






初入Python数据分析库——Numpy(一)
文章所用到的代码都是在 Jupyter notebook 里写的,不是传统的 Pycharm ,复制的时候注意语法问题!!!
一、Numpy是什么
Numpy 的英文全称是:Numerical Python。
我们可以从下面三个角度去理解Numpy:
1.一个开源的Python科学计算库
2.使用Numpy可以方便地对数组、矩阵进行计算
3.包含线性代数、傅里叶变换、统计运算、随机模拟等等大量函数
二、为什么用Numpy
在介绍之前,我们先要书写下面这段代码,表示我们引用了numpy 这个库函数,并将函数重命名为:np
import numpy as np
下面我们从两个方面来对比 Numpy 与 原生Python ,以说明我们为什么使用 Numpy 这个库函数。
(一)代码更简洁
1.原生Python
def python_sum(n):
# 使用列表生成式创建1-N的平方
a = [i**2 for i in range(n)]
# 使用表生成式创建1-N的平方
b = [i**3 for i in range(n)]
# 创建新列表
ab_sum = []
for i in range(n):
# 将a中的对应元素与b中对应的元素相加
ab_sum.append(a[i]+b[i])
return ab_sum
python_sum(10)
2.Numpy实现代码
def numpy_sum(n):
a = np.arange(n)**2
b = np.arange(n)**3
return a+b
numpy_sum(10)
上面两段代码的行数对比起来已经很明显了,这里就简单解释一下。
大家可以看到,我只是想实现一个数组倍乘相加的功能,Python就需要用到循环,而Numpy则可以直接乘。两者从复杂度来判断,根本不是一个量级的。
(二)性能更高效
1.运行时长对比
下面用到的 %timeit 是Python一个用于计运行耗时的工具。
# 对比运行1000次
%timeit python_sum(1000)
%timeit numpy_sum(1000)
# 对比运行100000次
%timeit python_sum(100000)
%timeit numpy_sum(100000)
2.画图比较
我们直接将刚刚得到的数据,画成图进行比较。
import pandas as pd
# 创建数据
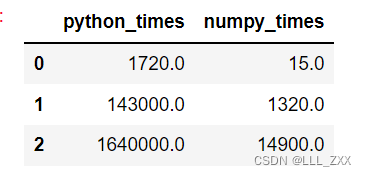
python_times = [1.72*1000,143*1000,1.64*1000*1000]
numpy_times = [15,1.32*1000,14.9*1000]
# 创建pandas的DataFrame类型数据
charts_data = pd.DataFrame({
'python_times':python_times,
'numpy_times':numpy_times,
})
#表格
charts_data
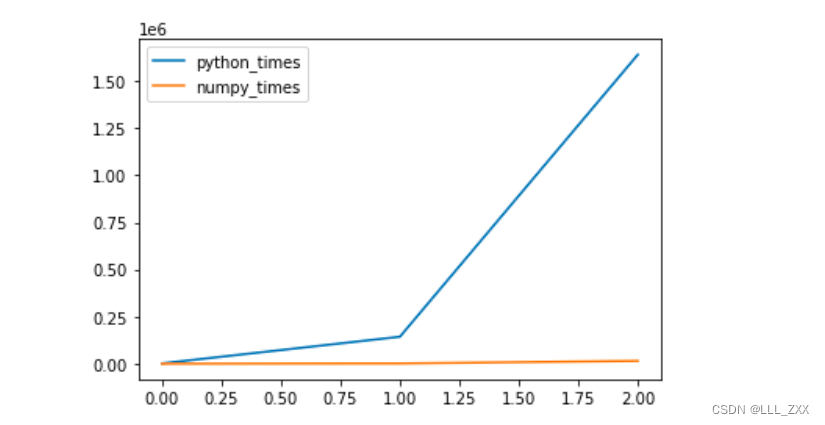
# 线性图
charts_data.plot()
# 柱状图
charts_data.plot.bar()
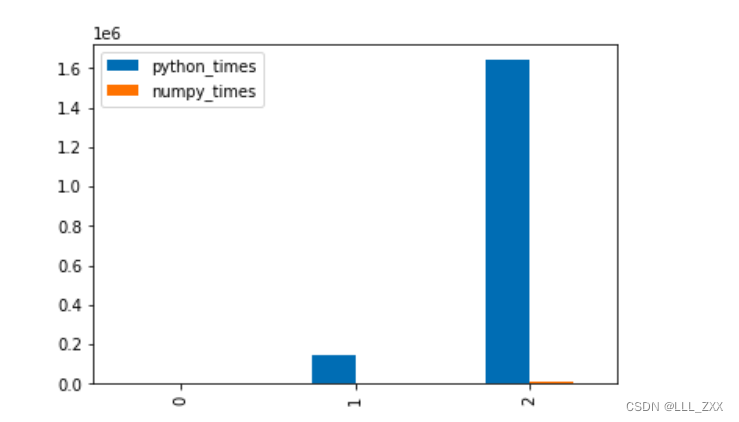
读者可以非常直观的通过这些图来对比两者,很明显,只要数量一上去,Python所需要耗的时间就变得很长,跟Numpy完全没法比。所以说:使用Numpy代码的性能优于Python。
二、Numpy ndarray对象
Ndarray是:NumPy 定义了一个n维数组对象,简称 ndarray 对象。它是一个一系列相同类型元素组成的数组集合。
数组中的每个元素都占有大小相同的内存块。
ndarray 对象采用了数组的索引机制,将数组中的每一个元素映射到内存块上。
读者可以看看下面这段代码,其意义就是看 np.array([1,2,3,4,5])的数据类型
np.array([1,2,3,4,5]) # 先忽略 np.array,下文会介绍
type(np.array([1,2,3,4,5])) # 先忽略 type ,下文会介绍
# 结果是:numpy.ndarray
也就是说,使用 Numpy 之后,我们创建出来的数据结构就是:numpy.ndarray
三、Numpy.array()
(一)函数说明
numpy.array(object,dtype = None ,copy = True , order = None ,subok = False ,nbmin =0)
1.object 表示一个数组序列
2.dtype 可选参数,通过它可以改变数组的数据类型
3.copy 可选参数,表示数组能否被复制,默认是True
4.ndmin 用于指定数组的维度
5.subok 可选参数,类型为bool值,默认为False。为True,使用object的内部数据类型
(二)详细说明
1.object 表示一个数组序列
array()函数,括号内可以是列表、元组、数组、迭代对象、生成器,但最终都会转变为numpy.ndarray的数组结构。
示例(1)
#元组
np.array((1,2,3,4,5))
type(np.array((1,2,3,4,5)))
#迭代对象
np.array(range(10))
#生成器
