







MySQL初阶【3】 —— 数据库约束及复杂查询SQL
一、数据库的约束
在正式介绍数据库的约束之前,肯定有读者想问:我们在学会前面两节初阶教程之后,已经有很强的操作数据库的能力了,为什么我们还要用上数据库的约束呢?这个问题是个好问题,任何技术都不能因为是技术而成为技术,脱离了业务的技术是毫无意义的。博主觉得用语言来描述约束的意义其实蛮空泛的,就算写出来了也只是表达了自己的看法,博主更希望大家能在了解约束的过程中去思考约束存在的必要性。
下面就正式开始介绍数据库约束了,请各位读者继续向下阅读。
1.primary key
在我们谈primary key这个约束之前,我们最好先了解一下NOT NULL和UNIQUE这两个约束,因为:primary key相当于NOT NULL和UNIQUE的合体。
那么NOT NULL是什么意思呢?翻译过来就是:非空。这代表着:当数据库表插入一条新数据时,被NOT NULL修饰字段不能够没有数据。而UNIQUE又是什么意思呢?很简单:唯一。也就是说:当数据库表插入一条新数据时,被UNIQUE修饰字段的数据不能够与前面的数据相同。
空口无凭,我们用代码来简单验证一下吧~各位读者也可以复杂下方代码自己运行一下
# 创建数据库表
create table student (
id int NOT NULL,
name varchar(20) UNIQUE
);
# 查看表结构
desc student;
# 插入错误数据:验证NOT NULL
insert into student (name) values ("张三");
# 验证 UNIQUE
insert into student values (1,"张三"); # 必须要插入一条数据才能造成重复的情况
insert into student values (2,"张三");
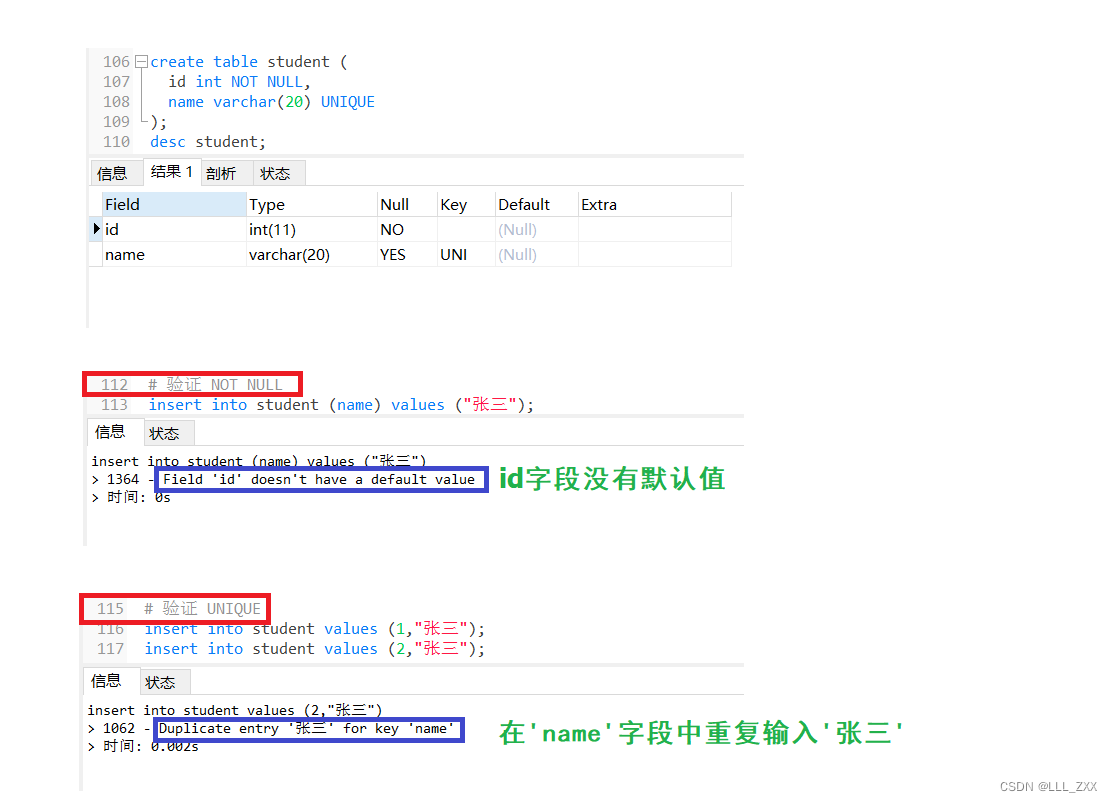
理解了NOT NULL和UNIQUE之后,我们就能理解PRIMARY KEY这个约束了。它的意思是:不重复且不为空的数据。那么这个约束在什么时候会用上呢?可以说每一张表都必须要一个PRIMARY KEY,也就是主键。为什么这么说呢 ?因为当我们不能用一个唯一的字段去标识一条数据的时候,我们在查询、修改以及删除的时候就不能找到唯一的依据。举个例子:在一个班上(相当于一张表中),有两个肉眼难分的双胞胎,且名字也是一样的(所有字段上的数据都是相同的),如果我们想让双胞胎中的老大起来朗读课文,我们能做到吗?很显然,根本不可以。为了区分两个双胞胎同学(两条数据),我们就可以用上学号(被PRIMARY KEY修饰的唯一非空字段)。
在理解PRIMARY KEY之后,我们会遇到一个棘手的问题:如果唯一约束的数据量太大,已经超出BIGINT类型,我们应该怎么办?很多读者应该会想到咱们在MySQL——初阶教程【1】中提到的:分布式。的确,我们的解决办法确实是分布式,但是数据分布在多台机器上,我们怎么去插入和查询一条数据呢?这就涉及到:分布式系统唯一id生成算法,算法的具体实现有很多方式,这里只是简单提一提大概的实现方法:时间戳 + 主机编号 + 随机因子。就是这个方法让所有的id都是不一样的,也就能够继续存储了。
2.auto_increment
这个auto_increment可以说是PRIMARY KEY的辅助约束,因为它的作用就是:自增。如果我们每一次在插入数据的时候都要去查表中最新的id字段到了多少,才去插入数据,无疑是很机械重复的无意义工作。这时候auto_increment这个约束就可以帮我们在最新数据的基础上增加一位。
让我们继续用代码演示一下吧~
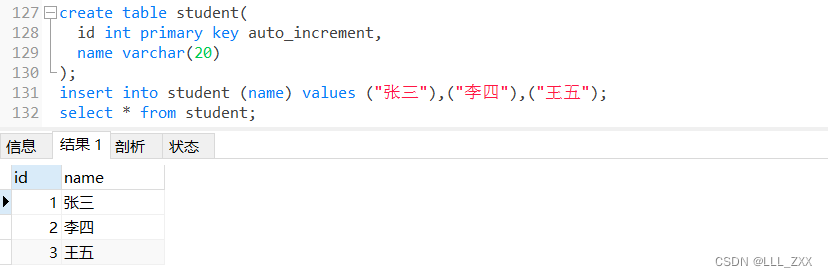
create table student(
id int primary key auto_increment,
name varchar(20)
);
insert into student (name) values ("张三"),("李四"),("王五"); # 一次性输入,节省资源开销
select * from student; # 数据量较少才选择使用
3.default
default这个约束我们在 MySQL——初阶教程【2】已经说过了,这里就不重复了,咱们直接看示例吧!
