










前言:对excel文件操作的封装Hutool已经很完善了。但还是有些不尽人意,本工具就是基于 Hutool的进一步封装。想让文件导出更加方便
注意:该工具使用新注解@Header表示表头,和原Hutool中的@Alias,@PropIgnore两个注解会有冲突,避免同时使用,否则会导致导出异常
-
普通文件导出
效果:

代码:
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class Simple {
@Header("ID")
private int id;
@Header("名称")
private String name;
@Header("布尔")
private boolean flag;
@Header("数量")
private double count;
}
/**
* 测试导出简单数据
*/
@Test
public void testSimple() {
File file = new File("./file/simple.xlsx");
ExcelWriter excelWriter = ExcelUtil.getWriter(file);
List<Simple> simpleList = new ArrayList<>();
for (int i = 0; i < 3; i++) {
simpleList.add(new Simple(i, "test" + i, true, i * 10));
}
DataKit.exportXlsx(excelWriter, simpleList, null);
excelWriter.close();
}-
合并表头文件导出
效果:
代码:
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class Merge {
@Header("ID")
private int id;
@Header("名称")
private String name;
@Header("布尔")
private boolean flag;
@Header({"统计", "数量1"})
private double cnt1;
@Header({"统计", "数量2"})
private double cnt2;
@Header({"统计", "数量3"})
private double cnt3;
@Header({"测试1", "测试"})
private String test1;
@Header({"测试2", "测试"})
private String test2;
@Header({"合并", "数量"})
private double val1;
@Header({"合并", "数量"})
private double val2;
} /**
* 测试导出合并头部数据
*/
@Test
public void testMerge() {
File file = new File("./file/merge.xlsx");
ExcelWriter excelWriter = ExcelUtil.getWriter(file);
List<Merge> mergeList = new ArrayList<>();
for (int i = 0; i < 3; i++) {
mergeList.add(new Merge(i, "test" + i, true, i * 10, i / 10d, i * 8, "demo" + i, "abc" + i, i / 8d, i * 5.5));
}
DataKit.exportXlsx(excelWriter, mergeList, null);
excelWriter.close();
}解析:表头值是数组,每一个下标对应一行,在同行和同列的名称如果相同将进行合并。如果有多行是,而某列数组只有一个值则向对应列合并。具体可以观察案例了解
-
携带图片文件导出
效果:

代码:
/**
* 测试导出简单数据携带图片
*/
@Test
public void testSimpleWithImg() {
File file = new File("./file/simple-img.xlsx");
ExcelWriter excelWriter = ExcelUtil.getWriter(file);
List<Simple> simpleList = new ArrayList<>();
for (int i = 0; i < 3; i++) {
simpleList.add(new Simple(i, "test" + i, true, i * 10));
}
// 加上图片路径回调,可以更加 数据内容来动态对于图片路径
DataKit.exportXlsx(excelWriter, simpleList, (simple)-> "https://www.baidu.com/img/flexible/logo/pc/result.png");
excelWriter.close();
}-
自定义排序文件导出
效果:
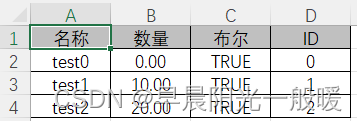
代码:
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class Order {
@Header(value = "ID", order = 3)
private int id;
@Header(value = "名称", order = 0)
private String name;
@Header(value = "布尔", order = 2)
private boolean flag;
@Header(value = "数量", order = 1)
private double count;
} /**
* 测试导出简单带排序数据
*/
@Test
public void testOrder() {
File file = new File("./file/order.xlsx");
ExcelWriter excelWriter = ExcelUtil.getWriter(file);
List<Order> orderList = new ArrayList<>();
for (int i = 0; i < 3; i++) {
orderList.add(new Order(i, "test" + i, true, i * 10));
}
DataKit.exportXlsx(excelWriter, orderList, null);
excelWriter.close();
}-
大数据分段导出
效果:
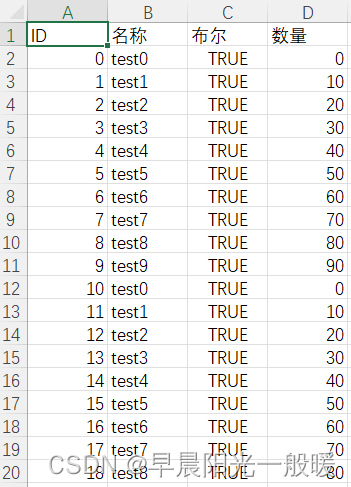
代码:
/**
* 测试使用csv文件方式,导出大量数据
*/
@Test
public void testExportBigdataToCsvByRange() {
File file = new File("./file/bigdata.csv");
// 定义开始页,
int page = 1;
// 定义每页查询的数量
int limit = 1000;
// 分段加载数据写入文件
DataKit.exportCsvByRange(file, page, limit, (p, l) -> {
