







目录
引言
引言
众所周知,深度学习是机器学习的一个子领域,它模仿了人类大脑中神经网络的工作方式,以通过数据学习复杂的模式和特征。它受到了生物神经系统,尤其是人脑神经元网络的启发。深度学习通过构建多层的人工神经网络模型来实现,这些模型能够自动地从数据中学习和提取特征,而无需人工进行特征工程。
在深度学习中,每层神经网络都可以视为对输入数据的一种抽象或转换,底层可能学习到的是非常基础的特征(如边缘检测),而高层则能学习到更加复杂和抽象的特征(如物体识别)。这种多层次的架构允许深度学习模型捕捉数据中的深层结构和模式,这在处理诸如图像、语音和自然语言等复杂数据类型时尤其有效。
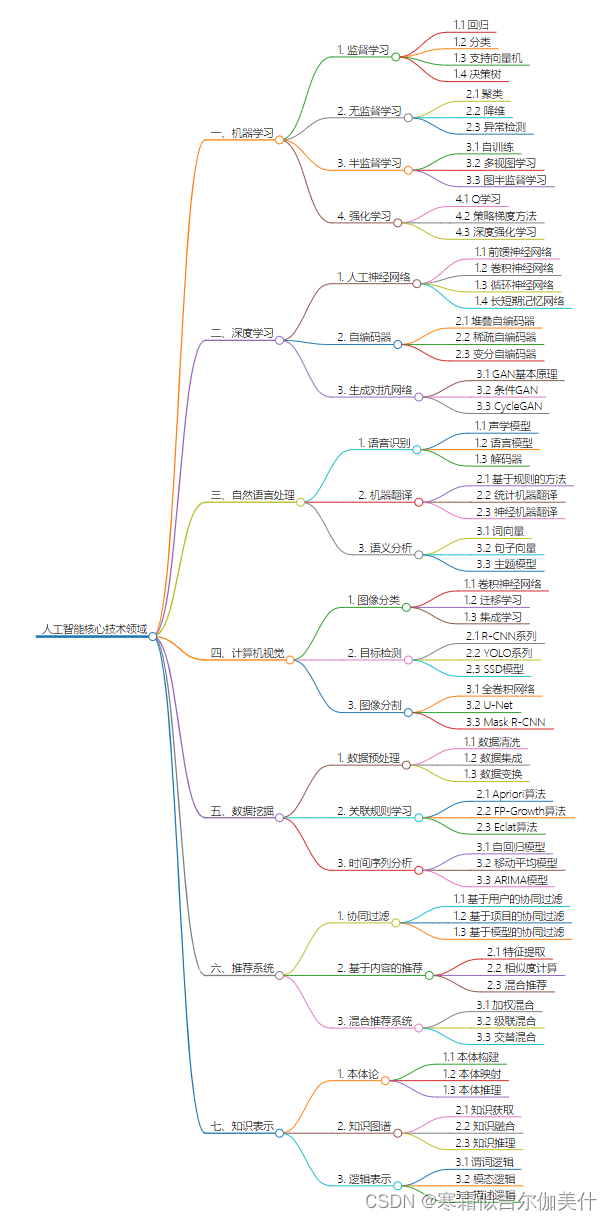
以下分享一些主要的深度学习算法:
多层感知机(MLP):
最基本的深度学习模型,由多层神经元组成,每一层都与下一层完全连接。
多层感知机(MLP)是深度学习中最基础的结构之一。它由多层神经元组成,通常包括输入层、一个或多个隐藏层以及输出层。每一层的神经元都与下一层的所有神经元相连接,这种结构使得MLP能够学习输入数据到输出标签之间的复杂映射。
MLP的基本组成部分包括:
-
输入层:接收原始数据。每个输入节点代表数据的一个特征。
-
隐藏层:介于输入层和输出层之间,可以有一个或多个。隐藏层的作用是从输入数据中提取特征并学习数据的复杂结构。
-
输出层:提供网络的最终输出。输出层的节点数取决于问题的性质。例如,在分类问题中,如果有N个类别,通常就会有N个输出节点,每个节点对应一个类别。
-
激活函数:用于在神经元的输入和输出之间引入非线性。常见的激活函数包括Sigmoid、Tanh、ReLU(Rectified Linear Unit)等。
-
权重和偏置:每个连接都有与之相关的权重,表示这个连接的强度。每个神经元还有一个偏置项,允许网络输出非零值即使输入为零。
-
前向传播:从输入层到输出层的信号传递过程,计算每个神经元的输出。
-
反向传播:通过计算损失函数关于网络参数的梯度来更新权重和偏置,以优化网络的性能。
-
损失函数:用于量化网络预测与真实标签之间的差异。常见的损失函数包括均方误差(MSE)、交叉熵等。
-
优化算法:如随机梯度下降(SGD)、Adam等,用于在网络中调整权重和偏置以最小化损失函数。
多层感知机可以用于各种任务,包括分类、回归等。由于其结构和训练过程的灵活性,MLP在许多领域都有广泛的应用。
卷积神经网络(CNN):
特别适用于处理具有网格结构的数据,如图像(2D网格)和视频(3D网格)。CNN在图像识别、物体检测和视频分析等领域表现出色。
卷积神经网络(CNN)是一种深度学习模型,特别适用于处理具有网格结构的数据,如图像(2D网格)和视频(3D网格)。CNN通过使用卷积层、池化层和全连接层等结构,能够有效地从图像和其他网格数据中提取特征,因此在图像识别、物体检测、视频分析和许多其他计算机视觉任务中表现出色。
CNN的主要组成部分包括:
-
卷积层:这是CNN的核心,通过应用一系列可学习的卷积核(或过滤器)来提取输入数据的空间特征。每个卷积核在输入数据上滑动,生成特征图(feature map)。
-
激活函数:通常在卷积层之后应用,如ReLU(Rectified Linear Unit),用于引入非线性,帮助网络学习更复杂的特征。
-
池化层:也称为下采样层,用于减少特征图的维度,减少计算量并提高模型的泛化能力。常见的池化操作包括最大池化和平均池化。
-
全连接层:在网络的最后几层,将池化层的输出展平并输入到全连接层中,进行分类或回归等任务。
-