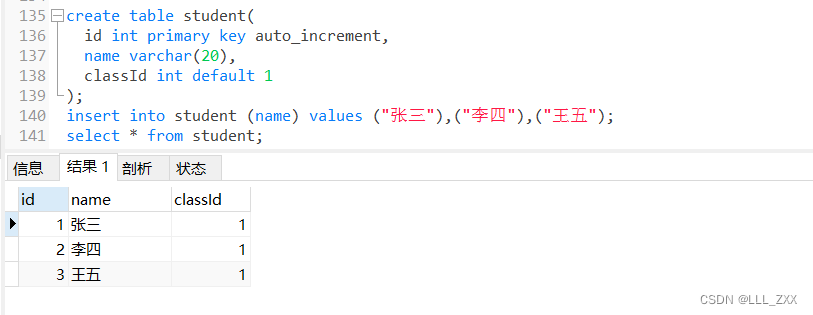
create table student(
id int primary key auto_increment,
name varchar(20),
classId int default 1
);
insert into student (name) values ("张三"),("李四"),("王五");
select * from student;
4.foreign key
foreign key可以称为:外键约束。它的作用有两层:第一,让MySQL帮我们自动完成一些检查工作;第二,可以通过外键约束字段进行联合查询。
我们在此处给大家验证第一点,第二点在后文联合查询部分会给大家进行详细的演示。
# 学生表
create table student(
id int primary key auto_increment,
name varchar(20),
classId int not null,
foreign key (classId) references class(id) # 指定外键关联关系
);
insert into student (name,classId) values ("张三",1),("李四",1),("王五",2);
select * from student;
# 班级表
create table class(
id int primary key auto_increment,
className varchar(20) NOT NULL
);
insert into class (className) values ("C"),("C++"),("Java");
select * from class;
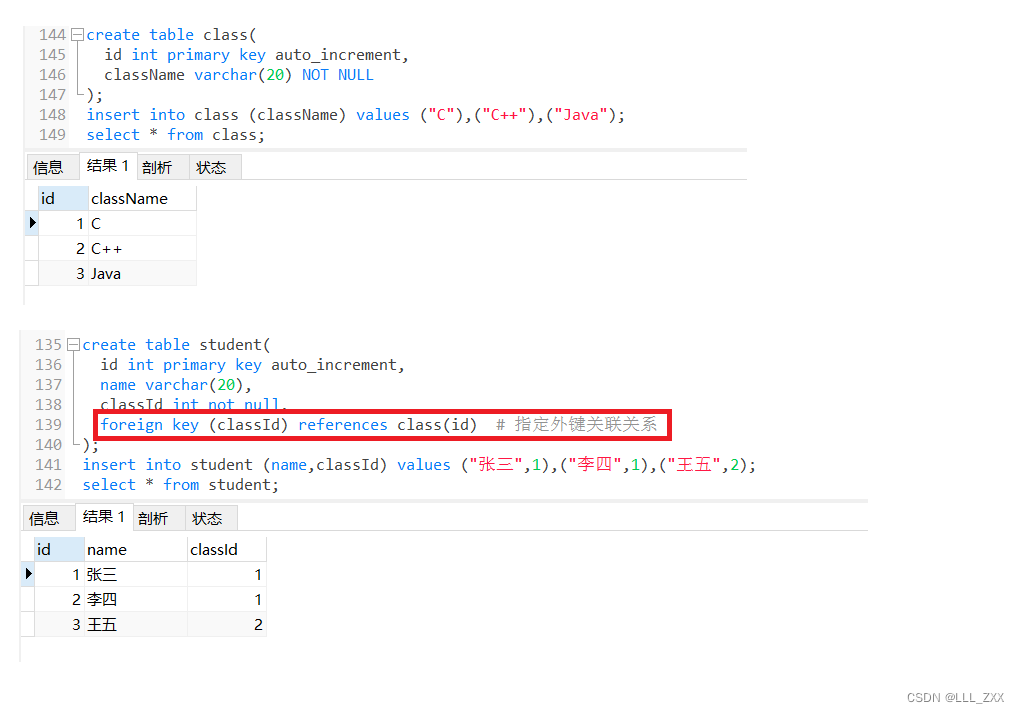
正常创建情况如上,foreign key的标准使用格式如下:
foreign key (外键字段) references 外键关联表(关联字段);