if (p == 5) {
return null;
}
// 模拟数据获取,真实环境这里去查询数据库
List<Simple> simpleList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
simpleList.add(new Simple((p - 1) * 10 + i, "test" + i, true, i * 10));
}
return simpleList;
});
}源码:
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class Column {
/**
* 字段名
*/
private String key;
/**
* 排序
*/
private int order;
/**
* 元素表头
*/
private String[] headers;
/**
* 处理填充表头
*/
private String[] fullHeaders;
}
import java.lang.annotation.*;
/**
* 导出 表头注解
*/
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Header {
/**
* 表头
*
* @return 数组
*/
String[] value();
/**
* 排序
*
* @return 序值
*/
int order() default 0;
}
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class Merge {
/**
* 合并的名称
*/
private String name;
/**
* 是否做合并
*/
private boolean isMerge;
/**
* 开始列
*/
private Integer startColIndex;
/**
* 结束列
*/
private Integer endColIndex;
/**
* 开始行
*/
private Integer startRowIndex;
/**
* 结束行
*/
private Integer endRowIndex;
public Merge(String name, int x, int y) {
this.name = name;
this.isMerge = false;
this.startColIndex = x;
this.endColIndex = x;
this.startRowIndex = y;
this.endRowIndex = y;
}
/**
* 合并,判断是否符合合并且做合并动作
*
* @param name 合并名
* @param x 坐标X
* @param y 左边Y
* @return 是否合并成功
*/
public boolean merge(String name, int x, int y) {
if (name.equals(this.name)) {
boolean flag = false;
if (this.endColIndex + 1 == x) {
this.endColIndex = x;
this.isMerge = true;
flag = true;
}
if (this.endRowIndex + 1 == y) {
this.endRowIndex = y;
this.isMerge = true;
flag = true;
}
return flag;
}
return false;
}
}import java.util.List;
/**
* 函数式接口,处理导出数据
*
* @param <T>
* @param <P>
* @param <L>
*/
@FunctionalInterface
public interface ResultFun<T, P, L> {
List<T> result(P p, L l);
}
import cn.hutool.core.bean.BeanUtil;
import cn.hutool.core.collection.CollUtil;
import cn.hutool.core.date.DatePattern;
import cn.hutool.core.date.DateUtil;
import cn.hutool.core.io.FileUtil;
import cn.hutool.core.util.ArrayUtil;
import cn.hutool.core.util.ReflectUtil;
import cn.hutool.core.util.URLUtil;
import cn.hutool.http.HttpUtil;
import cn.hutool.poi.excel.ExcelUtil;
import cn.hutool.poi.excel.ExcelWriter;
import cn.hutool.poi.excel.cell.CellUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Workbook;
import pers.lzy.datakit.util.export.Column;
import pers.lzy.datakit.util.export.Header;
import pers.lzy.datakit.util.export.Merge;
import pers.lzy.datakit.util.export.ResultFun;
import javax.servlet.http.HttpServletResponse;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.lang.reflect.Field;
import java.net.URLEncoder;
import java.time.LocalDateTime;
import java.util.*;
import java.util.function.Function;
import java.util.stream.Collectors;
/**
* 数据处理工具
*
* @author lzy
* @date 2021/9/23 9:34
*/
@Slf4j
@SuppressWarnings({"unused", "SimplifyStreamApiCallChains"})
public class DataKit {
private DataKit() {
}
/**
* 设置单元格
*
* @param excelWriter excel写入对象
* @param x x
* @param y x
* @param text 内容
* @param isHeader 头
*/
public static void setCell(ExcelWriter excelWriter, int x, int y, Object text, boolean isHeader) {
Row row = excelWriter.getOrCreateRow(y);
Cell cell = CellUtil.getOrCreateCell(row, x);
CellUtil.setCellValue(cell, text, excelWriter.getStyleSet(), isHeader);