归一化层:如批量归一化(Batch Normalization),用于加速训练过程,有时可以减少或消除Dropout的需求。
-
丢弃层(Dropout):在训练过程中随机丢弃一部分网络连接,以防止过拟合。
-
损失函数:用于量化模型预测与真实标签之间的差异,如交叉熵损失、均方误差等。
-
优化算法:如随机梯度下降(SGD)、Adam等,用于更新网络的权重。
CNN的关键优势在于其参数共享和空间层次结构特性,这使得它能够有效地处理高维数据,同时减少模型的参数数量。CNN在图像识别、物体检测、视频分析、图像分割、图像生成和风格迁移等领域都有广泛应用。
循环神经网络(RNN):
设计用来处理序列数据,如时间序列数据、语音、文本等。RNN能够保持状态信息,使其在处理序列数据时非常有效。
循环神经网络(RNN)是一种特别设计用来处理序列数据的神经网络。与传统的前馈神经网络不同,RNN具有循环结构,能够在序列的不同时间点保持并使用状态信息。这种特性使得RNN非常适合处理时间序列数据、语音、文本等序列数据。
RNN的基本结构包括:
-
循环单元:这是RNN的核心,它不仅接收当前时间步的输入,还接收前一个时间步的隐藏状态。循环单元的输出既用于当前时间步的预测,也作为下一个时间步的隐藏状态。
-
隐藏状态:隐藏状态是RNN在处理序列时保存的信息,它反映了到目前为止序列的历史信息。隐藏状态在序列的每个时间步都会更新。
-
输出层:根据隐藏状态计算输出。输出可以是序列的下一个元素、序列的分类标签或其他形式的预测。
-
激活函数:用于在循环单元中引入非线性,如tanh或ReLU。
RNN的关键优势在于其处理序列数据的能力,能够捕捉序列中的时间动态和长期依赖关系。然而,传统的RNN存在梯度消失或梯度爆炸的问题,这使得它们难以学习长序列中的长期依赖关系。
为了解决这些问题,发展了RNN的一些变体:
-
长短期记忆网络(LSTM):通过引入门控机制来控制信息的流入流出,有效地解决了传统RNN在长序列学习中的问题。
-
门控循环单元(GRU):是LSTM的一种更简单有效的变体,通过合并更新门和重置门来简化模型结构。
RNN及其变体在自然语言处理(如语言模型、机器翻译、文本生成)、语音识别、时间序列预测等领域有广泛的应用。
长短期记忆网络(LSTM):
RNN的变体之一,能够学习长期依赖关系。LSTM在处理长序列数据时表现优于传统RNN。
长短期记忆网络(LSTM)是循环神经网络(RNN)的一种变体,特别设计用于解决传统RNN在处理长序列数据时遇到的长期依赖问题。LSTM通过引入门控机制,能够在序列的每个时间步保持并更新长期状态信息,这使得它在学习长期依赖关系方面表现出色。
LSTM的核心结构包括:
-
遗忘门(Forget Gate):决定从长期状态中丢弃哪些信息。它查看前一个隐藏状态和当前输入,输出一个介于0和1之间的值给每个在长期状态中的数。1代表“完全保留这个信息”,而0代表“完全丢弃这个信息”。
-
输入门(Input Gate):控制新信息被更新到长期状态的程度。它包括一个决定哪些值要更新的输入门和一个创建一个新的候选值的向量。
-
细胞状态(Cell State):细胞状态是LSTM的核心,它贯穿于整个链结构,只有微小的线性交互,信息在这里可以无损地流动。
-
输出门(Output Gate):决定时间步的输出。输出门查看当前输入和前一个隐藏状态,然后决定细胞状态的哪些部分将输出。
LSTM的这些门控结构使其能够有效地学习序列数据中的长期依赖关系。与传统的RNN相比,LSTM在处理长序列数据时表现更优,特别是在需要长期记忆的任务中,如机器翻译、语音识别和时间序列预测等。
LSTM的这种能力使其成为处理序列数据问题的首选模型之一。尽管LSTM在模型大小和计算资源方面比传统RNN更复杂,但其强大的性能和灵活性使其在深度学习领域得到了广泛应用。
