







 Android Dex 文件解析文章目录Android Dex 文件解析前言基本数据类型LEB128 类型uleb128leb128uleb128p1Dex 文件结构图Dex 结构说明hedaer_itemstring_idstype_idsproto_idsfield_idsmethod_idsclass_defscall_site_idsmap_listtype_listclass_data_itemcode_itemdebug_info_itemDex 文件解析构建 Dex 文件执行 Dex 文件解
Android Dex 文件解析文章目录Android Dex 文件解析前言基本数据类型LEB128 类型uleb128leb128uleb128p1Dex 文件结构图Dex 结构说明hedaer_itemstring_idstype_idsproto_idsfield_idsmethod_idsclass_defscall_site_idsmap_listtype_listclass_data_itemcode_itemdebug_info_itemDex 文件解析构建 Dex 文件执行 Dex 文件解
Android Dex 文件解析
前言
Java 代码文件在经过 javac 编译器编译后会产出 .class 格式的 Java 虚拟机可执行的字节码文件,而 Dex 文件则是 Android SDK 编译 Java 代码后的产物(Android SDK 使用 dx 或 d8 编译器将 .class 文件编译为 .dex 文件),了解 Dex 文件结构是理解 Android 虚拟机原理的基础,同时也是学习 Android 逆向工程的基础。
Dex 文件的文件后缀为 .dex,是 Android 虚拟机的可执行文件。
基本数据类型
首先说明组成 Dex 文件结构中的基本类型,包含原生类型和 uleb128 类型:
| 名称 | 说明 |
|---|---|
| byte | 8 位有符号整数 |
| ubyte | 8 位无符号整数 |
| short | 16 位有符号整数,小端字节序 |
| ushort | 16 位无符号整数,小端字节序 |
| int | 32 位有符号整数,小端字节序 |
| uint | 32 位无符号整数,小端字节序 |
| long | 64 位有符号整数,小端字节序 |
| ulong | 64 位无符号整数,小端字节序 |
| sleb128 | 有符号 LEB128,可变长度 |
| uleb128 | 无符号 LEB128,可变长度 |
| uleb128p1 | 无符号 LEB128 + 1,可变长度 |
在系统源码 DexFile.h 的对应类型别名定义如下:
// DexFile.h
typedef uint8_t u1;
typedef uint16_t u2;
typedef uint32_t u4;
typedef uint64_t u8;
typedef int8_t s1;
typedef int16_t s2;
typedef int32_t s4;
typedef int64_t s8;
LEB128 类型
LEB128 类型是 Dex 文件中的基础类型之一,该类型格式借鉴了 DWARF3 规范。在 Dex 文件中,LEB128 仅用于对 32 位数字进行编码。
LEB128 全称为“Little-Endian Base 128“,表示任意有符号或无符号整数的可变长度编码。
每个 LEB128 编码值由 1-5 个字节组成,共同表示一个 32 位的值,设计 LEB128 的目的是为了节省内存。
表示方法是:每个字节的首位为标志位,为 0 说明这个字节是 LEB128 类型的最后一个字节,为 1 则表示后面还有若干字节,然后将每个字节去除标志位后的 7 位组合成一个 32 数字。
uleb128
对于无符号的 uleb128 类型,使用两个字节表示十进制数字 4176 的示例如下:
1 1 0 1 0 0 0 0 0 0 1 0 0 0 0 0
去除标志位后:
1 0 1 0 0 0 0 0 1 0 0 0 0 0
^ ^
去除 去除
组合后使用便于阅读的大端格式表示为:
0 0 0 1 0 0 0 0 0 1 0 1 0 0 0 0
^ ^
补充 0
1000001010000 转化为十进制的值为 4176。
leb128
对于有符号的 leb128 类型,最后一个字节的除了标志位的最高位将为符号位,将进行符号扩展。
例如下面使用两个字节的 leb128 表示有符号数:
