







通常来说,Hive只支持数据查询和加载,但后面的版本也支持了插入,更新和删除以及流式api。Hive具有目前Hadoop上最丰富最全的SQL语法,也拥有最慢最稳定的执行。是目前Hadoop上几乎标准的ETL和数据仓库工具。
Hive这个特点与其它AdHoc查询工具如Impala,Spark SQL或者Presto有着应用场景的区别,也就是虽然都是即席查询工具,前者适用与稳定作业执行,调度以及ETL,或者更倾向于交户式。一个典型的场景是分析师使用Impala去探测数据,验证想法,并把数据产品部署在Hive上执行。
在我们讲Hive原理和查询优化前,让我们先回顾一下Hadoop基本原理。
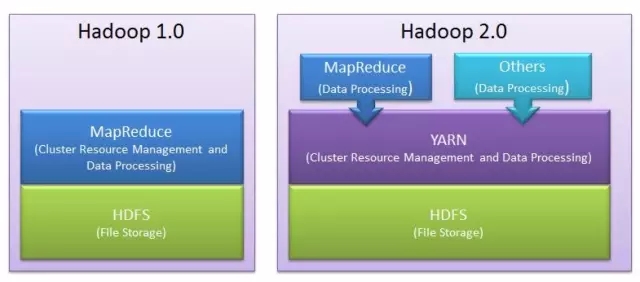
Hadoop是一个分布式系统,有HDFS和Yarn。HDFS用于执行存储,Yarn用于资源调度和计算。MapReduce是跑在Yarn上的一种计算作业,此外还有Spark等。
关于Hadoop介绍,硅谷的太阁实验室录制了一个视频。 http://v.youku.com/v_show/id_XMTUxOTA5MjA1Mg==.html 也是我主讲的。
Hive通常意义上来说,是把一个SQL转化成一个分布式作业,如MapReduce,Spark或者Tez。无论Hive的底层执行框架是MapReduce、Spark还是Tez,其原理基本都类似。
而目前,由于MapReduce稳定,容错性好,大量数据情况下使用磁盘,能处理的数据量大,所以目前Hive的主流执行框架是MapReduce,但性能相比Spark和Tez也就较低,等下讲到Group By和JOIN原理时会解释这方面的原因。
目前的Hive除了支持在MapReduce上执行,还支持在Spark和Tez 上执行。我们以MapReduce为例来说明的Hive的原理。先回顾一下 MapReduce 原理。
两个Mapper各自输入一块数据,由键值对构成,对它进行加工(加上了个字符n),然后按加工后的数据的键进行分组,相同的键到相同的机器。这样的话,第一台机器分到了键nk1和nk3,第二台机器分到了键nk2。
接下来再在这些Reducers上执行聚合操作(这里执行的是是count),输出就是nk1出现了2次,nk3出现了1次,nk2出现了3次。从全局上来看,MapReduce就是一个分布式的GroupBy的过程。
