






[CSP-S2020] 动物园
题目描述
动物园里饲养了很多动物,饲养员小 A 会根据饲养动物的情况,按照《饲养指南》购买不同种类的饲料,并将购买清单发给采购员小 B。
具体而言,动物世界里存在 2 k 2^k 2k 种不同的动物,它们被编号为 0 ∼ 2 k − 1 0 \sim 2^k - 1 0∼2k−1。动物园里饲养了其中的 n n n 种,其中第 i i i 种动物的编号为 a i a_i ai。
《饲养指南》中共有 m m m 条要求,第 j j j 条要求形如“如果动物园中饲养着某种动物,满足其编号的二进制表示的第 p j p_j pj 位为 1 1 1,则必须购买第 q j q_j qj 种饲料”。其中饲料共有 c c c 种,它们从 1 ∼ c 1 \sim c 1∼c 编号。本题中我们将动物编号的二进制表示视为一个 k k k 位 01 串,第 0 0 0 位是最低位,第 k − 1 k - 1 k−1 位是最高位。
根据《饲养指南》,小 A 将会制定饲料清单交给小 B,由小 B 购买饲料。清单形如一个 c c c 位 01 01 01 串,第 i i i 位为 1 1 1 时,表示需要购买第 i i i 种饲料;第 i i i 位为 0 0 0 时,表示不需要购买第 i i i 种饲料。 实际上根据购买到的饲料,动物园可能可以饲养更多的动物。更具体地,如果将当前未被饲养的编号为 x x x 的动物加入动物园饲养后,饲料清单没有变化,那么我们认为动物园当前还能饲养编号为 x x x 的动物。
现在小 B 想请你帮忙算算,动物园目前还能饲养多少种动物。
输入格式
第一行包含四个以空格分隔的整数
n
,
m
,
c
,
k
n, m, c, k
n,m,c,k。
分别表示动物园中动物数量、《饲养指南》要求数、饲料种数与动物编号的二进制表示位数。
第二行
n
n
n 个以空格分隔的整数,其中第
i
i
i 个整数表示
a
i
a_i
ai。
接下来
m
m
m 行,每行两个整数
p
i
,
q
i
p_i, q_i
pi,qi 表示一条要求。
数据保证所有
a
i
a_i
ai 互不相同,所有的
q
i
q_i
qi 互不相同。
输出格式
仅一行一个整数表示答案。
样例 #1
样例输入 #1
3 3 5 4
1 4 6
0 3
2 4
2 5
样例输出 #1
13
样例 #2
样例输入 #2
2 2 4 3
1 2
1 3
2 4
样例输出 #2
2
提示
【样例 #1 解释】
动物园里饲养了编号为 1 , 4 , 6 1, 4, 6 1,4,6 的三种动物,《饲养指南》上的三条要求为:
- 若饲养的某种动物的编号的第 0 0 0 个二进制位为 1 1 1,则需购买第 3 3 3 种饲料。
- 若饲养的某种动物的编号的第 2 2 2 个二进制位为 1 1 1,则需购买第 4 4 4 种饲料。
- 若饲养的某种动物的编号的第 2 2 2 个二进制位为 1 1 1,则需购买第 5 5 5 种饲料。
饲料购买情况为:
- 编号为 1 1 1 的动物的第 0 0 0 个二进制位为 1 1 1,因此需要购买第 3 3 3 种饲料;
- 编号为 4 , 6 4, 6 4,6 的动物的第 2 2 2 个二进制位为 1 1 1,因此需要购买第 4 , 5 4, 5 4,5 种饲料。
由于在当前动物园中加入一种编号为 0 , 2 , 3 , 5 , 7 , 8 , … , 15 0, 2, 3, 5, 7, 8, \ldots , 15 0,2,3,5,7,8,…,15 之一的动物,购物清单都不会改变,因此答案为 13 13 13。
【数据范围】
对于
20
%
20 \%
20% 的数据,
k
≤
n
≤
5
k \le n \le 5
k≤n≤5,
m
≤
10
m \le 10
m≤10,
c
≤
10
c \le 10
c≤10,所有的
p
i
p_i
pi 互不相同。
对于
40
%
40 \%
40% 的数据,
n
≤
15
n \le 15
n≤15,
k
≤
20
k \le 20
k≤20,
m
≤
20
