






安装部署Hadoop完全分布式集群
- 准备3台 CentOS6.5操作系统(一台用来做Master节点,2台用来做Slave节点)
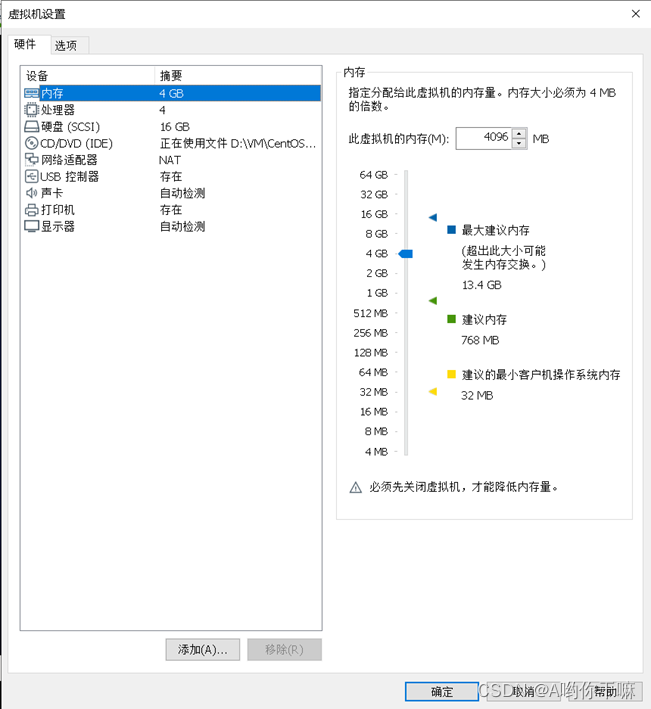
操作系统分区方案(每一台服务器磁盘空间统一分配16G,即16378M)
/ 6000M
/home 9000M
/boot 500M
/var 剩余所有
-
关闭防火墙(3台机器都需要)
service iptables stop
chkconfig iptables off
service network restart -
配置网络环境,保证三台集群之间的网络可以互通
3台虚拟机都进行 vim /etc/sysconfig/network-scripts/ifcfg-eth0
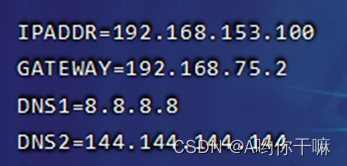
HadoopMaster添加下面内容:
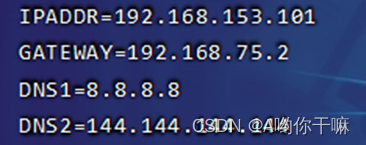
HadoopSlave01添加下面内容:
HadoopSlave02添加下面内容:
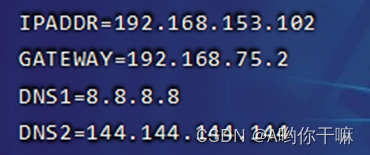
service network restart 后
ping www.baidu.com
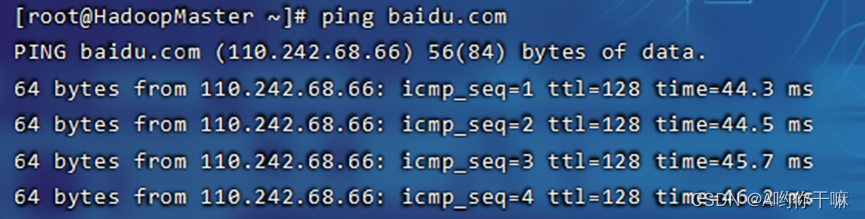
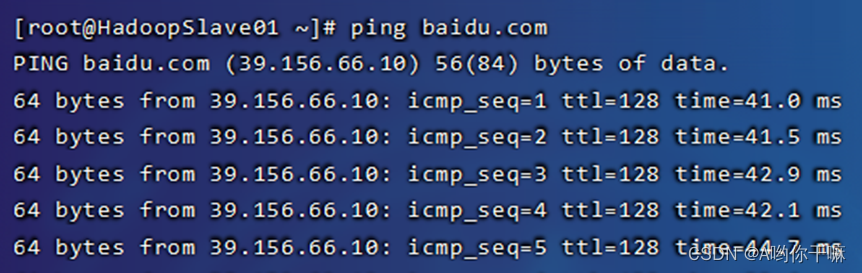
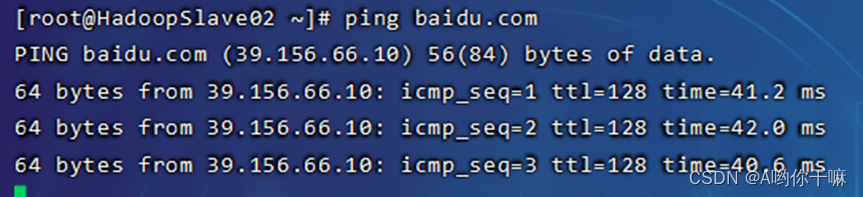
配置网络环境完成
- 修改主机名: vim /etc/sysconfig/network
source /etc/sysconfig/network (都source一下)
第一台叫:HadoopMaster
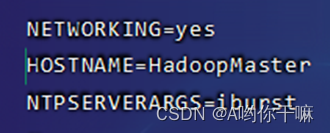
第二台:HadoopSlave01
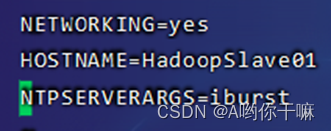
第三台:HadoopSlave02
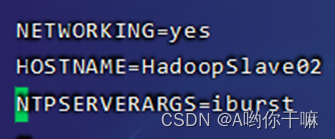
- 绑定/etc/hosts,IP和主机名
vim /etc/hosts
source /etc/hosts
(3台一样的操作)

