










哈希表
哈希表(HashTable)又叫散列表,是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表的做法其实很简单,就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字。把这个整型数字作为元素的下标存入数组(散列表),我们常用的算法有以下几种:
- 直接定址法
- 除留余数法
- 平方取中法
- 折叠法
- 数学分析法
- 随机数法
而这几种算法里面,最常用的还是前两种:
直接定址法——–>取关键字的某个线性函数为散列地址,Hash(Key)= Key 或Hash(Key)= A*Key + B,A、B为常数。
除留余数法——–>-取关键值被某个不大于散列表长m的数p除后的所得的余数为散列地址。Hash(Key)= Key%P。
不管是直接定址还是除留余数,这里肯定会存在一种情况——–>不同的key值经过处理后得到了相同的结果。我们称这种现象为哈希冲突(或者说哈希碰撞)。
当两个不同的元素经过哈希处理得到了相同的整型数据index,那么哪个元素该存入数组下标为index的位置上呢?另一个存放到哪呢?
哪里有压迫哪里就有斗争!哪里有冲突我们就要解决!
解决哈希冲突的办法:
闭散列方法(开放定址法)
它的核心思想就是把发生冲突的元素放到哈希表中的另一个位置。具体又可分为线性探测和二次探测。
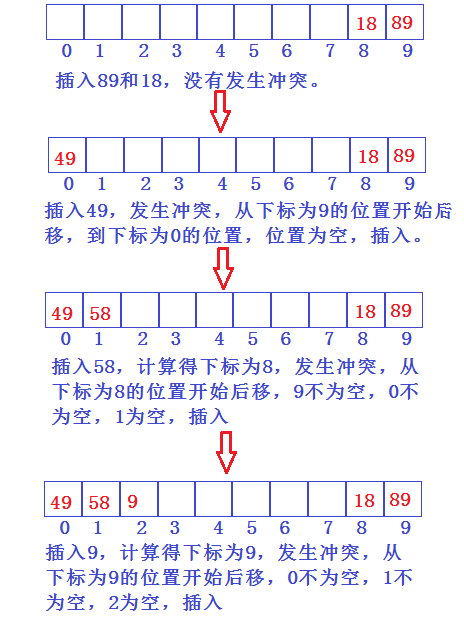
假设我们现在有一个哈希表table[10],大小为10。
将 89、18、49、58、9这5个key值插入table。(示例用除留余数法)
- 线性探测
线性探测要做的就是把发生冲突的元素插入从当前位置开始后移的第一个空位置。
我们用这几个key值分别模哈希表的大小10。得到每个应插入的下标。
89%10 = 9;
18%10 = 8;
49%10 = 9;
58%10 = 8;
9 % 10 = 9;
从上式可以看出89、49、9这三个元素发生冲突,18、8这两个发生冲突。
插入过程如图:
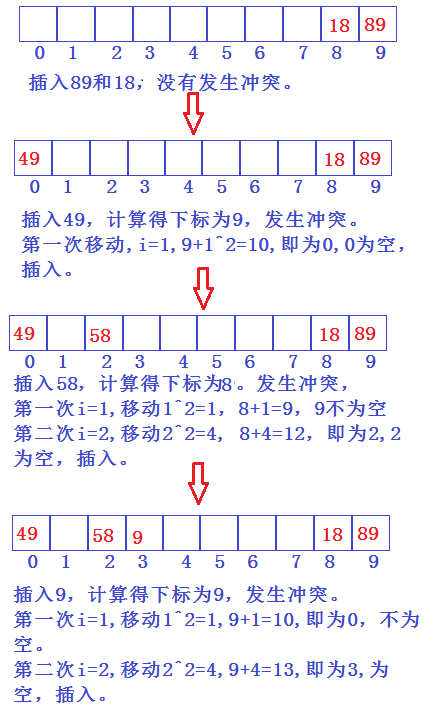
二次探测
二次探测的大致思想与线性探测相同,不同之处在于后移过程中它移动的大小为后移次数的平方。我们设后移的次数为i。
仍为上述条件:
针对闭散列方法(开放定址法),载荷因子的概念就显得特别重要。
散列表(哈希表)的载荷因子α =插入表中元素个数/散列表的长度。
α是散列表装满程度的标志因子。由于表长的定值,α与“填入表中元素个数”成正比,α越大,表明填入表中的元素越多,产生冲突的可能性就越大;反之,α越小,表明填入表中的元素越少,产生冲突的可能性就越小。
对于闭散列方法,载荷因子是特别重要的元素,应严格限制在0.7~0.8以下。没超过0.8,查表时的CPU缓存不命中按照指数曲线上升。因此,每当载荷因子超出范围,都应该resize散列表(扩容)。
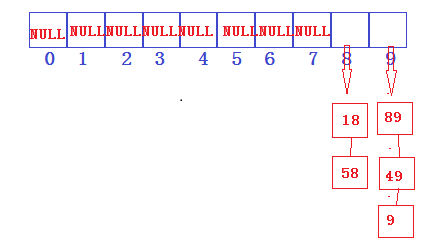
开散列方法(拉链法或叫开链法)
实现原理就是将哈希表变成一个指针数组。每次发生冲突,九江发生冲突的元素链到当前位置下。
仍未上述条件,处理完结果如图:
闭散列方法(线性探测)
#include<iostream>
#include<vector>
using namespace std;
enum STATE
{
EMPTY,
EXSIT,
DELETE
};
template<typename K>
struct __Hashfunc
{
size_t operator()(const K& key)
{
return key;
}
};
//特化
template<>
struct __Hashfunc<string>
{
public:
size_t operator()(const string& k)
{
return BKDRHash(k.c_str());
}
private:
//字符串哈希处理算法
static size_t BKDRHash(const char* str)
{
unsigned int seed = 131;// 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str)
{
hash = hash*seed + (*str++);
}
return(hash & 0x7FFFFFFF);
}
};
template<typename K, typename V>
struct HashNode
{
K _key;
V _value;
STATE _sta;
HashNode(const K& key = K(), const V& value = V())
:_key(key)
, _value(value)
, _sta(EMPTY)
{}
};
template<typename K, typename V, typename __HashFunc = __Hashfunc<K>>
class HashTable
{
typedef HashNode<K, V> Node;
public:
HashTable()
:_size(0)
{
_table.resize(GetPrimenum(0));
}
bool Insert(const K& key, const V& value)
{
CheckSize();
size_t index = Getindex(key);
while (_table[index]._sta == EXSIT)
{
if (_table[index]._key == key)