1 1 0 1 0 0 0 0 0 1 1 0 0 0 0 0
^
将进行符号扩展
去除标志位后:
1 0 1 0 0 0 0 1 1 0 0 0 0 0
^ ^
去除 去除
组合后使用便于阅读的大端格式表示为:
0 0 1 1 0 0 0 0 0 1 0 1 0 0 0 0
^ ^
补充 0
由于符号位为 1,说明表示负数,则使用补码计算:
首先求反码:
0 0 0 0 1 1 1 1 1 0 1 0 1 1 1 1
然后 +1 ->
0 0 0 0 1 1 1 1 1 0 1 1 0 0 0 0
111110110000 的十进制结果为 4016,添加负号为 -4016。
uleb128p1
uleb128p1 用于表示一个有符号值,它的编码方法为 uleb128 的值加 1,那么解码时首先以 uleb128 格式解析值,然后减去 1,主要是为了表示 -1 这个常用数而节省空间,原本使用 sleb128 需要 2 个字节才能表示 -1(11111111 01111111),现在一个字节就可以表示了(00000000)。
LEB128 类型的一些典型值:
| Binary | Hex | sleb128 | uleb128 | uleb128p1 |
|---|---|---|---|---|
| 00000000 00000000 | 00 | 0 | 0 | -1 |
| 00000000 00000001 | 01 | 1 | 1 | 0 |
| 00000000 01111111 | 7f | -1 | 127 | 126 |
| 10000000 01111111 | 80 7f | -128 | 16256 | 16255 |
Dex 文件结构图
Dex 文件的总体结构图:
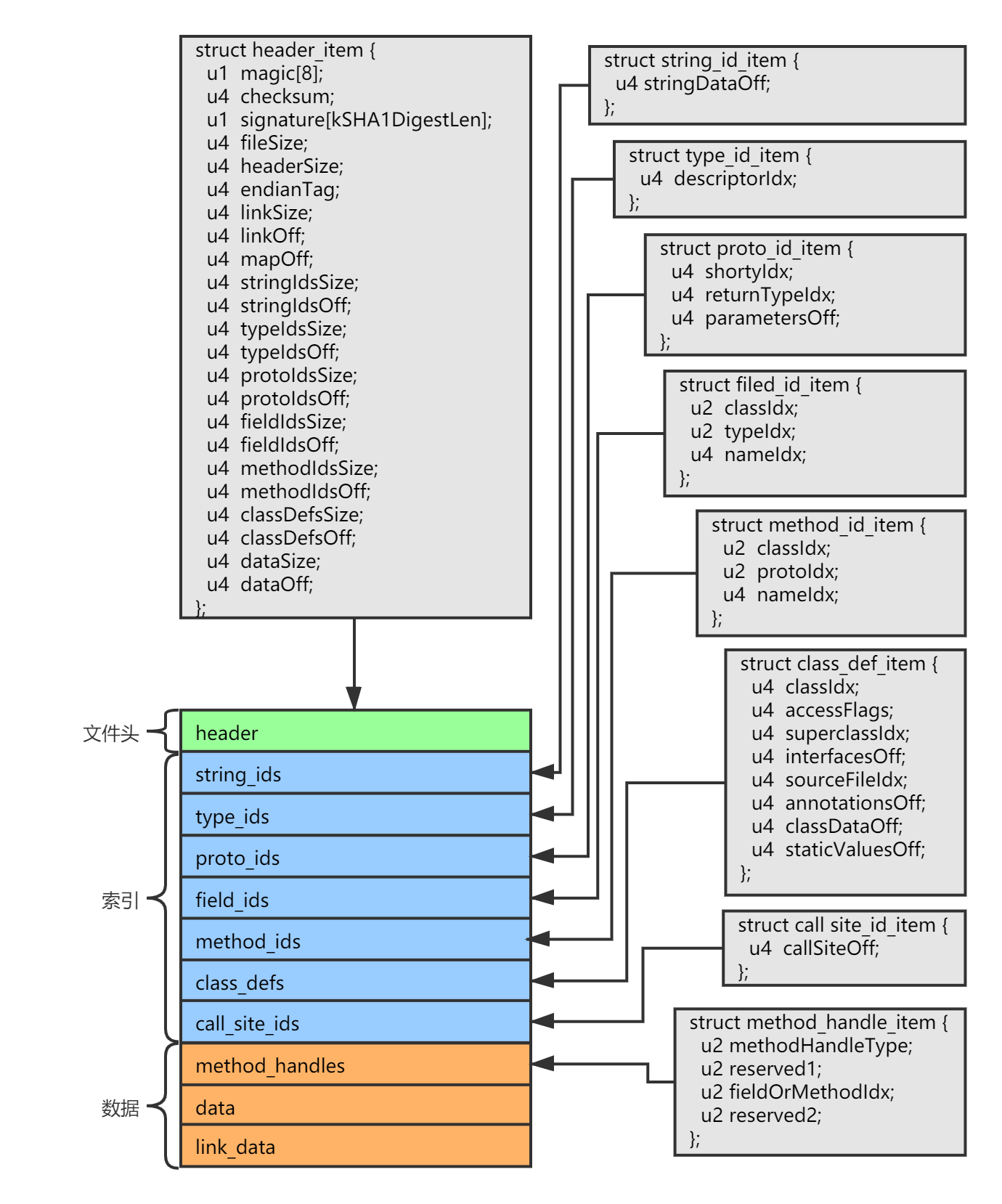
Dex 结构说明
下面对于 Dex 的详细结构进行说明(下面的参考了 Android 9.0.0_r3 系统源码中的 dalvik/libdex/DexFile.h 头文件)。
hedaer_item
首先 Dex 文件的头部具有一个 hedaer_item 结构,它存放了整个 Dex 文件的元信息,描述了一个 Dex 文件的概要结构。
下面是它的结构定义:
struct hedaer_item {
/* 魔数 */
u1 magic[8];
/*
文件剩余内容(除 magic 和此字段之外的所有内容)的 adler32 校验和;
用于检测文件损坏情况。
*/
u4 checksum;
/*
文件剩余内容(除 magic、checksum 和此字段之外的所有内容)的 SHA-1 签名(哈希);
用于对文件进行唯一标识。
*/
u1 signature[20];
/* 整个文件(包括标头)的大小,以字节为单位 */
u4 file_size;
/*
标头(整个区段)的大小,以字节为单位。这一项允许至少一定程度的向后/向前兼容性,
而不必让格式失效。
*/
u4 header_size;
/* 字节序标记 */
u4 endian_tag;
/* 链接区段的大小;如果此文件未进行静态链接,则该值为 0 */
u4 link_size;
/*
从文件开头到链接区段的偏移量;如果 link_size == 0,则该值为 0。
该偏移量(如果为非零值)应该是到 link_data 区段的偏移量。
*/
u4 link_off;
/* 从文件开头到映射项的偏移量。该偏移量(必须为非零)应该是到 data 区段的偏移量 */
u4 map_off;
/* 字符串标识符列表中的字符串数量 */
u4 string_ids_size;
/*
从文件开头到字符串标识符列表的偏移量;如果 string_ids_size == 0(极端情况),
则该值为 0。该偏移量(如果为非零值)应该是到 string_ids 区段开头的偏移量。
*/
u4 string_ids_off;
/* 类型标识符列表中的元素数量,最多为 65535 */
u4 type_ids_size;
/*
从文件开头到类型标识符列表的偏移量;如果 type_ids_size == 0(极端情况),
则该值为 0。该偏移量(如果为非零值)应该是到 type_ids 区段开头的偏移量。
*/
u4 type_ids_off;
/* 原型标识符列表中的元素数量,最多为 65535 */
u4 proto_ids_size;
/*
从文件开头到原型标识符列表的偏移量;如果 proto_ids_size == 0(极端情况),
则该值为 0。该偏移量(如果为非零值)应该是到 proto_ids 区段开头的偏移量。
