






ios内联函数 inline
缘由
由于在学习使用UIScrollVew开发的过程中,碰到下面这个属性(设置内边距):
@property(nonatomic) UIEdgeInsets scrollIndicatorInsets; // default is UIEdgeInsetsZero. adjust indicators inside - 1
光看UIEdgeInsets这个类型,一时还不知道它的具体内部结构是怎么样的,于是继续点进去发现它的定义如下:
typedef struct UIEdgeInsets {
CGFloat top, left, bottom, right; // specify amount to inset (positive) for each of the edges. values can be negative to 'outset' } UIEdgeInsets;- 1
- 2
- 3
原来是这样一个结构体!~ 随之,看到和UIEdgeInsets相关的使用方法,列举部分:
UIKIT_STATIC_INLINE UIEdgeInsets UIEdgeInsetsMake(CGFloat top, CGFloat left, CGFloat bottom, CGFloat right) {
UIEdgeInsets insets = {top, left, bottom, right};
return insets;
}
UIKIT_STATIC_INLINE UIOffset UIOffsetMake(CGFloat horizontal, CGFloat vertical) {
UIOffset offset = {horizontal, vertical};
return offset;
}
...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
看着上面的代码,又出现了一个我不认识的东西UIKIT_STATIC_INLINE,继续点进去查看发现这是这么一个宏:
#define UIKIT_STATIC_INLINE static inline- 1
哦,原来它的意思是告诉编译器这个函数是一个静态的内联函数!内联函数?好耳熟啊,但是想不起来具体有什么作用了,于是百度百度!!得出的能令我印象深刻的结论是:
-
引入内联函数是为了解决函数调用效率的问题
-
由于函数之间的调用,会从一个内存地址调到另外一个内存地址,当函数调用完毕之后还会返回原来函数执行的地址。函数调用会有一定的时间开销,引入内联函数就是为了解决这一问题。
实践
那么引用内联函数到底有什么区别呢?万一面试问到了,那只能回答”为了解决函数调用效率的问题”?如果面试官再问“如何解决呢?”,那岂不是歇菜了!!不如自己写代码测试看看?!!打开xcode..
代码一
说明:定义一个add(int,int)函数并声明为static inline,并调用。
头文件:inline.h
// inline.h
// inline
// Created by fenglh on 15/8/24.
// Copyright (c) 2015年 fenglh. All rights reserved.
#ifndef inline_inline_h #define inline_inline_h static inline int add(int a, int b){ return a+b; } #endif- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
.m文件:main.m
// main.m
// inline
// Created by fenglj on 15/8/24.
// Copyright (c) 2015年 fenglh. All rights reserved.
#import <Foundation/Foundation.h> #import "inline.h" int main(int argc, const char * argv[]) { int c = add(1, 2); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
查看main.m的汇编文件,如下:
.section __TEXT,__text,regular,pure_instructions
.globl _main
.align 4, 0x90 _main: ## @main Lfunc_begin0: .loc 2 14 0 ## /Users/fenglihai/Desktop/inline/inline/main.m:14:0 .cfi_startproc ## BB#0: pushq %rbp Ltmp0: .cfi_def_cfa_offset 16 Ltmp1: .cfi_offset %rbp, -16 movq %rsp, %rbp Ltmp2: .cfi_def_cfa_register %rbp ##DEBUG_VALUE: main:argc <- EDI ##DEBUG_VALUE: main:argv <- RSI Ltmp3: ##DEBUG_VALUE: main:c <- 3 xorl %eax, %eax .loc 2 17 5 prologue_end ## /Users/fenglihai/Desktop/inline/inline/main.m:17:5 Ltmp4: popq %rbp retq- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
代码二
说明:定义一个add(int,int)函数并调用。
头文件:Header.h
// Header.h
// notInline
// Created by fenglh on 15/8/25.
// Copyright (c) 2015年 fenglh. All rights reserved.
#ifndef notInline_Header_h #define notInline_Header_h int add(int a, int b){ return a+b; } #endif- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
.m文件:main.m
// main.m
// notInline
// Created by fenglh on 15/8/25.
// Copyright (c) 2015年 fenglh. All rights reserved.