- 创建普通用户hadoop
(3台都需要创建)
useradd hadoop
passwd hadoop
su hadoop


- 配置免密钥,保证HadoopMaster能ssh到两个Slave节点(HadoopSlave01,HadoopSlave02)
在HadoopMaster
ssh-keygen -t rsa
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
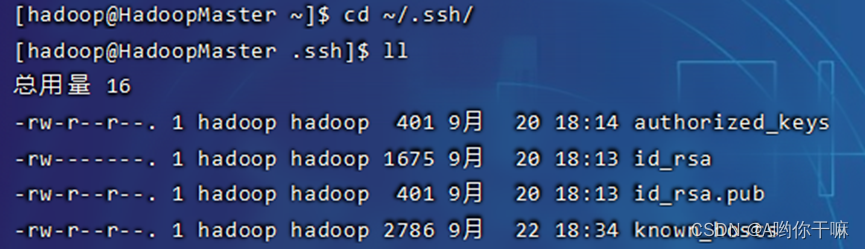
先免密 HadoopMaster 自己

然后 scp ~/.ssh/authorized_keys hadoop@HadoopSlaver01: ~/.ssh
scp ~/.ssh/authorized_keys hadoop@HadoopSlaver02: ~/.ssh
最后ssh 验证


记得 exit 退出
- 上传JDK和Hadoop安装包到hadoop@HadoopMaster /home/hadoop/software下并且解压
然后mkdir haooptmp
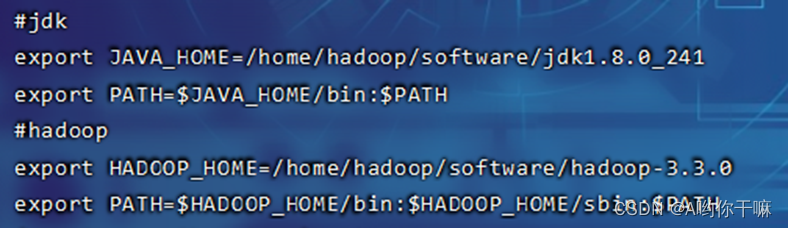
配置jdk hadoopd的环境变量(一样的操作,3台都要配置)
先到root用户,然后vim ~/.bash_profile(记得source)
回到hadoop用户然后验证
java
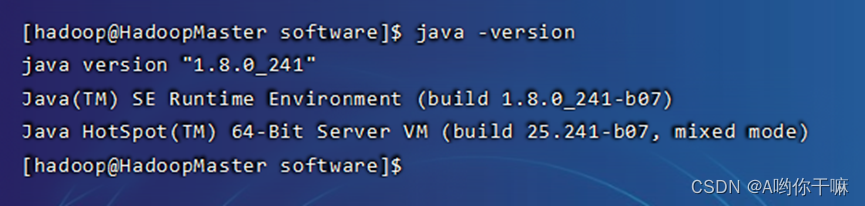
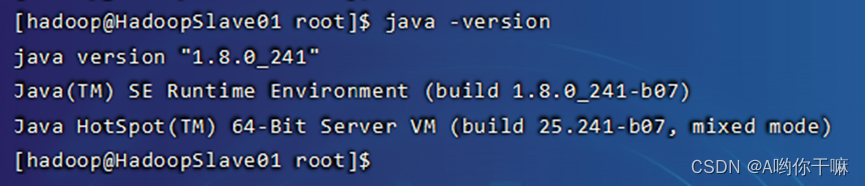

(如果版本和上传的不一致,就是虚拟机自带了java ,直接先 which java 找到路径,直接 rm -rf 删掉即可)
hadoop



- 配置6个配置文件和works文件
cd /home/hadoop/software/hadoop-3.3.0/etc/hadoop
1.hadoop-env.sh
vim hadoop-env.sh

