







分布式搜索引擎ElasticSearch
一、ElasticSearch部署与启动
下载ElasticSearch 5.6.8版本
https://www.elastic.co/downloads/past-releases/elasticsearch-5-6-8
无需安装,解压安装包后即可使用,和Tomcat比较类似。
在命令提示符下,进入ElasticSearch安装目录下的bin目录,执行命令
Windows下
直接点击 elasticsearch.bat 即可开启
Linux下执行
elasticsearch
我们打开浏览器,在地址栏输入http://127.0.0.1:9200/ 即可看到输出结果
{ "name" : "EIyQ3pY", "cluster_name" : "elasticsearch", "cluster_uuid" : "IFloaTjNTha5pztOoTeVEA", "version" : { "number" : "5.6.8", "build_hash" : "688ecce", "build_date" : "2018-02-16T16:46:30.010Z", "build_snapshot" : false, "lucene_version" : "6.6.1" }, "tagline" : "You Know, for Search" }
上面代码中,请求9200端口,Elastic 返回一个 JSON 对象,包含当前节点、集群、版本等信息。
按下 Ctrl + C,Elastic 就会停止运行。
默认情况下,Elastic 只允许本机访问,如果需要远程访问,可以修改 Elastic 安装目录的config/elasticsearch.yml文件,去掉network.host的注释,将它的值改成0.0.0.0,然后重新启动 Elastic。
network.host: 0.0.0.0
上面代码中,设成0.0.0.0让任何人都可以访问。线上服务不要这样设置,要设成具体的 IP。
二、基本概念
2.1 Node 与 Cluster
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。
单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
2.2 Index
Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
下面的命令可以查看当前节点的所有 Index。
$ curl -X GET 'http://localhost:9200/_cat/indices?v'
2.3 Document
Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
Document 使用 JSON 格式表示,下面是一个例子。
{ "user": "张三", "title": "工程师", "desc": "数据库管理" }
同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
2.4 Type
Document 可以分组,比如weather这个 Index 里面,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。
不同的 Type 应该有相似的结构(schema),举例来说,id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的一个区别。性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。
下面的命令可以列出每个 Index 所包含的 Type。
$ curl 'localhost:9200/_mapping?pretty=true'
根据,Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
三、基本操作
我们下面使用PostMan进行操作,采用Restful风格API
3.1 新建和删除 Index(索引)
我们要创建一个叫articleindex的索引 ,就以put方式提交
http://127.0.0.1:9200/articleindex/
成功则返回
{ "acknowledged": true, "shards_acknowledged": true, "index": "articleindex" }
同样如果我们要删除 articleindex的索引 ,就以delete方式提交
http://127.0.0.1:9200/articleindex/
成功则返回
{
"acknowledged": true
}
3.2 Document(文档)操作-(增删改查)
3.2.1 新建document
以post方式提交 http://127.0.0.1:9200/articleindex/article
body
{ "title":"SpringBoot", "content":"SpringBoot有重大更新" }
返回
{ "_index": "articleindex", "_type": "article", "_id": "AWr1D6-t30bC6S1aaH1n", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "created": true }
由于我们没有指定id,所以自动生成了 _id 为 AWr1D6-t30bC6S1aaH1n 。
当然我们也可以自己定义id 如下:
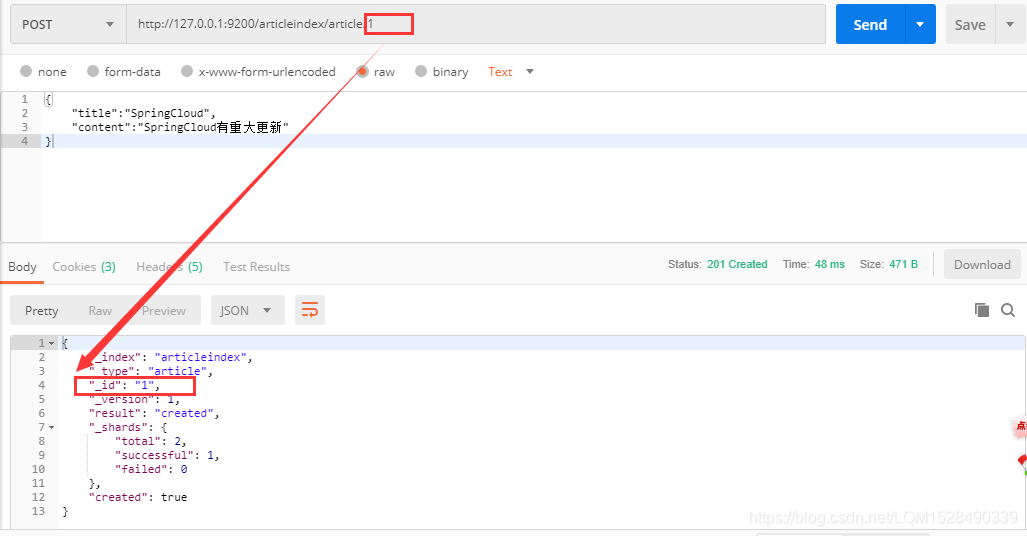
3.2.2 查询document
我们要查询所有文档,我们以 get 方式请求 http://127.0.0.1:9200/articleindex/article/_search
其中 _search 为查询所有。
按id查询,我们以 get 方式请求 http://127.0.0.1:9200/articleindex/article/1
返回
{ "_index": "articleindex", "_type": "article", "_id": "1", "_version": 1, "found": true, "_source": { "title": "SpringCloud", "content": "SpringCloud有重大更新" } }
3.2.3 基本匹配查询
下面我们根据 title 进行查询,采用 get 方式请求
http://127.0.0.1:9200/articleindex/article/_search?q=title:SpringCloud
我们可以看到查询结果。
3.2.4 模糊匹配查询
我们根据 title 进行模糊查询,类似于MySQL中的 like ,这里使用 * 进行匹配任意字符。
http://127.0.0.1:9200/articleindex/article/_search?q=title:*S*
3.2.5 更新document
通过id进行操作,采用 put 方式请求
http://127.0.0.1:9200/articleindex/article/1
body
{
"title":"SpringBoot",
"content":"SpringBoot有重大更新"
}
3.2.6 删除document
根据ID删除文档,删除ID为1的文档 DELETE 方式提交
http://127.0.0.1:9200/articleindex/article/1














 1531
1531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









