







提纲:本文主要介绍了C语言中的词法规则,包括字符、注释、接续符、标识符
一、字符
1、字符集都包括什么?
标准规定字符集包括英语所有的大写字母和小写字母、数字0~9、以及! ” # % ’ * + , - . / : ; = ? \ ^ _ | ~ <> {} () []等符号。
2、分类
(1)普通字符
由单引号括起来的一个字符;
(2)字符串常量
由双引号将若干个字符括起来;
(3)符号常量
用一个符号名代表一个常量的,称为符号常量;
例如:#define A 1
上面的代码表示,凡是程序中出现A的地方全部替换成1
(4)三字母词(9个)
三字母词是三个字符的序列,合起来表示一个字符,通常在C环境缺少字符的情乱下使用
常见的9个三字母词:
??( 代表 [
??) 代表 ]
??! 代表 |
??< 代表 {
??> 代表 }
??’ 代表 ^
??= 代表 #
??/ 代表 \
??- 代表 ~
(5)转义字符(13个)
当一个字符在一个编程环境中有特殊的意义,而想要使用这个特定的字符时,可能没有办法实现,这时候就提出了转义字符的概念。
下面列出了常见的13个转义字符
\’ 输出字符’
\” 输出字符”
\? 输出字符?
\ 输出字符\
\a 发出警告声音
\b 将当前位置后退一个字符

该程序的输出结果为

\f 将当前位置移动到下一页的开头

该程序的输出结果为

\n 换行符,将当前结果移动到下一行的开头
\r 回车符,将当前的位置移动到本行的开头
\t 水平制表符,将当前位置移动到下一个tab位置
\v 垂直制表符,将当前位置移动到下一个垂直制表对齐处
\ddd 其中一个d代表一个八进制数字,该输出结果是与八进制码对应的字符
\xddd 其中一个d代表一个十六进制数字,该输出结果是与十六进制码对应的字符
二、注释
1、注释方式
C语言中有两种注释方式
(1)/**/
(2)//
2、注释原则
(1)编译器剔除掉注释之后,会用空格来替换原有的注释位置。
(2)编译器把/当作一段注释的开始,将/后面的内容都当作注释内容,直到出现*/为止,表示注释结束。
(3)/总是与离他最近的/进行匹配。
(4)注释/**/不允许嵌套。
(5)只要/和*之间没有空格,编译器就会把他当作注释的开始。
(6)对加注释的几点建议
注释应当简洁明了;
一目了然的代码不加注释;
注释采用英文;
注释可以在代码的同行或者上一行,但不能在代码的下一行。
(7)哪些地方十分有必要加注释
对于全局变量必须加注释;
数值的单位一定要加注释;
对变量的范围给出注释;
对函数的入口出口数据给注释。
三、接续符
C语言中以\表示断行,编译器会自动将\剔除掉,跟在\后面的内容会自动接续到前一行
注:\之前和之后都不能有空格。
四、标识符
标识符就是函数、变量、类型等的名字
1、命名规则
标识符由大小写字母、数字、下划线组成,不能以数字开头。
2、注意事项
(1)标识符虽然没有长度限制,但是编译器会自动忽略第31个字符后面的字符;
(2)ANSI C标准规定,C实现必须能够区别出前6个字符不同的外部名称(由链接器操纵的名字),而且,这个定义中不区分英语字母的大小写。
(3)内部名和外部名
ANSI C标准规定,标识符可以为任意长度,但外部名必须至少能由前6个字符唯一地区分,并且不区分大小写。这里外部名指的是在链接过程中所涉及的标识符,其中包括文件间共享的函数名和全局变量名;
ANSI C标准还规定,内部名必须至少能由前31个字符唯一地区分。内部名指的是仅出现于定义该标识符的文件中的那些标识符。C语言中的字母是有大小写区别的,因此count Count COUNT是三个不同的标识符。
(4)标识符不能和C语言的32个关键字相同,也不能和用户已编制的函数或C语言库函数同名。
(5)看一个关于标识符例题
例:\40的值是多少?\100、\x40、\x100、\0123、\x0123的值又分别是什么?
我们分别将这些例子运行一下:
\40的值

分析:\ddd代表的是八进制数,将其转换为十进制数再查询ASCII表,便可以得到正确结果
八进制数40转换为十进制数是32,通过ASCII字符集查询到是空格字符,因此输出结果为空格;
\100和\x40的值

