







dex是Android平台上(Dalvik虚拟机)的可执行文件, 相当于Windows平台中的exe文件, 每个Apk安装包中都有dex文件, 里面包含了该app的所有源码, 通过反编译工具可以获取到相应的java源码。
为什么需要学习dex文件格式? 最主要的一个原因: 由于通过反编译dex文件可以直接看到java源码, 越来越多的app(包括恶意病毒app)都使用了加固技术以防止app被轻易反编译, 当需要对一个加固的恶意病毒app进行分析或对一个app进行破解时, 就需要了解dex文件格式, 将加固的dex文件还原后(脱壳)再进行反编译获取java源码, 所以
要做Android安全方面的深入, dex文件格式是基础中的基础。
通过一个构建简单的dex文件, 来学习和了解dex文件的相关格式, 首先编写一段java代码:

public class Hello { public static void MyPrint(String str) { System.out.printf(str + "\r\n"); } public static void main(String[] argc) { MyPrint("nihao, shijie"); System.out.println("Hello World!"); } }
将.java文件编译成.class文件:
javac Hello.java
将.class文件编译成.dex文件:
dx --dex --output=Hello.dex Hello.class
dx是Android SDK中继承的工具(dx.bat), 在SDK目录下 AndroidSDK\build-tools\19.1.0中(选择自己的安装版本, 这里就用19.1.0了)
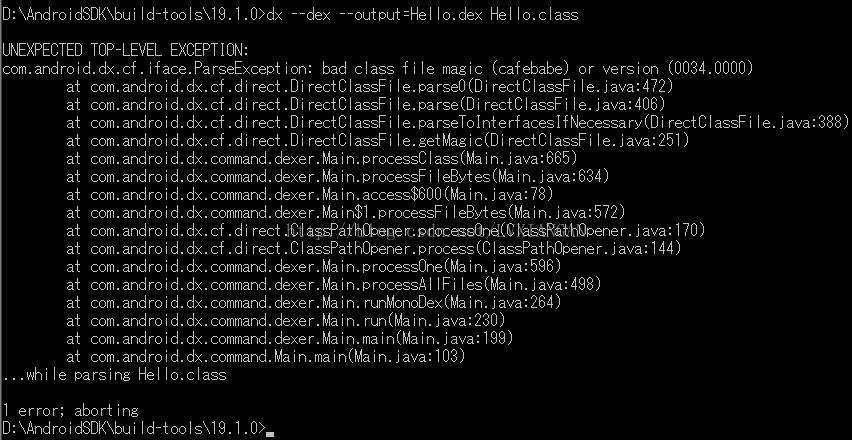
如果在编译dex时, 出现图上的错误提示, 说明编译.class文件时使用的JDK版本太高了, 使用1.6版本的JDK就可以了, 重新生成.class文件, 然后再使用dx工具生成.dex文件即可:
javac -source 1.6 -target 1.6 Hello.java
可以将生成的dex放到Android的虚拟机中运行测试:
adb push Hello.dex /mnt/sdcard/
adb shell dalvikvm -cp /mnt/sdcard/Hello.dex Hello

进入正题, 先来看一张dex文件结构图, 来了解一个大概:
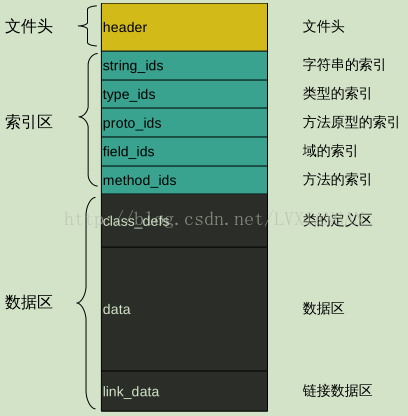
整个dex文件被分成了三个大块
(可用UltraEdit打开)
第一块: 文件头
文件头记录了dex文件的一些基本信息, 以及大致的数据分布. dex文件头部总长度是固定的0x70
dex_header:
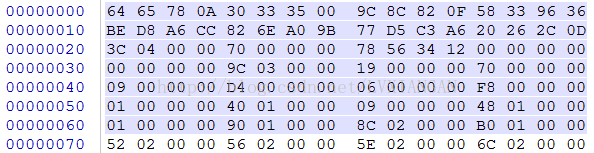
下表中,偏移量=起始下标,长度=数据长度,需要对照ASC码表,如字符d对应着16进制的0x64
| 字段名称 | 偏移量 | 长度(byte) | 当前例子中字段值 | 字段描述 |
| magic | 0x0 | 0x8 | dex 035 | dex魔术字, 固定信息: dex\n035 |
| checksum | 0x8 | 0x4 | 0x0F828C9C | alder32算法, 去除了magic和checksum 字段之外的所有内容的校验码 |
| signature | 0xc | 0x14 | 58339636BED8A6CC826E A09B77D5C3A620262CD | sha-1签名, 去除了magic、checksum和 signature字段之外的所有内容的签名 |
| fileSize | 0x20 | 0x4 | 0x0000043C | 整个dex的文件大小 |
| headerSize | 0x24 | 0x4 | 0x00000070 | 整个dex文件头的大小 (固定大小为0x70) |
| endianTag | 0x28 | 0x4 | 0x12345678 | 字节序 (大尾方式、小尾方式) 默认为小尾方式 <--> 0x12345678 |
| linkSize | 0x2c | 0x4 | 0x00000000 | 链接段的大小, 默认为0表示静态链接 |
| linkOff | 0x30 | 0x4 | 0x00000000 | 链接段开始偏移 |
| mapOff | 0x34 | 0x4 | 0x0000039C | map_item偏移 |
| stringIdsSize | 0x38 | 0x4 | 0x00000019 | 字符串列表中的字符串个数 |
| stringIdsOff | 0x3c | 0x4 | 0x00000070 | 字符串列表偏移 |
| typeIdsSize | 0x40 | 0x4 | 0x00000009 | 类型列表中的类型个数 |
| typeIdsOff | 0x44 | 0x4 | 0x000000D4 | 类型列表偏移 |
| protoIdsSize | 0x48 | 0x4 | 0x00000006 | 方法声明列表中的个数 |
| protoIdsOff | 0x4c | 0x4 | 0x000000F8 | 方法声明列表偏移 |
| fieldIdsSize | 0x50 | 0x4 | 0x00000001 | 字段列表中的个数 |
| fieldIdsOff | 0x54 | 0x4 | 0x00000140 | 字段列表偏移 |
| methodIdsSize | 0x58 | 0x4 | 0x00000009 | 方法列表中的个数 |
| methodIdsOff | 0x5c | 0x4 | 0x00000148 | 方法列表偏移 |
| classDefsSize | 0x60 | 0x4 | 0x00000001 | 类定义列表中的个数 |
| classDefsOff | 0x64 | 0x4 | 0x00000190 | 类定义列表偏移 |
| dataSize | 0x68 | 0x4 | 0x0000028C | 数据段的大小, 4字节对齐 |
| dataOff | 0x6c | 0x4 | 0x000001B0 | 数据段偏移 |
第二块: 索引区
索引区中索引了整个dex中的字符串、类型、方法声明、字段以及方法的信息, 其结构体的开始位置和个数均来自dex文件头中的记录(或通过map_list也可以索引到记录)
1. 字符串索引区, 描述dex文件中所有的字符串信息
//Direct-mapped "string_id_item". struct DexStringId { u4 stringDataOff; //file offset to string_data_item };
描述字符串索引的结构体为DexStringId, 里面只有一个成员是指向string_id_item结构的偏移, 在dalvik源码的doc文档(dex-format.html)中可以看到对该结构的描述