门控循环单元(GRU):
RNN的变体之一,与LSTM类似,但结构更为简单。GRU在某些任务中与LSTM性能相当,但参数更少。
门控循环单元(GRU)是循环神经网络(RNN)的一种变体,与长短期记忆网络(LSTM)类似,都是为了解决传统RNN在处理长序列数据时遇到的长期依赖问题。GRU通过合并LSTM中的遗忘门和输入门为一个更新门,同时合并细胞状态和隐藏状态,从而简化了模型结构。这使得GRU在某些任务中与LSTM性能相当,但参数更少,计算效率更高。
GRU的核心结构包括:
-
更新门(Update Gate):决定多大程度上将旧的状态信息传递到下一个状态。更新门查看前一个隐藏状态和当前输入,输出一个介于0和1之间的值。1代表“完全保留旧的状态信息”,而0代表“完全忽略旧的状态信息”。
-
重置门(Reset Gate):决定多大程度上将旧的状态信息忽略,并根据当前输入生成新的状态信息。重置门查看前一个隐藏状态和当前输入,输出一个介于0和1之间的值。
-
候选隐藏状态:基于重置门的输出,决定是否要“重置”或忽略旧的状态信息,并根据当前输入生成新的状态信息。
-
隐藏状态:最终隐藏状态是更新门和候选隐藏状态的组合,决定了在下一个时间步传递的信息。
GRU的这种结构简化了LSTM的门控机制,但仍然能够有效地学习序列数据中的长期依赖关系。与LSTM相比,GRU的参数更少,这使得它在计算资源有限的情况下更加高效。此外,GRU的训练过程通常比LSTM更快,因为它需要更少的计算来更新状态。
GRU在处理序列数据问题时,特别是在需要长期记忆的任务中,如自然语言处理、语音识别和时间序列预测等,表现出了与LSTM相当的性能。由于其结构简单和高效性,GRU在深度学习领域得到了广泛应用。
自编码器(Autoencoders):
用于无监督学习,目的是学习输入数据的有效表示(编码)。它们通常用于降维、特征学习和数据去噪。
自编码器(Autoencoders)是一种无监督学习的神经网络,旨在学习输入数据的有效表示(编码)。它们通常用于降维、特征学习和数据去噪等任务。自编码器由两部分组成:编码器和解码器。编码器负责将输入数据压缩成更小的维度,而解码器则尝试从这些压缩表示中重建原始数据。
自编码器的基本结构包括:
-
编码器:这部分网络将输入数据编码为一个更小的维度,通常是一个向量,称为编码或编码表示。编码过程通常涉及一系列的线性变换和非线性激活函数。
-
解码器:这部分网络接收编码表示,并尝试重建原始输入数据。解码过程通常涉及一系列的线性变换和非线性激活函数。
-
损失函数:用于量化重建数据与原始输入数据之间的差异。常见的损失函数包括均方误差(MSE)和交叉熵损失。
自编码器的关键特性是它们试图最小化重建误差,即重建数据与原始输入数据之间的差异。在训练过程中,自编码器学习如何忽略输入数据中的“噪声”,只保留重要的特征,从而实现数据的去噪和特征学习。
自编码器有多种变体,包括:
-
稀疏自编码器:通过引入稀疏性约束,迫使自编码器学习更稀疏的表示,即大部分编码表示为零或接近零。
-
去噪自编码器:通过随机 corrupt 输入数据来增加模型的鲁棒性,从而学习去除噪声并重建干净数据。
-
变分自编码器(VAEs):引入概率模型,将编码表示定义为概率分布,从而能够生成具有类似于训练数据的新数据。
自编码器在降维、特征学习和数据去噪等任务中表现出色。它们也可以作为其他复杂模型的基础组件,如深度信念网络(DBNs)和生成对抗网络(GANs)。
生成对抗网络(GANs):
由两部分组成——生成器和判别器,通过相互对抗来生成新的数据。GANs在图像生成、风格迁移等领域有广泛应用。
