







Hive
什么是Hive
- Hive是建立在Hadoop HDFS之上的
数据仓库基础架构(开源) - Hive可以用来进行数据提取转化加载(ETL)
- Hive定义了简单的类似SQL查询语言,成为HQL,它允许熟悉SQL的用户查询数据
- Hive允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作
- Hive是SQL解释引擎,他将SQL语句转移成M/R Job,然后在Hadoop执行
- Hive的表其实就是HDFS的目录/文件
数据仓库就是数据库,也就是说我们可以用数据仓库来保存数据
数据仓库是一个面向
主题的、集成的不可更新的、随时间不变化的数据集合,它用于支持企业或组织的决策分析处理
主题是用户使用数据仓库进行决策时关心的重点方面
集成也就是说数据仓库中的数据来自分的的操作性的数据,我们把分散的操作性的数据从原来的数据中抽取出来进行加工处理,然后满足一定要求,这样就可以进入数据仓库,原来的数据可以来自传统的数据库,也可以来自文本文件…,我们把不同的数据集成起来就成了数据仓库
不可更新也就是说数据仓库主要是为了决策分析所提供数据,所以所涉及的操作主要指数据查询,我们一般不在数据仓库做删除和更新,因为数据仓库就是做查询操作,并且数据仓库中的数据不随时间推移产生变化
数据仓库的结构和建立过程
- 首先需要有数据源,可能来自于业务数据系统、文档资料、或其它数据
- 数据存储即管理,抽取(Extract)、转换(Transform)、装载(Load),抽取:把数据源中的数据按照一定方式独取出来然后进行转换,因为不同数据源格式可能不一样,不一定满足要求,所以需要按照一定规则进行转换,这样转换完的数据就可以存储在数据仓库
- 数据仓库引擎,包含有不同服务器,提供不同服务,