字符串列表中的字符串并非普通的ascii字符串, 它们是由MUTF-8编码表示的
MUTF-8为Modified UTF-8, 即经过修改的UTF-8编码, 有以下特点:
①. MUTF-8使用1~3字节编码长度
②. 大于16位的Unicode编码 U+10000~U+10ffff使用3字节来编码
③. U+0000采用2字节来编码
④. 采用类似于C语言中的空字符null作为字符串的结尾
string_id_item:
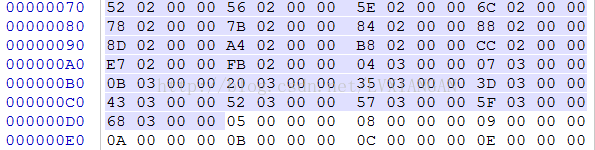
string_data_item:
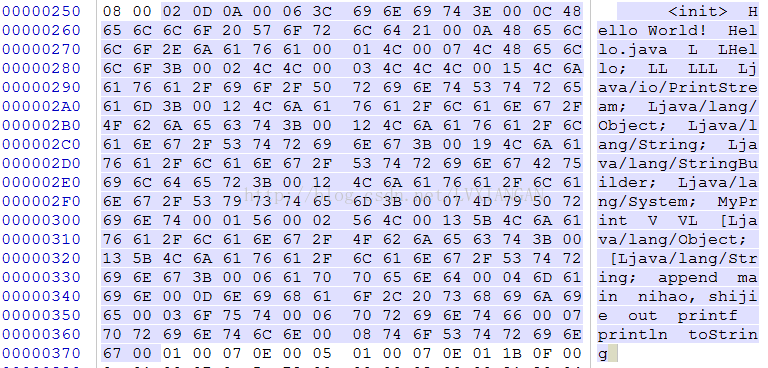
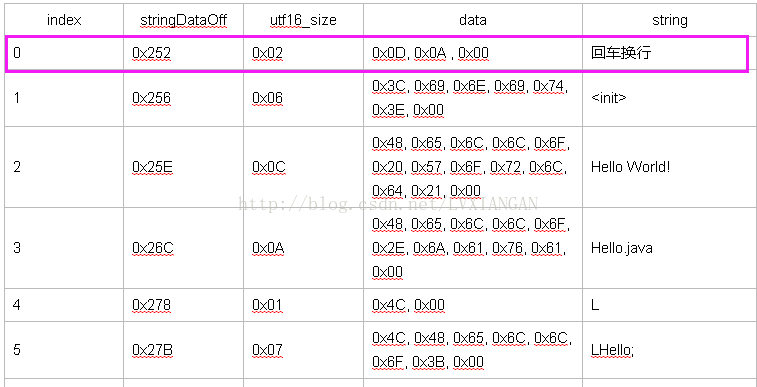
| index | stringDataOff | utf16_size | data | string |
| 0 | 0x252 | 0x02 | 0x0D, 0x0A , 0x00 | 回车换行 |
| 1 | 0x256 | 0x06 | 0x3C, 0x69, 0x6E, 0x69, 0x74, 0x3E, 0x00 | <init> |
| 2 | 0x25E | 0x0C | 0x48, 0x65, 0x6C, 0x6C, 0x6F, 0x20, 0x57, 0x6F, 0x72, 0x6C, 0x64, 0x21, 0x00 | Hello World! |
| 3 | 0x26C | 0x0A | 0x48, 0x65, 0x6C, 0x6C, 0x6F, 0x2E, 0x6A, 0x61, 0x76, 0x61, 0x00 | Hello.java |
| 4 | 0x278 | 0x01 | 0x4C, 0x00 | L |
| 5 | 0x27B | 0x07 | 0x4C, 0x48, 0x65, 0x6C, 0x6C, 0x6F, 0x3B, 0x00 | LHello; |
| 6 | 0x284 | 0x02 | 0x4C, 0x4C, 0x00 | LL |
| 7 | 0x288 | 0x03 | 0x4C, 0x4C, 0x4C, 0x00 | LLL |
| 8 | 0x28D | 0x15 | 0x4C, 0x6A, 0x61, 0x76, 0x61, 0x2F, 0x69, 0x6F, 0x2F, 0x50, 0x72, 0x69, 0x6E, 0x74, 0x53, 0x74, 0x72, 0x65, 0x61, 0x6D, 0x3B, 0x00 | Ljava/io/PrintStream; |
| 9 | 0x2A4 | 0x12 | 0x4C, 0x6A, 0x61, 0x76, 0x61, 0x2F, 0x6C, 0x61, 0x6E, 0x67, 0x2F, 0x4F, 0x62, 0x6A, 0x65, 0x63, 0x74, 0x3B, 0x00 | Ljava/lang/Object; |
| 10 | 0x2B8 | 0x12 | 0x4C, 0x6A, 0x61, 0x76, 0x61, 0x2F, 0x6C, 0x61, 0x6E, 0x67, 0x2F, 0x53, 0x74, 0x72, 0x69, 0x6E, 0x67, 0x3B, 0x00 | Ljava/lang/String; |
| 11 | 0x2CC | 0x19 | 0x4C, 0x6A, 0x61, 0x76, 0x61, 0x2F, 0x6C, 0x61, 0x6E, 0x67, 0x2F, 0x53, 0x74, 0x72, 0x69, 0x6E, 0x67, 0x42, 0x75, 0x69, 0x6C, 0x64, 0x65, 0x72, 0x3B, 0x00 | Ljava/lang/StringBuilder; |
| 12 | 0x2E7 | 0x12 | 0x4C, 0x6A, 0x61, 0x76, 0x61, 0x2F, 0x6C, 0x61, 0x6E, 0x67, 0x2F, 0x53, 0x79, 0x73, 0x74, 0x65, 0x6D, 0x3B, 0x00 | Ljava/lang/System; |
| 13 | 0x2FB | 0x07 | 0x4D, 0x79, 0x50, 0x72, 0x69, 0x6E, 0x74, 0x00 | MyPrint |
| 14 | 0x304 | 0x01 | 0x56, 0x00 | V |
| 15 | 0x307 | 0x02 | 0x56, 0x4C, 0x00 | VL |
| 16 | 0x30B | 0x13 | 0x5B, 0x4C, 0x6A, 0x61, 0x76, 0x61, 0x2F, 0x6C, 0x61, 0x6E, 0x67, 0x2F, 0x4F, 0x62, 0x6A, 0x65, 0x63, 0x74, 0x3B, 0x00 | [Ljava/lang/Object; |
| 17 | 0x320 | 0x13 | 0x5B, 0x4C, 0x6A, 0x61, 0x76, 0x61, 0x2F, 0x6C, 0x61, 0x6E, 0x67, 0x2F, 0x53, 0x74, 0x72, 0x69, 0x6E, 0x67, 0x3B, 0x00 | [Ljava/lang/String; |
| 18 | 0x335 | 0x06 | 0x61, 0x70, 0x70, 0x65, 0x6E, 0x64, 0x00 | append |
| 19 | 0x33D | 0x04 | 0x6D, 0x61, 0x69, 0x6E, 0x00 | main |
| 20 | 0x343 | 0x0D | 0x6E, 0x69, 0x68, 0x61, 0x6F, 0x2C, 0x20, 0x73, 0x68, 0x69, 0x6A, 0x69, 0x65, 0x00 | nihao, shijie |
| 21 | 0x352 | 0x03 | 0x6F, 0x75, 0x74, 0x00 | out |
| 22 | 0x357 | 0x06 | 0x70, 0x72, 0x69, 0x6E, 0x74, 0x66, 0x00 | printf |
| 23 | 0x35F | 0x07 | 0x70, 0x72, 0x69, 0x6E, 0x74, 0x6C, 0x6E, 0x00 | println |
| 24 | 0x368 | 0x08 | 0x74, 0x6F, 0x53, 0x74, 0x72, 0x69, 0x6E, 0x67, 0x00 | toString |
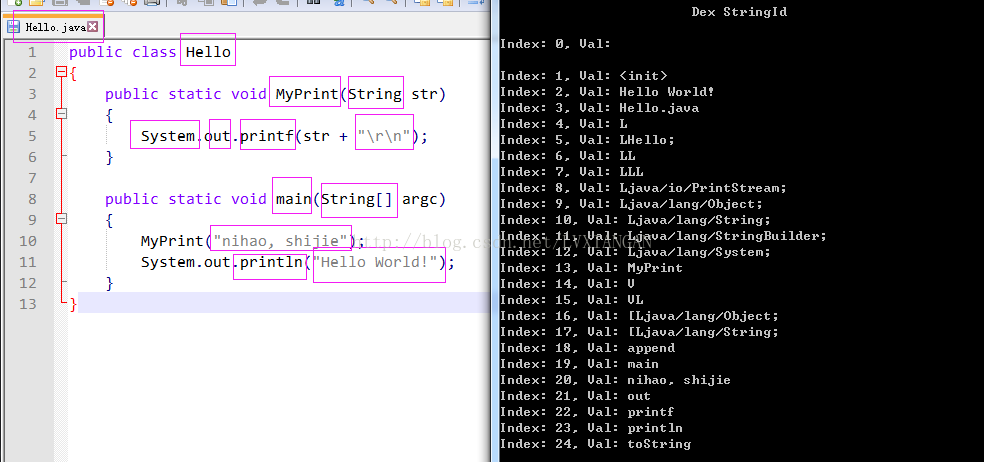
通过源码和字符串列表中的对比可以发现, 我们定义的类的类名, 成员函数名, 函数的参数类型, 字符串, 以及调用的系统函数的名和源码的文件名在字符串列表中都有对应的值
包括在MyPrint函数中printf的参数 str + "\r\n", 实际被转换为StringBuilder.append的形式在字符串列表中也有所体现
了解了字符串列表中的信息后, 其实就可以实现一个dex的字符串混淆器了, 把当前有意义的字符串名称替换成像a b c这样无意义的名称
当前目前只依靠字符串列表就实现混淆是不够的, 因为里面包含了系统函数的名称(System.out.print、main等),像这样的系统函数是不能被混淆的,所以还需要借助其他索引区的信息将一些不能被混淆的字符串排除掉
2. 类型索引区, 描述dex文件中所有的类型, 如类类型、基本类型、返回值类型等
//Direct-mapped "type_id_item". struct DexTypeId { u4 descriptorIdx; //DexStringId中的索引下标 };
描述类型索引的结构体为DexTypeId, 里面只有一个成员是指向字符串索引区的下标, 基本上结构体成员中以Idx结尾的都是某个索引列表的下标
type_id_item:

| index | descriptorIdx | string |
| 0 | 0x05 | LHello; |
| 1 | 0x08 | Ljava/io/PrintStream; |
| 2 | 0x09 | Ljava/lang/Object; |
| 3 | 0x0A | Ljava/lang/String; |
| 4 | 0x0B | Ljava/lang/StringBuilder; |
| 5 | 0x0C | Ljava/lang/System; |
| 6 | 0x0E | V |
| 7 | 0x10 | [Ljava/lang/Object; |
| 8 | 0x11 | [Ljava/lang/String; |

源码中的类类型、返回值类型在类型列表中都有对应的值, 在做dex字符串混淆的时间, 可以通过类型索引区过滤掉描述系统类类型、返回值类型的字符串,当然这还是不够的, 还需要借助其他索引区进行相应的排除
//Direct-mapped "proto_id_item". struct DexProtoId { u4 shortyIdx; //DexStringId中的索引下标 u4 returnTypeIdx; //DexTypeId中的索引下标 u4 parametersOff; //DexTypeList的偏移 };
shortyIdx为方法声明字符串
returnTypeIdx为方法返回类型字符串

![]()

![]()
type_list:
![]()
![]()
![]()
parametersOff指向一个DexTypeList结构体, 存放了方法的参数列表, 如果方法没有参数值为0
//Direct-mapped "type_item". struct DexTypeItem { u2 typeIdx; //DexTypeId中的索引下标 }; //rect-mapped "type_list". struct DexTypeList { u4 size; //DexTypeItem的个数 DexTypeItem list[1]; //DexTypeItem变长数组 };
proto_id_item:
type_list:
proto_it_item:
| index | shortyIdx | returnTypeIdx | parametersOff | shortyIdx_string | returnTypeIdx_string |
| 0 | 0x07 | 0x01 | 0x23C | LLL | Ljava/io/PrintStream; |
| 1 | 0x04 | 0x03 | 0x0 | L | Ljava/lang/String; |
| 2 | 0x06 | 0x04 | 0x244 | LL | Ljava/lang/StringBuilder; |
| 3 | 0x0E | 0x06 | 0x0 | V | V |
| 4 | 0x0F | 0x06 | 0x244 | VL | V |
| 5 | 0x0F | 0x06 | 0x24C | VL | V |
| parametersOff | typeIdx | string |
| 0x23C | 0x03 | Ljava/lang/String; |
| 0x23C | 0x07 | [Ljava/lang/Object; |
| 0x244 | 0x03 | Ljava/lang/String; |
| 0x24C | 0x08 | [Ljava/lang/String; |
4. 字段索引区, 描述dex文件中所有的字段声明, 这个结构中的数据全部都是索引值, 指明了字段所在的类、字段的类型以及字段名称
//Direct-mapped "field_id_item". struct DexFieldId { u2 classIdx; 类的类型, DexTypeId中的索引下标 u2 typeIdx; 字段类型, DexTypeId中的索引下标 u4 nameIdx; 字段名称, DexStringId中的索引下标 };

| index | classIdx | typeIdx | nameIdx | classIdx_string | typeIdx_string | nameIdx_string |
| 0 | 0x05 | 0x01 | 0x15 | Ljava/lang/System; | Ljava/io/PrintStream; | out |
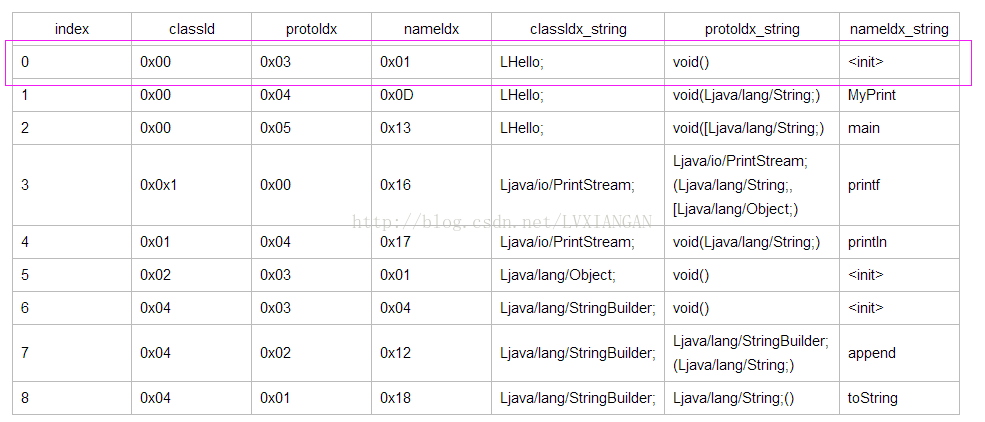
5. 方法索引区, 描述Dex文件中所有的方法, 指明了方法所在的类、方法的声明以及方法名字
//Direct-mapped "method_id_item". struct DexMethodId{ u2 classIdx; 类的类型, DexTypeId中的索引下标 u2 protoIdx; 声明类型, DexProtoId中的索引下标 u4 nameIdx; 方法名, DexStringId中的索引下标 };