*/
u4 proto_ids_off;
/* 字段标识符列表中的元素数量 */
u4 field_ids_size;
/*
从文件开头到字段标识符列表的偏移量;如果 field_ids_size == 0,则该值为 0。
该偏移量(如果为非零值)应该是到 field_ids 区段开头的偏移量。
*/
u4 field_ids_off;
/* 方法标识符列表中的元素数量 */
u4 method_ids_size;
/*
从文件开头到方法标识符列表的偏移量;如果 method_ids_size == 0,则该值为 0。
该偏移量(如果为非零值)应该是到 method_ids 区段开头的偏移量
*/
u4 method_ids_off;
/* 类定义列表中的元素数量 */
u4 class_defs_size;
/*
从文件开头到类定义列表的偏移量;如果 class_defs_size == 0(极端情况),
则该值为 0。该偏移量(如果为非零值)应该是到 class_defs 区段开头的偏移量。
*/
u4 class_defs_off;
/* data 区段的大小(以字节为单位)。该数值必须是 sizeof(uint) 的偶数倍 */
u4 data_size;
/* 从文件开头到 data 区段开头的偏移量 */
u4 data_off;
};
和所有文件格式标准一样(使用魔数标识文件类型),Dex 文件的前 8 个字节 magic 字段是魔数,表示 Dex 这种文件类型,它的值是 dex 字符串和文件格式版本号的组合,例如 dex\n039\0,其中版本号用于为系统识别解析不同版本格式的 Dex 文件提供支持,不同版本的 Dex 文件可能具有结构差异,新版本可能支持更多指令。039 版本的格式在 Android 9.0 中被增加。
从前面的结构图中可以知道,Dex 文件大致分为 3 块区域,文件头、索引区域以及数据区域。其中索引区域用于描述 Dex 几个关键子结构的分布,包含指向子结构的地址偏移的列表,数据区用于存放具体的信息,是索引区域所指向的目标区域,包含每个类的详细信息以及类成员和类方法的信息,以及每个方法的完整字节码指令等。
如果要对一个 Dex 文件进行解析,那么可以按照从上至下的方式,由文件概要信息自然的解析到具体数据结构。
索引区内容,包含 string_ids、type_ids、proto_ids、field_ids、method_ids、class_defs、call_site_ids 一共 7 个 Dex 核心结构,上面 header_item 结构的已经包含了每个结构的相关信息,每个结构都是一个数组,在 header_item 的描述中都具有一个 size 属性表示数组成员数量,和一个 off 表示在文件中的偏移值。
下面介绍索引区结构的详细结构。
string_ids
string_ids 是字符串池,保存 Dex 文件中所用到的所有字符串,其他结构中如果包含字符串类型的变量,将会提供对应字符串在字符串池中的索引。
string_ids 是数组结构,每个数组成员为一个 string_id_item,它存放了每个字符串在 data 结构中的偏移地址。
struct string_id_item {
/*
从文件开头到此项的字符串数据的偏移量。该偏移量应该是到 data 区段中某个位置的
偏移量。
*/
u4 string_data_off;
};
string_id_item 的偏移指向一个表示字符串的结构,为 string_data_item,它包含字符串的长度和具体内容,长度使用 uleb128 类型存储:
struct string_data_item
{
/*
此字符串的大小;以 UTF-16 代码单元(在许多系统中为“字符串长度”)为单位。
也就是说,这是该字符串的解码长度(编码长度隐含在 0 字节的位置)。
*/
uleb128 utf16_size;
/*
一系列 MUTF-8 代码单元(又称八位字节),后跟一个值为 0 的字节。
*/
u1* data;
}
type_ids
type_ids 是类型标识符信息,包含了代码中使用到的所有 Java 类型以及原始类型。
type_ids 是数组结构,每个数组成员为一个 type_id_item 结构,它存放了类型所对应名字的字符串的在字符串池中的索引。
struct type_id_item
{
/*
此类描述符字符串的 string_ids 列表中的索引。该字符串必须符合上文定义的
TypeDescriptor 的语法。
*/
u4 descriptor_idx;
};