}
// --------------------------------------------------------------------------------------------------------------------
/**
* 导出 excel,不适合导出大文件
*
* @param response 响应对象
* @param fileName 文件名
* @param data 数据
* @throws Exception 异常
*/
public static <T> void exportXlsx(HttpServletResponse response, String fileName, List<T> data) throws Exception {
exportXlsx(response, fileName, data, null);
}
/**
* 导出 excel ,不适合导出大文件
*
* @param response 响应对象
* @param fileName 文件名
* @param data 数据
* @param urlOrPathFun 回调,处理返回请求服务URL,或文件路径,携带一个数据对象参数
* @throws Exception 异常
*/
public static <T> void exportXlsx(HttpServletResponse response, String fileName, List<T> data,
Function<T, String> urlOrPathFun) throws Exception {
try (
OutputStream outputStream = response.getOutputStream();
ExcelWriter excelWriter = ExcelUtil.getBigWriter()
) {
fileName = URLEncoder.encode(fileName, "UTF-8") + "-" + DateUtil.format(LocalDateTime.now(), DatePattern.PURE_DATETIME_PATTERN) + ".xlsx";
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet;charset=utf-8");
response.setHeader("Content-Disposition", "attachment;filename=" + fileName);
exportXlsx(excelWriter, data, urlOrPathFun);
excelWriter.flush(outputStream, true);
} catch (Exception e) {
throw new Exception("导出异常:" + e.getMessage());
}
}
/**
* 导出 excel ,不适合导出大文件
*
* @param excelWriter excel写入对象
* @param data 数据
* @param urlOrPathFun 回调,处理返回请求服务URL,或文件路径,携带一个数据对象参数
* @throws Exception 异常
*/
public static <T> void exportXlsx(ExcelWriter excelWriter, List<T> data, Function<T, String> urlOrPathFun) throws Exception {
if (CollUtil.isNotEmpty(data)) {
//图片的列下标
int imgColIndex = 0;
List<Column> columnList = getColumnList(data.get(0).getClass());
int rowCnt = columnList.get(0).getFullHeaders().length;
for (int i = 0; i < data.size(); i++) {
if (i == 0) {
fullHeader(excelWriter, columnList);
if (urlOrPathFun != null) {
imgColIndex = columnList.size();
// 设置头像的表格header
if (rowCnt == 1) {
DataKit.setCell(excelWriter, imgColIndex, 0, "图片", true);
} else {
excelWriter.merge(0, rowCnt - 1, imgColIndex, imgColIndex, "图片", true);
}
excelWriter.setColumnWidth(imgColIndex, 5);
}
}
Map<String, Object> map = BeanUtil.beanToMap(data.get(i), new LinkedHashMap<>(), false, false);
for (int j = 0; j < columnList.size(); j++) {
excelWriter.writeCellValue(j, i + rowCnt, map.get(columnList.get(j).getKey()));
}
if (urlOrPathFun != null) {
putImgToExcel(excelWriter, imgColIndex, i + (rowCnt == 1 ? 0 : rowCnt - 1), urlOrPathFun.apply(data.get(i)));
}
}
}
}
private static void putImgToExcel(ExcelWriter excelWriter, int colIndex, int rowIndex, String urlOrPath) {
try {
excelWriter.setRowHeight(rowIndex + 1, 30);
//获取文件
byte[] imgBytes;
if (HttpUtil.isHttp(urlOrPath) || HttpUtil.isHttps(urlOrPath)) {
imgBytes = HttpUtil.downloadBytes(URLUtil.normalize(urlOrPath, true));
} else {
imgBytes = FileUtil.readBytes(new File(urlOrPath));
}
//获取图片在表格中的悬浮位置和尺寸
excelWriter.writeImg(imgBytes, Workbook.PICTURE_TYPE_JPEG, 0, 0, 1, 1,
colIndex, rowIndex + 1, colIndex + 1, rowIndex + 2);
// //获取图片在表格中的悬浮位置和尺寸
// XSSFClientAnchor anchor = new XSSFClientAnchor(0, 0, 1, 1,
// colIndex, rowIndex + 1, colIndex + 1, rowIndex + 2);
// //添加头像图片