// #import <Foundation/Foundation.h> #import "Header.h" int main(int argc, const char * argv[]) { int c = add(1,2); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
查看main.m的汇编文件,如下:
.section __TEXT,__text,regular,pure_instructions
.globl _add
.align 4, 0x90
_add: ## @add
Lfunc_begin0:
.file 3 "/Users/fenglihai/Desktop/notInline/notInline" "Header.h" .loc 3 12 0 ## /Users/fenglihai/Desktop/notInline/notInline/Header.h:12:0 .cfi_startproc ## BB#0: pushq %rbp Ltmp0: .cfi_def_cfa_offset 16 Ltmp1: .cfi_offset %rbp, -16 movq %rsp, %rbp Ltmp2: .cfi_def_cfa_register %rbp movl %edi, -4(%rbp) movl %esi, -8(%rbp) .loc 3 13 5 prologue_end ## /Users/fenglihai/Desktop/notInline/notInline/Header.h:13:5 Ltmp3: movl -4(%rbp), %esi addl -8(%rbp), %esi movl %esi, %eax popq %rbp retq Ltmp4: Lfunc_end0: .cfi_endproc .globl _main .align 4, 0x90 _main: ## @main Lfunc_begin1: .loc 2 12 0 ## /Users/fenglihai/Desktop/notInline/notInline/main.m:12:0 .cfi_startproc ## BB#0: pushq %rbp Ltmp5: .cfi_def_cfa_offset 16 Ltmp6: .cfi_offset %rbp, -16 movq %rsp, %rbp Ltmp7: .cfi_def_cfa_register %rbp subq $32, %rsp movl $1, %eax movl $2, %ecx movl $0, -4(%rbp) movl %edi, -8(%rbp) movq %rsi, -16(%rbp) .loc 2 13 13 prologue_end ## /Users/fenglihai/Desktop/notInline/notInline/main.m:13:13 Ltmp8: movl %eax, %edi movl %ecx, %esi callq _add xorl %ecx, %ecx movl %eax, -20(%rbp) .loc 2 14 5 ## /Users/fenglihai/Desktop/notInline/notInline/main.m:14:5 movl %ecx, %eax addq $32, %rsp popq %rbp retq- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
上面2段代码可以看出,只有add函数的定义不一样,一个是加了static inline修饰,而另外一个没有。再对比一下汇编代码,发现的确有很大的不一样呀!!!给人第一感觉,有用static inline修饰的汇编之后的代码比没有static inline修饰的的汇编之后的代码简洁的多了!!
其次,在没有调用static inline修饰add函数的main.m汇编代码中,add函数是有单独的汇编代码的!
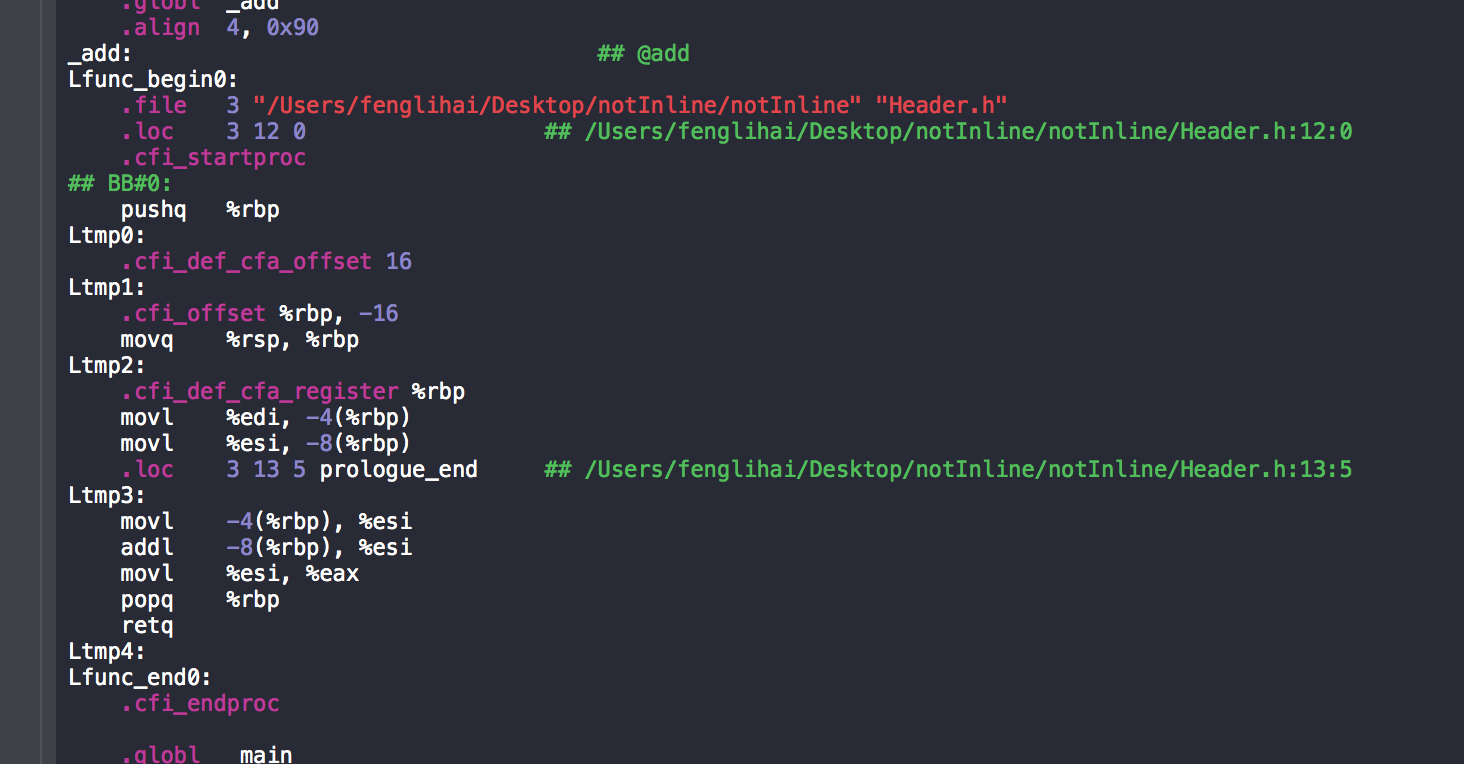
而没有使用内联函数的main.m汇编代码中,仅仅只有main函数的汇编代码!