从上图可以看到,Global Shuffle左边,两台机器执行的是Map。Global Shuffle右边,两台机器执行的是Reduce。所以Hive,实际上就是一个编译器,一个翻译机。把SQL翻译成MapReduce之类的作业。
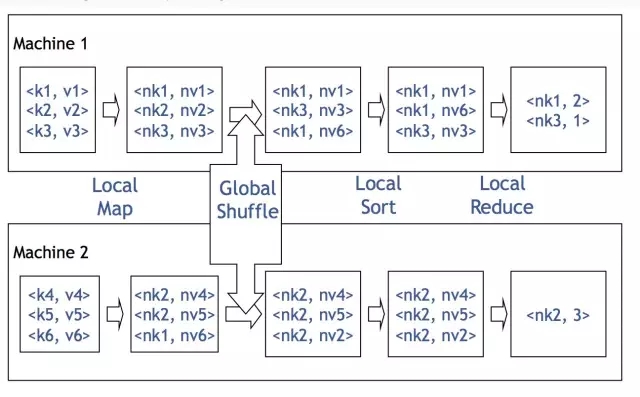
>>>>Hive架构
下面这个旧一点的图片来自Facebook
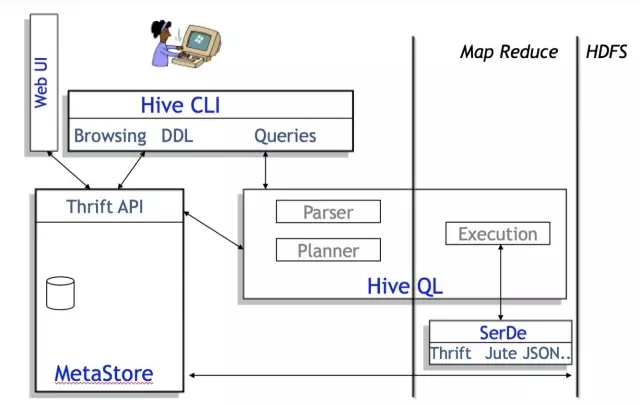
从架构图上可以很清楚地看出Hive和Hadoop(MapReduce,HDFS)的关系。
Hive是最上层,即客户端层或者作业提交层。
MapReduce/Yarn是中间层,也就是计算层。
HDFS是底层,也就是存储层。
从Facebook的图上可以看出,Hive主要有QL,MetaStore和Serde三大核心组件构成。QL就是编译器,也是Hive中最核心的部分。Serde就是Serializer和Deserializer的缩写,用于序列化和反序列化数据,即读写数据。MetaStore对外暴露Thrift API,用于元数据的修改。比如表的增删改查,分区的增删改查,表的属性的修改,分区的属性的修改等。等下我会简单介绍一下核心,QL。
>>>>Hive的数据模型
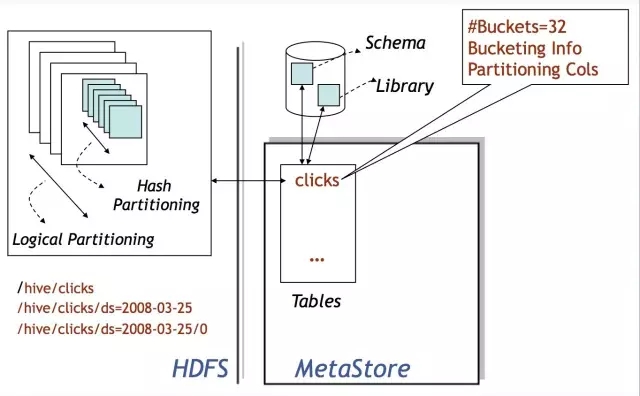
Hive的数据存储在HDFS上,基本存储单位是表或者分区,Hive内部把表或者分区称作SD,即Storage Descriptor。一个SD通常是一个HDFS路径,或者其它文件系统路径。SD的元数据信息存储在Hive MetaStore中,如文件路径,文件格式,列,数据类型,分隔符。Hive默认的分格符有三种,分别是^A、^B和^C,即ASCii码的1、2和3,分别用于分隔列,分隔列中的数组元素,和元素Key-Value对中的Key和Value。
还记得大明湖畔暴露Thrift API的MetaStore么?嗯,是她,就是它!所有的数据能不能认得出来全靠它!
Hive的核心是Driver,Driver的核心是SemanticAnalyzer。 Hive实际上是一个SQL到Hadoop作业的编译器。 Hadoop上最流行的作业就是MapReduce,当然还有其它,比如Tez和Spark。Hive目前支持MapReduce, Tez, Spark三种作业,其原理和刚才回顾的MapReduce过程类似,只是在执行优化上有区别。
Hive作业的执行过程实际上是SQL翻译成作业的过程?那么,它是怎么翻译的?
