







一般场景的唯一ID我们都可以使用数据库的自增主键来实现,但是当数据量过大的时候,一张表无法承载那么大的数据量,我们就需要使用分库分表的技术方案,此时如果多张表需要不能重复的主键,就需要使用到我们今天所讲的分布式唯一ID生成方案了。简单来说,就是需要一个特定规则的发号器来给你的分布式系统生成唯一ID
-
UUID
JDK自带的UUID功能就可以生成一个唯一的ID,也没有并发的压力,但是这种方案生成的唯一ID非常长,而且无序,这样就会产生一个很严重的问题,导致数据库经常会进行页分裂。因为数据库的索引查询是基于有序的主键来的,无序的主键就会经常发生页分裂,降低数据库的性能,页分裂具体的细节可以查看我之前的博客(图解MySQL页分裂) -
Redis自增
Redis本身有自增的方法incrby,可以指定要增加的步长,同时天然支持高并发。在使用的时候,我们可以进行Redis的集群部署,有多少台机器就可以指定多少的步长。比如3台机器组成的集群,步长就是3,第一台机器生成的主键ID就是1,4,7…,第二台机器生成的主键ID就是2,5,8…,第三台机器生成的主键ID就是3,6,9…,以此类推
这个方案看起来很美好,但是实际使用的时候也存在一些问题,比如说在机器伸缩的时候,这个步长需要动态进行调整,需要额外的开发量,同时Redis集群进行数据同步的时候,也可能存在一些极端的场景导致主键ID重复,比如leader生成了主键ID但是还未同步至slave就发生了宕机,此时slave就会产生重复的主键ID -
时间戳 + 业务ID
举个例子,比如说在生成订单ID的时候,就可以使用时间戳 + 客户ID + 商品ID或者再加上一些其他的业务ID共同来组成我们需要的唯一ID,这种方式生成唯一ID简单方便,而且也不会存在其他的并发或者性能问题,只要能保证当前业务场景下生成的ID是唯一的话,那么这个方案应该是第一优先级被考虑的 -
数据库自增主键
既然不能用本身这张表的数据库的自增主键来生成的话,那么是不是可以单独从一个库里拿出一张表,就干生成主键ID的事情,这样做的话其实也很简单,不需要额外的开发成本。但是这个方案最大的缺点就是单库单表的并发量不会很高,无法支持高并发的场景,而且这张表一直生成唯一ID数据的话,最后历史数据会越来越多,需要定时清理(之所以将这种方式放这里讲,是为了和下面的方案进行一个对比) -
flickr(雅虎旗下的图片分享平台)的数据库唯一id生成方案
这种方式可以认为是使用数据库自增主键的一个变种方式,首先这种方式需要一个单独的数据库表
CREATE TABLE `id_generator` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`stub` char(1) NOT NULL default '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=MyISAM;
上面的建表语句非常常规,唯一需要注意的话,就是这里推荐使用MyISAM数据库引擎,而不是InnoDB,可以屏蔽掉一些数据库事务的相关影响
当我们有了这张表之后,要想获得我们需要的分布式唯一ID,就需要下面的SQL了
REPLACE INTO id_generator(stub) VALUES ('value');
SELECT LAST_INSERT_ID();
REPLACE INTO会生成一条新的数据,如果这条数据的value值存在的话,就会替代原先的数据,同时数据库的id还是会递增,这么做的好处就是不会再生成大量的insert数据,导致数据库表的数据太多,需要定时清理了,同时后面的value值我们可以进行自定义,比如说我们想生成订单的唯一ID,那么这个value我们可以指定为order,如果想生成库存的唯一ID就可以指定为stock等等,这样的话,这一张表就可以承载大量业务场景下的分布式唯一ID生成数据
查询分布式唯一ID的语句中的last_insert_id()函数是connection级别的,就是这个连接的最近insert生成的id,多个客户端之间没影响,不会产生并发问题
