






python3用requests模块爬取数据后得到一堆乱码
最近在学习爬虫,平时爬到的中文都是正常的,但今天爬完后得到的却是乱码

接着搜索了很多解决办法,最多的办法就是检查网页所用的编码方式,可以在网页中右键点击 检查(或F12)→在窗口console标签下,键入 “document.charset” 。即可查看编码方式。或者在爬取到的网页中有显示,如图一所示。于是我就用了response.encode(‘utf-8’)最后得到的结果如图二所示。
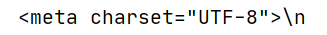
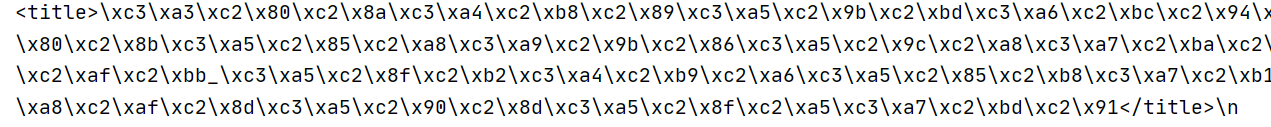
最后,使用的方法是responseencode(“raw_unicode_escape”).decode(“utf-8”)成功解决!!!
如下图所示















 3226
3226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