生成对抗网络(GANs)是一种无监督学习的框架,由两部分组成:生成器和判别器。这两部分通过相互对抗来训练,生成器负责生成新的数据,而判别器则尝试区分生成器生成的数据和真实数据。这种对抗过程使得生成器能够学习生成越来越逼真的数据,而判别器则能够更好地识别真实数据与生成数据之间的差异。
GANs的基本结构包括:
-
生成器(Generator):这部分网络接收一个随机噪声向量作为输入,并输出一个与真实数据相似的数据样本。生成器的目标是欺骗判别器,使其认为生成的数据是真实的。
-
判别器(Discriminator):这部分网络接收来自生成器或真实数据集的数据样本,并输出一个概率值,表示输入样本是真实数据的概率。判别器的目标是正确地区分真实数据和生成数据。
-
损失函数:用于量化生成器和判别器的性能。生成器的损失通常与判别器对生成数据的判断有关,而判别器的损失与正确分类真实数据和生成数据的能力有关。
GANs的关键特性是它们能够生成新的、与训练数据相似的数据样本。这使得GANs在图像生成、风格迁移、视频生成、图像超分辨率、文本到图像的合成等领域有广泛的应用。
GANs的挑战之一是训练过程中的稳定性问题。生成器和判别器之间的平衡非常重要,如果一方过于强大,另一方可能无法有效地学习。因此,许多研究致力于改进GANs的训练过程和结构,如引入条件GANs、Wasserstein GANs(WGANs)、CycleGANs等更高级的变体。
深度信念网络(DBNs):
由多个受限玻尔兹曼机(RBM)层组成,用于无监督特征学习和降维。
深度信念网络(DBNs)是一种无监督学习的深度神经网络,由多个受限玻尔兹曼机(RBM)层组成。DBNs主要用于特征学习和降维,它们能够学习输入数据的复杂分布,并提取有用的特征表示。
DBNs的基本结构包括:
-
受限玻尔兹曼机(RBM)层:RBM是一种两层的随机神经网络,包括一个可见层和一个隐藏层。可见层接收输入数据,而隐藏层用于提取特征。RBM通过调整连接权重和偏置来学习数据的概率分布。
-
堆叠结构:DBNs通过将多个RBM层堆叠在一起形成深度网络。每一层的隐藏层输出作为下一层的输入,从而形成层次化的特征学习过程。
-
无监督预训练:在DBNs的训练过程中,首先对每个RBM层进行单独的无监督预训练,以学习数据的局部特征。预训练完成后,可以使用反向传播或其他监督学习算法对整个网络进行微调。
-
特征表示:DBNs通过逐层学习,将原始输入数据转换为一个更紧凑、更有意义的特征表示。这种特征表示可以用于降维、分类、回归等任务。
DBNs的关键优势在于它们能够通过无监督学习从原始数据中自动提取特征。这使得DBNs在处理高维数据和复杂模式识别任务时非常有用。此外,DBNs的层次化特征学习过程有助于捕获数据中的层次结构和局部相关性。
随着深度学习领域的发展,DBNs虽然在某些应用中已被更先进的模型(如卷积神经网络和生成对抗网络)所取代,但它们在无监督特征学习和降维等领域仍然具有一定的应用价值。DBNs的研究和优化也为后续深度学习模型的发展奠定了基础。
转换器(Transformers):
一种基于自注意力机制的模型,尤其在自然语言处理任务中表现出色,如机器翻译、文本摘要和情感分析。
转换器(Transformers)是一种基于自注意力机制的深度学习模型,它在自然语言处理(NLP)任务中表现出色,如机器翻译、文本摘要、情感分析等。Transformers通过引入自注意力(Self-Attention)机制,能够有效地处理序列数据中的长距离依赖问题,同时提高模型的并行计算能力。
Transformers的基本结构包括:
-