proto_ids
proto_ids 是方法原型标识符信息,存放方法返回值和参数的类型标识符信息。
proto_ids 是数组结构,每个数组成员为一个 proto_id_item,它存放了方法返回类型标识符字符串在字符串池中的索引,以及参数、返回类型在 type_ids 中的索引。
struct proto_id_item
{
/*
此原型的简短式描述符字符串的 string_ids 列表中的索引。该字符串必须符合上文定义
的 ShortyDescriptor 的语法,而且必须与该项的返回类型和参数相对应。
*/
u4 shorty_ids;
/* 此原型的返回类型的 type_ids 列表中的索引 */
u4 return_type_idx;
/*
从文件开头到此原型的参数类型列表的偏移量;如果此原型没有参数,则该值为 0。
该偏移量(如果为非零值)应该位于 data 区段中,且其中的数据应采用下文中
“"type_list"”指定的格式。此外,不得对列表中的类型 void 进行任何引用。
*/
u4 parameters_off;
};
field_ids
field_ids 是类成员变量标识符信息,存放所有类成员类型标识符信息。
field_ids 是数组结构,每个数组成员为一个 field_id_item,它存放了成员变量所属类型的信息,和成员变量本身的类型信息:
struct field_id_item
{
/*
此字段的定义符的 type_ids 列表中的索引。此项必须是“类”类型,而不能是“数组”或
“基元”类型。
*/
u2 class_idx;
/* 此字段的类型的 type_ids 列表中的索引 */
u2 type_idx;
/*
此字段的名称的 string_ids 列表中的索引。该字符串必须符合上文定义的 MemberName
的语法。
*/
u4 name_idx;
};
method_ids
method_ids 是类方法标识符信息,存放所有类方法的类型标识符信息。
method_ids 是数组结构,每个数组成员为一个 method_id_item,它存放了方法所属类型的信息,和方法本身的类型信息:
struct method_id_item
{
/*
此方法的定义符的 type_ids 列表中的索引。此项必须是“类”或“数组”类型,而不能是
“基元”类型。
*/
u2 class_idx;
/* 此方法的原型的 proto_ids 列表中的索引 */
u2 proto_idx;
/*
此方法名称的 string_ids 列表中的索引。该字符串必须符合上文定义的 MemberName
的语法。
*/
u4 name_idx;
};
class_defs
class_defs 是类定义信息,存放了所有类的定义信息。
class_defs 是数组结构,每个数组成员为一个 class_def_item,包含这个类定义所需要的全部信息。
struct class_def_item
{
/*
此类的 type_ids 列表中的索引。此项必须是“类”类型,而不能是“数组”或“基元”类型。
*/
u4 class_idx;
/*
类的访问标记(public、final 等)。有关详情,请参阅“access_flags 定义”。
*/
u4 access_flag;
/*
超类的 type_ids 列表中的索引。如果此类没有超类(即它是根类,例如 Object),
则该值为常量值 NO_INDEX。如果此类存在超类,则此项必须是“类”类型,而不能是
“数组”或“基元”类型。
*/
u4 superclass_idx;
/*
从文件开头到接口列表的偏移量;如果没有接口,则该值为 0。该偏移量应该位于 data
区段,且其中的数据应采用下文中“type_list”指定的格式。该列表的每个元素都必须是
“类”类型(而不能是“数组”或“基元”类型),并且不得包含任何重复项。
*/
u4 interfaces_off;
/*
文件(包含这个类(至少大部分)的原始来源)名称的 string_ids 列表中的索引;
或者该值为特殊值 NO_INDEX,以表示缺少这种信息。任何指定方法的 debug_info_item
都可以覆盖此源文件,但预期情况是大多数类只能来自一个源文件。
*/
u4 source_file_idx;
/*
从文件开头到此类的注释结构的偏移量;如果此类没有注释,则该值为 0。该偏移量
(如果为非零值)应该位于 data 区段,且其中的数据应采用下文中
“annotations_directory_item”指定的格式,同时所有项将此类作为定义符进行引用。