- 进行前端展示,例如数据查询、数据报表、数据分析、各类应用
OLTP应用与OLAP
OLTP(OnLine Transition Procession)联机事务处理,关注焦点是事务处理,例:银行转帐
OLAP(OnLine Analysis Processing)联机分析处理,最典型应用是商品推荐系统,基于历史数据进行分析挖掘然后提供给别的系统进行使用。主要面向查询,一般不进行更新或者删除或者插入操作,因为里面数据都属于历史数据
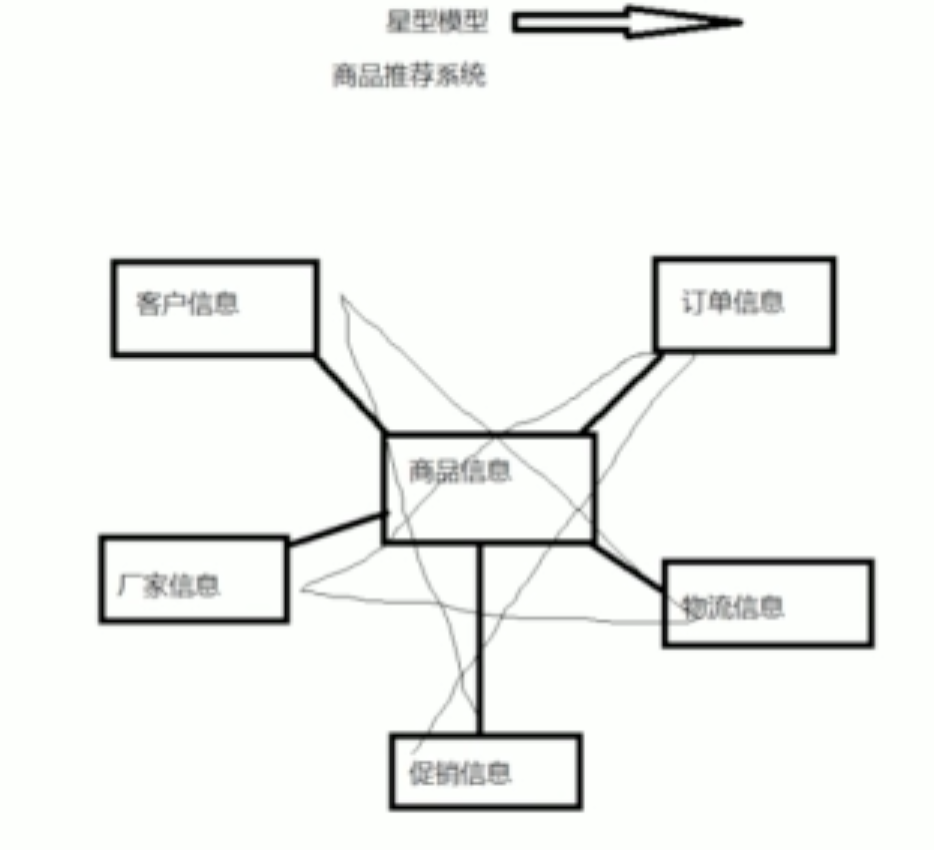
数据仓库中的数据模型
- 星型模型
最基本的数据模型,是搭建数据仓库的模型
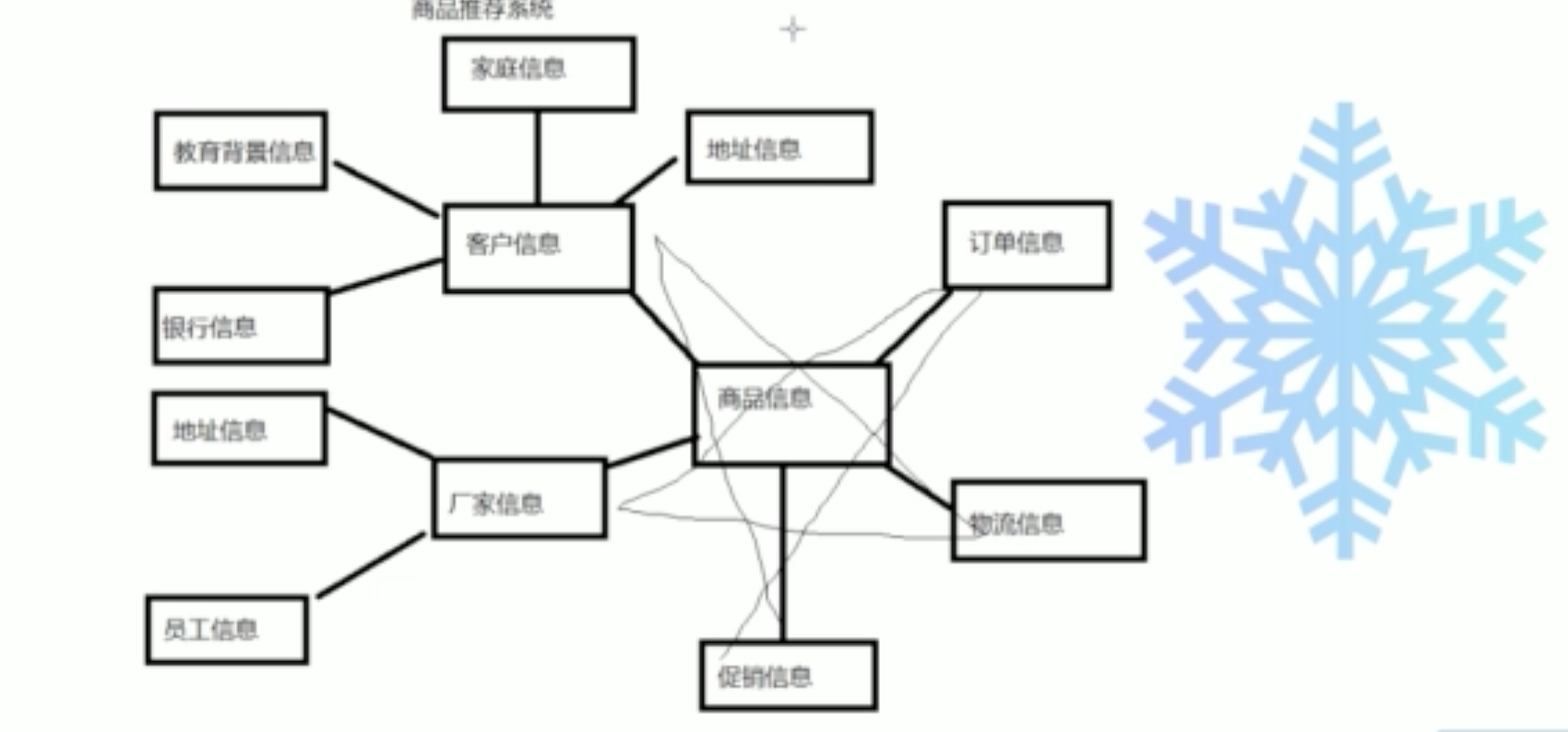
- 雪花模型
适用于更复杂场景
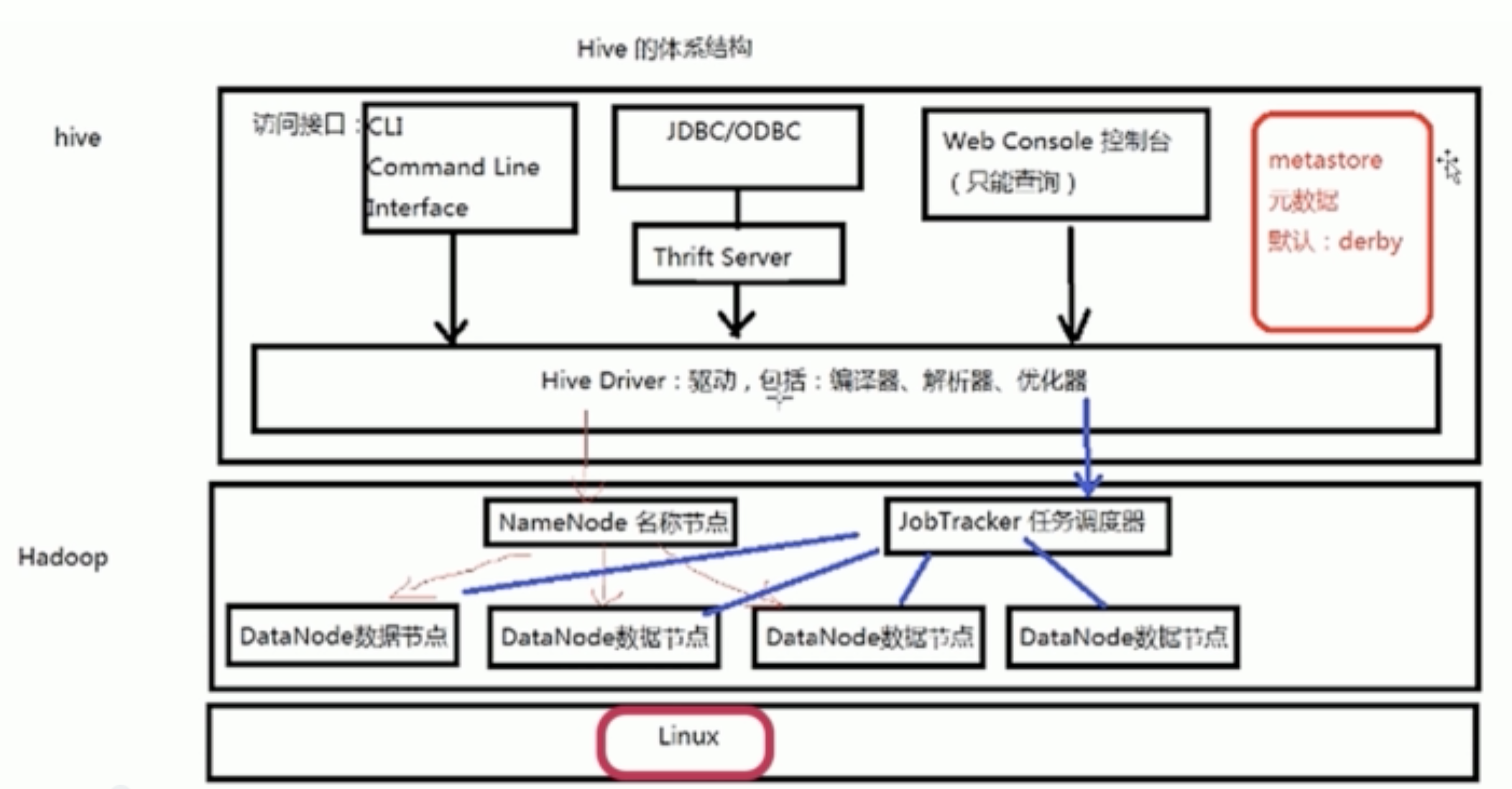
Hive的体系结构
- Hadoop
