







在上一个博客里,我们将一辆汽车的油箱、发动机进行了大体的说明了,汽车的最主要的功能已经说明了,那么想让汽车发动起来,我们应该怎么办呢?对,司机,我们现在还缺一个司机来使用这些资源,那么这些资源是如何使用的呢?
在我们刚开始的时候,我对spark进行相应的简介的时候说过一个词,也在后面对这个词进行了具体的讲解,他就是RDD--分布式弹性数据集,它通过将计算数据持久化到内存中进行存储,提高了集群的运行效率,那么,作为一个大数据处理方面的劳斯莱斯,spark仅仅只是在这一个方面进行了优化吗?他会满足仅仅只是由RDD提供的运行效率吗?答案是肯定的,一定不会,所以,spark在另外两个重点的方面进行了自己的发展,资源和任务。进行一个数据的计算无非就是两个方面,提交处理任务,获取相应的资源之后对提交的任务进行处理,那么在spark内部是如何进行资源调度的呢
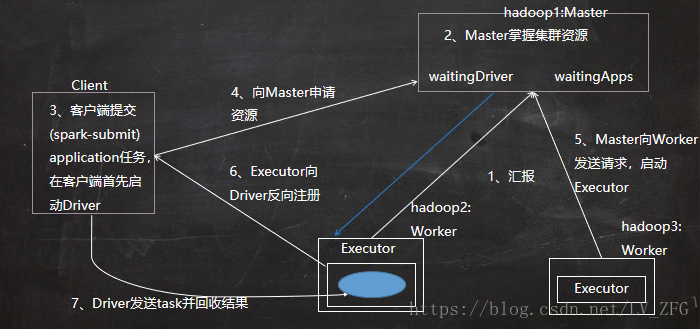
- 资源调度:Worker是在集群启动的时候就向Master注册了集群的相关信息,存储在一个HashSet中,Master就掌握了整个集群的资源情况。Driver在启动后将其信息注册到Master中,存储在ArrayBuffer中,Driver启动后会另外启动一个线程将Application注册到Master,同样存储在ArrayBuffer里。一个Worker默认给一个Application启动1个Executor,可以设置 --executor-cores num来启动多个。开机启动时最好设置spreadOut,可以在集群中分散启动executor。
- 资源调度的流程:
start-all.sh ssh去链接其他的节点,连接成功之后在hadoop2,3上各启动worker进程,往worker进程启动之后会向master注册,spark://hadoop1:7077
在client提交一个application,这个提交命令一回车,就会在客户端上启动一个进程(sparksubmit)。负责向master为driver申请资源,在底层源码中就是将申请的信息发送到master进程的waitingDriver对象中
master会根据worker的资源情况,选择合适的节点启动Driver
当Driver进程启动完毕后,会向master为application申请资源,在底层源码就是将申请信息写入到了waitingApps中
master会根据worker的资源情况选择资源充足的节点去启动executor
当executor启动完毕后,会反向注册给Driver进程,Driver就掌握了一批Executor进程
Driver进行任务调度,将task发送到Executor的线程池中去运行
就像人有点粗心有的细心一样,资源调度也有两种不同的类型:粗粒度的资源调度,细粒度的资源调度
粗粒度的资源调度(Spark):就像一个富二代一样,一生下来就掌握了一大批的资源,可以自己任意挥霍,去干自己想干的事情,不担心会没有钱,粗粒度的资源调度就是这样在Application执行之前,现将资源申请完毕在执行任务调度,一直到最后一个task执行 完毕在会释放资源
优点:task启动快,所以stage、job、application的一系列的流程的处理速度都会加快,执行时间短
缺点:当集群中有一个task没有执行完都不会释放这个资源,集群的资源产生浪费
细粒度的资源调度(MapReduce):穷人家的孩子早当家,当有事情要去处理的时候会好好的考考虑一下资源的使用情况,看看够不够,给每件事情使用刚刚好的钱,细粒度的资源调度就是这样在Application执行之前,不会将资源准备好,而是直接进行任务调度,让每一个task自己去申请资源,他需要多少资源就申请多少资源,每一个task执行完毕之后就立即释放资源
优点:很好的利用了集群的资源,因为每一次都是task动态的申请资源,需要多少申请多少,不会造成资源的浪费,能够充分的利用集群的资源,
缺点:来一个task申请一次,国家都支持简短操作流程了,他还是浪费时间的操作在申请上,很烦,而且造成的结果就是task启动时间长,从而之后一系列的都会很慢,影响了集群的使用效率
人无完人,孰能无过,不同的事情不同的对待,我们可以自己选择合适的方式进行资源的申请,可是这之后呢,如果集群在处理过程中出现问题,怎么办,不用担心,这个时候就体现出来程序员缜密的逻辑思维能力了,在spark的设定中
1、如果在提交Application的时候没有指定 --executor-cores这个选项,默认每台节点启动一个executor进程,占用1G内存和Worker管理的所有core,或默认的分配这些资源,但是人心不足蛇吞象,总会有不满足这么点资源的,那这个时候国家就会进行分配了,我们可以通过在提交任务的时候书面申请一下我需要多少资源
2、启动多个Executor进行需要指定
spark-submit --master spark://hadoop1:7077,hadoop2:7077 --executor-cores 1 --class org.apache.spark.examples.SparkPi ../lib/spark-submit-1.6.0-hadoop2.6.0.jar 101
--driver-cores 每个Driver进程需要的核数
--driver-memory 每个Driver进程需要的内存
--executor-cores 每个Executor进程需要的核数
--executor-memory 每个Executor进程需要的内存
--total-executor-cores Application总共需要使用的核数
最后补充一点在启动applicationInfo的时候,master回去worker上启动executor,我们的数据跟executor都是随机启动的,Executor的启动过程是轮训启动的方式,executor启动时候计算能够更好地找到数据,有助于数据的本地化














 595
595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