接下来我们可以尝试对已经设置了外键的student表进行一些实验。比如说:把"王五"的班级信息修改的6班 或者 插入"赵六"是6班这条信息。结果如下所示,我们看到虽然执行了不同的代码,但是报了相同的错误!也就是:不能新增或者修改子表中的这一行,一个外键已经约束了字段。而这个错误本质上是因为:在class这个表中,根本没有id = 6的班级。这恰恰就能体现:外键能够帮我们进行一些检查的操作。
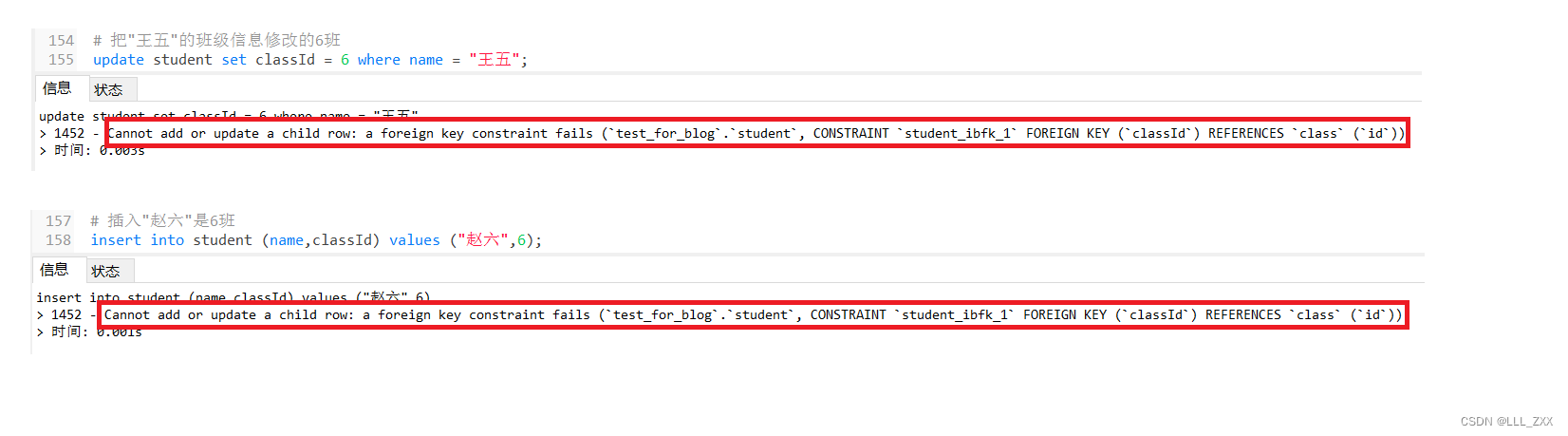
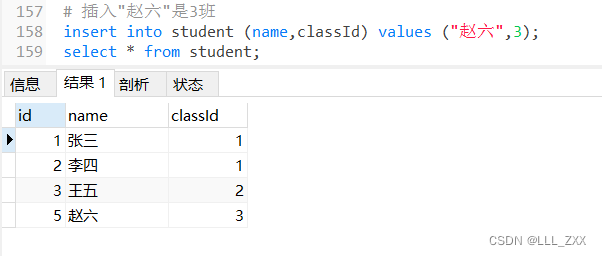
然而,当我们插入的数据在class表中id是正确的情况下就能成功。
二、复杂的查询
1.聚合查询
(1)聚合函数
认识聚合查询,我们最好从学习聚合函数。
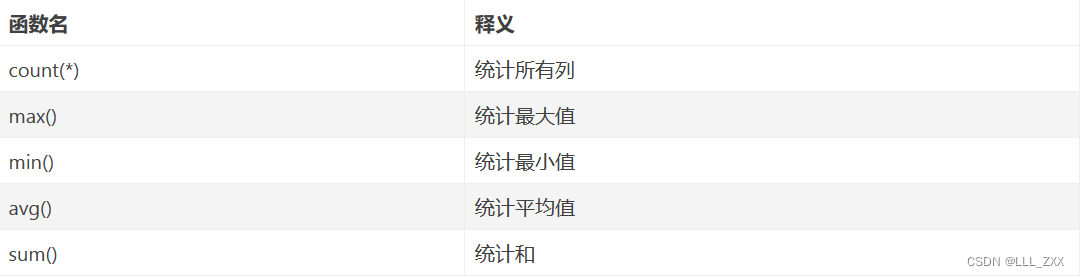
以上是常用的五个聚合函数,各位读者自行阅读。
接下来,我们分别对五个聚合函数进行一些验证,在这之前我们先创建一个表并插入一些数据。
create table score (
id int,
name varchar(50),
chinese decimal(3,1),
math decimal(3,1),
english decimal(3,1)
);
insert into score values
(1,'唐三藏', 67, 98, 56),
(2,'孙悟空', 87.5, 78, 77),
(3,'猪悟能', 88, 98.5, 90),
(4,'曹孟德', 82, '84', 67),
(5,'刘玄德', 55.5, 85, 45),
(6,'孙权', 70, 73, 78.5),
(7,'宋公明', 75, 65, 30);

count()
为了更好的演示效果,我们再添加一行代码
insert into score (id,chinese,math,english) values (8,56,48,86);
代码运行结果如下所示:
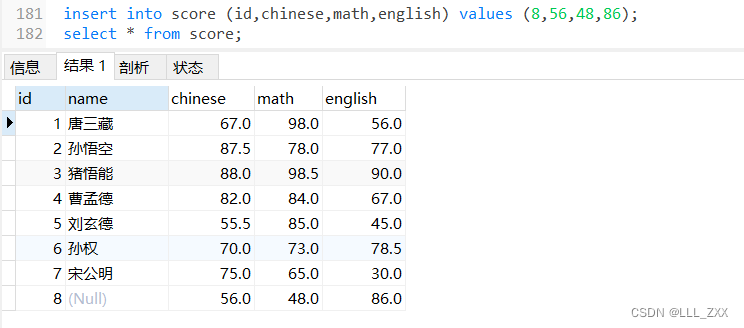
此时如果我们使用了count()这个聚合函数会发生什么呢?