{
_table[index]._value++;
return false;
}
if (index == _table.size() - 1)
{
index = 0;
}
++index;
}
_table[index]._key = key;
_table[index]._value = value;
_table[index]._sta = EXSIT;
_size++;
return true;
}
void Swap(HashTable<K, V>& hash)
{
this->_table.swap(hash._table);
swap(_size, hash._size);
}
Node* Find(const K& key)
{
size_t index = Getindex(key);
while (_table[index]._sta == EXSIT)
{
if (_table[index]._key == key)
{
return &_table[index];
}
if (index == _table.size() - 1)
{
index = 0;
}
++index;
}
return NULL;
}
bool Remove(const K& key)
{
size_t index = Getindex(key);
while (_table[index]._sta == EXSIT)
{
if (_table[index]._key == key)
{
_table[index]._sta = DELETE;
_size--;
return true;
}
if (index == _table.size() - 1)
{
index = 0;
}
++index;
}
return false;
}
protected:
size_t Getindex(const K& key)
{
//return key%_table.size();
__HashFunc h;
return h(key) % _table.size();
}
size_t GetPrimenum(const size_t& sz)
{
const int Primesize = 28;
static const unsigned long Primenum[Primesize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul,
786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul,
25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul,
805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
for (int i = 0; i < Primesize; ++i)
{
if (Primenum[i] > sz)
{
return Primenum[i];
}
}
return sz;
}
void CheckSize()
{
if (_table.size() == 0 || _size * 10 / _table.size() >= 8)
{
HashTable<K, V> NewHash;
NewHash._table.resize(GetPrimenum(_table.size()));
for (size_t i = 0; i < _table.size(); ++i)
{
NewHash.Insert(_table[i]._key, _table[i]._value);
}
this->Swap(NewHash);
}
}
protected:
vector<Node> _table;
size_t _size;
};开散列方法(拉链法)
#include<iostream>
#include<vector>
using namespace std;
//特化
template<>
struct __Hashfunc<string>
{
public:
size_t operator()(const string& k)
{
return BKDRHash(k.c_str());
}
private:
//字符串哈希处理算法
static size_t BKDRHash(const char* str)
{
unsigned int seed = 131;// 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str)
{
hash = hash*seed + (*str++);
}
return(hash & 0x7FFFFFFF);
}
};
template<typename K, typename V>
struct HashNode
{
K _key;
V _value;
HashNode<K, V>* _next;
HashNode(const K& key, const V& value)
:_key(key)
, _value(value)
, _next(NULL)
{
}
};
template<typename K, typename V, typename __HashFunc = __Hashfunc<K>>
class HashTable
{
typedef HashNode<K, V> Node;
public:
HashTable()
:_size(0)
{
_tables.resize(GetPrimenum(0));
}