2.yarn-env.sh

3.core-site.xml

4.hdfs-site.xml
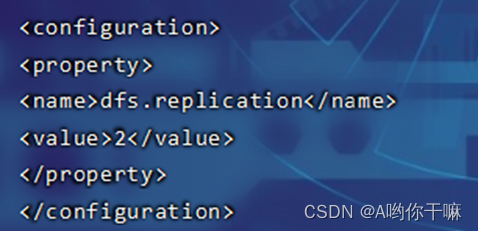
5.yarn-site.xml
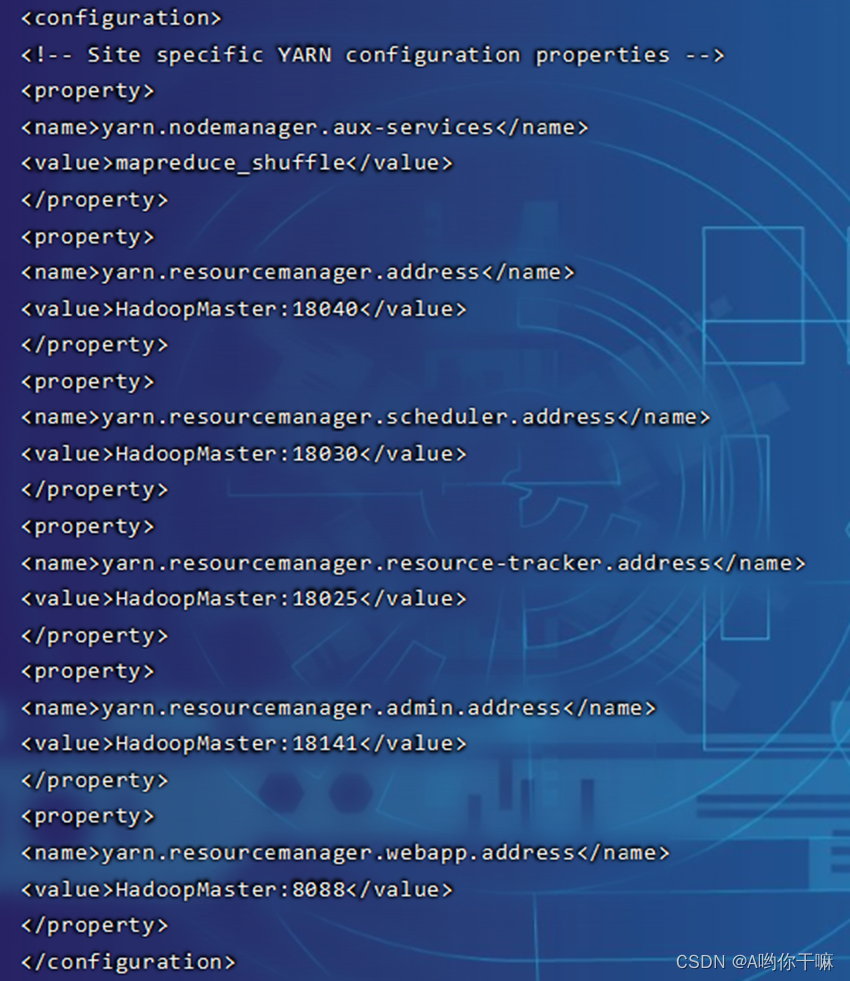
6.mapred-site.xml
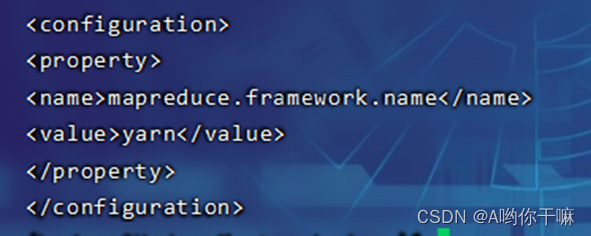
7.配置 works 文件

