






目录
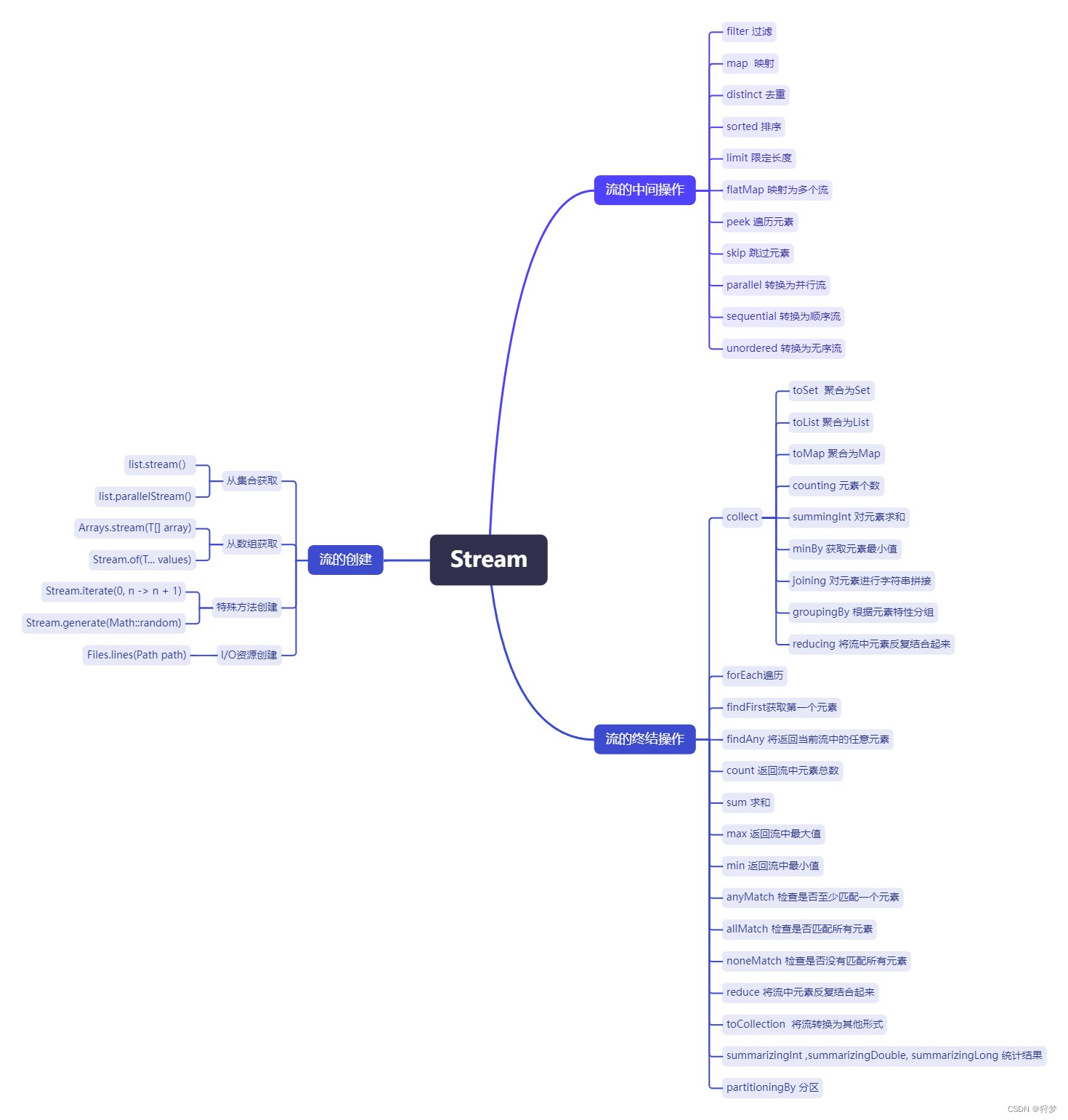
1 思维导图(功能点集结)
2 代码示例
2.1 流的创建,获取
2.1.1 通过集合获取流
集合的.stream()方法:所有实现了Collection接口的类(如List, Set, Queue)都提供了.stream()方法来获取一个流。
List<String> list = Arrays.asList("apple", "banana", "orange");
Stream<String> stream1 = list.stream(); // 获取顺序流集合的.parallelStream()方法:与.stream()类似,但会尝试并行处理流中的元素。
List<String> list = Arrays.asList("apple", "banana", "orange");
Stream<String> stringStream = list.parallelStream(); // 获取并行流
2,1,2 从数组获取
Arrays.stream(T[] array):用于从数组创建流。
String[] strArray = {"apple", "banana", "orange"};
Stream<String> stream2 = Arrays.stream(strArray);Stream.of(T... values):静态方法,可以直接从一系列值创建流。
Stream<String> stream = Stream.of("a", "b", "c");2.1.3 特殊方法创建
Stream.iterate(T seed, Predicate<T> hasNext, UnaryOperator<T> f):生成一个无限或者有限的顺序流,起始于给定的种子值,然后依次应用函数f。
Stream<String> stream4 = Stream.generate(() -> "apple");
Stream.generate(Supplier<T> s):生成一个无限的流,每次调用supplier函数生成下一个元素。
Stream<Integer> stream5 = Stream.iterate(0, (x) -> x + 2);
2.1.4 I/O资源创建
Files.lines(Path path):从文件的每一行读取内容生成流。
try (Stream<String> lines = Files.lines(Paths.get("path/to/file.txt"))) {
lines.forEach(System.out::println);
}catch (Exception e){
e.printStackTrace();
}2.2 流的中间操作
首先创建一个用户类用于操作
class User {
private String name;
private Integer age;
private String address;
public User(String name, Integer age, String address) {
this.name = name;
this.age = age;
this.address = address;
}
public void setName(String name){
this.name = name;
}
public void setAge(Integer age){
this.age = age;
}
public void setAddress(String address){
this.address = address;
}
public String getName(){
return name;
}
public Integer getAge(){
return age;
}
public String getAddress(){
return address;
}
List<User> userList = new ArrayList<>(Arrays.asList(
new User("张三", 18, "北京"),
new User("李四", 19, "上海"),
new User("王五", 20, "广州"),
new User("赵六", 21, "深圳")));2.2.1 filter
根据指定的条件过滤流中的元素。
以下代码作用:筛选集合中以“a"开头的元素
list.stream().filter(s -> s.startsWith("a")).forEach(System.out::println);
2.2.2 map
接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素(使用映射一词,是因为它和转换类似,但其中的细微差别在于它是"创建一个新版本"而不是去"修改")
以下代码所用: 将列表中的每个元素转为大写并打印
list.stream().map(String::toUpperCase).forEach(System.out::println);
2.2.3 distinct
去除流中的重复元素
userList.stream().map(User::getAge).distinct().collect(Collectors.toList());
2.2.4 sorted
该函数的作用是对用户列表按照年龄进行升序排序,并将排序后的结果转换为列表形式。
userList.stream():将用户列表转换为流。