# 查看一共有多少行
select count(*) from score;
# 查看有名字的有几行
select count(name) from score;
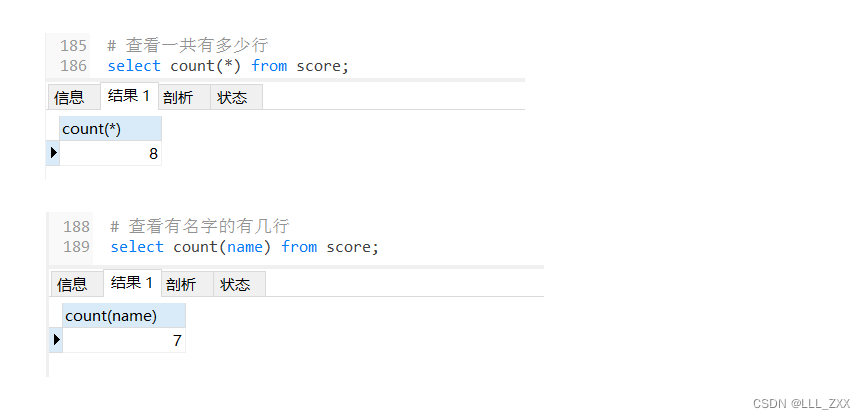
可以发现:count()这个聚合函数就算的行是按照是否为空来统计的。
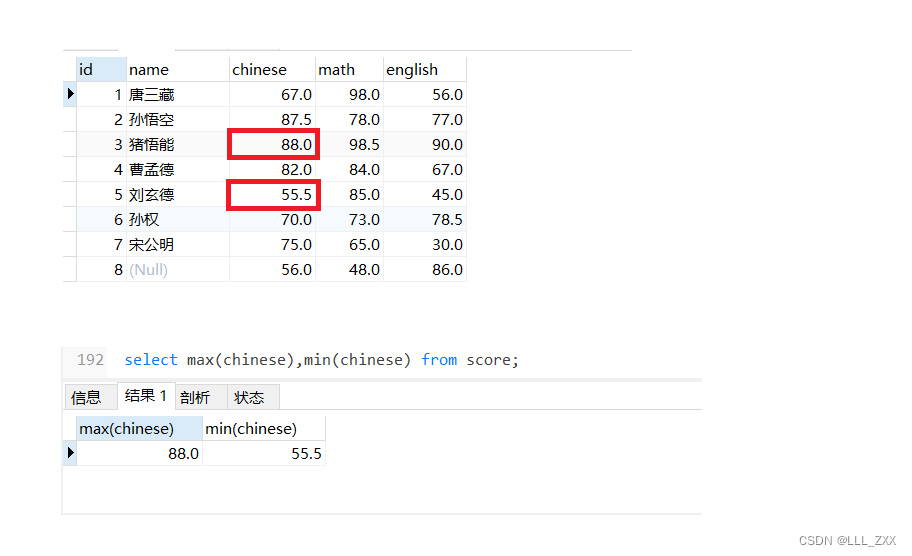
max() 与 min()
这两个聚合函数的含义非常清晰,这里就不再赘述了,我们直接看代码示例吧。
select max(chinese),min(chinese) from score;
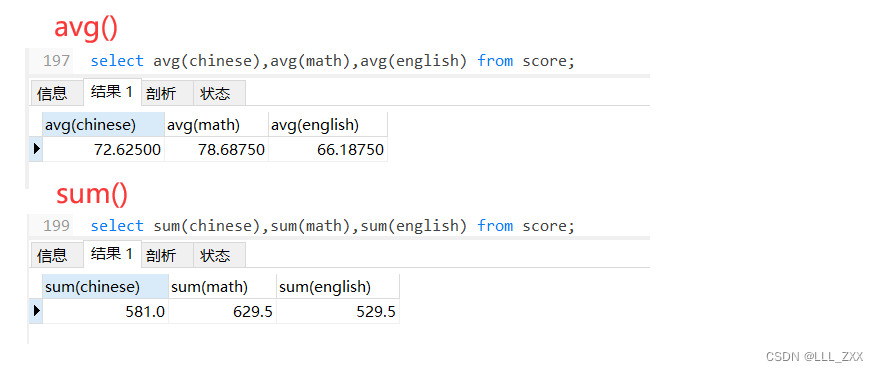
avg() 与 sum()
select avg(chinese),avg(math),avg(english) from score;
select sum(chinese),sum(math),sum(english) from score;
(2)用 group by 分组查询
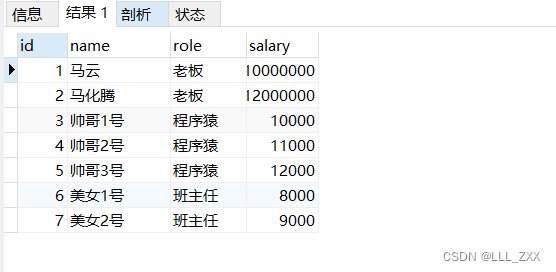
同样为了演示方便,我们先运行以下代码,运行结果如图。
create table emp (
id int primary key auto_increment,
name varchar(20),
role varchar(20),
salary int
);
insert into emp values (null,'马云','老板',10000000),
(null,'马化腾','老板',12000000),(null,'帅哥1号','程序猿',10000),
(null,'帅哥2号','程序猿',11000),(null,'帅哥3号','程序猿',12000),
(null,'美女1号','班主任',8000),(null,'美女2号','班主任',9000);
这里我们计算一下大家的平均工资,使用的方法也很简单,就算上方介绍的聚合函数avg(),代码如下,运行结果如图:
select avg(salary) from emp;
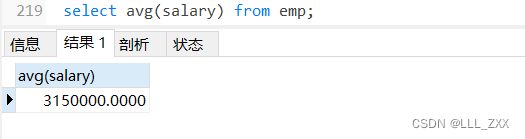
不知道各位读者看到这张表的时候作何感想,博主只是无奈叹气呀!本来我们想算算平均数,算完之后却发现,所有程序员、班主任的工资都被平均了。我们得出这样的结果对我们分析数据真的有意义吗?那么真正有意义的做法是什么呢?其实是:按角色来计算平均值。
那么怎么样才能按角色来计算呢?这就要用到group by子句进行分组查询了。具体代码如下,运行结果如下:
select role,avg(salary) from emp group by role order by avg(salary) asc;
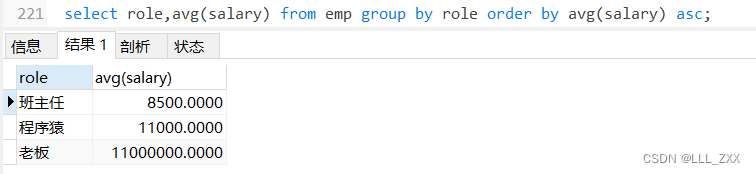
这个group by子句是肉眼可见的强,那我们能不能将前面学的where子句一起用上呢?当然没问题,比如:在剔除帅哥3号之后再分组求平均薪资。
select role,avg(salary) from emp where name != "帅哥3号" group by role order by avg(salary) asc;

这个操作很不错,那现在博主不想看到老板这个角色的平均工资,看到就是慢慢的嫉妒,代码应该怎么写呢?简单:group by之后再用where嘛!然而事情真的有这么简单吗,少年少女们?

很明显,我们不能用where为我们过滤结果,那应该怎么办呢?别着急,马上就介绍到!
(3)用 having 对分组结果过滤
我们可以用having关键字对分组结果过滤!
