







最近学Nodejs时候,就做了一个简单的网络爬虫来练下手,就是提取如下图博客主页的10条最新评论,
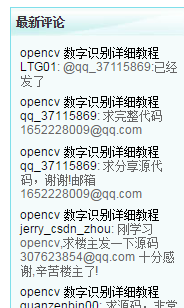
要抓取网页信息首先要获取博客主页的HTML信息,使用http.get(options[, callback])方法获取信息,代码如下:
http.get(url,function(res){
var html=''
res.on('data',function(data){
html+=data
})
res.on('end',function(){
console.log(html)
})
}).on('error',function(){
console.log('获取失败!')
})
<div id="newcomments" class="panel">
<ul class="panel_head"><span>最新评论</span></ul>
<ul class="panel_body itemlist">
<li>
<a href="/ltg01/article/details/50492556#comments">opencv 数字识别详细教程</a>
<p style="margin:0px;"><a href="/LTG01" class="user_name">LTG01</a>:
@qq_37115869:已经发了
</p>
</li>
<li>
<a href="/ltg01/article/details/50492556#comments">opencv 数字识别详细教程</a>
<p style="margin:0px;"><a href="/qq_37115869" class="user_name">qq_37115869</a>:
求完整代码1652228009@qq.com
</p>
</li>
<li>
<a href="/ltg01/article/details/50492556#comments">opencv 数字识别详细教程</a>
<p style="margin:0px;"><a href="/qq_37115869" class="user_name">qq_37115869</a>:
求分享源代码,谢谢!邮箱1652228009@qq.com
</p>
</li>
<li>
<a href="/ltg01/article/details/50492556#comments">opencv 数字识别详细教程</a>
<p style="margin:0px;"><a href="/jerry_csdn_zhou" class="user_name">jerry_csdn_zhou</a>:
刚学习opencv,求楼主发一下源码307623854@qq.com 十分感谢,辛苦楼主了!
</p>
</li>
<li>
<a href="/ltg01/article/details/50492556#comments">opencv 数字识别详细教程</a>
<p style="margin:0px;"><a href="/guanzenbin00" class="user_name">guanzenbin00</a>:
求源码,非常感谢 155293190@qq.com
</p>
</li>
<li>
<a href="/ltg01/article/details/50492556#comments">opencv 数字识别详细教程</a>
<p style="margin:0px;"><a href="/dream_tianyi" class="user_name">dream_tianyi</a>:
@dream_tianyi:楼主效率极高,谢谢,不胜感激~
</p>
</li>
<li>
<a href="/ltg01/article/details/50492556#comments">opencv 数字识别详细教程</a>
<p style="margin:0px;"><a href="/weixin_37725857" class="user_name">weixin_37725857</a>:
楼主,求源代码,菜鸟面临毕设,需要参考一下,感激不尽!1825011050@qq.com
</p>
</li>
<li>
<a href="/ltg01/article/details/50492556#comments">opencv 数字识别详细教程</a>
<p style="margin:0px;"><a href="/dream_tianyi" class="user_name">dream_tianyi</a>:
楼主您好,我这段时间正好在解决一个OCR的小问题,对这方面不太了解,看了您的这篇文章,豁然开朗。能否...
</p>
</li>
<li>
<a href="/ltg01/article/details/50492556#comments">opencv 数字识别详细教程</a>
<p style="margin:0px;"><a href="/heihahu" class="user_name">heihahu</a>:
楼主你好,正在opencv相关的东西,你的观点很清晰,我正在依照你的观点来实现程序,不过你那里有一个...
</p>
</li>
<li>
<a href="/ltg01/article/details/50492556#comments">opencv 数字识别详细教程</a>
<p style="margin:0px;"><a href="/qq_37688955" class="user_name">qq_37688955</a>:
楼主,你的代码很清楚,很详细,受益匪浅,本人学生,最近在做这个相关的一个课程设计,希望楼主能发一份源...
</p>
</li>
</ul>
</div>
</div>在做网页爬虫时候需要安装cheerio库, 了解更多cheerio其安装方法为 npm install cheerio 若出现问题则参考 安装问题 ,安装好后
通过Cheerio,我们需要把HTML document 传进去。
这是首选:
var cheerio = require('cheerio'),
$ = cheerio.load('<ul id="fruits">...</ul>');function filterChaper(html){
var $=cheerio.load(html)
var chapters=$('#newcomments')
var courseData=[]
chapters.each(function(item){
var chapter =$(this)
var videos=chapter.find('.panel_body').children('li')
videos.each(function(){
var video=$(this).find('p')
var videoTitle=video.text()
courseData.push(videoTitle)
})
})
return courseData
}
function printCourseData(courseData){
courseData.forEach(function(item){
console.log(item)
})
}
var reg=/[a-zA-Z0-9]{1,10}@[a-zA-Z0-9]{1,5}\.[a-zA-Z0-9]{1,5}/;
var value=reg.exec(item)完整代码如下
var http = require('http')
var cheerio=require('cheerio')
var url='http://blog.csdn.net/ltg01'
http.get(url,function(res){
var html=''
res.on('data',function(data){
html+=data
})
res.on('end',function(){
var courseData=filterChaper(html)
printCourseData(courseData)
//console.log(html)
})
}).on('error',function(){
console.log('获取失败!')
})
function filterChaper(html){
var $=cheerio.load(html)
var chapters=$('#newcomments')
var courseData=[]
chapters.each(function(item){
var chapter =$(this)
var videos=chapter.find('.panel_body').children('li')
videos.each(function(){
var video=$(this).find('p')
var videoTitle=video.text()
courseData.push(videoTitle)
})
})
return courseData
}
function printCourseData(courseData){
courseData.forEach(function(item){
console.log(item)
/*var reg=/[a-zA-Z0-9]{1,10}@[a-zA-Z0-9]{1,5}\.[a-zA-Z0-9]{1,5}/;
var value=reg.exec(item)
if(value!=null)
{console.log(value[0])}
else
{console.log('无')}
*/
})
}















 873
873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