m \le 20
m≤20,
c
≤
20
c \le 20
c≤20。
对于
60
%
60 \%
60% 的数据,
n
≤
30
n \le 30
n≤30,
k
≤
30
k \le 30
k≤30,
m
≤
1000
m \le 1000
m≤1000。
对于
100
%
100 \%
100% 的数据,
0
≤
n
,
m
≤
1
0
6
0 \le n, m \le 10^6
0≤n,m≤106,
0
≤
k
≤
64
0 \le k \le 64
0≤k≤64,
1
≤
c
≤
1
0
8
1 \le c \le 10^8
1≤c≤108。
题解
本题的入手点在输入格式中提到:数据保证所有
a
i
a_i
ai 互不相同,所有的
q
i
q_i
qi 互不相同。
这是重点啊,重点啊!!!苯人已疯
我第一眼看到这题时,快傻掉了,压根想不出什么好方法。当我再读一遍题目的时候,我注意到很不起眼的输入样例解释,我整个人都亮了。
既然每个位置对应的饲料不同,那我们就不管饲料了,只管位置(反正又不会问你买了哪些)。
这个问题就转化为,共有k个位置的而二进制数,其中,不需要买饲料的位置上可以放
0
0
0或
1
1
1两种数字,需要买饲料但是没买的位置上只能放
0
0
0,需要买饲料而且买了的可以放
0
0
0或
1
1
1。
所以,我们只用找出有
x
x
x个位置需要买但是没有买,除去这些位置还剩
k
−
x
k-x
k−x个,则一共有2k-x种动物,再减去动物园原来就有的
n
n
n种动物,就可以得到了。
注意:
- 开 u n s i g n e d unsigned unsigned l o n g long long l o n g long long 防止溢出
- 有一种情况会溢出(x=0, k=64),直接特判带走
代码
#include <bits/stdc++.h>
using namespace std;
unsigned long long n, m, c, k, cnt, a, st;
bool flag[1000];
int main()
{
scanf("%lld%lld%lld%lld", &n, &m, &c, &k);
cnt = k;
for(int i=0 ; i<n ; i++){
scanf("%llu", &a);
st |= a;
}
for(int i=0 ; i<m ; i++)
{
int p, q;
scanf("%d%d", &p, &q);
if((st>>p)&1);
else{
if(!flag[p])
flag[p] = true, cnt--;
}
}
if(cnt==64 && n==0){
puts("18446744073709551616");
return 0;
}
printf("%llu", (1ULL<<cnt)-n);
return 0;
}
[CSP-S2020] 贪吃蛇
题目描述
草原上有 n n n 条蛇,编号分别为 1 , 2 , … , n 1, 2, \ldots , n 1,2,…,n。初始时每条蛇有一个体力值 a i a_i ai,我们称编号为 x x x 的蛇实力比编号为 y y y 的蛇强当且仅当它们当前的体力值满足 a x > a y a_x > a_y ax>ay,或者 a x = a y a_x = a_y ax=ay 且 x > y x > y x>y。
接下来这些蛇将进行决斗,决斗将持续若干轮,每一轮实力最强的蛇拥有选择权,可以选择吃或者不吃掉实力最弱的蛇:
- 如果选择吃,那么实力最强的蛇的体力值将减去实力最弱的蛇的体力值,实力最弱的蛇被吃掉,退出接下来的决斗。之后开始下一轮决斗。
- 如果选择不吃,决斗立刻结束。
每条蛇希望在自己不被吃的前提下在决斗中尽可能多吃别的蛇(显然,蛇不会选择吃自己)。
现在假设每条蛇都足够聪明,请你求出决斗结束后会剩几条蛇。
本题有多组数据,对于第一组数据,每条蛇体力会全部由输入给出,之后的每一组数据,会相对于上一组的数据,修改一部分蛇的体力作为新的输入。
输入格式
第一行一个正整数
T
T