- 用HDFS进行存储,利用MapReduce进行计算
- Hive的元数据
- Hive将元数据存储在数据库中(metastore),支持mysql,derby等数据库
- Hive中的元数据包括表的名字,表的咧和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
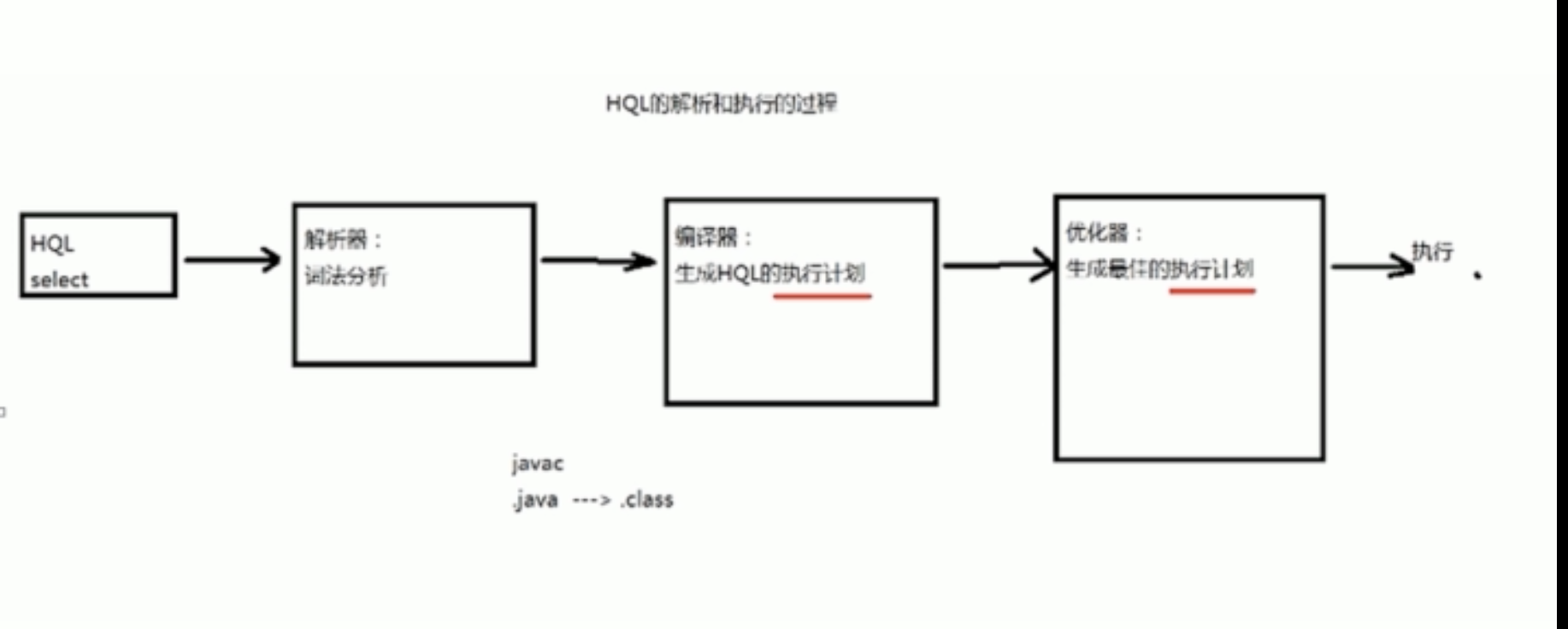
一条HQL语句如何在hive中进行查询
- 解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划(Plan)的生成。生成的查寻计划存储在HDFS中,并在随后有MapReduce调用执行















 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