那么代码应该怎么写呢?
select role,avg(salary) from emp group by role having role != "老板";
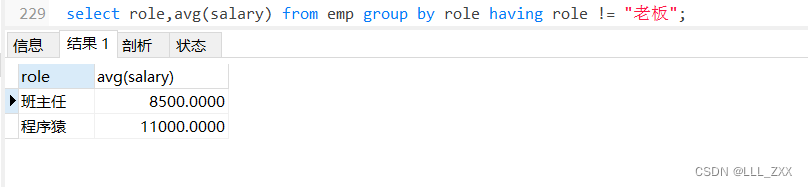 ]
]
果然成功了!那么接下来就把where子句也拉进来,搞应该巨复杂的代码玩一玩吧~
业务要求:按照从高到低的顺序对不同角色的工资进行查询,这次查询不包含
帅哥3号,查询结果也不包含老板
select role,avg(salary) from emp where name != "帅哥3号" group by role having role != "老板";

2.联合查询
终于谈到联合查询这一块了,我们上面在foreign key挖的坑让博主耿耿于怀。在谈联合查询之前,我们需要补充一个简单的数学知识,就是接下来要介绍的笛卡尔积。
(1)笛卡尔积
百度百科对笛卡尔积的定义如下:两个集合X和Y的笛卡尔积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员,而第二个对象是Y的所有可能有序对的其中一个成员 。
这句话让我们大概有点感觉,但是不够直观,接下来我们就用代码来演示一下怎么弄出一个笛卡尔积出来吧!代码如下所示,运行结果如图:
# 学生表
create table student (
id int primary key auto_increment,
name varchar(20) not null,
classId int not null,
foreign key (classId) references class(id)
);
insert into student (name,classId) values ("张三",1),("李四",1),("王五",2),("赵六",3);
# 班级表
create table class (
id int primary key auto_increment,
className varchar(20) not null
);
insert into class (className) values ("C"),("C++"),("Java");
# 笛卡尔积写法
select * from student,class;
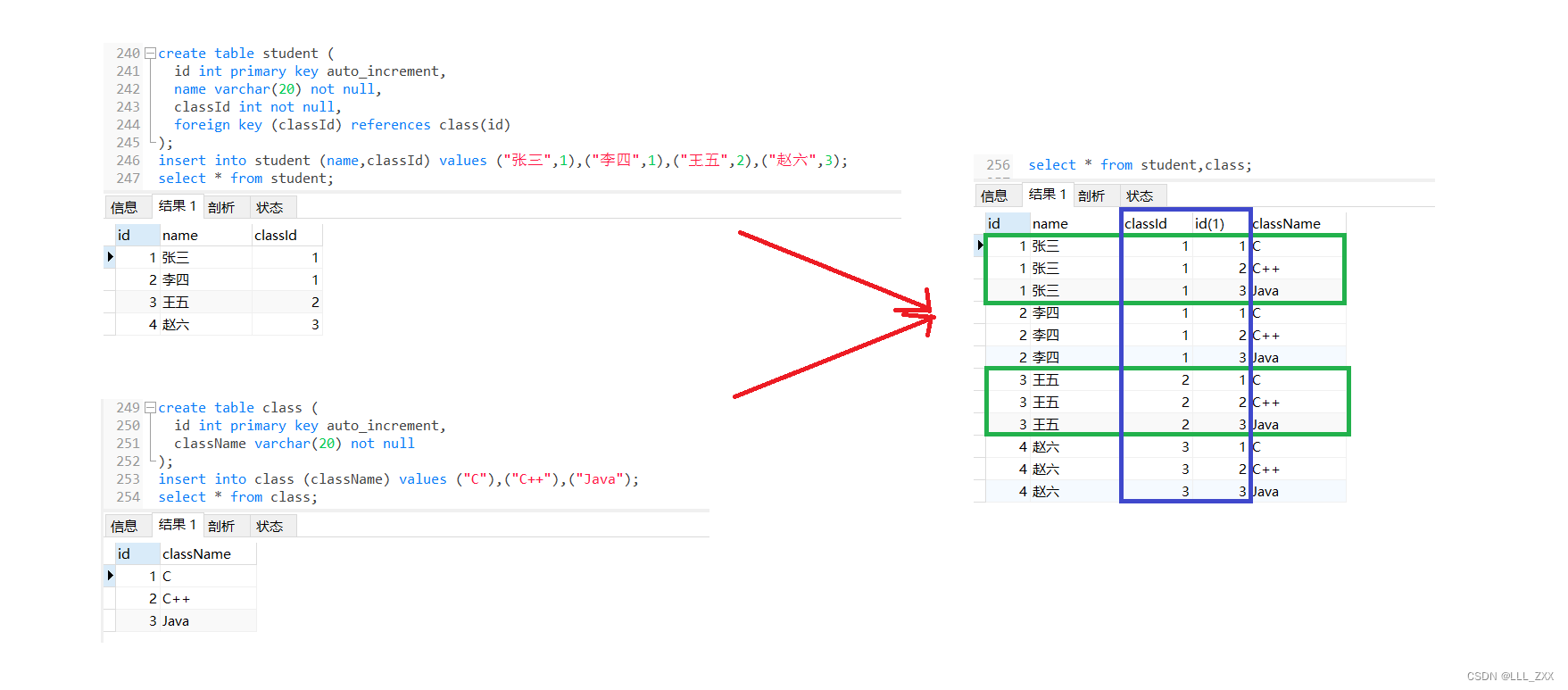
看到运行结果就很清晰了,这里的笛卡尔积就是让student表的每一个数据都包含了一个class表。我们可以看到,蓝色框处有许多对不上的数据,因为我们设置的外键就是要求student.classId = class.id呀!但是这都没关系,因为我们可以用where子句进行过滤,最让我们惊喜的是:student表和class表联合在一起成了一张大表!
接下来我们就来处理这张大表,一起看看联合之后正确的代码和运行结果长啥样吧!
select student.id, student.name, student.classId, class.className
from student,class
where student.classId = class.id;
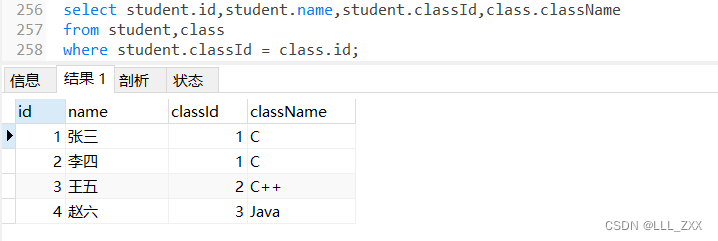
有了笛卡尔积这个操作,我们就能利用外键看到很多其他表的消息了,是一个非常好玩的工具!
