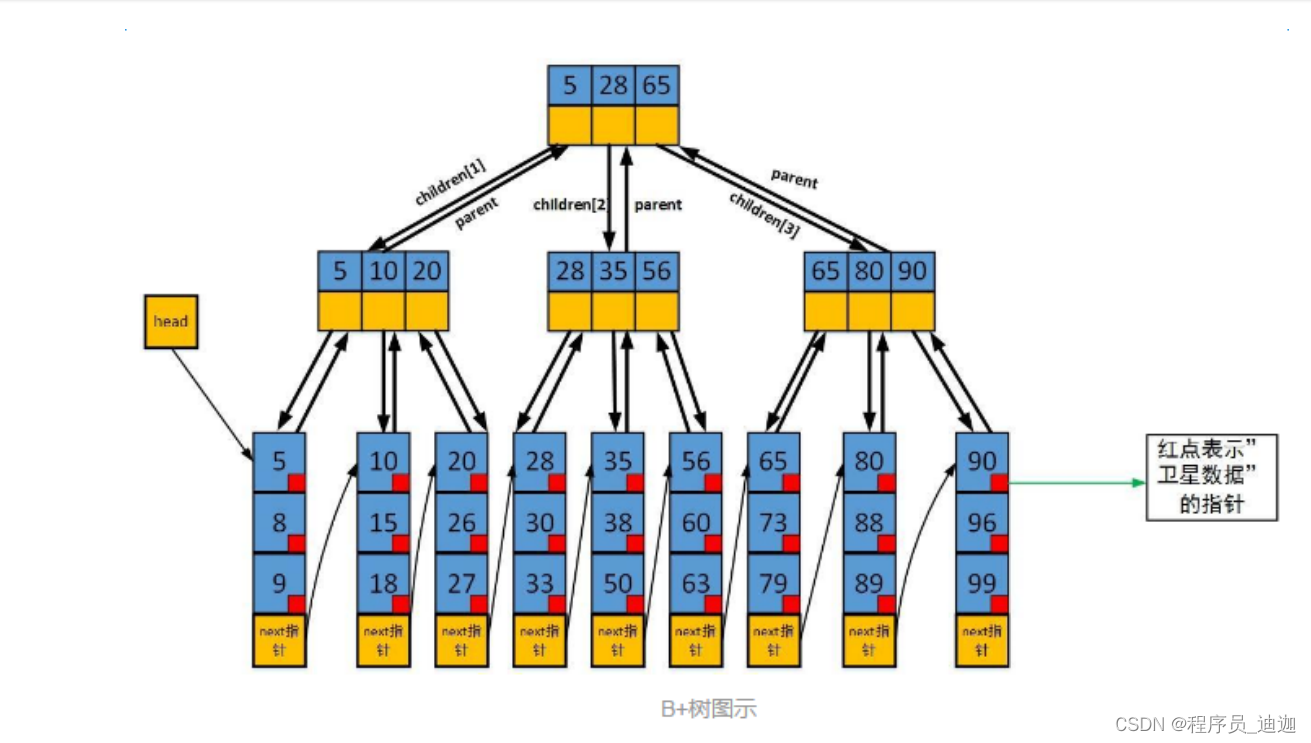
B+树搜索过程与B树的查询过程没有区别。但实际上有三点不一样:(B+Tree优
势)
简述B+Tree:
②叶子节点之间会形成一个有序的双向链表,我们只需要找到链表两端数据,就可以获取到范围数据,适合范围查询
不经历IO的情况下,可以直接使用二叉树吗?