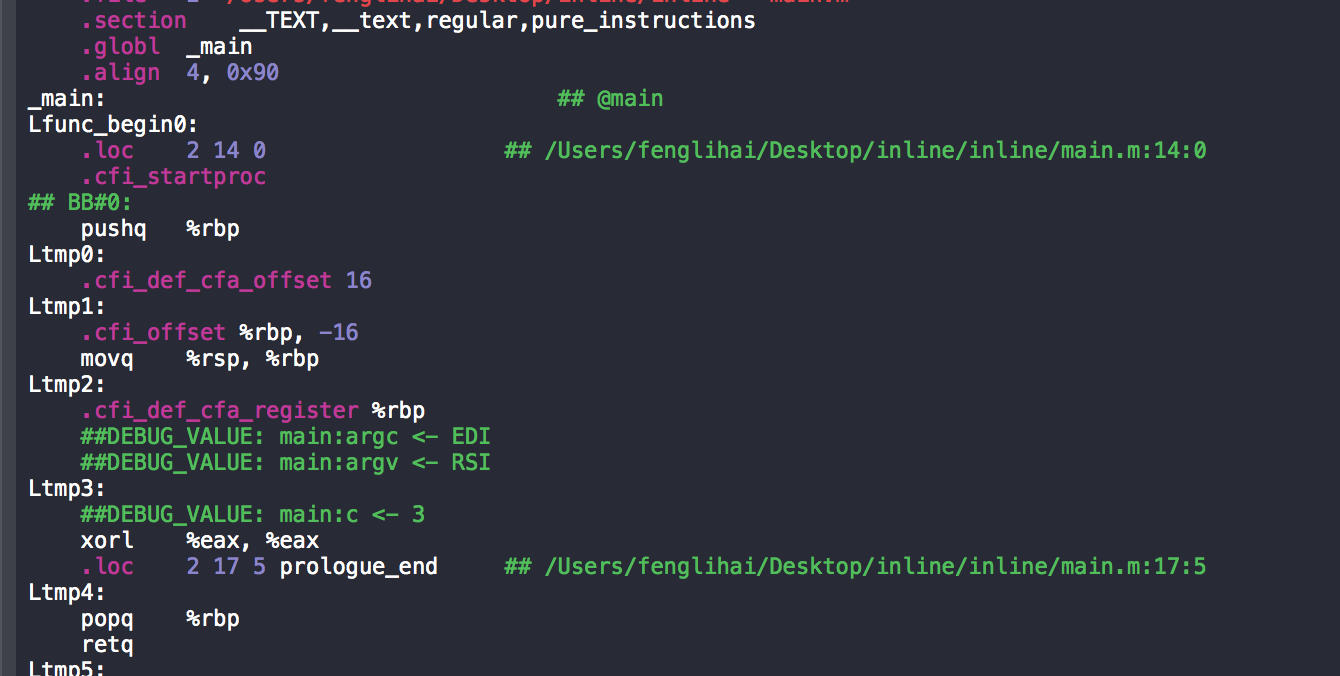
再看看使用了内联函数的main.m汇编代码:
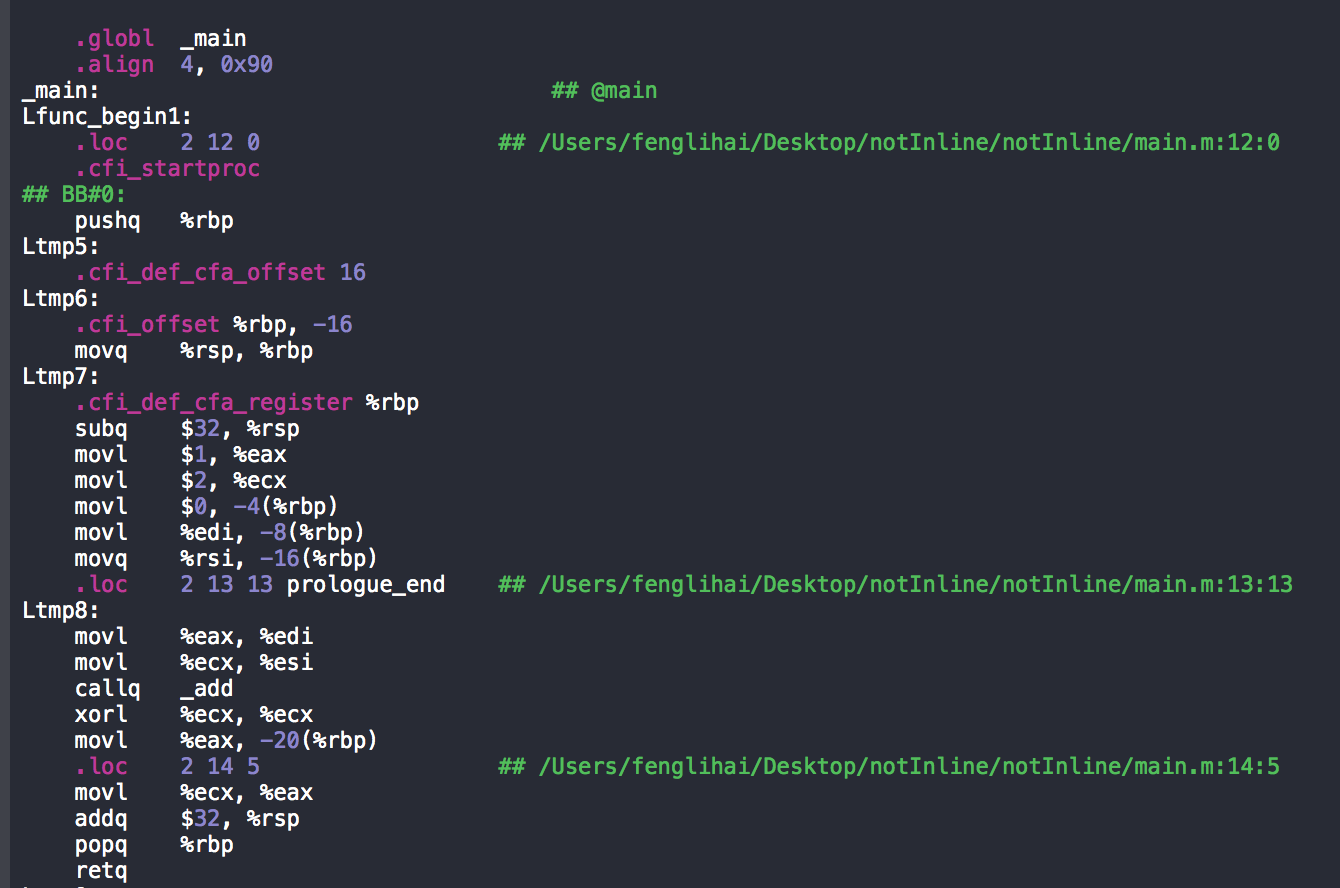
对比两者的mian.m的汇编代码,可以发现,没有使用`static inline修饰的内联函数的mian函数汇编代码中,会出现 call 指令!这就是区别!调用call指令就是就需要:
- (1)将下一条指令的所在地址(即当时程序计数器PC的内容)入栈
- (2)并将子程序的起始地址送入PC(于是CPU的下一条指令就会转去执行子程序)。
恩恩,对于汇编就不扯淡了,凭借着上学时候学过点汇编只能深入到这里了!唉!那么得知,影响效率的原因就是在解决在call调用这里了!!
结论
1.使用inline修饰的函数,在编译的时候,会把代码直接嵌入调用代码中。就相当于用#define 宏定义来定义一个add 函数那样!与#define的区别是:
1)#define定义的格式要有要求,而使用inline则就行平常写函数那样,只要加上`inline即可!
2)使用#define宏定义的代码,编译器不会对其进行参数有效性检查,仅仅只是对符号表进行替换。
3)#define宏定义的代码,其返回值不能被强制转换成可转换的适合的转换类型。可参考百度文科 关于inline
2.在inline加上`static修饰符,只是为了表明该函数只在该文件中可见!也就是说,在同一个工程中,就算在其他文件中也出现同名、同参数的函数也不会引起函数重复定义的错误!**
实践到这里,对于内联函数终的理解,终于加深理解和记忆了!!















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