*/
u4 annotations_off;
/*
从文件开头到此项的关联类数据的偏移量;如果此类没有类数据,则该值为 0(这种情况
有可能出现,例如,如果此类是标记接口)。该偏移量(如果为非零值)应该位于 data
区段,且其中的数据应采用下文中“class_data_item”指定的格式,同时所有项将此类作
为定义符进行引用。
*/
u4 class_data_off;
/*
从文件开头到 static 字段的初始值列表的偏移量;如果没有该列表(并且所有 static
字段都将使用 0 或 null 进行初始化),则该值为 0。该偏移量应该位于 data 区段,
且其中的数据应采用下文中“encoded_array_item”指定的格式。该数组的大小不得超出
此类所声明的 static 字段的数量,且 static 字段所对应的元素应采用相对应的
field_list 中所声明的顺序每个数组元素的类型均必须与其相应字段的声明类型相匹配。
如果该数组中的元素比 static 字段中的少,则剩余字段将使用适当类型 0 或 null
进行初始化。
*/
u4 static_values_off;
};
其中 access_flags 为访问标识符,可选值如下:
enum {
ACC_PUBLIC = 0x00000001, // class, field, method, ic
ACC_PRIVATE = 0x00000002, // field, method, ic
ACC_PROTECTED = 0x00000004, // field, method, ic
ACC_STATIC = 0x00000008, // field, method, ic
ACC_FINAL = 0x00000010, // class, field, method, ic
ACC_SYNCHRONIZED= 0x00000020, // method (only allowed on natives)
ACC_SUPER = 0x00000020, // class (not used in Dalvik)
ACC_VOLATILE = 0x00000040, // field
ACC_BRIDGE = 0x00000040, // method (1.5)
ACC_TRANSIENT = 0x00000080, // field
ACC_VARARGS = 0x00000080, // method (1.5)
ACC_NATIVE = 0x00000100, // method
ACC_INTERFACE = 0x00000200, // class, ic
ACC_ABSTRACT = 0x00000400, // class, method, ic
ACC_STRICT = 0x00000800, // method
ACC_SYNTHETIC = 0x00001000, // field, method, ic
ACC_ANNOTATION = 0x00002000, // class, ic (1.5)
ACC_ENUM = 0x00004000, // class, field, ic (1.5)
ACC_CONSTRUCTOR = 0x00010000, // method (Dalvik only)
ACC_DECLARED_SYNCHRONIZED = 0x00020000, // method (Dalvik only)
ACC_CLASS_MASK =
(ACC_PUBLIC | ACC_FINAL | ACC_INTERFACE | ACC_ABSTRACT
| ACC_SYNTHETIC | ACC_ANNOTATION | ACC_ENUM),
ACC_INNER_CLASS_MASK =
(ACC_CLASS_MASK | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC),
ACC_FIELD_MASK =
(ACC_PUBLIC | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC | ACC_FINAL
| ACC_VOLATILE | ACC_TRANSIENT | ACC_SYNTHETIC | ACC_ENUM),
ACC_METHOD_MASK =
(ACC_PUBLIC | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC | ACC_FINAL
