







一、基本介绍
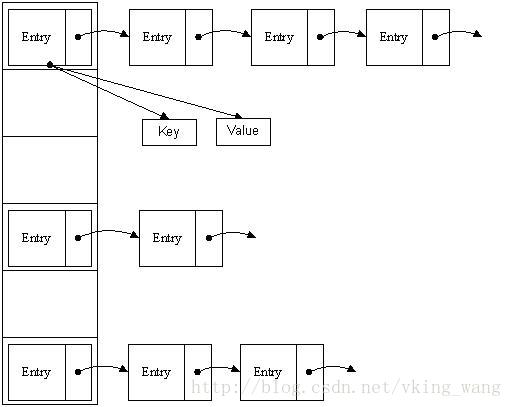
HashMap是一种基于哈希表(hash table)实现的map,哈希表(也叫关联数组)一种通用的数据结构,大多数的现代语言都原生支持,其概念也比较简单:key经过hash函数作用后得到一个槽(buckets或slots)的索引(index),槽中保存着我们想要获取的值,如下图所示:
二、哈希函数设计原理
在哈希表容量(也就是buckets或slots大小)为length的情况下,为了使每个key都能在冲突最小的情况下映射到[0,length)(注意是左闭右开区间)的索引(index)内,一般有两种做法:
让length为素数,然后用hashCode(key) mod length的方法得到索引
让length为2的指数倍,然后用hashCode(key) & (length-1)的方法得到索引
HashTable用的是方法1,HashMap用的是方法2。
/**
* Retrieve object hash code and applies a supplemental hash function to the
* result hash, which defends against poor quality hash functions. This is
* critical because HashMap uses power-of-two length hash tables, that
* otherwise encounter collisions for hashCodes that do not differ
* in lower bits. Note: Null keys always map to hash 0, thus index 0.
*/
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}首先算得key得hashcode值,然后跟数组的长度-1做一次“与”运算(&)。看上去很简单,其实比较有玄机。比如数组的长度是2的4次方,那么hashcode就会和2的4次方-1做“与”运算。很多人都有这个疑问,为什么hashmap的数组初始化大小都是2的次方大小时,hashmap的效率最高,我以2的4次方举例,来解释一下为什么数组大小为2的幂时hashmap访问的性能最高。
看下图,左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!

所以说,当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
待续。。。。。。。。。。。。。。。。















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