sorted(Comparator.comparing(User::getAge)):使用Comparator.comparing方法指定按照用户年龄进行排序。
collect(Collectors.toList()):将排序后的流收集到一个新的列表中。
userList.stream().sorted(Comparator.comparing(User::getAge)).collect(Collectors.toList());
2.2.5 limit
会返回一个不超过给定长度的流
该函数的作用是将用户列表(userList)转换成流,然后限制流中的元素数量最多为2个,最后将限制后的流收集并转换成一个新的列表。
userList.stream().limit(2).collect(Collectors.toList());
2,2,6 flatMap
flatMap() 方法与 map() 方法在处理流时都用于转换元素,但它们的行为有显著差异:
map():
接受一个函数,这个函数作用于流中的每个元素,将其转换成另一个对象。
返回一个新的流,其中包含原始流中每个元素经过转换后的结果。
结果流的元素个数与原流相同,保持原有的结构。
flatMap():
也接受一个函数,但这个函数返回的是一个流,而不是单一的值。
对流中的每个元素应用该函数,得到一个流的流。
使用 flatMap() 会将所有这些小流“扁平化”成一个单一的流,即合并所有的流成一个不包含流的流。
结果流的元素个数可能与原流不同,取决于转换函数返回的流的长度。
简单来说,map() 用于一对一的转换,而 flatMap() 用于一对多的转换并整合成单一流。
该函数的作用是将userList中的每个用户对象user拆分为姓名和地址,然后将拆分后的结果合并为一个流,并将其转换为列表。
具体解释如下:
userList.stream():将userList转换为流,以便进行流式操作。
flatMap(user -> Stream.of(user.getName(), user.getAddress())):对每个用户对象user进行拆分操作,将其姓名和地址分别封装为一个流,然后将所有流合并为一个流。
collect(Collectors.toList()):将合并后的流转换为列表形式进行收集。
最终结果是一个包含所有用户姓名和地址的列表。
userList.stream().flatMap(user -> Stream.of(user.getName(), user.getAddress())).collect(Collectors.toList());
2.2.7 peek
对元素进行遍历处理
这段Java代码使用了Stream API来对userList进行操作。具体功能如下:
userList.stream() 将userList转换为流。
peek(user -> user.setAge(user.getAge() + 1)) 对流中的每个元素执行操作,将用户的年龄加1,并返回更新后的用户对象。该操作不会改变原列表中的元素。
collect(Collectors.toList()) 将更新后的用户对象流收集到一个新的列表中,并返回该列表。
整体来说,这段代码的作用是将userList中每个用户的年龄加1,并返回一个新的列表,原列表不受影响。
userList.stream().peek(user -> user.setAge(user.getAge() + 1)).collect(Collectors.toList());
2.2.8 skip
skip 跳过元素,返回一个扔掉了前n个元素的流。如果流中元素不足n个,则返回一个空流。与limit(n)互补
该函数的作用是将用户列表(userList)中的元素跳过前两个,然后将剩余的元素收集到一个新的列表中。使用了Java 8的Stream API进行操作。
具体步骤如下:
调用userList的stream()方法,将列表转换为Stream流。
调用skip(2)方法,跳过前两个元素。
调用collect(Collectors.toList())方法,将剩余的元素收集到一个新的列表中,并返回该列表。
userList.stream().skip(2).collect(Collectors.toList());
2.2.9 parallel
转化为并行流
该函数将用户列表转换为并行流,允许以并行方式对列表中的用户进行操作。这可以通过利用多核处理器的优势来提高处理速度。在处理大量数据时,使用并行流可以显著减少处理时间
Stream<User> parallel = userList.stream().parallel();
2.2.10 sequential
转化为顺序流
该代码片段是一个Java 8 Stream的操作。
首先,parallel()方法将Stream设置为并行模式,这意味着在处理元素时可以使用多线程来提高效率。
接下来,sequential()方法将Stream设置为顺序模式,即恢复到默认的串行处理方式。
最后,forEach()方法对Stream中的每个元素执行给定的操作,这里使用System.out::println作为操作,即打印每个元素的值。
总结来说,这段代码的作用是将一个Stream中的元素以顺序方式打印出来。
parallel.sequential().forEach(System.out::println);
2.2.11 unordered
取消流中元素的遍历顺序(无序流)
该函数是一个Java 8 Stream的操作,作用是将Stream中的每个元素并行、无序地通过System.out::println方法进行输出。其中,parallel()方法将Stream转为并行流,unordered()方法表示可以不保留元素的原有顺序,forEach()方法用于遍历流中的每个元素。
