






目录:
1. 内存结构
2 .指针
3. 字符串处理
4. 裢表
5. 复习大纲中的一些知识点理解
1、 内存结构
这是核心中的核心,请仔细看完,充分理解,否则请不要看下一节内容。
每个程序一启动都有一个大小为4GB的内存,这个内存叫虚拟内存,是概念上的,真正能用到的,只是很小一部分,一般也就是在几百K到几百M。我们PC中内存,我们称之为物理内存,也就是256M,512M等,虚拟内存和物理内存的如何转换是由操作系统完成的,我们不需要管它。我们只需要管好我们自己程序的那4GB内存就可以了。
要管理4GB的虚拟内存,就必须给每个字节分配一个号码,以便程序与访问到其中任何一个字节。这个号码是从0开始顺序递增的,针对于这个号码我们就称之为地址,从0x00000000-0xFFFFFFFF,这样,我们理论上就可以访问其中内存中任何一个字节了。但有一点请注意,系统并不让我们全部都可以用。其中后面2GB的内容是留给系统用的,用户是不可以访问的,而且在前面的2GB也有部分区段不能访问,比如0x00000000就不能访问。具体是哪些区段,不必关心。
注意:类似于0x12345678或12345678H是10进制数305419896的16进制表示法,他们是一回事,显示16进制是为了方便显示及计算机计算。
程序都是用来做一些具体的事情,不管做什么事,结构都是很相似。程序启动,就有4GB的虚拟内存,通过CPU的计算,改变内存的内容,最后再复制内存的内容输出,输出的目的地可以是:屏幕、文件、磁盘等外存、端口、网络等。如何输出呢,最后全部都是调用系统的API,由操作系统完成。(这段话,请仔细体会,并牢牢记住)
所以我们的核心问题就是:如何控制内存,让内存里的值,变成我们想要的结果。
注意:这里的控制,指读取或写入某段内存的内容。
在虚拟内存中,我们一般将其分为4个区域:
栈(stack)
堆(heap)
静态区域(static)
数据区域(data)
注意:不同的资料可能到具体的分法,有所不同,但大体上就是这样,我也是这样理解的。如下图:
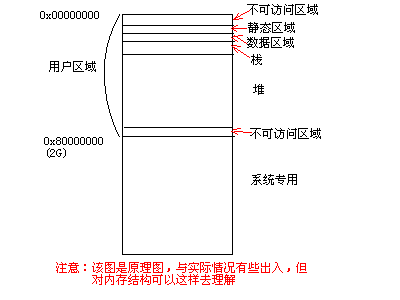
有兴趣的话,可以参考《Windows核心编程》第三版,里面有详细的论述。
栈
任何除静态外的变量,数组等。都是被分配到栈中的。这些变量类似于:
int x;
char c;
char s[10];
整个程序中,栈的区域是一个连续的区域,其大小在VC6.0中,是1M。这个栈的特点有点类似于我们以前学过的数据结构课程中的堆栈,都是后进先出。如何理解呢?看下面的程序:
#include <stdio.h>
void ExecuteOtherCode()
{
/*
...
*/
}
void TestStack1()
{
int a = 1;
int b = 2;
ExecuteOtherCode();
}
void TestStack2()
{
int c = 3;
int d = 4;
ExecuteOtherCode();
}
void main()
{
TestStack1();
TestStack2();
}