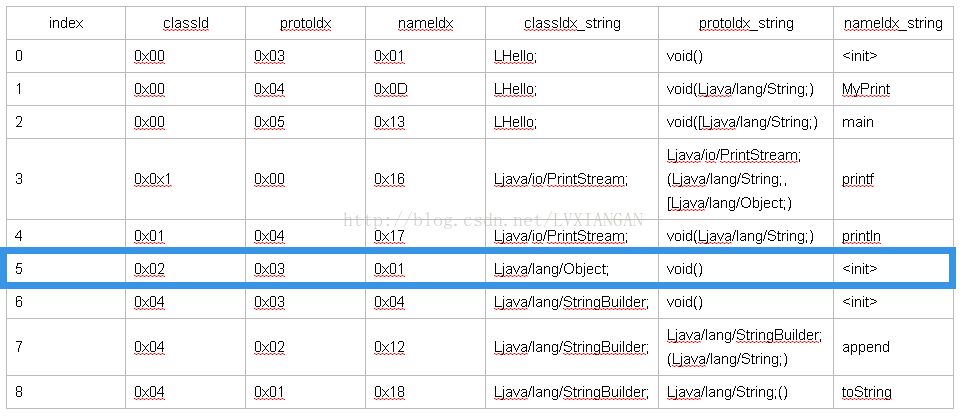
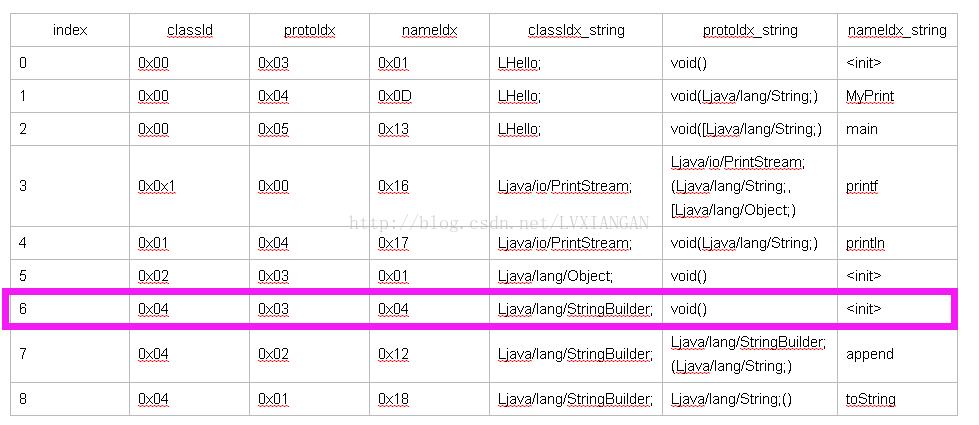
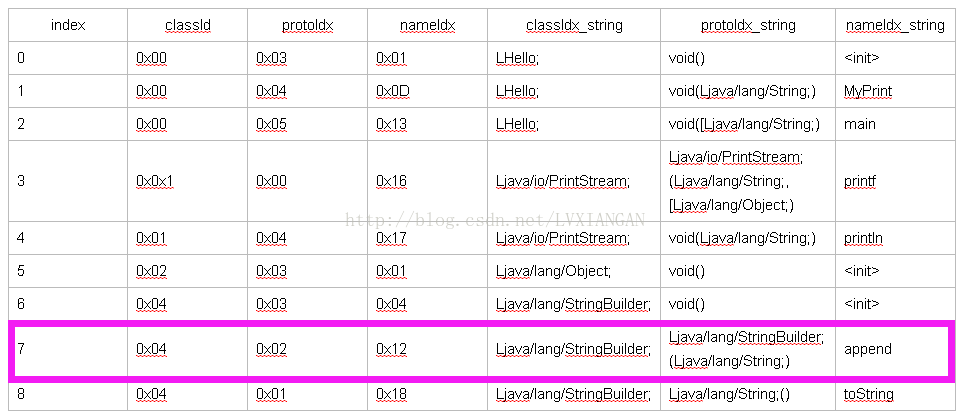
| index | classId | protoIdx | nameIdx | classIdx_string | protoIdx_string | nameIdx_string |
| 0 | 0x00 | 0x03 | 0x01 | LHello; | void() | <init> |
| 1 | 0x00 | 0x04 | 0x0D | LHello; | void(Ljava/lang/String;) | MyPrint |
| 2 | 0x00 | 0x05 | 0x13 | LHello; | void([Ljava/lang/String;) | main |
| 3 | 0x0x1 | 0x00 | 0x16 | Ljava/io/PrintStream; | Ljava/io/PrintStream; (Ljava/lang/String;, [Ljava/lang/Object;) | printf |
| 4 | 0x01 | 0x04 | 0x17 | Ljava/io/PrintStream; | void(Ljava/lang/String;) | println |
| 5 | 0x02 | 0x03 | 0x01 | Ljava/lang/Object; | void() | <init> |
| 6 | 0x04 | 0x03 | 0x04 | Ljava/lang/StringBuilder; | void() | <init> |
| 7 | 0x04 | 0x02 | 0x12 | Ljava/lang/StringBuilder; | Ljava/lang/StringBuilder; (Ljava/lang/String;) | append |
| 8 | 0x04 | 0x01 | 0x18 | Ljava/lang/StringBuilder; | Ljava/lang/String;() | toString |
到此第二块索引区就解析完了, 可以看到解析的步骤非常简单,在解析第三块数据区之前, 补上一个MapList的解析,就是在dex文件头中map_off所指向的位置
这个DexMapList描述Dex文件中可能出现的所有类型, map_list和dex文件头中的有些数据是重复的, 但比dex文件头中要多, 完全是为了检验作用而存在的
//Direct-mapped "map_list". struct DexMapList { u4 size; //DexMapItem的个数 DexMapItem list[1]; //变长数组 };
struct DexMapItem { u2 type; //kDexType开头的类型 u2 unused; //未使用, 用于字节对齐 u4 size; //指定类型的个数 u4 offset; //指定类型数据的文件偏移 };
/* map item type codes */ enum { kDexTypeHeaderItem = 0x0000, kDexTypeStringIdItem = 0x0001, kDexTypeTypeIdItem = 0x0002, kDexTypeProtoIdItem = 0x0003, kDexTypeFieldIdItem = 0x0004, kDexTypeMethodIdItem = 0x0005, kDexTypeClassDefItem = 0x0006, kDexTypeMapList = 0x1000, kDexTypeTypeList = 0x1001, kDexTypeAnnotationSetRefList = 0x1002, kDexTypeAnnotationSetItem = 0x1003, kDexTypeClassDataItem = 0x2000, kDexTypeCodeItem = 0x2001, kDexTypeStringDataItem = 0x2002, kDexTypeDebugInfoItem = 0x2003, kDexTypeAnnotationItem = 0x2004, kDexTypeEncodedArrayItem = 0x2005, kDexTypeAnnotationsDirectoryItem = 0x2006, };
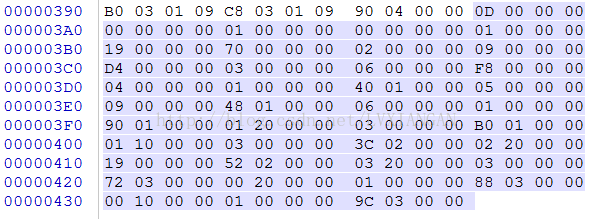
| index | type | unused | size | offset | type_string |
| 0 | 0x00 | 0x00 | 0x01 | 0x00 | kDexTypeHeaderItem |
| 1 | 0x01 | 0x00 | 0x19 | 0x70 | kDexTypeStringIdItem |
| 2 | 0x02 | 0x00 | 0x09 | 0xD4 | kDexTypeTypeIdItem |