parallel.unordered().forEach(System.out::println);
2.3 流的终结操作
创建一个集合,用于示例
List<String> strings = Arrays.asList("cv", "abd", "aba", "efg", "abcd", "jkl", "jkl");
2.3.1 forEach
遍历
该函数将一个字符串列表通过stream流进行遍历,并使用forEach方法对每个元素进行处理,具体的处理方式为调用System.out::println方法,即打印每个元素的值。
strings.stream().forEach(System.out::println);
2.3.2 findFirst
返回第一个元素
这段代码的功能是通过调用strings的stream()方法将其转换为流,然后调用findFirst()方法返回流中的第一个元素,并将其打印出来。
System.out.println(strings.stream().findFirst());
2,3,3 findAny
将返回当前流中的任意元素
该函数的作用是在给定的字符串集合strings中找到任意一个元素并将其打印出来。
strings.stream()将字符串集合转换为流;
findAny()方法在流中查找任意一个元素;
System.out.println()打印找到的元素。
System.out.println(strings.stream().findAny());
2.3.4 count
返回流中元素总数
该函数的功能是输出字符串数组strings中元素的个数。
strings.stream()将字符串数组转换为流。
count()方法统计流中的元素个数。
System.out.println()输出统计结果。
System.out.println(strings.stream().count());
2.3.5 sum
求和
这段代码的功能是计算字符串数组strings中所有字符串的长度之和。
strings.stream()将字符串数组转换为流(Stream)。
mapToInt(String::length)将流中的每个字符串映射到其长度,并转换为整数流(IntStream)。
sum()对整数流中的所有元素进行求和操作,返回一个整数。
System.out.println(strings.stream().mapToInt(String::length).sum());
2.3.6 max min
最大/最小值
该函数的功能是从字符串数组strings中找出最长的字符串,并打印出其长度。
strings.stream()将字符串数组转换为流。
Comparator.comparing(String::length)根据字符串的长度进行比较。
max(),min()方法返回流中的最大/最小值,即最长的字符串。
System.out.println(strings.stream().max(Comparator.comparing(String::length)));
System.out.println(strings.stream().min(Comparator.comparing(String::length)));
2.3.7 anyMatch
检查是否至少匹配一个元素
该函数的功能是判断给定的字符串数组strings中是否存在以字母"a"开头的字符串。通过stream()方法将数组转为流,然后使用anyMatch()方法对流中的每个元素进行匹配判断,判断条件为字符串是否以"a"开头。最后将匹配结果输出。
System.out.println(strings.stream().anyMatch(s -> s.startsWith("a")));
2.3.8 allMatch
检查是否匹配所有元素
该代码片段的功能是判断字符串数组strings中的所有字符串是否都以字母"a"开头。
strings.stream():将字符串数组转换为流(Stream)。
allMatch(s -> s.startsWith("a")):对流中的每个字符串应用lambda表达式s -> s.startsWith("a"),判断是否都以"a"开头,返回布尔值。
System.out.println(strings.stream().allMatch(s -> s.startsWith("a")));
2.3.9 noneMatch
检查是否没有匹配所有元素
该函数的功能是判断给定的字符串数组strings中是否存在不以字母"a"开头的字符串,并打印结果。使用了Java 8的流式操作,通过noneMatch方法对数组中的每个字符串应用lambda表达式s -> s.startsWith("a"),判断是否不以"a"开头,返回布尔值。最终结果为true表示不存在以"a"开头的字符串,false表示存在至少一个以"a"开头的字符串。
System.out.println(strings.stream().noneMatch(s -> s.startsWith("a")));
2.3.10 reduce
将流中元素反复结合起来
该函数将字符串数组strings中的所有字符串连接起来形成一个新的字符串。使用了Java 8的流式操作,通过reduce方法和lambda表达式(s1, s2) -> s1 + s2将所有字符串进行累加拼接。最终输出连接后的字符串。
System.out.println(strings.stream().reduce((s1, s2) -> s1 + s2));