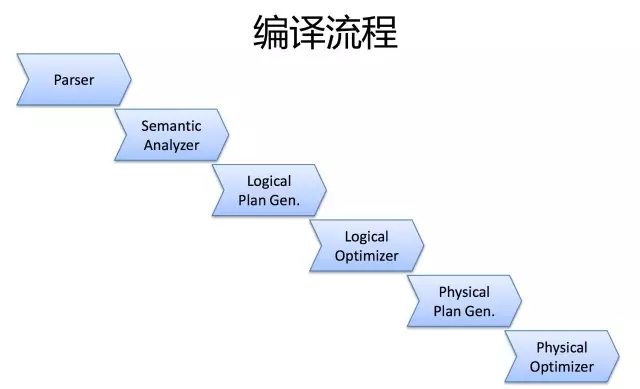
一条SQL,进入的Hive。经过上述的过程,其实也是一个比较典型的编译过程变成了一个作业。
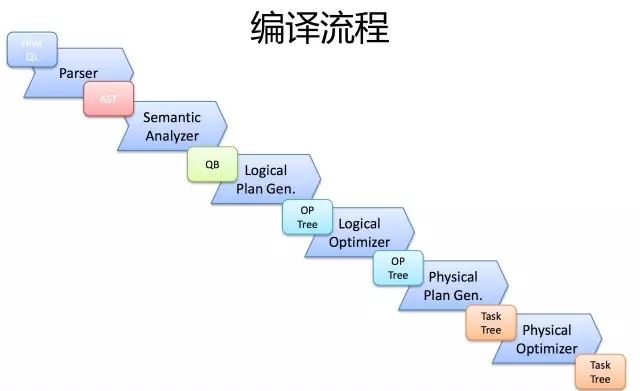
首先,Driver会输入一个字符串SQL,然后经过Parser变成AST,这个变成AST的过程是通过Antlr来完成的,也就是Anltr根据语法文件来将SQL变成AST。
AST进入SemanticAnalyzer(核心)变成QB,也就是所谓的QueryBlock。一个最简的查询块,通常来讲,一个From子句会生成一个QB。生成QB是一个递归过程,生成的 QB经过GenLogicalPlan过程,变成了一个Operator图,也是一个有向无环图。
OP DAG经过逻辑优化器,对这个图上的边或者结点进行调整,顺序修订,变成了一个优化后的有向无环图。这些优化过程可能包括谓词下推(Predicate Push Down),分区剪裁(Partition Prunner),关联排序(Join Reorder)等等
经过了逻辑优化,这个有向无环图还要能够执行。所以有了生成物理执行计划的过程。GenTasks。Hive的作法通常是碰到需要分发的地方,切上一刀,生成一道MapReduce作业。如Group By切一刀,Join切一刀,Distribute By切一刀,Distinct切一刀。
这么很多刀砍下去之后,刚才那个逻辑执行计划,也就是那个逻辑有向无环图,就被切成了很多个子图,每个子图构成一个结点。这些结点又连成了一个执行计划图,也就是Task Tree.
把这些个Task Tree 还可以有一些优化,比如基于输入选择执行路径,增加备份作业等。进行调整。这个优化就是由Physical Optimizer来完成的。经过Physical Optimizer,这每一个结点就是一个MapReduce作业或者本地作业,就可以执行了。
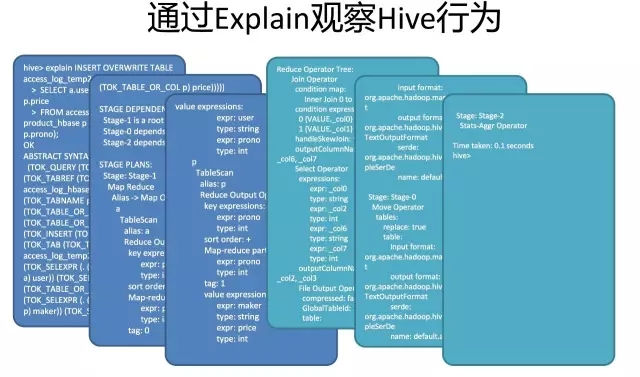
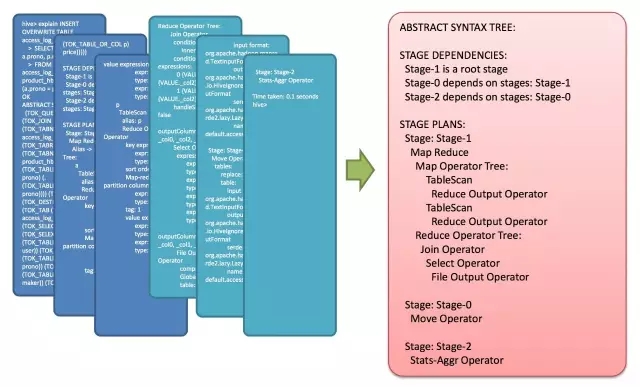