(2)内连接与外连接
内连接
其实我们上面利用笛卡尔积联合成一张大表的操作其实就是内连接,内连接是只返回两个表中连接字段相等的行。它只会返回两个表中匹配到的数据,如果匹配不到,则不保留。如果用内连接的语法写,我们需要:join on关键字。标准使用格式如下:
# 内连接
select 字段名 from 表1 inner join 表2 on 连接条件
select 字段名 from 表1 join 表2 on 连接条件
我们还是用具体代码来描述吧!代码如下,运行效果如下:
# 学生表
create table student(
id int primary key auto_increment,
name varchar(20) not null
);
insert into student (name) values ('张三'),('李四'),('王五');
# 分数表
create table score(
score_id int,
score int
);
insert into score values (1,90),(2,98),(3,99);
# 内连接
select * from student join score on student.id = score.score_id;

外连接
相信大家已经明白内连接是怎么一回事了,那么外连接是干嘛用的呢?当数据没有对应时,外连接会分成:左外连接和右外连接。它们在处理数据时,会根据关联条件分别返回左表、右表或左右表中所有的记录,如果在一侧的表中没有找到匹配的记录,那么这一侧的表中的数据将以NULL显示。同样的,我们先分别介绍一下语法格式吧~
# 左连接
select 字段名 from 表1 left join 表2 on 连接条件
# 右连接
select 字段名 from 表1 right join 表2 on 连接条件
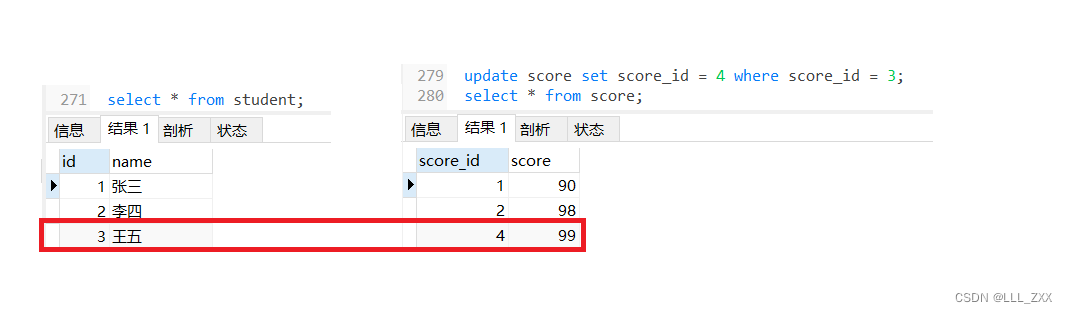
为了方便演示,我们需要将数据改成不对应的形式,因此加入下方代码,运行结果如下:
update score set score_id = 4 where score_id = 3;
此时如果我们可以尝试使用左连接 和 右连接,就会发现如下情况:
# 左连接
select * from student left join score on student.id = score.score_id;
# 右连接
select * from student right join score on student.id = score.score_id;
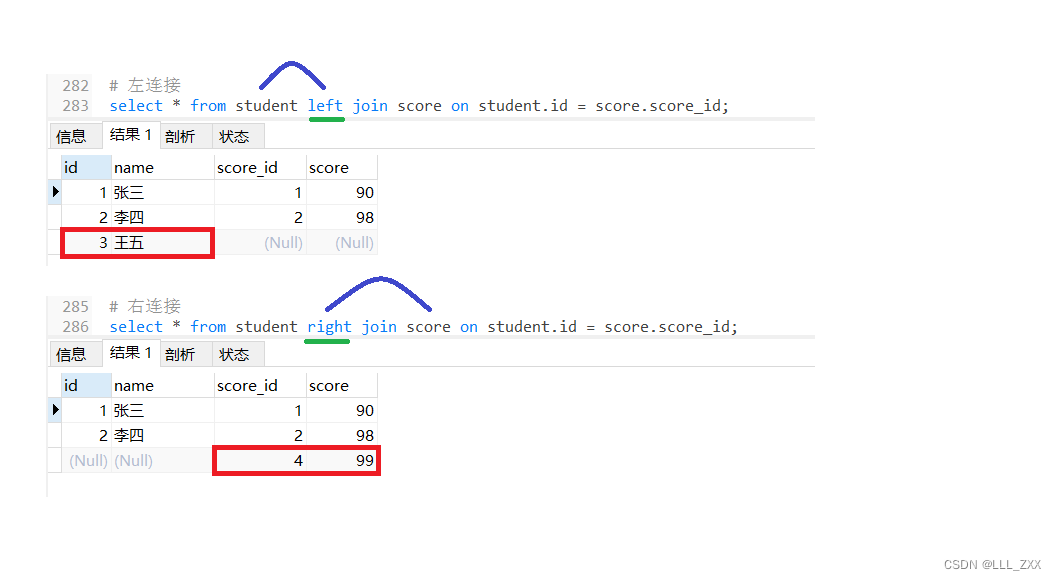
因此我们可以知道:当数据不对应时:左连接就是保留左表的数据,右连接就是保留右表的数据。
(3)自连接
自连接其实属于奇淫巧计一类的方法,因为不同行之间无法比较。那么有什么办法能够让不同行之间进行比较呢?最先想到的也应该是笛卡尔积。我们上方演示的所有代码其实都把信息不同的通过where子句排除出去,但是我们要比较不同行,就是要保留这些不同信息。
我们还是用代码来演示,预备代码如下,运行效果如图:
create table score(
id int primary key auto_increment,
name varchar(20) not null,
chinese int,
math int,
english int
);
insert into score values (1,"张三",45,89,61),(2,"李四",75,64,125),(3,"王五",75,25,45);
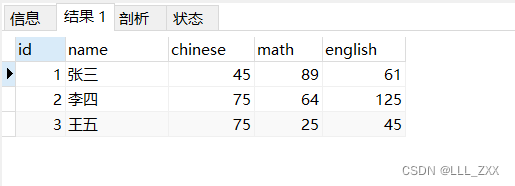
自连接标准格式:
select * from score as s1,score as s2;
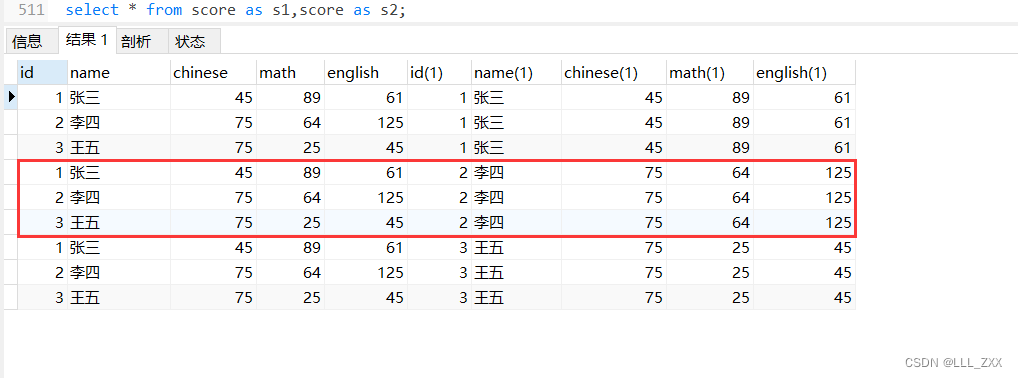
我们已经把相同信息和不同信息一起放到这张表上了,但是我们的工作其实还没有真正完成,因为我们需要把相同的信息排除才算真正得到我们想要的表,要完成这一步就非常简单了,只需要排除id相同的同学就好了,注意:最好不要用名字作为比较,因为名字也很可能重复,而唯一不可能重复的信息就是id字段了!
