







 本文详细介绍如何在VisualStudio2019环境下安装CUDA10.1和Cudnn7.6.4,以及如何通过调整环境变量和配置pip镜像源来优化TensorFlow-GPU1.15的安装过程。
本文详细介绍如何在VisualStudio2019环境下安装CUDA10.1和Cudnn7.6.4,以及如何通过调整环境变量和配置pip镜像源来优化TensorFlow-GPU1.15的安装过程。
安装 Visual Studio 2019下载地址
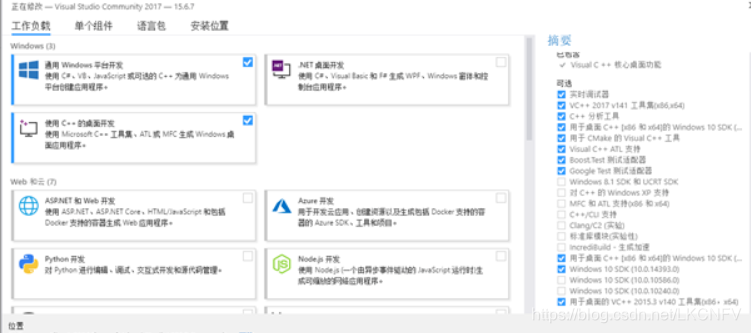
下载完成后点击exe,勾选通用Windows平台开发和使用c++的桌面开发,直到安装完成。
右键点击NVIDIA控制面板,进入帮助->系统信息,选择组件,查看NVCUDA.dll上写的CUDA版本号
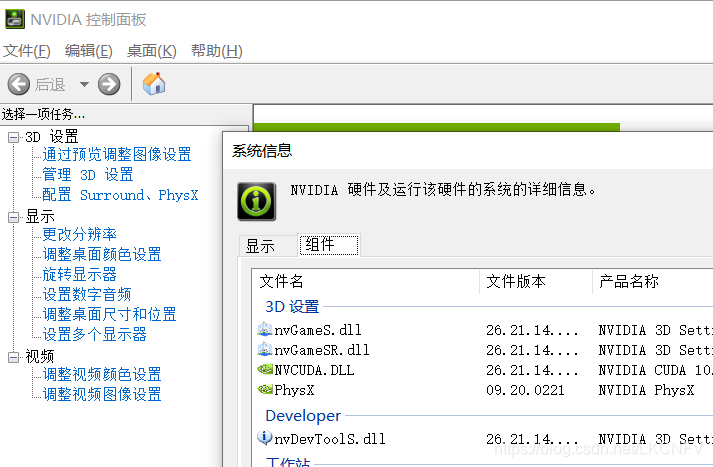
我的Nvdia控制面板上写的是CUDA10.1
我安装的是CUDA10.1和对应的Cudnn7.6.4(查看CUDA和Cudnn对应的版本,需要登陆一下)
CUDA默认安装路径:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
以上完成之后把以下四个路径加入到环境变量中:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\libnvvp
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\lib
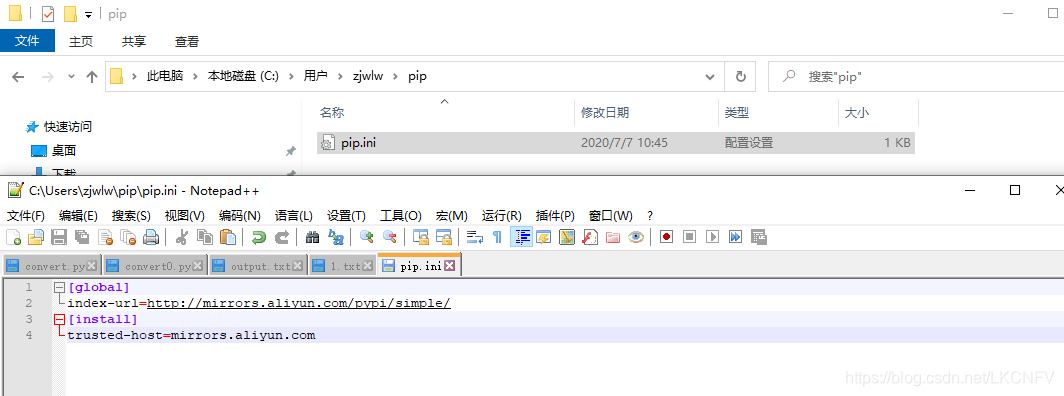
安装完成后,在C盘的用户目录下,选择你当前的用户进去新建文件夹pip,再在里面建立文件pip.ini,在里面设置镜像源和信任,如下
[global]
index-url=http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
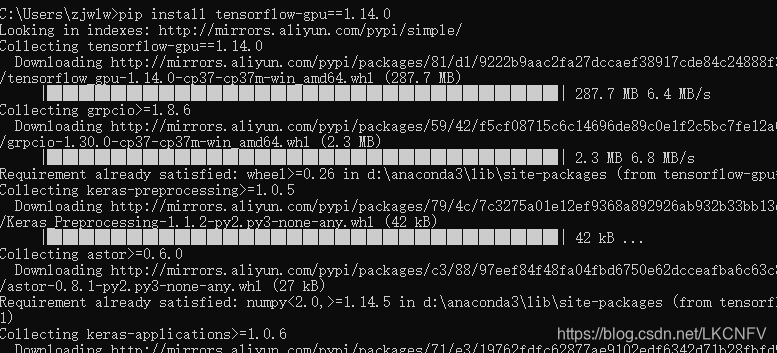