这就是一个SQL如何变成MapReduce作业的过程。要想观查这个过程的最终结果,可以打开Hive,输入Explain + 语句,就能够看到。
Hive最重要的部分是Group By和Join。下面分别讲解一下:
首先是Group By
例如我们有一条SQL语句:
INSERT INTO TABLE pageid_age_sum
SELECT pageid, age, count(1)
FROM pv_users
GROUP BY pageid, age;
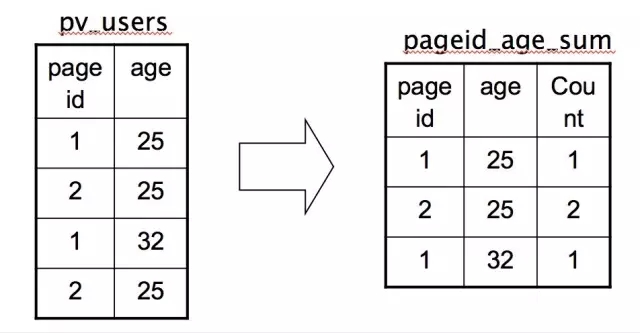
把每个网页的阅读数按年龄进行分组统计。由于前面介绍了,MapReduce就是一个Group By的过程,这个SQL翻译成MapReduce就是相对简单的。
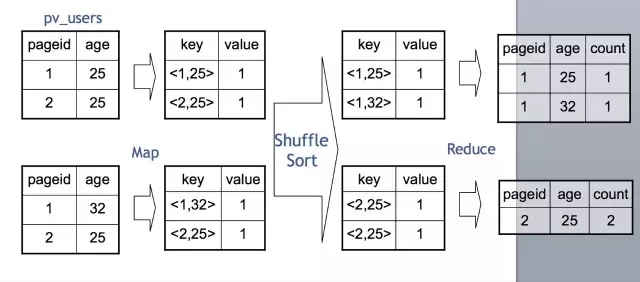
我们在Map端,每一个Map读取一部分表的数据,通常是64M或者256M,然后按需要Group By的Key分发到Reduce端。经过Shuffle Sort,每一个Key再在Reduce端进行聚合(这里是Count),然后就输出了最终的结果。值得一提的是,Distinct在实现原理上与Group By类似。当Group By遇上 Distinct……例如:SELECT pageid, COUNT(DISTINCT userid) FROM page_view GROUP BY pageid
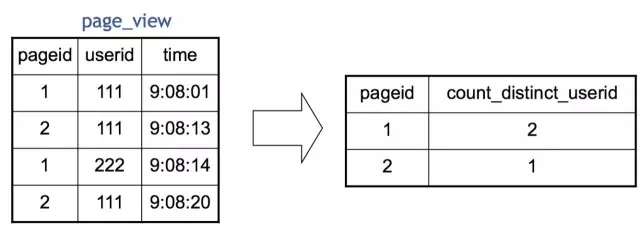
Hive 实现成MapReduce的原理如下:
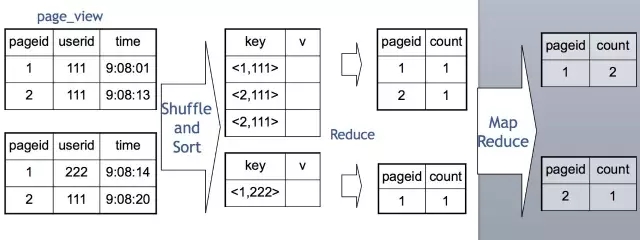
也就是说Map分发到Reduce的时候,会使用pageid和userid作为联合分发键,再去聚合(Count),输出结果。
介绍了这么多原理,重点还是为了使用,为了适应场景和业务,为了优化。从原理上可以看出,当遇到Group By的查询时,会按Group By 键进行分发?如果键很多,撑爆了机器会怎么样?