select * from score as s1,score as s2 where s1.id != s2.id;
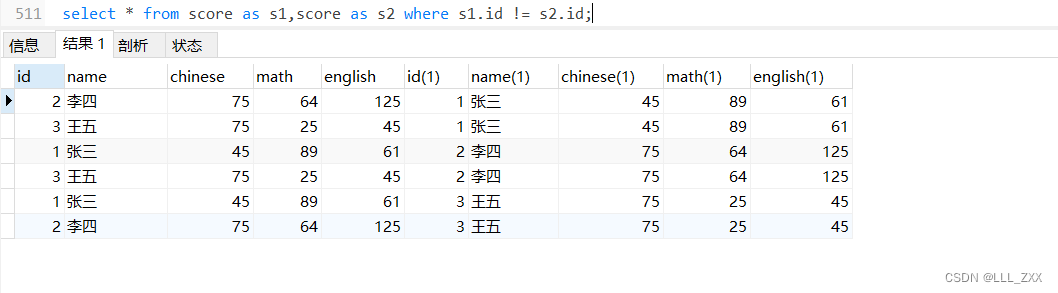
这个表中,无论哪位同学想跟其他的同学比较哪一科都是没问题的,具体的比较示例这里就不写了,大家可以自己玩一玩。
3.子查询
子查询本质上就是套娃。只需要把一个SQL语句用()包裹,写到另外一个子句上就可以了。
这部分的内容比较简单,加上博主自己不喜欢子查询(巨长巨丑,读起来老费劲了),所以大家自己去练习吧。
4.合并查询
要想实现合并查询主要靠的是union与union all这两个关键字。合并查询这个操作用在同一张表相当于or,真正能凸显出其能力的是:可以合并不用表中的相同数据类型。
我们先来看看,合并同一张表的操作是长啥样的先吧~
select country from student where id >= 2
union select country from student where name = "张三";
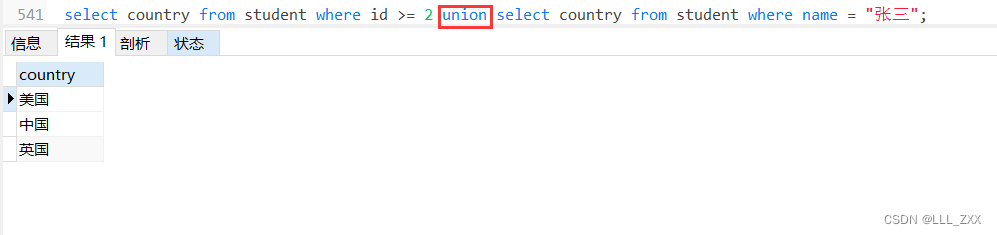
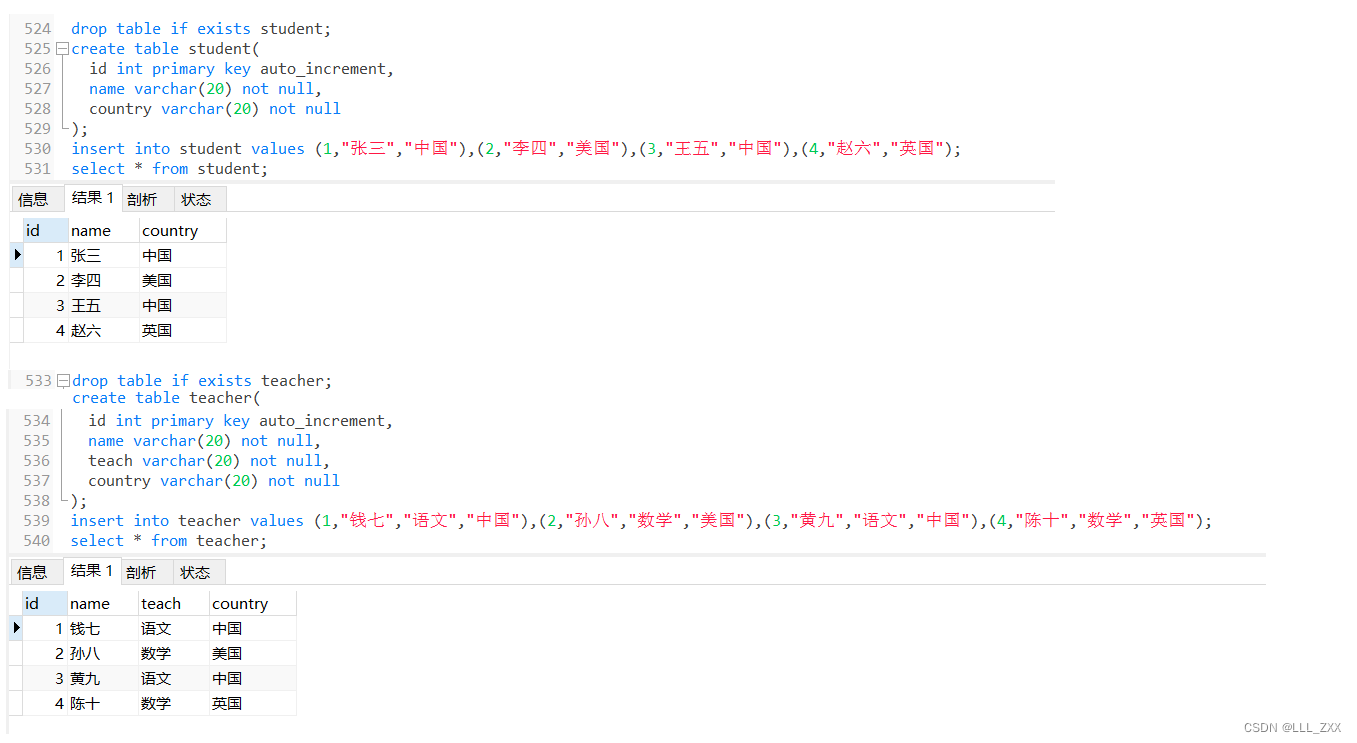
合并不同表的操作其实也不难,看了下方的例子就能明白啦!我们先准备一些数据,代码如下,运行结果如下:
drop table if exists student;
create table student(
id int primary key auto_increment,
name varchar(20) not null,
country varchar(20) not null
);
insert into student values (1,"张三","中国"),(2,"李四","美国"),(3,"王五","中国"),(4,"赵六","英国");
drop table if exists teacher;
create table teacher(
id int primary key auto_increment,
name varchar(20) not null,
teach varchar(20) not null,
country varchar(20) not null
);
insert into teacher values (1,"钱七","语文","中国"),(2,"孙八","数学","美国"),(3,"黄九","语文","中国"),(4,"陈十","数学","英国");
那么,怎么实现我们想要的合并查询呢?直接用union,只不过在union的另一侧填上别的表,以下方代码为例,查询结果如下:
select country from student where id >= 2 union select country from teacher where id < 5;
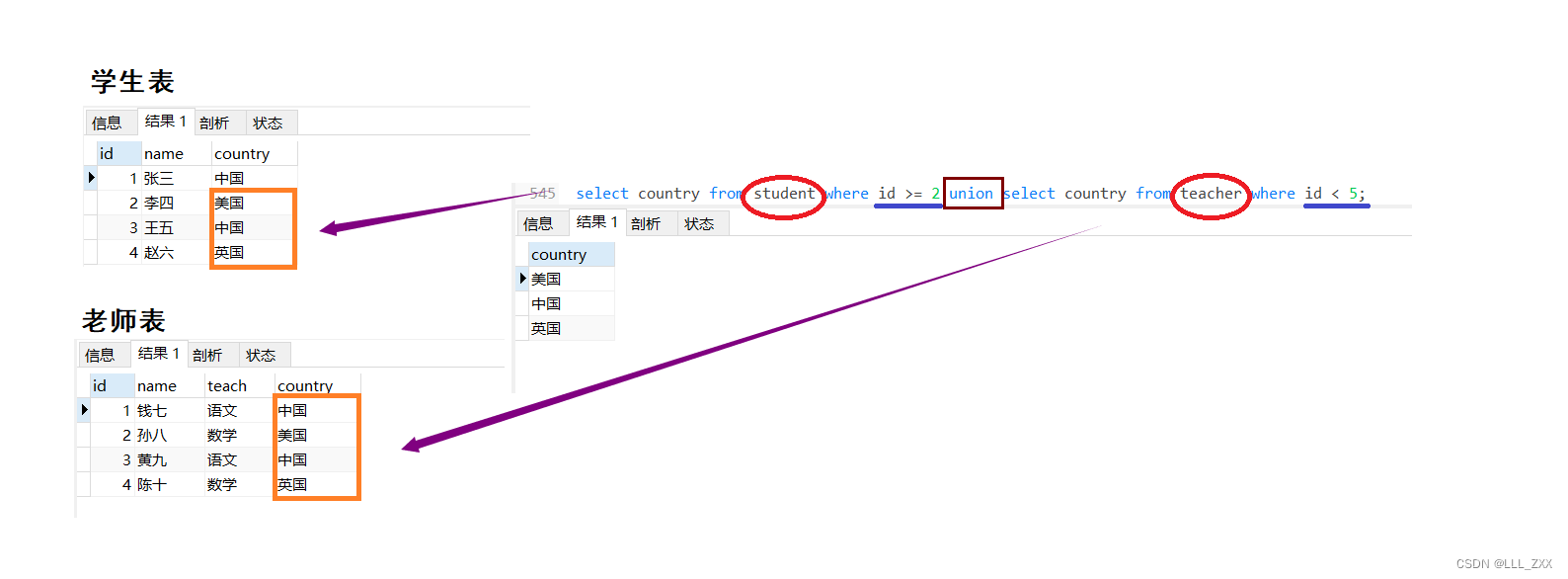
在最开始的时候,咱们提到了,只要是相同的数据类型就能够合并,那我们能不能合并一下学生表的country和老师表的teach呢?没问题!不过结果蛮搞笑的。
select country as `不伦不类`from student where id >= 2 union select teach from teacher where id < 5;

三、SQL语句汇总
1.建表约束
-- 题目表
drop table question;
create table if not exists question
(