T,表示数据组数。
接下来有
T
T
T 组数据,对于第一组数据,第一行一个正整数
n
n
n,第二行
n
n
n 个非负整数表示
a
i
a_i
ai。
对于第二组到第
T
T
T 组数据,每组数据:
第一行第一个非负整数
k
k
k 表示体力修改的蛇的个数。
第二行
2
k
2k
2k 个整数,每两个整数组成一个二元组
(
x
,
y
)
(x,y)
(x,y),表示依次将
a
x
a_x
ax 的值改为
y
y
y。一个位置可能被修改多次,以最后一次修改为准。
输出格式
输出 T T T 行,每行一个整数表示最终存活的蛇的条数。
样例 #1
样例输入 #1
2
3
11 14 14
3
1 5 2 6 3 25
样例输出 #1
3
1
样例 #2
样例输入 #2
2
5
13 31 33 39 42
5
1 7 2 10 3 24 4 48 5 50
样例输出 #2
5
3
提示
【样例 #1 解释】
第一组数据,第一轮中 3 3 3 号蛇最强, 1 1 1 号蛇最弱。若 3 3 3 号蛇选择吃,那么它将在第二轮被 2 2 2 号蛇吃掉。因此 3 3 3 号蛇第一轮选择不吃, 3 3 3 条蛇都将存活。
对于第二组数据, 3 3 3 条蛇体力变为 5 , 6 , 25 5, 6, 25 5,6,25。第一轮中 3 3 3 号蛇最强, 1 1 1 号蛇最弱,若它选择吃,那么 3 3 3 号蛇体力值变为 20 20 20,在第二轮中依然是最强蛇并能吃掉 2 2 2 号蛇,因此 3 3 3 号蛇会选择两轮都吃,最终只有 1 1 1 条蛇存活。
【数据范围】
对于
20
%
20 \%
20% 的数据,
n
=
3
n = 3
n=3。
对于
40
%
40 \%
40% 的数据,
n
≤
10
n \le 10
n≤10。
对于
55
%
55 \%
55% 的数据,
n
≤
2000
n \le 2000
n≤2000。
对于
70
%
70\%
70% 的数据,
n
≤
5
×
10
4
n \le 5 \times {10}^4
n≤5×104。
对于
100
%
100\%
100% 的数据:
3
≤
n
≤
10
6
3 \le n \le {10}^6
3≤n≤106,
1
≤
T
≤
10
1 \le T \le 10
1≤T≤10,
0
≤
k
≤
10
5
0 \le k \le {10}^5
0≤k≤105,
0
≤
a
i
,
y
≤
1
0
9
0 \le a_i, y \le 10^9
0≤ai,y≤109。保证每组数据(包括所有修改完成后的)的
a
i
a_i
ai 以不降顺序排列。
题解
发现一篇好题解,再加上这道题解释起来比较复杂,所以直接转载了。
来源:洛谷
作者: OMG_wc


int a[N];
int main() {
int _;
scanf("%d", &_);
int n;
for (int cas = 1; cas <= _; cas++) {
if (cas == 1) {
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
scanf("%d", &a[i]);
}
} else {
int k;
scanf("%d", &k);
while (k--) {
int x, y;
scanf("%d%d", &x, &y);
a[x] = y;
}
}
set<pair<int, int> > se;
for (int i = 1; i <= n; i++) {
se.insert({a[i], i});
}
int flag = 0, ans;
while (1) {
if (se.size() == 2) {
se.erase(se.begin());
if (flag) {
if ((flag - se.size()) % 2) {
ans = flag + 1;
} else {
ans = flag;
}
} else
ans = 1;
break;
}
set<pair<int, int> >::iterator it = se.end();