| 3 | 0x03 | 0x00 | 0x06 | 0xF8 | kDexTypeProtoIdItem |
| 4 | 0x04 | 0x00 | 0x01 | 0x140 | kDexTypeFieldIdItem |
| 5 | 0x05 | 0x00 | 0x09 | 0x148 | kDexTypeMethodIdItem |
| 6 | 0x06 | 0x00 | 0x01 | 0x190 | kDexTypeClassDefItem |
| 7 | 0x2001 | 0x00 | 0x03 | 0x1B0 | kDexTypeCodeItem |
| 8 | 0x1001 | 0x00 | 0x03 | 0x23C | kDexTypeTypeList |
| 9 | 0x2002 | 0x00 | 0x19 | 0x252 | kDexTypeStringDataItem |
| 10 | 0x2003 | 0x00 | 0x03 | 0x372 | kDexTypeDebugInfoItem |
| 11 | 0x2000 | 0x00 | 0x01 | 0x388 | kDexTypeClassDataItem |
| 12 | 0x1000 | 0x00 | 0x01 | 0x39C | kDexTypeMapList |
可以看到Dex文件头中的项与在DexMapList中存在的项的描述信息(个数和偏移)是一致的
当Android系统加载dex文件时,如果比较文件头类型个数与map里类型不一致时,就会停止使用这个dex文件
第三块: 数据区
索引区中的最终数据偏移以及文件头中描述的map_off偏移都指向数据区, 还包括了即将要解析的class_def_item, 这个结构非常重要,下面就开始解析
class_def_item:
这个结构由dex文件头中的classDefsSize和classDefsOff所指向, 描述Dex文件中所有类定义信息, 每一个DexClassDef中包含一个DexClassData的结构(classDataOff),
每一个DexClassData中包含了一个Class的数据, Class数据中包含了所有的方法, 方法中包含了该方法中的所有指令
//Direct-mapped "class_def_item". struct DexClassDef { u4 classIdx; //类的类型, DexTypeId中的索引下标 u4 accessFlags; //访问标志 u4 superclassIdx; //父类类型, DexTypeId中的索引下标 u4 interfacesOff; //接口偏移, 指向DexTypeList的结构 u4 sourceFileIdx; //源文件名, DexStringId中的索引下标 u4 annotationsOff; //注解偏移, 指向DexAnnotationsDirectoryItem的结构 u4 classDataOff; //类数据偏移, 指向DexClassData的结构 u4 staticValuesOff; //类静态数据偏移, 指向DexEncodedArray的结构 }; struct DexClassData { DexClassDataHeader header; //指定字段与方法的个数 DexField* staticFields; //静态字段 DexField* instanceFields; //实例字段 DexMethod* directMethods; //直接方法 DexMethod* virtualMethods; //虚方法 }; struct DexClassDataHeader { uleb128 staticFieldsSize; //静态字段个数 uleb128 instanceFieldsSize; //实例字段个数 uleb128 directMethodsSize; //直接方法个数 uleb128 virtualMethodsSize; //虚方法个数 }; struct DexMethod { uleb128 methodIdx; //指向DexMethodId的索引 uleb128 accessFlags; //访问标志 uleb128 codeOff; //指向DexCode结构的偏移 }; struct DexCode { u2 registersSize; 使用的寄存器个数 u2 insSize; 参数个数 u2 outsSize; 调用其他方法时使用的寄存器个数 u2 triesSize; Try/Catch个数 u4 debugInfoOff; 指向调试信息的偏移 u4 insnsSize; 指令集个数, 以2字节为单位 u2 insns[1]; 指令集 //followed by optional u2 padding //followed by try_item[triesSize] //followed by uleb128 handlersSize //followed by catch_handler_item[handlersSize] };
class_def_item:

| index | classIdx | accessFlags | superclassIdx | interfacesOff | sourceFileIdx | annotationsOff | classDataOff | staticValuesOff |
| 0 | 0x00 | 0x01 | 0x02 | 0x00 | 0x03 | 0x00 | 0x388 | 0x00 |
| 0_string | LHello; | public | Ljava/lang/Object; | no interfaces | Hello.java | no annotations |

DexClassData的定义在源码的DexClass.h中, 在DexClass.h中的u4类型是uleb128类型, 在DexFile.h中的u4类型是unsigned int
所以这里DexClassDataHeader中的u4其实都是uleb128类型
在程序中,一般使用32位比特位来表示一个整型的数值。不过,一般能够使用到的整数值都不会太大,使用32比特位来表示就有点太浪费了。对于普通计算机来说,这没什么问题,毕竟存储空间那么大。但是,对于移动设备来说,存储空间和内存空间都非常宝贵,不能浪费,能省就省。
每个leb128由1~5字节组成, 所有字节组合在一起表示一个32位的数据, 每个字节只有7位有效, 如果第1个字节的最高位为1, 表示leb128需要使用到第2个字节, 如果第2个字节的最高位为1, 表示需要使用到第3个字节, 以此类推直到最后的字节最高位为0, 当然, leb128最多只会使用到5个字节, 如果读取5个字节后下一个字节最高位仍为1, 则表示该dex无效
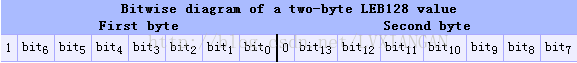
这张图表示了,只使用两个字节进行编码的情况。可以看到,第一个字节的最高位为1,代表还要用到接着的下一个字节。并且,第一个字节存放的是整型值的最低7位。而第二个字节的最高位为0,代表编码到此结束,剩下的7个比特位存放了整型值的高7位数据。
例如uleb128编码的数据: c0 83 92 25
拆分为二进制
11000000 10000011 10010010 00100101
读取第1个字节0xc0(11000000), 其最高位为1, 表示需要继续读取第2个字节 (余下的7位: 1000000)
读取第2个字节0x83(10000011), 其最高位为1, 表示需要继续读取第3个字节 (余下的7位: 0000011)
读取第3个字节0x92(10010010), 其最高位为1, 表示需要继续读取第4个字节 (余下的7位: 0010010)
读取第4个字节0x25(00100101), 其最高位为0, 表示读取结束 (余下的7位: 0100101)
读取结束后, 按照读取的字节顺序将剩余的7位数据从右向左依次拼接起来即可:
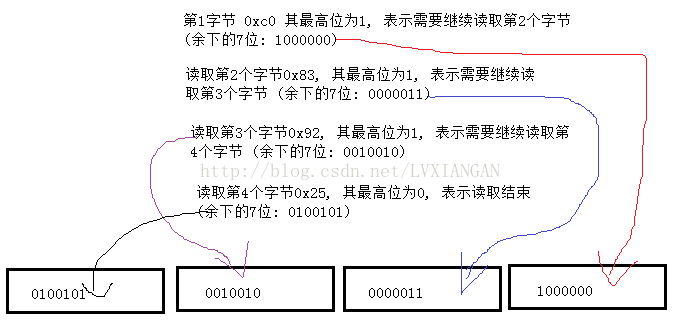
最终拼得二进制数据: 0100101001001000000111000000
将其转换为十六进制数据: 0x4A481C0 即可得到当前uleb128编码的数据所表示的最终32位数据
在dalvik的源码中也有对uleb128数据读取的代码:
DEX_INLINE int readUnsignedLeb128(const u1** pStream) { const u1* ptr = *pStream; int result = *(ptr++); if (result > 0x7f) { int cur = *(ptr++); result = (result & 0x7f) | ((cur & 0x7f) << 7); if (cur > 0x7f) { cur = *(ptr++); result |= (cur & 0x7f) << 14; if (cur > 0x7f) { cur = *(ptr++); result |= (cur & 0x7f) << 21; if (cur > 0x7f) { cur = *(ptr++); result |= cur << 28; } } } } *pStream = ptr; return result; }
| index | staticFieldsSize | instanceFieldsSize | directMethodsSize | virtualMethodsSize |
| 0 | 0 | 0 | 3 | 0 |
DexMethod:

| index | methodIdx | accessFlags | codeOff |
| 0 | 0x0 | 0x10001 | 0x1B0 |
| 0_string | void LHello;-><init>() | public|constructor | |
| 1 | 0x01 | 0x09 | 0x1C8 |
| 1_string | void LHello;->MyPrint(Ljava/lang/String;) | public|static | |
| 2 | 0x01(看010Editor解析此处也是0x01) | 0x09 | 0x210 |
| 2_string | 但是字符串描述也是下表为0x02的信息 | public|static |
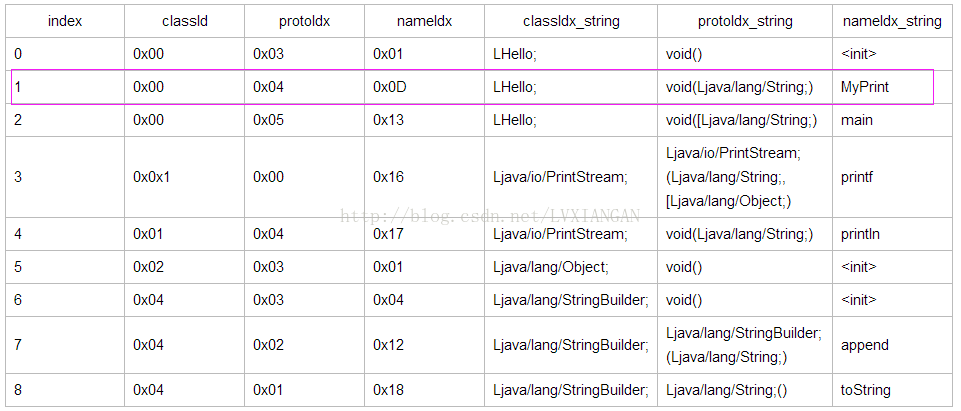
DexMethod表中下标1中成员methonIdx所指向的Method信息:
DexMethod中的codeOff指向的是DexCode的结构,描述了方法更详细的信息以及方法中指令的内容, 在这个结构中会涉及到Dalvik指令格式的解析
可以先了解一下Dalvik指令格式:
http://www.cnblogs.com/dacainiao/p/6035298.html
| DexMethod_index | registersSize | insSize | outsSize | triesSize | debugInfoOff | insnsSize | insns |
| 0 | 0x01 | 0x01 | 0x01 | 0x00 | 0x372 | 0x04 | 0x70, 0x10, 0x05, 0x00, 0x00, 0x00, 0x0E, 0x00 |
| 1 | 0x04 | 0x01 | 0x03 | 0x00 | 0x377 | 0x1C | 0x62, 0x00, 0x00, 0x00, 0x22, 0x01, 0x04, 0x00, 0x70, 0x10, 0x06, 0x00, 0x01, 0x00, 0x6E, 0x20, 0x07, 0x00, 0x31, 0x00, 0x0C, 0x01, 0x1A, 0x02, 0x00, 0x00, 0x6E, 0x20, 0x07, 0x00, 0x21, 0x00, 0x0C, 0x01, 0x6E, 0x10, 0x08, 0x00, 0x01, 0x00, 0x0C, 0x01, 0x12, 0x02, 0x23, 0x22, 0x07, 0x00, 0x6E, 0x30, 0x03, 0x00, 0x10, 0x02, 0x0E, 0x00 |
| 2 | 0x03 | 0x01 | 0x02 | 0x00 | 0x380 | 0x0D | 0x1A, 0x00, 0x14, 0x00, 0x71, 0x10, 0x01, 0x00, 0x00, 0x00, 0x62, 0x00, 0x00, 0x00, 0x1A, 0x01, 0x02, 0x00, 0x6E, 0x20, 0x04, 0x00, 0x10, 0x00, 0x0E, 0x00 |
第一个方法 DexMethod_index: 0, void LHello;-><init>()
其指令集为: 0x70, 0x10, 0x05, 0x00, 0x00, 0x00, 0x0E, 0x00
根据Dalvik指令格式介绍, 每16位的字采用空格分隔开来, 每个字母表示四位, 每条指令的参数从指令第一部分开始,op位于低8位,高8位可以是一个8位的 参数,也可以是两个4位的参数,还可以为空,如果指令超过16位,则后面部分 依次作为参数
所以上述指令格式可以划分为: 0x70, 0x10 | 0x05, 0x00 | 0x00, 0x00 | 0x0E, 0x00
指令集格式采用小尾方式, 第一部分的低8位是 0x70 (op)
拿到op位后,查看Dalvik的官方文档, 在dalvik\docs目录下 dalvik-bytecode.html 和 instruction-formats.html
查看dalvik-bytecode.html 对于0x70的定义

可以看到0x70表示为 invoke-direct, 而指令的格式编码为35c
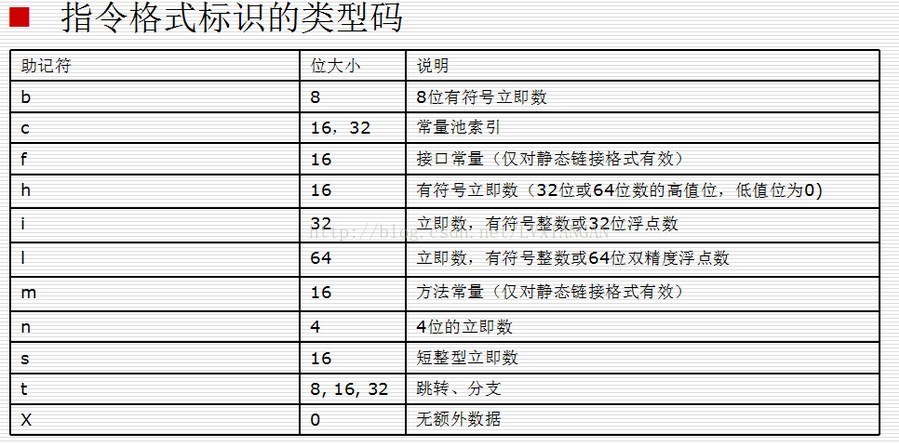
单独使用位标识还无法确定一条指令,必须通过指令格式标识来指定指令的格式编码。 它的约定如下:指令格式标识大多由三个字符组成,前两个是数字,最后一个是字母第一个数字是表示指令有多少个16位的字组成第二个数字是表示指令最多使用寄存器的个数。特殊标记“r”标识使用一定范围内的寄存器第三个字母为类型码,表示指令用到的额外数据的类型
所以当前的指令格式编码为35c表示
该条指令占用了3个16位
该条指令最多使用5个寄存器
该条指令有常量池索引
既然占用了3个16位,所以先将该条指令的3个16位拷贝过来
0x70, 0x10 | 0x05, 0x00 | 0x00, 0x00
查看instruction-formats.html对于类型码35c的定义