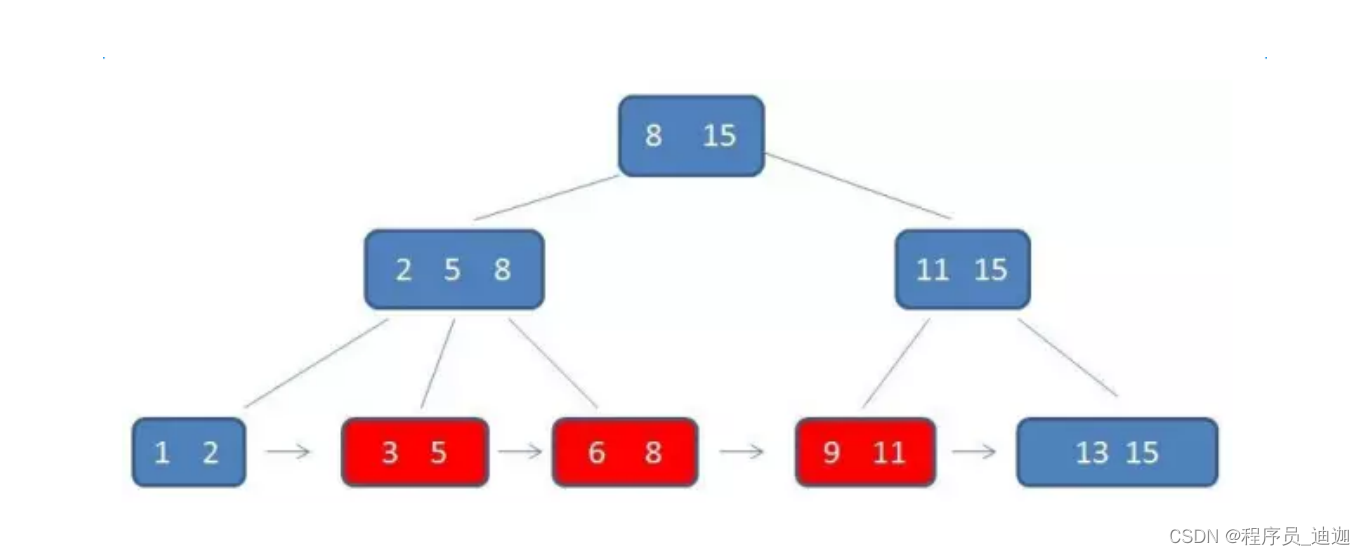
红黑树:
红黑树具有以下五个特性:
6)红黑树任意节点其左右子树最多相差2层红节点(自动相对平衡)
缺点:
数据量大,树高度会很高导致查找速度变慢
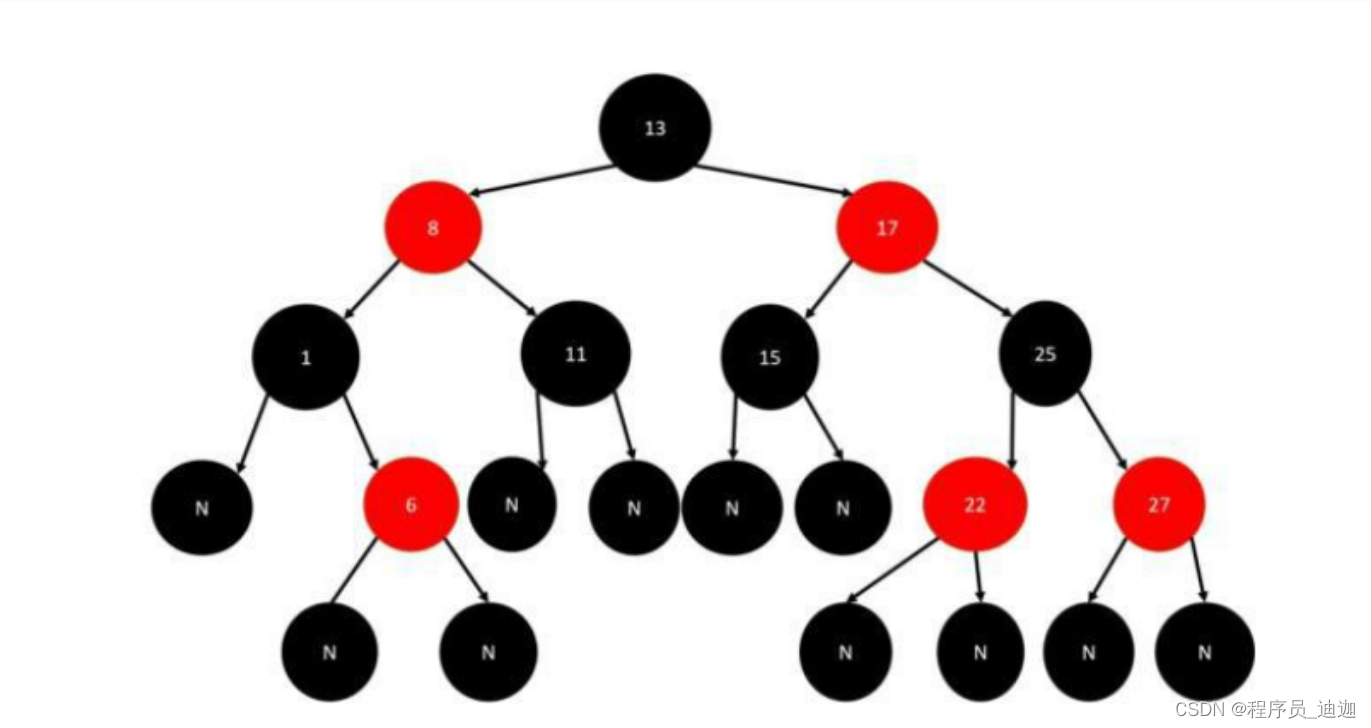
红黑树任意节点其左右子树最多相差2层红节点。所以大致上是平衡的。

hashmap的原理:
特点:
底层使用hash表数据结构,即数组+(链表或者红黑树)
添加数据时,计算key的值确定元素在数组中的下标,key相同则替换不同则存入链表或红黑树中
获取数据通过key的hash计算数组下标获取元素
hashmap的put流程:
判断table是否为空,如果空的话,会先调用resize扩容;
根据当前key的 hash 值,通过 (n - 1) & hash计算应当存放在数组中的下标 index ;