对于Impala,或Spark,为了快,key在内存中,爆是经常的。爆了就失败了。对于Hive,Key在硬盘,本身就比Impala, Spark的处理能力大上几万倍。但……不幸的是,硬盘也有可能爆。
当然,硬盘速度也比内存慢上不少,这也是Hive总是被吐槽的原因,场景不同,要明白自己使用的场景。当Group By Key大到连硬盘都能撑爆时……这个时候可能就需要优化了。
Group By优化通常有Map端数据聚合和倾斜数据分发两种方式。Map端部分聚合,配置开关是hive.map.aggr
也就是执行SQL前先执行 set hive.map.aggr=true;它的原理是Map端在发到Reduce端之前先部分聚合一下。来减少数据量。因为我们刚才已经知道,聚合操作是在Reduce端完成的,只要能有效的减少Reduce端收到的数据量,就能有效的优化聚合速度,避免爆机,快速拿到结果。
另外一种方式则是针对倾斜的key做两道作业的聚合。什么是倾斜的数据?比如某猫双11交易,华为卖了1亿台,苹果卖了10万台。华为就是典型的倾斜数据了。如果要统计华为和苹果,会用两个Reduce作Group By,一个处理1亿台,一个处理10万台,那个1亿台的就是倾余。
由于按key分发,遇到倾斜数据怎么办?
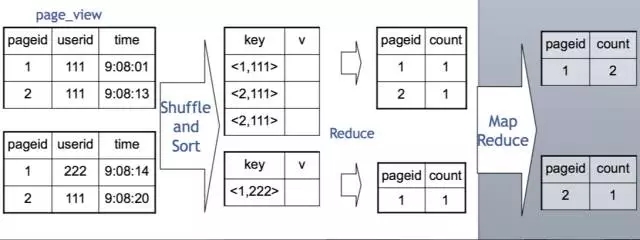
可以使用hive.groupby.skewindata选项,通过两道MapReduce作业来处理。当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group ByKey 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce中),最后完成最终的聚合操作。
第一道作业:Map随机分发,按gby key部分聚合
第二道作业:第一道作业结果Map倾斜的key分发,按gbk key进行最终聚合
无论你使用Map端,或者两道作业。其原理都是通过部分聚合来来减少数据量。能不能部分聚合,部分聚合能不能有效减少数据量,通常与UDAF,也就是聚合函数有关。也就是只对代数聚合函数有效,对整体聚合函数无效。
所谓代数聚合函数,就是由部分结果可以汇总出整体结果的函数,如count,sum。 所谓整体聚合函数,就是无法由部分结果汇总出整体结果的函数,如avg,mean。 比如,sum, count,知道部分结果可以加和得到最终结果。 而对于,mean,avg,知道部分数据的中位数或者平均数,是求不出整体数据的中位数和平均数的。
在遇到复杂逻辑的时候,还是要具体问题具体分析,根据系统的原理,优化逻辑。刚才说了,Hive最重要的是Group By和Join,所以下面我们讲Join.