it--;
int x = it->first, id = it->second;
int y = se.begin()->first;
se.erase(it);
se.erase(se.begin());
se.insert({x - y, id});
if (se.begin()->second != id) {
if (flag) {
if ((flag - se.size()) % 2) {
ans = flag + 1;
} else {
ans = flag;
}
break;
}
} else {
if (flag == 0) flag = se.size();
}
}
printf("%d\n", ans);
}
return 0;
}

int a[N];
int main() {
int _;
scanf("%d", &_);
int n;
for (int cas = 1; cas <= _; cas++) {
if (cas == 1) {
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
scanf("%d", &a[i]);
}
} else {
int k;
scanf("%d", &k);
while (k--) {
int x, y;
scanf("%d%d", &x, &y);
a[x] = y;
}
}
deque<pair<int, int> > q1, q2;
for (int i = 1; i <= n; i++) {
q1.push_back({a[i], i});
}
int ans;
while (1) {
if (q1.size() + q2.size() == 2) {
ans = 1;
break;
}
int x, id, y;
y = q1.front().first, q1.pop_front();
if (q2.empty() || !q1.empty() && q1.back() > q2.back()) {
x = q1.back().first, id = q1.back().second, q1.pop_back();
} else {
x = q2.back().first, id = q2.back().second, q2.pop_back();
}
pair<int, int> now = make_pair(x - y, id);
if (q1.empty() || q1.front() > now) {
ans = q1.size() + q2.size() + 2; // 不吃
int cnt = 0;
while (1) {
cnt++;
if (q1.size() + q2.size() + 1 == 2) {
if (cnt % 2 == 0) ans--;
break;
}
int x, id;
if (q2.empty() || !q1.empty() && q1.back() > q2.back()) {
x = q1.back().first, id = q1.back().second, q1.pop_back();
} else {
x = q2.back().first, id = q2.back().second, q2.pop_back();
}
now = {x - now.first, id};
if ((q1.empty() || now < q1.front()) && (q2.empty() || now < q2.front())) {
;
} else {
if (cnt % 2 == 0) ans--;
break;
}
}
break;
} else {
q2.push_front(now);
}
}
printf("%d\n", ans);
}
return 0;
}
再次感谢原作者OMG_wc
[CSP-S2020] 函数调用
题目描述