查看链表是否存在数据,没有数据就构造一个 Node 节点存放在链表中;
存在数据,说明发生了 hash 冲突,继续判断 key 是否相等,如果相等,用新的 value 替换原数据;
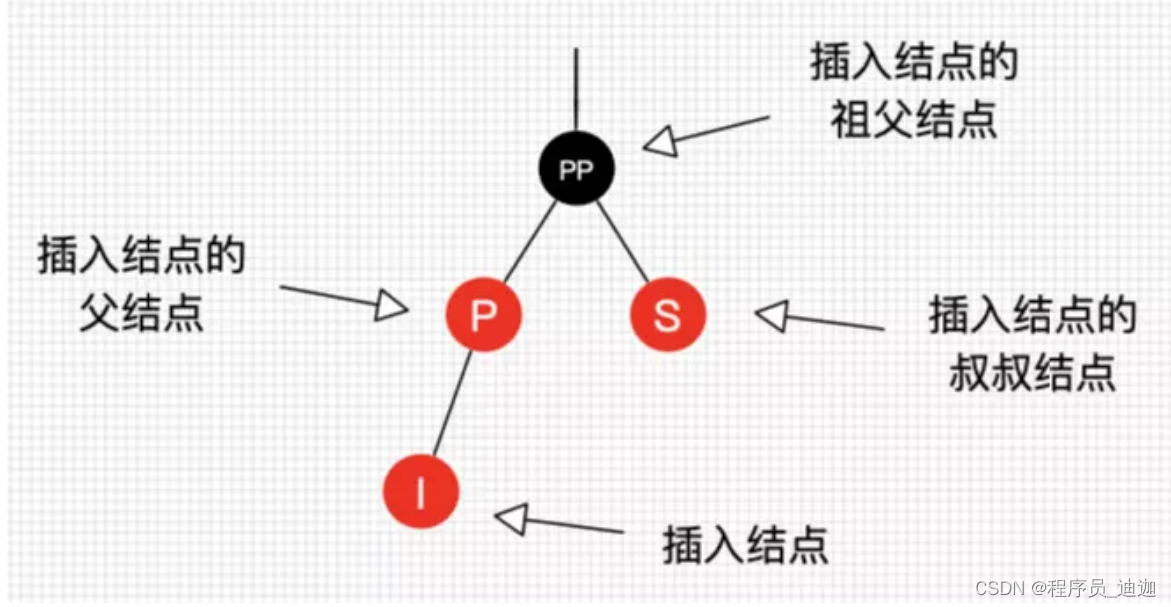
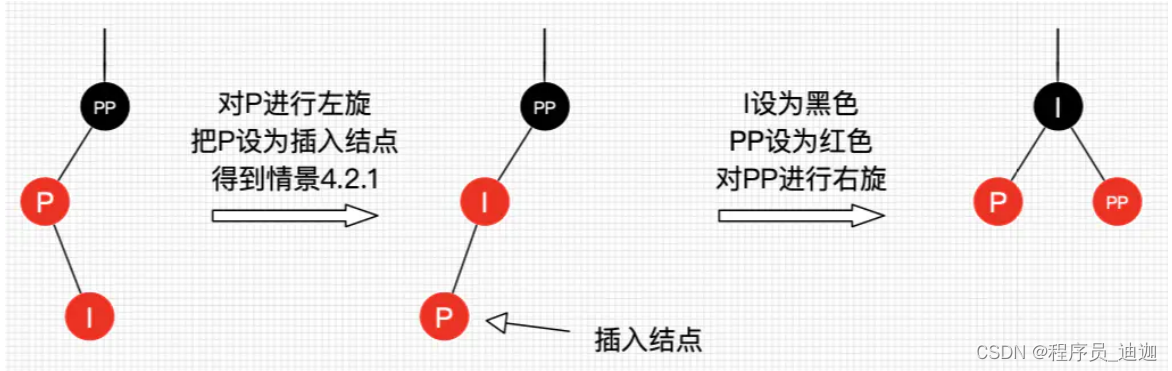
如果不相等,判断当前节点类型是不是树型节点,如果是树型节点,创建树型节点插入红黑树中;
如果不是树型节点,则采用尾插法,把新节点加入到链表尾部;判断链表长度是否大于 8, 大于的话链表转换为红黑树;
插入完成之后判断当前节点数是否大于扩容因子阈值,如果大于开始扩容为原数组的二倍。
扩容时机:
当数据的容量到达总容量的0.75的时候就会扩容;
为什么不上来就树化:
红黑树使用TreeNode比链表使用的node内存占用要大;
为了防止dos攻击解决超长链表出现的特殊手段,几率比较小.