| ACC_SYNCHRONIZED | ACC_BRIDGE | ACC_VARARGS | ACC_NATIVE
| ACC_ABSTRACT | ACC_STRICT | ACC_SYNTHETIC | ACC_CONSTRUCTOR
| ACC_DECLARED_SYNCHRONIZED),
};
call_site_ids
call_site_ids 存放的是调用站点标识符信息,它是和 Java 中的提供的 MethodHandler 相关的信息。
call_site_ids 是数组结构,每个数组成员为一个 call_site_id_item。
struct call_site_id_item
{
/*
从文件开头到调用点定义的偏移量。该偏移量应位于数据区段中,且其中的数据应采用下
文中“call_site_item”指定的格式。
*/
u4 call_site_off;
};
call_site_item 是一个 encoded_array_item 结构,具体内容,可参考官方介绍,这里不对它进行重点关注。
到这里就介绍完了索引区的基本内容。
然后现在回到 header_item 中,看第 9 个 map_off 字段,它指向一个 map_list 结构,map_list 存放了 Dex 文件所有的结构描述,同时也包含 header_item 区域和索引区结构,下面看一下它的具体内容。
map_list
map_list 结构定义如下:
struct map_list
{
u4 size; // 列表的大小(以条目数表示)。
map_item* list; // 列表的元素。
};
有大小和数组成员,在解析时首先读取数组元素的大小,再根据大小解析指定数量的 map_item 数组成员结构。
map_item 结构定义如下:
struct map_item
{
u2 type; // 项的类型。
u2 unused; // 未使用。
u4 size; // 在指定偏移量处找到的项数量。
u4 offset; // 从文件开头到相关项的偏移量。
};
根据 type 的值来可确认其说明的对应结构:
enum
{
TYPE_HEADER_ITEM = 0x0000, // header_item
TYPE_STRING_ID_ITEM = 0x0001, // string_id_item
TYPE_TYPE_ID_ITEM = 0x0002, // type_id_item
TYPE_PROTO_ID_ITEM = 0x0003, // proto_id_item
TYPE_FIELD_ID_ITEM = 0x0004, // field_id_item
TYPE_METHOD_ID_ITEM = 0x0005, // method_id_item
TYPE_CLASS_DEF_ITEM = 0x0006, // class_def_item
TYPE_CALL_SITE_ID_ITEM = 0x0007, // call_site_id_item
TYPE_METHOD_HANDLE_ITEM = 0x0008, // method_handle_item
TYPE_MAP_LIST = 0x1000, // map_list
TYPE_TYPE_LIST = 0x1001, // type_list
TYPE_ANNOTATION_SET_REF_LIST = 0x1002, // annotation_set_ref_list
TYPE_ANNOTATION_SET_ITEM = 0x1003, // annotation_set_item
TYPE_CLASS_DATA_ITEM = 0x2000, // class_data_item
TYPE_CODE_ITEM = 0x2001, // code_item
TYPE_STRING_DATA_ITEM = 0x2002, // string_data_item
TYPE_DEBUG_INFO_ITEM = 0x2003, // debug_info_item
TYPE_ANNOTATION_ITEM = 0x2004, // annotation_item
TYPE_ENCODED_ARRAY_ITEM = 0x2005, // encoded_array_item
TYPE_ANNOTATIONS_DIRECTORY_ITEM = 0x2006, // annotations_directory_item
};
通过遍历 map_list 即可得到每个结构的偏移地址和结构中项的数量,从而对整个 Dex 文件进行解析。