这种方式一般都会配合MySQL双机高可用方案,两个库设置不同的起始ID和相同的步长,类似Redis的那种方式,比如说库A起始ID是1,步长为2,那么生成的ID就是1,3,5…,库B起始ID是2,步长也为2,生成的ID就是2,4,6…
- flickr高并发变种方案
flickr方式相比于传统的数据库自增主键,减少了单表生成的数据量,不用再去清理历史数据了,但是单库单表的并发限制还是依然存在,瓶颈就在最后获取唯一ID的那个select语句,所以又有了支持高并发的flickr变种方式
这种方式将之前查询唯一ID的方法变成了一个查询号段的方法,比如说我们查询出来了的结果是1,那么我们自定义一个号段的规则,起始号段就是结果1 * 10000,结束号段就是(1 + 1)* 10000,此时我们就得到了一个唯一ID号段[10000,20000)
我列一段伪代码来描述一下如何获取唯一ID
Integer n = 1; // 通过数据库查询的结果
volatile AtomicLong uniqueId = new AtomicLong(n * 10000);
volatile AtomicLong maxId = new AtomicLong((n + 1) * 10000);
volatile boolean needRefresh = false;
public Long idGenerator() {
uniqueId.incrementAndGet();
if (uniqueId >= maxId) {
// 如果needRefresh需要刷新的标记为true的话,就会再次去请求数据库查询新的号段
needRefresh = true;
Thread.sleep(10);
}
return uniqueId;
}
大致思路就是这样的,通过号段的方式来减少数据库的查询次数,从而提高并发量,在控制好号段边界的情况下不断取出号段中的值我们就能获得想要的唯一ID了
- Snowflake雪花算法
Snowflake是Twitter开源的分布式唯一ID生成方案,核心思想是有64个bit位,最高位1个bit是0,41位放时间戳(到毫秒单位,最多使用69年),10位放机器标识(最多部署在1024台机器上,当然这个地方也可以分机房和机器,比如前5位代表机房标识,后5位代表机器标识),12位放序号(每毫秒,每台机器,可以顺序生成4096个ID)
我从网上找了一张图,看起来应该会更直观一点
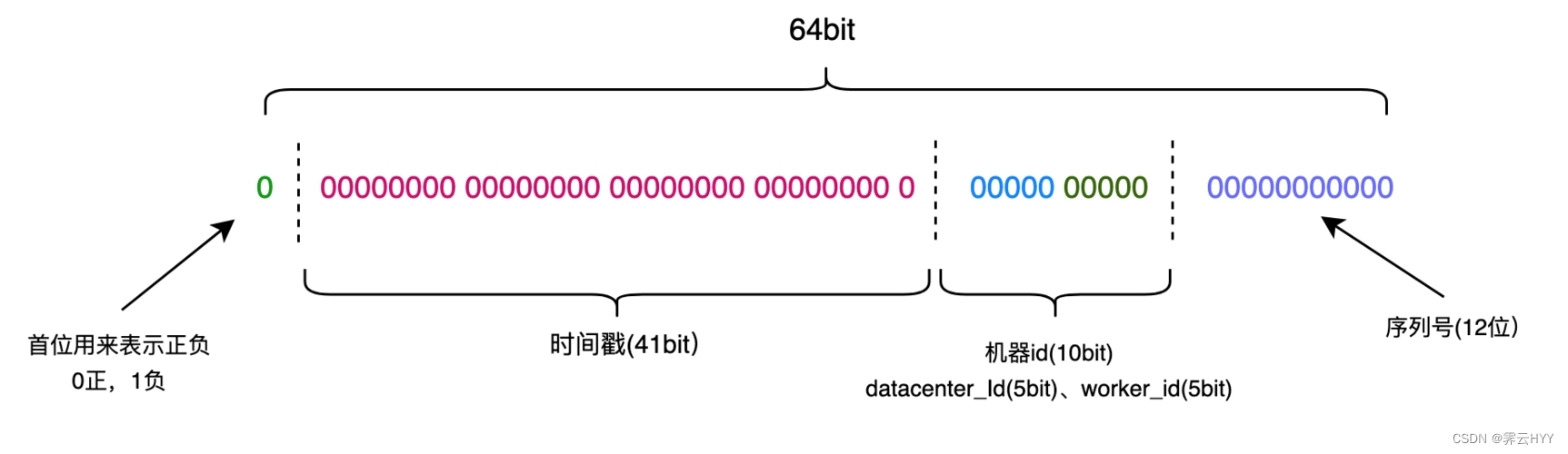
整个snowflake的核心逻辑也就是几十行,非常简单,使用起来也很方便,跟我们上面讲的那些方案比较起来算是非常简单的了,但是里面有一个很致命的问题,就是时钟回拨
时钟回拨就是多台机器进行了一个时间同步,比如机器A的时间比其他的机器都快了5s,那么它就需要进行时钟回拨来校准时间,snowflake算法中最长的那一部分就是代表的时间戳,那万一机器A回拨之后在同样的时间生成了唯一ID,那么就有可能会导致这个ID重复
要解决这个问题的话,首先得记录下上一次生成ID的时间,然后针对时钟回拨的时间长短分几种不同的情况:
- 如果时间回拨的时间比较短,比如说小于300ms的话,这个时间业务等得起,那么可以让获取唯一ID的线程稍微等一下,等到时间比上一次生成ID的时间大的话,此时再去获取ID就不会重复了
- 如果这个时间适中,比如说在300ms~1min之内,那么可以让获取唯一ID的线程不要访问这台机器了,去访问其他的机器来获取(毕竟不可能单机部署吧,这样太容易单点故障了)
- 如果这个时间太长了,比如说大于1min了,那么这个时候可以让这个机器先暂时下线(从服务注册中心里面剔除),让其他的线程也都先别去请求这台机器了,等过一段时间时钟回拨的影响消除了,再让服务注册中心能够发现这台机器,重新提供生成唯一ID的服务
如果时间回拨的时间很短(一般场景下都是很短的,几百毫秒之内)且实在不想等待的话,还有一个办法就是在最近几秒内每一毫秒生成的最大ID都记录下来,当发生时钟回拨时,直接在当前毫秒内生成的最大ID基础上再进行递增,也能保证ID唯一















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