接下去在打开Anaconda Prompt输入,命令pip install tensorflow-gpu==1.15.0即可很快的完成安装
在测试时,发生了错误如下:
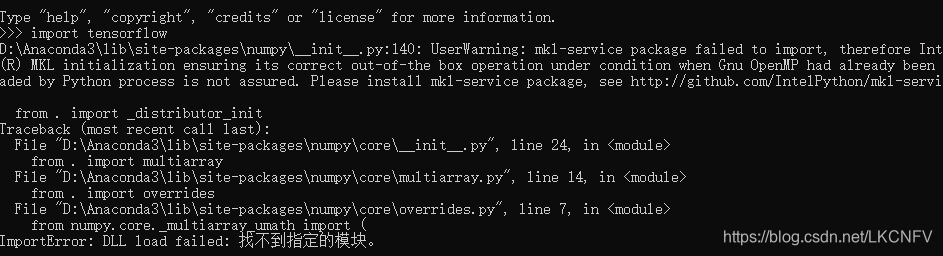
Traceback (most recent call last):
File "D:\Anaconda3\lib\site-packages\numpy\core\__init__.py", line 24, in <module>
from . import multiarray
File "D:\Anaconda3\lib\site-packages\numpy\core\multiarray.py", line 14, in <module>
from . import overrides
File "D:\Anaconda3\lib\site-packages\numpy\core\overrides.py", line 7, in <module>
from numpy.core._multiarray_umath import (
ImportError: DLL load failed: 找不到指定的模块。
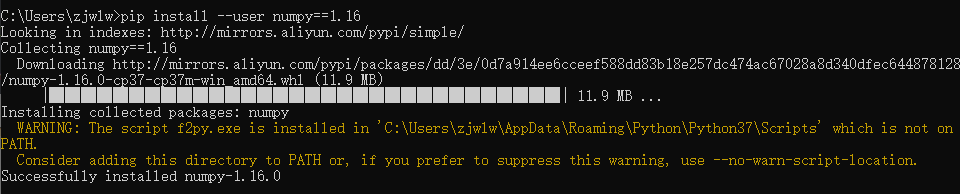
看着是numpy版本发生错误,于是我降低了版本:pip install --user numpy==1.16
由于一些不确定性我本身也不了解,一开始我安装1.14的版本出现了很多错误,比如ImportError: DLL load failed: 找不到指定的模块的问题
历程是直接pip install tensorflow-gpu,但是这个直接给你装2.2的新版本,由于想用旧版本,于是又pip uninstall tensorflow-gpu删除掉,换了博客上面说的1.15最终成功。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