下面看一下除了索引区结构的其他结构。
type_list
type_list 是类型列表,结构如下:
struct type_list
{
u4 size; // 列表的大小(以条目数表示)
type_item *list; // 列表的元素。
};
每个列表成员为 type_item,包含 type_ids 数组的索引:
struct type_item
{
u2 type_idx; // type_ids 列表中的索引。
};
class_data_item
class_data_item 表示类的信息,包含类成员和类方法的信息。
struct class_data_item
{
uleb128 static_fields_size; // 此项中定义的静态字段的数量。
uleb128 instance_fields_size; // 此项中定义的实例字段的数量。
uleb128 direct_methods_size; // 此项中定义的直接方法的数量。
uleb128 virtual_methods_size; // 此项中定义的虚拟方法的数量。
/*
定义的静态字段;以一系列编码元素的形式表示。这些字段必须按 field_idx 以升序进行排序。
*/
encoded_field* static_fields;
/*
定义的实例字段;以一系列编码元素的形式表示。这些字段必须按 field_idx 以升序进行排序。
*/
encoded_field* instance_fields;
/*
定义的直接(static、private 或构造函数的任何一个)方法;以一系列编码元素的形式
表示。这些方法必须按 method_idx 以升序进行排序。
*/
encoded_method* direct_methods;
/*
定义的虚拟(非 static、private 或构造函数)方法;以一系列编码元素的形式表示。
此列表不得包括继承方法,除非被此项所表示的类覆盖。这些方法必须按 method_idx 以
升序进行排序。虚拟方法的 method_idx 不得与任何直接方法相同。
*/
encoded_method* virtual_methods;
};
描述类成员和类方法的子结构:
struct encoded_field
{
/*
此字段标识(包括名称和描述符)的 field_ids 列表中的索引;
它会表示为与列表中前一个元素的索引之间的差值。列表中第一个元素的索引则直接表示出来。
*/
uleb128 field_idx_diff;
/*
字段的访问标记(public、final 等)。
*/
uleb128 access_flags;
};
struct encoded_method
{
/*
此方法标识(包括名称和描述符)的 method_ids 列表中的索引;
它会表示为与列表中前一个元素的索引之间的差值。列表中第一个元素的索引则直接表示出来。
*/
uleb128 method_idx_diff;
/*
方法的访问标记(public、final 等)。
*/
uleb128 access_flags;
/*
从文件开头到此方法代码结构的偏移量;如果此方法是 abstract 或 native,则该值为 0。
该偏移量应该是到 data 区段中某个位置的偏移量。数据格式由下文的“code_item”指定。
*/
uleb128 code_off;
};
code_item
code_item 是字节码信息,包含每个 Java 代码块的代码,和寄存器数量等相关信息。
struct code_item
{
u2 registers_size; // 此代码使用的寄存器数量。
u2 ins_size; // 此代码所用方法的传入参数的字数。
u2 outs_size; // 此代码进行方法调用所需的传出参数空间的字数。
/*
此实例的 try_item 数量。如果此值为非零值,则这些项会显示为 tries 数组
(正好位于此实例中 insns 的后面)。
*/
u2 tries_size;
/*
从文件开头到此代码的调试信息(行号 + 局部变量信息)序列的偏移量;如果没有任
何信息,则该值为 0。该偏移量(如果为非零值)应该是到 data 区段中某个位置的偏移量。数据格式由下文的“debug_info_item”指定。
*/
u4 debug_info_off;
u4 insns_size; // 指令列表的大小(以 16 位代码单元为单位)。
/* 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