// excelWriter.getSheet().createDrawingPatriarch()
// .createPicture(anchor, excelWriter.getWorkbook().addPicture(imgBytes, Workbook.PICTURE_TYPE_JPEG));
} catch (Exception e) {
log.error(e.getMessage());
}
}
// --------------------------------------------------------------------------------------------------------------------
/**
* 导出CSV文件,使用分段式,减少内存的使用,大量数据时建议使用该方式
*
* @param response 响应对象
* @param fileName 文件名,默认拼接当前时间,和文件后缀
* @param resultFun 回调,数据回调,参数:页、页数。如果数据为空则会结束渲染数据
* @throws Exception 异常
*/
public static <T> void exportCsvByRange(HttpServletResponse response, String fileName,
ResultFun<T, Integer, Integer> resultFun) throws Exception {
int page = 1;
int limit = 10000;
exportCsvByRange(response, fileName, page, limit, resultFun);
}
/**
* 导出CSV文件,使用分段式,减少内存的使用,大量数据时建议使用该方式
*
* @param response 响应对象
* @param fileName 文件名,默认拼接当前时间,和文件后缀
* @param page 页
* @param limit 页数
* @param resultFun 回调,数据回调,参数:页、页数。如果数据为空则会结束渲染数据
* @throws Exception 异常
*/
public static <T> void exportCsvByRange(HttpServletResponse response, String fileName,
int page, int limit, ResultFun<T, Integer, Integer> resultFun) throws Exception {
try (
OutputStream outputStream = response.getOutputStream()
) {
fileName = URLEncoder.encode(fileName, "UTF-8") + "-" + DateUtil.format(LocalDateTime.now(), DatePattern.PURE_DATETIME_PATTERN) + ".csv";
response.setContentType("application/octet-stream;charset=utf-8");
response.setHeader("Content-Disposition", "attachment;filename=" + fileName);
reExportCsv(outputStream, page, limit, resultFun);
outputStream.flush();
} catch (Exception e) {
throw new Exception("导出异常:" + e.getMessage());
}
}
/**
* 导出CSV文件,使用分段式,减少内存的使用,大量数据时建议使用该方式
*
* @param file 导出文件
* @param resultFun 回调,数据回调,参数:页、页数。如果数据为空则会结束渲染数据
* @throws Exception 异常
*/
public static <T> void exportCsvByRange(File file, ResultFun<T, Integer, Integer> resultFun) throws Exception {
int page = 1;
int limit = 10000;
exportCsvByRange(file, page, limit, resultFun);
}
/**
* 导出CSV文件,使用分段式,减少内存的使用,大量数据时建议使用该方式
*
* @param file 导出文件
* @param page 页
* @param limit 页数
* @param resultFun 回调,数据回调,参数:页、页数。如果数据为空则会结束渲染数据
* @throws Exception 异常
*/
public static <T> void exportCsvByRange(File file, int page, int limit, ResultFun<T, Integer, Integer> resultFun) throws Exception {
try (
OutputStream outputStream = new FileOutputStream(file);
) {
reExportCsv(outputStream, page, limit, resultFun);
outputStream.flush();
} catch (Exception e) {
throw new Exception("导出异常:" + e.getMessage());
}
}
/**
* 导出CSV文件,使用分段式,减少内存的使用,大量数据时建议使用该方式
*
* @param page 页
* @param limit 页数
* @param resultFun 回调,数据回调,参数:页、页数。如果数据为空则会结束渲染数据
* @param outputStream 输出流
* @throws Exception 异常
*/
private static <T> void reExportCsv(OutputStream outputStream, int page, int limit, ResultFun<T, Integer, Integer> resultFun
) throws IOException {
List<T> list = resultFun.result(page, limit);
if (CollUtil.isNotEmpty(list)) {
List<Column> columnList = getColumnList(list.get(0).getClass());
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < list.size(); i++) {
if (page == 1 && i == 0) {
String strHeader = columnList.stream().map(column ->
ArrayUtil.join(column.getHeaders(), "-")
.replace(",", ",")
).collect(Collectors.joining(","));