np.array([i**2 for i in range(10)])
以上三者的结果都是:numpy.ndarray。
示例(2)
练习:创建10以内的偶数的数组
# 方法1:
np.array(range(0,10,2))
# 方法2:
np.array([i for i in range(10) if i%2 ==0])
# 结果是:array([0, 2, 4, 6, 8])
object可以放很多数据结构,最终我们都转换成数组来操作。
2.dtype 可选参数,通过它可以改变数组的数据类型
(1)在不使用 dtype 创建数组时
注意1:当列表中元素类型不同,会统一改成字符最大的数据类型
# 列表中元素类型不同 --> 改成字符最大的数据类型
np.array([1,1.5,3,4,4.5,5,'5'])
# 结果:array(['1', '1.5', '3', '4', '4.5', '5', '5'], dtype='<U32')
# 浮点型
ar2 = np.array([1,2,3.14,4.5])
ar2
# 结果:array([1. , 2. , 3.14, 4.5 ])
# 二维数组:嵌套序列数量不一致时
# ( 嵌套序列(列表,元组均可) )
ar3 = np.array([
[1,2,3],
('a','b','c')
])
ar3
# 结果:array([['1', '2', '3'],
['a', 'b', 'c']], dtype='<U11')
# 二维数组:嵌套序列数量不一致时 --> 不会怎么样,同类的归为一起
ar4 = np.array([[1,2,3],('a','b','c','d')])
print(ar4)
# 结果是:array([list([1, 2, 3]), ('a', 'b', 'c', 'd')], dtype=object)
# 列表 元组
(2)在使用 dtype 改变数组时
a = np.array([1,2,3,4,5])
# 设置数组元素类型 --> 强制转化
has_dtype_a = np.array([1,2,3,4,5],dtype='float')
has_dtype_a
# 结果是:array([1., 2., 3., 4., 5.])
3.copy 可选参数,表示数组能否被复制,默认是True
示例(1)
注意:列表中是引用传值,也就是直接给到被引用者地址
my_list1 = [1,2,3,4] # my_list1 存储的是地址
my_list2 = my_list1 # # 直接等于,是试图操作,相当于把 my_list1 的地址给了 my_list2
my_list2[1] = 10 # 当修改 my_list2 的元素时,my_list1 也会发生变化
my_list1
my_list2
id(my_list1)
id(my_list2)
# 结果是:
[1, 10, 3, 4]
[1, 10, 3, 4]
2166468147336
2166468147336
示例(2)
a = np.array([1,2,3,4,5])
# 定义b ,复制a
b = np.array(a) # 这是真正的复制,不是那种指向同一份空间的引用
print('a:',id(a),'b:',id(b))
print("以上看出a 和 b 的内存地址")
b[0] = 10 # 当修改b的元素是,a不会发生变化
print('a:',a,'b:',b)
# 结果是:
a: 2166468357704 b: 2166468357440
以上看出a 和 b 的内存地址
a: [1 2 3 4 5] b: [10 2 3 4 5]
4.ndmin 用于指定数组的维度
a = np.array([1,2,3])
print(a)
a = np.array([1,2,3],ndmin = 3)
print(a) # 注意看括号的变化
a.ndim
# 结果是:
[1 2 3]
[[[1 2 3]]]
3
5.subok 可选参数,类型为bool值,默认为False。为True,使用object的内部数据类型
示例(1)
# 创建一个矩阵
a = np.mat([1,2,3,4]) #注意:此处是 np.mat --> 数据结构是:numpy.matrix
# 输出为矩阵
print(type(a))
# 结果是:
<class 'numpy.matrix'>
示例(2)
a = np.mat([1,2,3,4])
at = np.array(a,subok = True) #注意:此处是 np.array --> 数据结构是:numpy.ndarray
af = np.array(a) # 不是直接 = 的操作,就相当于给了一份副本,使 at 保持原数据
print('at,subok = True',type(at))
print('af,subok = Flase',type(af))
print(id(at))
print(id(af))
# 结果是:
at,subok = True <class 'numpy.matrix'>
af,subok = Flase <class 'numpy.ndarray'>
2166468336280
2166468449712















 892
892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