bool Insert(const K& key, const V& value)
{
CheckSize();
size_t index = Getindex(key, _tables.size());
Node* cur = _tables[index];
Node* parent = NULL;
if (_tables[index] == NULL)
{
_tables[index] = new Node(key, value);
_size++;
return true;
}
while (cur)
{
if (cur->_key == key)
{
cur->_value++;
_size++;
return true;
}
cur = cur->_next;
}
Node* newNode = new Node(key, value);
newNode->_next = _tables[index];
_tables[index] = newNode;
_size++;
return true;
}
Node* Find(const K& key)
{
size_t index = Getindex(key, _tables.size());
if (_tables[index] == NULL)
return NULL;
Node* cur = _tables[index];
while (cur)
{
if (cur->_key == key)
return cur;
cur = cur->_next;
}
return NULL;
}
bool Delete(const K& key)
{
size_t index = Getindex(key, _tables.size());
if (_tables[index] == NULL)
{
return false;
}
Node* cur = _tables[index];
Node* parent = NULL;
if (cur->_key == key)
{
cur = cur->_next;
}
while (cur)
{
if (cur->_key == key)
{
if (cur->_next == NULL)
{
parent->_next = NULL;
}
else
{
parent->_next = cur->_next;
}
break;
}
parent = cur;
cur = cur->_next;
}
if (cur)
{
delete cur;
cur = NULL;
return true;
}
return false;
}
void Print()
{
for (size_t i = 0; i < _tables.size(); ++i)
{
printf("tables[%d]->", i);
Node* cur = _tables[i];
while (cur)
{
cout << cur->_key << "->";
cur = cur->_next;
}
cout << "NULL" << endl;
}
}
protected:
void CheckSize()
{
if (_tables.size() == 0 || _size / _tables.size() >= 1)
{
vector<Node*> Newtable;
Newtable.resize(GetPrimenum(_tables.size()));
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
_tables[i] = next;
size_t index = Getindex(cur->_key, Newtable.size());
Node* tmp = Newtable[index];
Newtable[index] = cur;
cur->_next = tmp;
cur = next;
}
}
//this->_size = Newtable.size();
this->_tables.swap(Newtable);
}
}
size_t Getindex(const K& key, const size_t& size)
{
//return key%_table.size();
__HashFunc h;
return h(key) % size;
}
size_t GetPrimenum(const size_t& sz)
{
const int Primesize = 28;
static const unsigned long Primenum[Primesize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul,
786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul,
25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul,
805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
for (int i = 0; i < Primesize; ++i)
{
if (Primenum[i] > sz)
{
return Primenum[i];
}
}
return sz;
}
protected:
vector<Node*> _tables;
size_t _size;
};
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