自注意力机制:这是Transformers的核心,允许模型在处理每个输入时考虑到序列中的其他所有位置。自注意力机制通过计算输入序列中每个位置的加权表示来捕捉序列内的依赖关系。
-
多头注意力(Multi-Head Attention):将自注意力机制分成多个“头”,每个头关注不同的信息。然后将这些头的输出合并,以获得更丰富的表示。
-
编码器-解码器结构:Transformers通常采用编码器-解码器结构。编码器接收输入序列并生成一个连续的表示,解码器则基于编码器的输出和已生成的部分输出生成目标序列。
-
位置编码:由于Transformers不包含循环或卷积结构,因此需要位置编码来保留序列中单词的位置信息。
-
残差连接和层归一化:每个注意力层和前馈网络层后面都跟着一个残差连接和层归一化,这有助于训练深度网络。
-
前馈神经网络:在每个注意力层后面,Transformers还包括一个简单的前馈神经网络,为每个位置提供相同的作用。
Transformers的关键优势在于它们能够有效地处理长序列数据,同时保持较高的并行计算能力。这使得Transformers在处理长文本、文档、对话等自然语言处理任务时非常有效。
如今Transformers的结构也在不断发展和优化。例如,BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pre-trained Transformer)等预训练模型,通过在大规模文本语料库上预训练Transformers,然后在特定任务上进行微调,进一步提高了Transformers在各种NLP任务中的性能。此外,Transformers也在计算机视觉、音频处理等领域得到了应用。
图神经网络(GNNs):
用于处理图结构数据,如图像、社交网络和知识图谱。GNNs能够学习节点之间的关系和特征。
图神经网络(GNNs)是一种专门用于处理图结构数据的深度学习模型。与传统的深度学习模型(如卷积神经网络和循环神经网络)不同,GNNs能够直接在图结构上运行,有效地捕捉节点之间的关系和特征。这使得GNNs在处理图像、社交网络、知识图谱等具有图结构的数据时表现出色。
GNNs的基本结构包括:
-
节点表示学习:GNNs通过更新节点的表示来学习图结构数据。每个节点的表示是基于其自身的特征以及与其相连的邻居节点的特征。
-
图卷积:类似于传统卷积神经网络中的卷积操作,图卷积在图结构上进行,用于聚合节点及其邻居的信息。这可以通过各种方式实现,如谱方法、空间方法或注意力机制。
-
消息传递机制:在GNNs中,节点通过发送和接收消息来交换信息。这些消息通常是基于节点之间的连接关系和特征计算的。
-
多层结构:GNNs通常包含多个图卷积层,每一层都能够捕捉节点之间更远的关系。通过多层结构,GNNs能够学习图中的层次化特征。
-
池化操作:在某些GNN模型中,可能包括池化操作,用于减少图的大小,同时保留重要的信息。
GNNs的关键优势在于它们能够处理具有复杂关系和结构的数据。这使得GNNs在许多领域都有广泛的应用,如社交网络分析、推荐系统、生物信息学、化学信息学、知识图谱推理等。
随着研究的深入,GNNs的结构也在不断发展和优化。例如,图注意力网络(Graph Attention Networks, GATs)、图卷积网络(Graph Convolutional Networks, GCNs)、图自编码器(Graph Autoencoders)等都是GNNs的变体,它们在处理不同类型的图结构数据时具有各自的优势和应用场景。随着图数据在各个领域的广泛应用,GNNs的研究和优化也将继续扩展和深化。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