outputStream.write((strHeader + "\r\n").getBytes("gbk"));
outputStream.flush();
}
Map<String, Object> map = BeanUtil.beanToMap(list.get(i), new LinkedHashMap<>(), false, false);
String strLine = columnList.stream()
.map(column -> Objects.toString(map.get(column.getKey()), "")
// 处理特殊内容,避免数据出现多列,异常列
.replace(",", ",")
// 处理数据内容,避免数据出现多行,异常行
.replaceAll("[\\r\\n]", " ")
)
.collect(Collectors.joining(","));
stringBuilder.append(strLine).append("\r\n");
}
outputStream.write(stringBuilder.toString().getBytes("gbk"));
// 非常注意,这里使用了递归,相关变量的引用必须置空,垃圾回收才检测到,否则一直存活导致内存泄漏
columnList = null;
list = null;
stringBuilder = null;
reExportCsv(outputStream, ++page, limit, resultFun);
}
}
// --------------------------------------------------------------------------------------------------------------------
/**
* 通过类类型获取列,根据 @Header 判断
*
* @param beanClass 类类型
* @return 列
*/
private static List<Column> getColumnList(Class<?> beanClass) {
// 获取所有字段
Field[] fields = ReflectUtil.getFields(beanClass, field -> field.getAnnotation(Header.class) != null);
int rowCnt = 1;
List<Column> columnList = new ArrayList<>();
for (int i = 0; i < fields.length; i++) {
Header header = fields[i].getAnnotation(Header.class);
columnList.add(
Column.builder()
.key(fields[i].getName())
.order(header.order() == 0 ? -(fields.length - i) : header.order())
.headers(header.value())
.build()
);
if (header.value().length > rowCnt) {
rowCnt = header.value().length;
}
}
// 处理表头,进行排序
int finalRowCnt = rowCnt;
columnList = columnList.stream()
.map(column -> {
String[] headers = column.getHeaders();
if (headers.length != finalRowCnt) {
String[] newHeaders = new String[finalRowCnt];
System.arraycopy(headers, 0, newHeaders, 0, headers.length);
for (int i = headers.length; i < finalRowCnt; i++) {
newHeaders[i] = headers[headers.length - 1];
}
column.setFullHeaders(newHeaders);
} else {
column.setFullHeaders(headers);
}
return column;
})
.sorted(Comparator.comparingInt(Column::getOrder)).collect(Collectors.toList());
return columnList;
}
/**
* 填充表头
*
* @param writer excel写入对象
* @param columnList 列
*/
private static void fullHeader(ExcelWriter writer, List<Column> columnList) {
List<Merge> mergeList = new ArrayList<>();
for (int i = 0; i < columnList.size(); i++) {
String[] fullHeaders = columnList.get(i).getFullHeaders();
for (int j = 0; j < fullHeaders.length; j++) {
// 逐个插入表头
DataKit.setCell(writer, i, j, fullHeaders[j], true);
DataKit.setCell(writer, i, j, fullHeaders[j], true);
// 判断获取合并的坐标
if (CollUtil.isEmpty(mergeList)) {
mergeList.add(new Merge(fullHeaders[j], i, j));
} else {
final int x = i, y = j;
Optional<Boolean> optionalBoolean = mergeList.stream()
.map(merge -> merge.merge(fullHeaders[y], x, y))
.filter(Boolean::booleanValue)
.findFirst();
if (!optionalBoolean.isPresent()) {
mergeList.add(new Merge(fullHeaders[j], i, j));
}
}
}
}
// 合并表头
for (Merge merge : mergeList) {
if (merge.isMerge()) {
writer.merge(merge.getStartRowIndex(), merge.getEndRowIndex(), merge.getStartColIndex(), merge.getEndColIndex(), null, true);
}
}
// 跳到非表头行
if (CollUtil.isNotEmpty(columnList)) {
writer.setCurrentRow(columnList.get(0).getFullHeaders().length);
}
}
}















 4940
4940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