>>>>JOIN
例如这样一个查询:INSERT INTO TABLE pv_users
SELECT pv.pageid, u.age
FROM page_view pv JOIN user u ON (pv.userid = u.userid);

把访问和用户表进行关联,生成访问用户表。Hive的Join也是通过MapReduce来完成的。
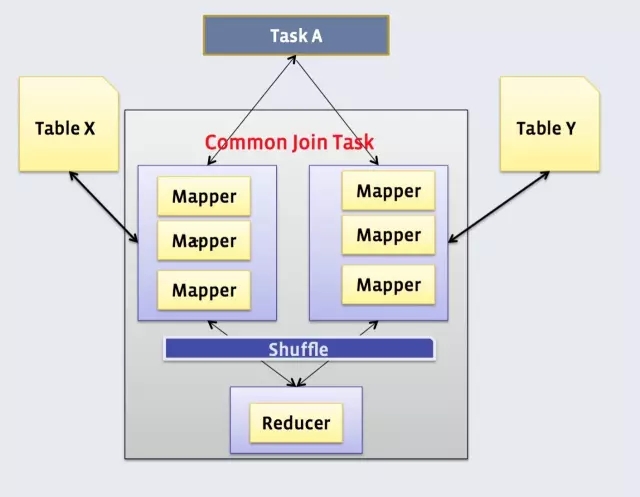
就上面的查询,在MapReduce的Join的实现过程如下:
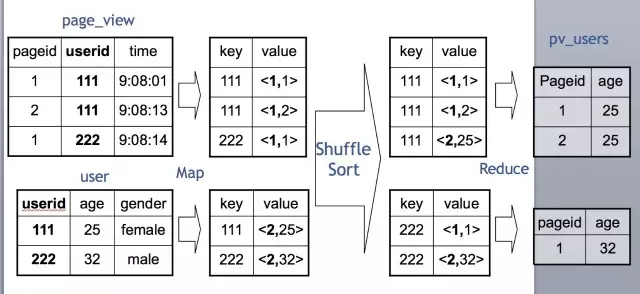
Map端会分别读入各个表的一部分数据,把这部分数据进行打标,例如pv表标1,user表标2.
Map读取是分布式进行的。标完完后分发到Reduce端,Reduce 端根据Join Key,也就是关联键进行分组。然后按打的标进行排序,也就是图上的Shuffle Sort。
在每一个Reduce分组中,Key为111的在一起,也就是一台机器上。同时,pv表的数据在这台机器的上端,user表的数据在这台机器的下端。
这时候,Reduce把pv表的数据读入到内存里,然后逐条与硬盘上user表的数据做Join就可以了。
从这个实现可以看出,我们在写Hive Join的时候,应该尽可能把小表(分布均匀的表)写在左边,大表(或倾斜表)写在右边。这样可以有效利用内存和硬盘的关系,增强Hive的处理能力。
同时由于使用Join Key进行分发, Hive也只支持等值Join,不支持非等值Join。由于Join和Group By一样存在分发,所以也同样存在着倾斜的问题。所以Join也要对抗倾斜数据,提升查询执行性能。
通常,有一种执行非常快的Join叫Map Join 。
>>>>Map Join 优化
手动的Map Join SQL如下:
INSERT INTO TABLE pv_users
SELECT /*+ MAPJOIN(pv) */ pv.pageid, u.age
FROM page_view pv JOIN user u
ON (pv.userid = u.userid);
还是刚才的例子,用Map Join执行
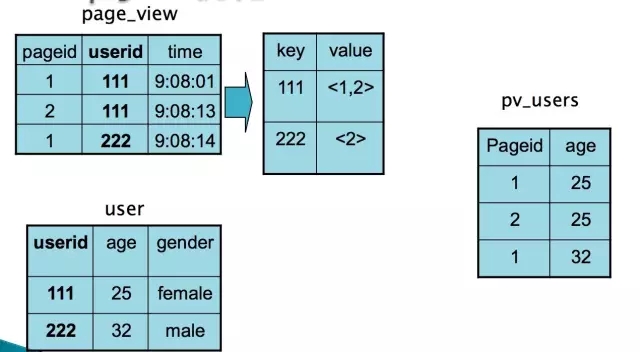

Map Join通常只适用于一个大表和一个小表做关联的场景,例如事实表和维表的关联。
原理如上图,用户可以手动指定哪个表是小表,然后在客户端把小表打成一个哈希表序列化文件的压缩包,通过分布式缓存均匀分发到作业执行的每一个结点上。然后在结点上进行解压,在内存中完成关联。
Map Join全过程不会使用Reduce,非常均匀,不会存在数据倾斜问题。默认情况下,小表不应该超过25M。在实际使用过程中,手动判断是不是应该用Map Join太麻烦了,而且小表可能来自于子查询的结果。
Hive有一种稍微复杂一点的机制,叫Auto Map Join
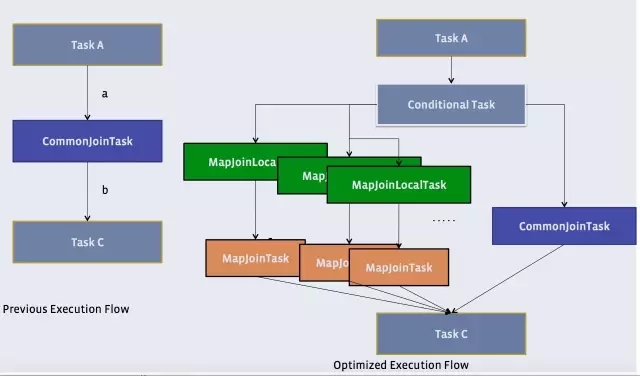
还记得原理中提到的物理优化器?Physical Optimizer么?它的其中一个功能就是把Join优化成Auto Map Join
图上左边是优化前的,右边是优化后的
优化过程是把Join作业前面加上一个条件选择器ConditionalTask和一个分支。左边的分支是MapJoin,右边的分支是Common Join(Reduce Join)
看看左边的分支是不是和我们上上一张图很像?