什么时候会退化成链表:
当树的元素小于6个的时候会退化成链表.
为什么hashmap每次扩容都是2的n次幂:
只有2的n次幂计算索引的时候才能把取模运算转换为位运算.
为什么选择0.75作为扩容因子:
0.75只不过说是在时间上和空间上做了一个比较好的权衡;
大于0.75说明扩容机会少,这样会形成超长链表;
小于0.75说明扩容机会多,链表减少,但是空间变大.
hashmap1.8和1.7的区别:
JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法,JDK1.7是用单链表进行的纵向延伸, 当采用头插法时多线程环境会容易出现扩容死链(ABA)问题。
但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。
concurrentHashMap的原理:
使用:
![]()
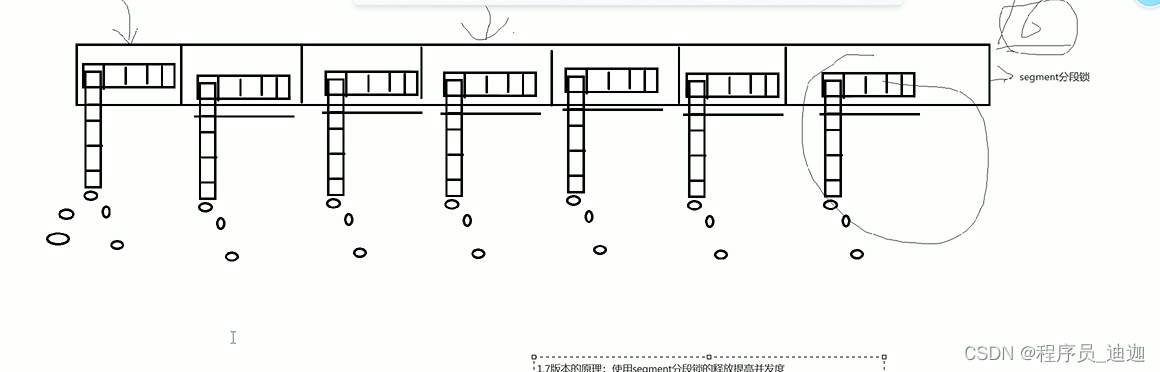
1.7版本:
使用segment分段锁实现concurrentHashMap,每个segment的下面都有一个hashtable,这样比单个hashtable并发量要高,使用segment
锁的方式最大支持16个并发,但是需要经过两次hash hash时间太长
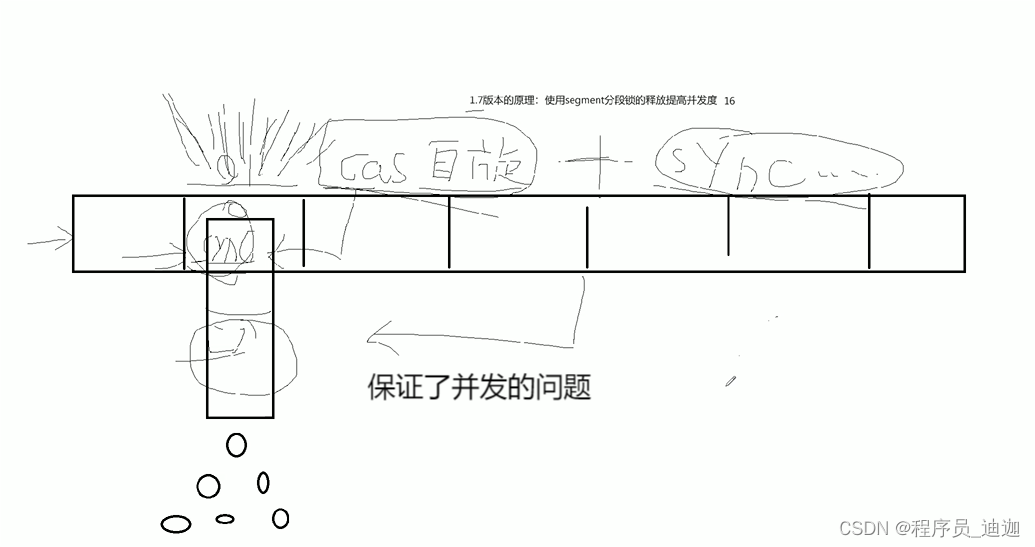
1.8版本:
去除segment分段锁的概念,改用cas+sync的方式实现concurrentHashMap,当多个线程锁定一个数组的下标的时候,让多个线程进行cas
自旋抢锁,当抢到锁之后 直接进行写的操作,写的操作不能并发 需要结合sync完成数据的写入
















 1218
1218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