函数是各种编程语言中一项重要的概念,借助函数,我们总可以将复杂的任务分解成一个个相对简单的子任务,直到细化为十分简单的基础操作,从而使代码的组织更加严密、更加有条理。然而,过多的函数调用也会导致额外的开销,影响程序的运行效率。
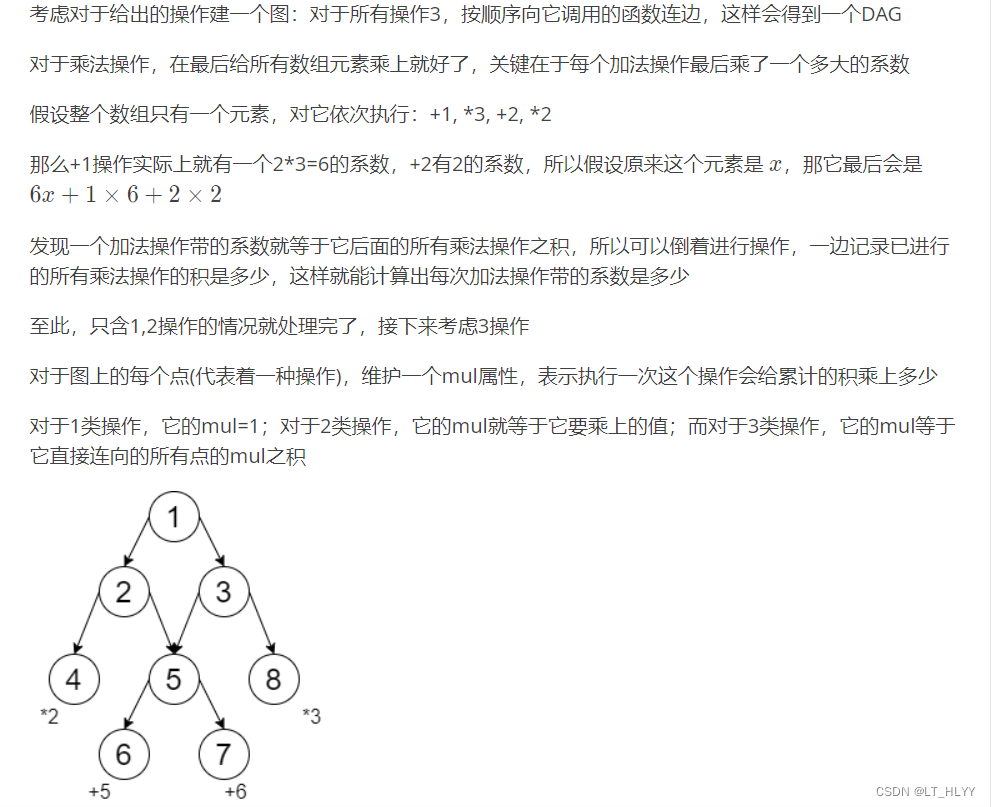
某数据库应用程序提供了若干函数用以维护数据。已知这些函数的功能可分为三类:
- 将数据中的指定元素加上一个值;
- 将数据中的每一个元素乘以一个相同值;
- 依次执行若干次函数调用,保证不会出现递归(即不会直接或间接地调用本身)。
在使用该数据库应用时,用户可一次性输入要调用的函数序列(一个函数可能被调用多次),在依次执行完序列中的函数后,系统中的数据被加以更新。某一天,小 A 在应用该数据库程序处理数据时遇到了困难:由于频繁而低效的函数调用,系统在执行操作时进入了无响应的状态,他只好强制结束了数据库程序。为了计算出正确数据,小 A 查阅了软件的文档,了解到每个函数的具体功能信息,现在他想请你根据这些信息帮他计算出更新后的数据应该是多少。
输入格式
第一行一个正整数
n
n
n,表示数据的个数。
第二行
n
n
n 个整数,第
i
i
i 个整数表示下标为
i
i
i 的数据的初始值为
a
i
a_i
ai。
第三行一个正整数
m
m
m,表示数据库应用程序提供的函数个数。函数从
1
∼
m
1 \sim m
1∼m 编号。
接下来
m
m
m 行中,第
j
j
j(
1
≤
j
≤
m
1 \le j \le m
1≤j≤m)行的第一个整数为
T
j
T_j
Tj,表示
j
j
j 号函数的类型:
- 若 T j = 1 T_j = 1 Tj=1,接下来两个整数 P j , V j P_j, V_j Pj,Vj 分别表示要执行加法的元素的下标及其增加的值;
- 若 T j = 2 T_j = 2 Tj=2,接下来一个整数 V j V_j Vj 表示所有元素所乘的值;
- 若
T
j
=
3
T_j = 3
Tj=3,接下来一个正整数
C
j
C_j
Cj 表示
j
j
j 号函数要调用的函数个数,
随后 C j C_j Cj 个整数 g 1 ( j ) , g 2 ( j ) , … , g C j ( j ) g^{(j)}_1, g^{(j)}_2, \ldots , g^{(j)}_{C_j} g1(j),g2(j),…,gCj(j) 依次表示其所调用的函数的编号。
第
m
+
4
m + 4
m+4 行一个正整数
Q
Q
Q,表示输入的函数操作序列长度。
第
m
+
5
m + 5
m+5 行
Q
Q
Q 个整数
f
i
f_i
fi,第
i
i
i 个整数表示第
i
i
i 个执行的函数的编号。
输出格式
一行 n n n 个用空格隔开的整数,按照下标 1 ∼ n 1 \sim n 1∼n 的顺序,分别输出在执行完输入的函数序列后,数据库中每一个元素的值。答案对 998244353 \boldsymbol{998244353} 998244353 取模。
样例 #1
样例输入 #1
3
1 2 3
3
1 1 1
2 2
3 2 1 2
2
2 3
样例输出 #1
6 8 12
样例 #2
样例输入 #2
10
1 2 3 4 5 6 7 8 9 10
8
3 2 2 3
3 2 4 5
3 2 5 8
2 2
3 2 6 7
1 2 5
1 7 6
2 3
3
1 2 3
样例输出 #2
36 282 108 144 180 216 504 288 324 360
样例 #3
样例输入 #3
见附件中的 call/call3.in
样例输出 #3
见附件中的 call/call3.ans
提示
【样例 #1 解释】
1 1 1 号函数功能为将 a 1 a_1 a1 的值加一。 2 2 2 号函数功能为所有元素乘 2 2 2。 3 3 3 号函数将先调用 1 1 1 号函数,再调用 2 2 2 号函数。
最终的函数序列先执行 2 2 2 号函数,所有元素的值变为 2 , 4 , 6 2, 4, 6 2,4,6。