这个时候,我们在执行的时候,就由这个Conditional Task 进行实时路径选择,遇到小于25兆走左边,大于25兆走右边。所谓,男的走左边,女的走右边,人妖走中间。
在比较新版的Hive中,Auto Mapjoin是默认开启的。如果没有开启,可以使用一个开关, set hive.auto.convert.join=true 开启。
当然,Join也会遇到和上面的Group By一样的倾斜问题。
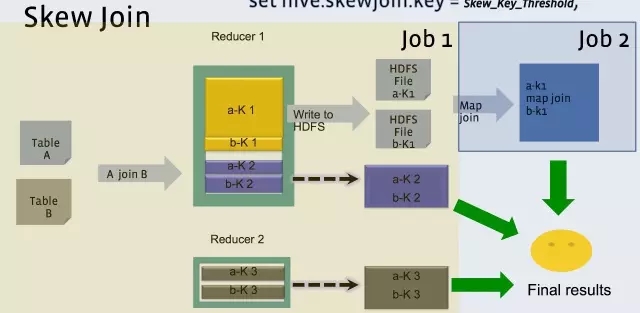
Hive 也可以通过像Group By一样两道作业的模式单独处理一行或者多行倾斜的数据。
>>>>
hive 中设定
set hive.optimize.skewjoin = true;
set hive.skewjoin.key = skew_key_threshold (default = 100000)
其原理是就在Reduce Join过程,把超过十万条的倾斜键的行写到文件里,回头再起一道Join单行的Map Join作业来单独收拾它们。最后把结果取并集就是了。如上图所示。
Update/Insert/Delete原理
Hive从0.14开始支持ACID。也就是支持了Update Insert Delete及一些流式的API。也就是这个原因,Hive把0.14.1 Bug Fixes版本改成了 Hive 1.0,也就是认为功能基本稳定和健全了。
由于HDFS是不支持本地文件更改的,同时在写的时候也不支持读。
表或者分区内的数据作为基础数据。事务产生的新数据如Insert/Update/Flume/Storm等会存储在增量文件(Delta Files)中。读取这个文件的时候,通常是Table Scan阶段,会合并更改,使读出的数据一致。
Hive Metastore上面增加了若干个线程,会周期性地合并并合并删除这些增量文件。
具体可以实现参考这个网页。 https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions
>>>>
Hive适合做什么?
由于多年积累,Hive比较稳定,几乎是Hadoop上事实的SQL标准。 Hive适合离线ETL,适合大数据离线Ad-Hoc查询。适合特大规模数据集合需要精确结果的查询。对于交互式Ad-Hoc查询,通常还会有别的解决方案,比如Impala, Presto等等。
特大规模的离线数据处理,尤其是大表关联,特大规模数据聚集,很适合使用Hive。讲了这么多原理,最重要的还是应用,还是创造价值。
对Hive来说,数据量再大,都不怕。数据倾斜,是大难题。但有很多优化方法和业务改进方法可以避过。Hive执行稳定,函数多,扩展性强,数据吞吐量大,了解原理,有助于用好和选型。















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