由于每个字母占用4位, 所以按照类型码35c的格式编码解析当前指令为
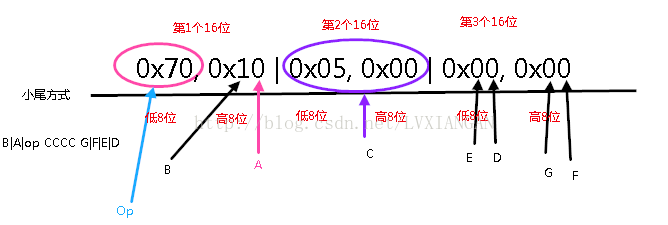
B = 1, A = 0, C = 5, D = 0, E = 0, F = 0, G = 0
可以看到后面[B = 1]对应的是 [B=1] op {vD}, kind@CCCC
由于D = 0, 所以 {vD) == {v0}

C = 5, 在dalvik-bytecode.html 中对于0x70定义处有提到, C是方法列表的下标,占16位
所以kind@cccc == void Ljava/lang/Object-->init()
最终该条指令解析为:
invoke-direct {v0}, Ljava/lang/Object-><init>V
然后继续解析剩下的指令: 0x0E, 0x00
还是一样的方法:
0x0E为低8位,所以为op位,查看dalvik-bytecode.html 关于0x0E的定义

指令的格式编码为10x, 表示
该条指令占用了1个16位
该条指令最多使用0个寄存器
该条指令无额外数据
最终该条指令解析为:
return-void
所以,第一个方法,DexMethod_index: 0, void LHello;-><init>(),的方法实现为:
invoke-direct {v0}, Ljava/lang/Object-><init>V
return-void
对照反编译工具的结果:

第二个方法 DexMethod_index: 1, void LHello;->MyPrint(Ljava/lang/String;)
其指令集为: 0x62, 0x00, 0x00, 0x00, 0x22, 0x01, 0x04, 0x00, 0x70, 0x10, 0x06, 0x00, 0x01, 0x00, 0x6E, 0x20, 0x07, 0x00, 0x31, 0x00, 0x0C, 0x01, 0x1A, 0x02, 0x00, 0x00, 0x6E, 0x20, 0x07, 0x00, 0x21, 0x00, 0x0C, 0x01, 0x6E, 0x10, 0x08, 0x00, 0x01, 0x00, 0x0C, 0x01, 0x12, 0x02, 0x23, 0x22, 0x07, 0x00, 0x6E, 0x30, 0x03, 0x00, 0x10, 0x02, 0x0E, 0x00
这里就不再赘述了, 都是按照上面的方法来解析的
0x62为op,62: sget-object 格式编码为 21c
2个16位(0x62, 0x00, 0x00, 0x00),最多1个寄存器, 常量表索引

a = 0, b = 0, B: static field reference index (16 bits)
b是field中的下标

最终解释为:
sget-object v0, Ljava/lang/System;.out:Ljava/io/PrintStream;
紧接着0x22为op, 22: new-instance vAA, type@BBBB, 格式编码为 21c
2个16位(0x22, 0x01, 0x04, 0x00),最多1个寄存器, 常量表索引

a = 1, b = 4
A: destination register (8 bits)
B: type index

最终解释为:
new-instance v1, Ljava/lang/StringBuilder;
紧接着0x70为op, 70: invoke-direct 格式编码为 35c
3个16位(0x70, 0x10, 0x06, 0x00, 0x01, 0x00), 最多5个寄存器,常量池索引

b = 1, a = 0, c = 6, f = 0, g = 0, e = 0, d =1
C: method index (16 bits)
[B=1] op {vD}, kind@CCCC
最终解析为:
invoke-direct {v1}, Ljava/lang/StringBuilder-><init>V
紧接着0x6E为op, 6e: invoke-virtual 格式编码为 35c
3个16位(0x6E, 0x20, 0x07, 0x00, 0x31, 0x00), 最多5个寄存器,常量池索引

b = 2, a = 0, c = 7, g = 0, f = 0, e = 3, d = 1
[B=2] op {vD, vE}, kind@CCCC
最终解析为:
invoke-virtual {v1, v3} Ljava/lang/StringBuilder->append( Ljava/lang/String;)Ljava/lang/StringBuilder
紧接着0c为op, 0c: move-result-object vAA 格式编码为11x
1个16位(0x0C, 0x01), 最多1个寄存器, 无额外数据

b = 0, a = 1
如果参数采用“+X”的方式表示,表明它是一个相对指令的地址偏移
最终解析为:
move-result-object v1
紧接着1a为op, 1a: const-string vAA, string@BBBB 格式编码为21c
2个16位(0x1A, 0x02, 0x00, 0x00),最多1个寄存器,常量池索引
a = 2, b = 0
A: destination register (8 bits)
B: string index
最终解析为:
const-string v2, "\r\n"
紧接着0x6E为op, 6e: invoke-virtual 格式编码为 35c
3个16位(0x6E, 0x20, 0x07, 0x00, 0x21, 0x00), 最多5个寄存器,常量池索引

b = 2, a = 0, c = 7, g = 0, f = 0, e = 2, d = 1
[B=2] op {vD, vE}, kind@CCCC
最终解析为:
invoke-virtual {v1, v2} Ljava/lang/StringBuilder->append( Ljava/lang/String;)Ljava/lang/StringBuilder
Dalvik指令解析方法大致就是这样,后面以此类推就可以,就不再继续解析了,解析这玩意太累。。。。
解析完dex之后我们有很多事都可以做了我们可以检测一个apk中是否包含了指定系统的api(当然这些api没有被混淆),同样也可以检测这个apk是否包含了广告,以前我们可以通过解析AndroidManifest.xml文件中的service,activity,receiver,meta等信息来判断,因为现在的广告sdk都需要添加这些东西,如果我们可以解析dex的话,那么我们可以得到他的所有字符串内容,就是string_ids池,这样就可以判断调用了哪些api。那么就可以判断这个apk的一些行为了,当然这里还有一个问题,假如dex加密了我们就蛋疼了。好吧,那就牵涉出第二件事了。我们在之前说过如何对apk进行加固,其实就是加密apk/dex文件内容,那么这时候我们必须要了解dex的文件结构信息,因为我们先加密dex,然后在动态加载dex进行解密即可我们可以更好的逆向工作,其实说到这里,我们看看apktool源码也知道,他内部的反编译原理就是这些,只是他会将指令翻译成smail代码,这个网上是有相对应的jar包api的,所以我们知道了dex的数据结构,那么原理肯定就知道了,同样还有一个dex2jar工具原理也是类似的.














 6410
6410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