2.3.11 collect
2.3.11.1 toSet
转为Set
该函数将字符串列表strings通过流操作转换为一个不包含重复元素的集合set。使用Collectors.toSet()方法收集流的元素,保证集合中的元素唯一。
Set set = strings.stream().collect(Collectors.toSet());
2.3.11.2 toList
转为List
该函数将字符串集合strings通过流操作转换为列表类型List。使用collect方法和Collectors.toList()收集器将流中的元素收集到一个新的列表中。
List list = strings.stream().collect(Collectors.toList());2.3.11.3 toMap
转为Map
该函数将strings流中的每个元素通过拼接_name的方式作为键,将元素本身作为值,使用toMap方法将流转换为Map。如果出现重复的键,则使用lambda表达式(v1, v2) -> v1保留第一个出现的值。
Map<String, String> map = strings.stream().collect(Collectors.toMap(v -> v.concat("_name"), v1 -> v1, (v1, v2) -> v1));
2.3.11.4 counting
统计数量
该函数使用Java 8的流式操作,对字符串列表进行过滤,仅保留长度大于3的字符串,然后对符合条件的字符串进行计数,返回符合条件的字符串总数。
long count = strings.stream().filter(item -> item.length() > 3).collect(Collectors.counting()); // 符合条件的用户总数
2.3.11.5 summingInt
统计
该函数的功能是计算字符串数组strings中所有字符串的长度之和。
strings.stream()将字符串数组转换为流(Stream)。
Collectors.summingInt(item -> item.length())使用IntStream的sum方法对流中的每个字符串的长度进行求和操作。
System.out.println(strings.stream().collect(Collectors.summingInt(item -> item.length()))); // 求和
2.3.11.6 minBy maxBy
最小值/最大值
这段代码使用Java 8的Stream API和Collectors对字符串列表进行操作。
首先,strings.stream()将字符串列表转换为流。
然后,使用Collectors.minBy()和Collectors.maxBy()收集器来找到字符串长度的最小值和最大值。
Comparator.comparingInt(String::length)根据字符串的长度进行比较。
System.out.println(strings.stream().collect(Collectors.minBy(Comparator.comparingInt(String::length))));// 最小值
System.out.println(strings.stream().collect(Collectors.maxBy(Comparator.comparingInt(String::length))));// 最小值
2.3.11.7 joining
字符串拼接
该函数将字符串数组strings中的所有元素通过stream()方法转换为流,然后使用collect()方法将流中的元素收集起来,并用"||"连接起来,最后通过println()方法打印输出。
System.out.println(strings.stream().collect(Collectors.joining("||")));
2.3.11.8 groupingBy
分组
该函数将字符串数组strings中的字符串按照长度进行分组,并打印出分组结果。具体来说,它使用了Java 8的流式操作,通过stream()方法将数组转为流,然后使用collect()方法进行收集操作,其中Collectors.groupingBy()方法用于指定按照字符串的长度进行分组,最后将分组结果打印出来。
System.out.println(strings.stream().collect(Collectors.groupingBy(String::length)));
2.3.11.9 reducing
拼接
该函数将字符串数组strings中的所有字符串进行拼接。使用stream()方法将数组转为流,然后通过collect()方法结合Reducing操作将流中的字符串进行拼接,使用lambda表达式(a, b) -> a + b定义拼接规则为将两个字符串相加。如果数组为空,则返回默认值"字符串不存在"。
System.out.println(strings.stream().collect(Collectors.reducing((a, b) -> a + b)).orElse("字符串不存在")); // 拼接
System.out.println(strings.stream().collect(Collectors.reducing(String::concat)).orElseGet(() -> "字符串不存在"));















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