分析:八进制数100和十六进制数40转换为十进制数是64,通过ASCII字符集查询到是字符@,因此输出结果为@;
\x100的值
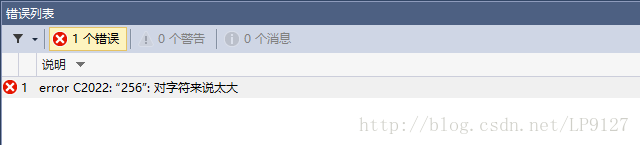
分析:由图可知,十六进制数100超出了ASCII所能表示的范围,因此出错;
\0123的值

分析:由图可知,输出的结果为一个空行加上数字3,\0123是将其看成\012和3,所以打印结果为\n3,即换行和3;
\x0123
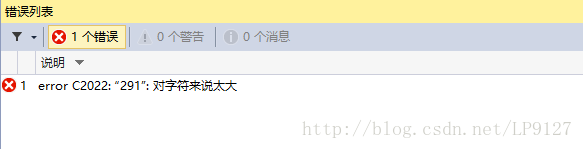
分析:在VS2013下,因为超出ASCII编码范围而出错;
但是在有的编译器下,对于\x0123,二进制数为0000 0001 0010 0011,舍弃高八位,只表示低八位,ascll码为35,即为 #。
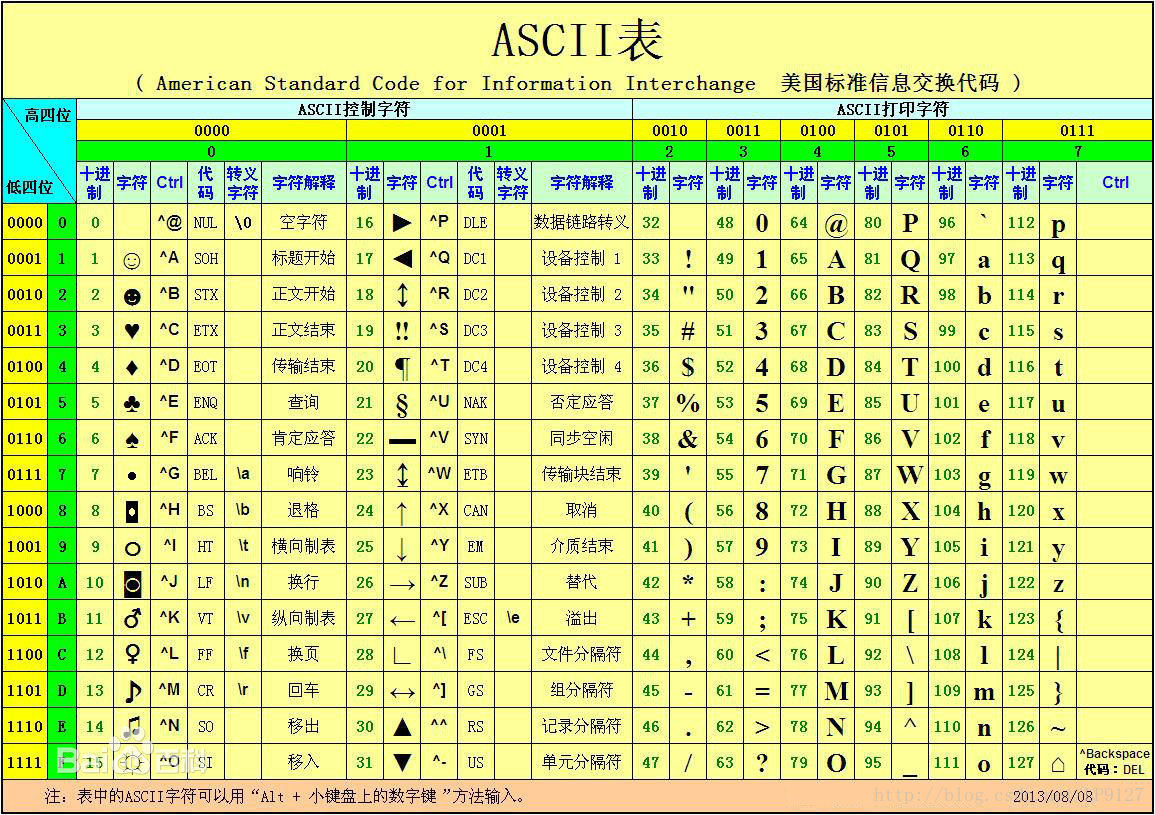
最后附上ASCII编码表:















12-11
 5325
5325
5325
04-09
1万+
1万+
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