id bigint auto_increment primary key comment 'id',
title varchar(512) null comment '标题',
tags varchar(1024) null comment '标签列表(JSON数组)',
content text null comment '内容',
answer text null comment '题目答案',
submitNum int default 0 not null comment '题目提交次数',
acceptedNum int default 0 null comment '题目通过数',
passRate varchar(20) default '0.00%' not null comment '题目通过率',
-- 若干用例文件 > 512KB,建议单独存放在一个文件中,数据库中只保存文件URL(类似于存储用户头像)
-- MySQL扛不住可以用 MongoDB,更加适合用于存文件类型的数据库
judgeCase text null comment '判题用例(JSON数组)',
-- 存JSON的好处:便于扩展,只需要改变对象内部的字段,而不用修改数据库表(可能会影响数据库)
-- 时间限制 timeLimit 空间限制 memoryList
judgeConfig text null comment '判题配置(JSON对象)',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除',
index idx_userId (userId)
) comment '题目' collate = utf8_unicode_ci;
2.复杂查询
(1)聚合查询
select role, count(name), max(chinese), min(chinese), avg(salary), sum(math)
from emp
group by role
having role != "老板";
(2)联合查询
1)笛卡尔积
select student.id, student.name, student.classId, class.className
from student,class
where student.classId = class.id;
2)内连接
select 字段名 from 表1 inner join 表2 on 连接条件
3)外连接
# A.左连接
select 字段名 from 表1 left join 表2 on 连接条件
# B.右连接
select 字段名 from 表1 right join 表2 on 连接条件
4)自连接
select * from score as s1,score as s2;
(3)合并查询
# A.union 不去重
select country from student
union
select country from student;
# B.union all 去重
select country from student
union all
select country from student;
结语
MySQL进阶第一章的教程就到处结束啦,内容很多,但却不难,需要我们不断去练习与实践!
如果你觉得博主写得不错的话,请给一个赞支持一下吧!博主能力有限,欢迎大家给我纠错!















 1495
1495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