再执行 3 3 3 号函数时,先调用 1 1 1 号函数,所有元素的值变为 3 , 4 , 6 3, 4, 6 3,4,6。再调用 2 2 2 号函数,所有元素的值变为 6 , 8 , 12 6, 8, 12 6,8,12。
【数据范围】
| 测试点编号 | n , m , Q ≤ n, m, Q \le n,m,Q≤ | ∑ C j \sum C_j ∑Cj | 其他特殊限制 |
|---|---|---|---|
| 1 ∼ 2 1 \sim 2 1∼2 | 1000 1000 1000 | = m − 1 = m - 1 =m−1 | 函数调用关系构成一棵树 |
| 3 ∼ 4 3 \sim 4 3∼4 | 1000 1000 1000 | ≤ 100 \le 100 ≤100 | 无 |
| 5 ∼ 6 5 \sim 6 5∼6 | 20000 20000 20000 | ≤ 40000 \le 40000 ≤40000 | 不含第 2 2 2 类函数或不含第 1 1 1 类函数 |
| 7 7 7 | 20000 20000 20000 | = 0 = 0 =0 | 无 |
| 8 ∼ 9 8 \sim 9 8∼9 | 20000 20000 20000 | = m − 1 = m - 1 =m−1 | 函数调用关系构成一棵树 |
| 10 ∼ 11 10 \sim 11 10∼11 | 20000 20000 20000 | ≤ 2 × 1 0 5 \le 2 \times 10^5 ≤2×105 | 无 |
| 12 ∼ 13 12 \sim 13 12∼13 | 1 0 5 10^5 105 | ≤ 2 × 1 0 5 \le 2 \times 10^5 ≤2×105 | 不含第 2 2 2 类函数或不含第 1 1 1 类函数 |
| 14 14 14 | 1 0 5 10^5 105 | = 0 = 0 =0 | 无 |
| 15 ∼ 16 15 \sim 16 15∼16 | 1 0 5 10^5 105 | = m − 1 = m - 1 =m−1 | 函数调用关系构成一棵树 |
| 17 ∼ 18 17 \sim 18 17∼18 | 1 0 5 10^5 105 | ≤ 5 × 1 0 5 \le 5 \times 10^5 ≤5×105 | 无 |
| 19 ∼ 20 19 \sim 20 19∼20 | 1 0 5 10^5 105 | ≤ 1 0 6 \le 10^6 ≤106 | 无 |
对于所有数据: 0 ≤ a i ≤ 1 0 4 0 \le a_i \le 10^4 0≤ai≤104, T j ∈ { 1 , 2 , 3 } T_j \in \{1,2,3\} Tj∈{1,2,3}, 1 ≤ P j ≤ n 1 \le P_j \le n 1≤Pj≤n, 0 ≤ V j ≤ 1 0 4 0 \le V_j \le 10^4 0≤Vj≤104, 1 ≤ g k ( j ) ≤ m 1 \le g^{(j)}_k \le m 1≤gk(j)≤m, 1 ≤ f i ≤ m 1 \le f_i \le m 1≤fi≤m。
题解
把每个函数的关系抽象成为一张图,每个函数对应的操作抽象成一条边,然后用拓扑排序。
由于还没有
A
C
AC
AC,再加上没有详细的证明,所以我就做一个搬运工,这里转载AK_Dream的题解。

#include <bits/stdc++.h>
#define N 1000005
using namespace std;
typedef long long ll;
template <typename T>
inline void read(T &num) {
T x = 0; char ch = getchar();
for (; ch > '9' || ch < '0'; ch = getchar());
for (; ch <= '9' && ch >= '0'; ch = getchar()) x = (x << 3) + (x << 1) + (ch ^ '0');
num = x;
}
const ll mod = 998244353;
int n, m, Q, F[N];