- 复制到从节点
使用下面的命令将已经配置完成的 Hadoop目录复制到从节点 Slave 上:
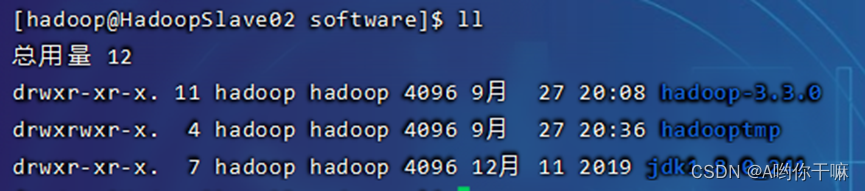
scp -r /home/hadoop/software/ hadoop@HadoopSlave01:~/software/
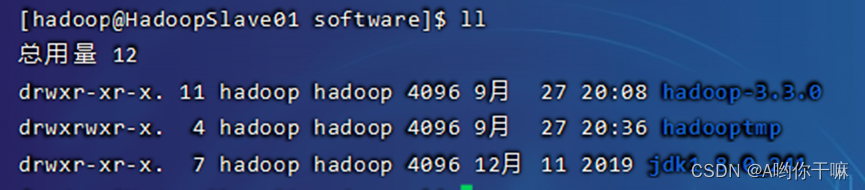
scp -r /home/hadoop/software/ hadoop@HadoopSlave02:~/software/
- 格式化NameNode文件系统
格式化命令如下,该操作需要在HadoopMaster 节点上执行:
hdfs namenode -format
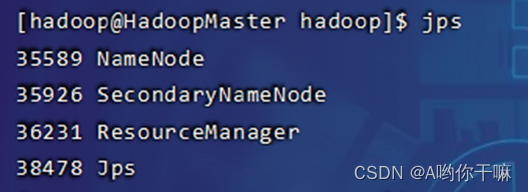
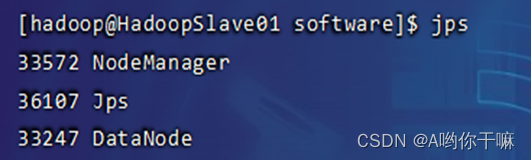
- 启动 Hadoop集群并验证
start-all.sh

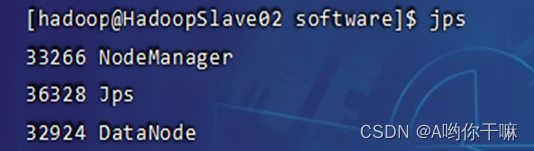
jps验证
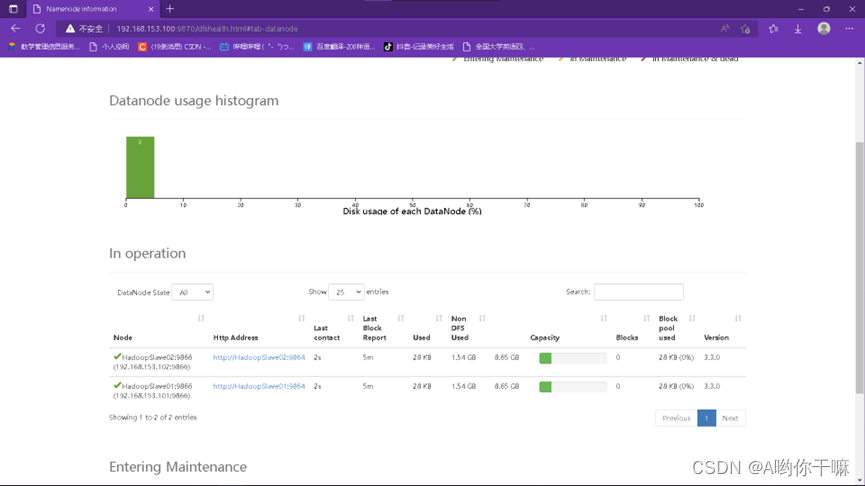
Web验证
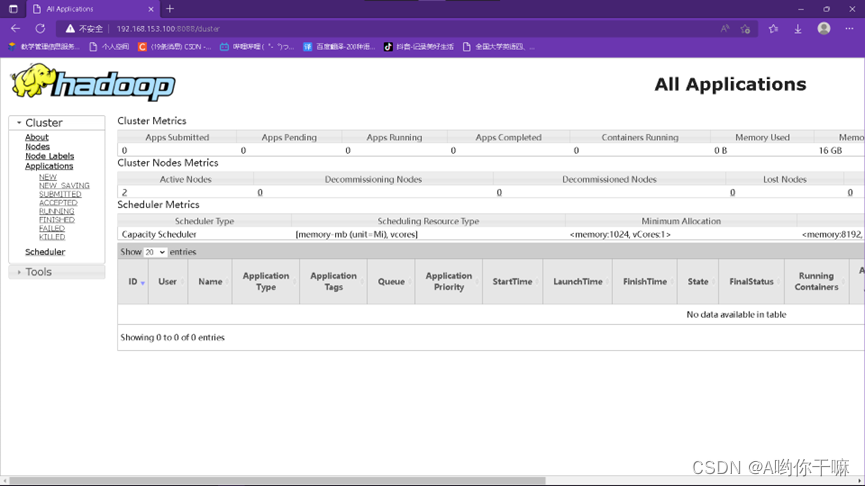
Hadoop完全分布式集群搭建完成















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