int head[N], pre[N<<1], to[N<<1], sz, inde[N];
ll a[N];
inline void addedge(int u, int v) {
pre[++sz] = head[u]; head[u] = sz; to[sz] = v; inde[v]++;
}
struct oper {
int tp, p;
ll v, mul, sum;
} b[N];
queue<int> q;
int ord[N], bnbn;
void toposort() { //拓扑排序
for (int i = 1; i <= m; i++) if (!inde[i]) q.push(i);
while (!q.empty()) {
int x = q.front(); q.pop();
ord[++bnbn] = x;
for (int i = head[x]; i; i = pre[i]) {
int y = to[i];
inde[y]--;
if (!inde[y]) q.push(y);
}
}
}
void getmul() { //计算节点的mul
for (int i = m; i; i--) {
int x = ord[i];
for (int j = head[x]; j; j = pre[j]) {
int y = to[j];
b[x].mul = b[x].mul * b[y].mul % mod;
}
}
}
void getsum() { //下传节点的sum
for (int i = 1; i <= m; i++) {
int x = ord[i]; ll now = 1;
for (int j = head[x]; j; j = pre[j]) {
int y = to[j];
b[y].sum = (b[y].sum + b[x].sum * now % mod) % mod;
now = now * b[y].mul % mod;
}
}
}
int main() {
read(n);
for (int i = 1; i <= n; i++) read(a[i]);
read(m);
for (int i = 1; i <= m; i++) {
read(b[i].tp);
if (b[i].tp == 1) {
read(b[i].p); read(b[i].v);
b[i].mul = 1;
} else if (b[i].tp == 2) {
read(b[i].v); b[i].mul = b[i].v;
} else {
read(b[i].p); b[i].mul = 1;
for (int j = 1, x; j <= b[i].p; j++) {
read(x);
addedge(i, x);
}
}
}
toposort();
getmul();
read(Q); ll now = 1;
for (int i = 1; i <= Q; i++) read(F[i]);
for (int i = Q; i; i--) {
int x = F[i]; b[x].sum = (b[x].sum + now) % mod;
now = now * b[x].mul % mod;
}
getsum();
for (int i = 1; i <= n; i++) a[i] = a[i] * now % mod;
for (int i = 1; i <= m; i++) {
if (b[i].tp == 1) {
a[b[i].p] = (a[b[i].p] + b[i].v * b[i].sum % mod) % mod;
}
}
for (int i = 1; i <= n; i++) printf("%lld ", a[i]);
return 0;
}
再次感谢AK_Dream!















 2415
2415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