栈的处理在VC6中是从高地址到低地址。执行该程序,运行函数到TestStack1,其中定义一个变量a,此时a就是在栈中分配一段大小为sizeof(int)的内存空间。比如a的地址&a的值就为0x0012ff28,由于a是int型的数据,其占用内存的大小为4B(其详细介绍参见稍后的注意)。所以b地址为0x0012ff24,这两个内存的分配过程我们称之为“入栈”。见下图:
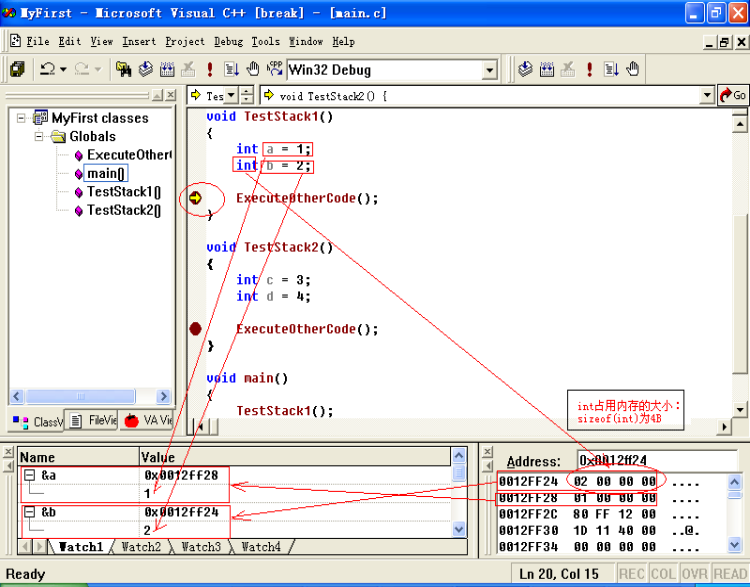
TestStack1结束后,系统则先收回b的空间,再收加a空间,这个过程我们叫“出栈”。即0x0012ff28到0x0012ff28-2*4这段空间的内容不再有用了,即使其值还没有变化。接着再运行到TestStack2函数,也定义了两个int变量c,d,同样进行入栈操作,这样c,d很“可能”就占用了原来a,b的空间,见下图:
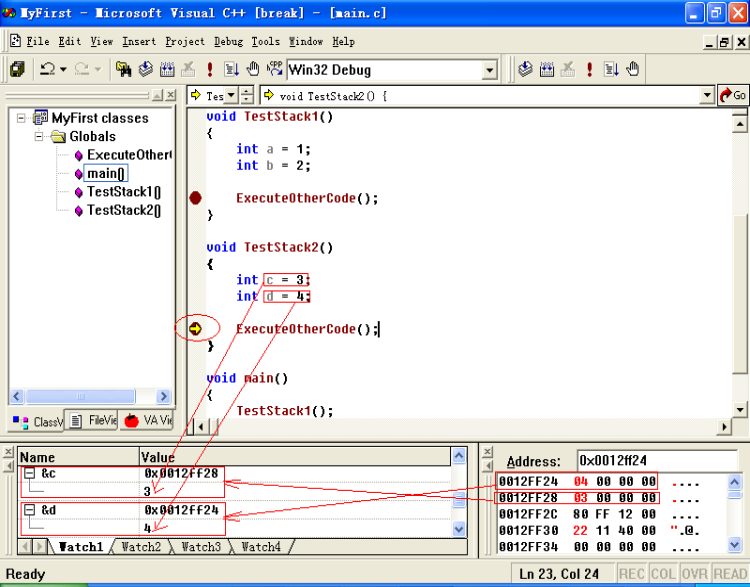
这里用到“可能”两个字,是因为实际栈中存放着不仅仅是这些变量,包括函数的指针等也是存放在栈中,这样就会造成两个类似函数中的变量所占据的内存空间不一样。
注意:计算占用内存空间的大小,可以用sizeof(x)表示,其中x可以是变量,指针,数组,以及各种类型名等,其返回值为整形数值。每一种类型占用多大空间,这个要特别注意,在我们平常的32位普通PC机中,常见的有:
char
1B
short
2B
int
4B
long
4B
float
4B
double
8B
任何类型的指针均为 4B,它正好能指向全部4G的虚拟内存,2的32次方为4G。
数组:
int arr[10];
表示10个连续的int类型的内存区域。
则sizeof(arr)的值为10* sizeof(int),就是40B
这些内置的int等类型,默认都是指有符号的,即可以赋值为负数。如果是定义成无符号的,如
unsigned int x;
则sizeof(x)还是4B,有无符号,在占用内存空间的大小上是一样的。其它的也是如此。
结构
struct A
{
int x;
int y;
};
A mystruct;
表示声明有一个结构类型A,其中有两个int类型的成员,定义该类型一个对象mystruct。则
sizeof(mystruct)就是sizeof(mystruct.x)+sizeof(mystruct y),即sizeof(int) + sizeof(int),即8B
这些类型的大小,对理解内存中数据结构,很有帮助,请记住。
栈有入栈和出栈,当程序运行到一个函数中,依次将函数中定义的变量入栈,运行完该函数,然后按相反的顺序出栈,这些都是系统自动完成的,我们不用管,知道原理就行了。所以这些变量都是临时,一量出了函数,我们都不能用它。事实上,差不多一切临时的数据都被分配到栈中。
堆
堆是相对于栈的,前面说到栈的大小大概为1MB,而用户能用到的内存大概有2GB,因此除了少量的数据区域和静态区域,以及这2G中被小部分限制的区域处,剩余都是堆的空间,其大小还是接近2G。(接近2G,是我的理解,没有在其它书中看到类似的结论,说错了,你别笑话我。)
堆主要有两个作用:
1、 欲分配内存空间的大小,或称长度,可以是变量,这意味着这个大小,在分配前,可以随着环境的改变而改变,不要求是定值。注意,这里说的是“分配前”,在分配完了以后,这段内存的大小理论上还是不可以改大小的,除非释放掉或用一些特别的方法。
2、 可以分配比较大的空间。
堆分配内存,主要通过函数malloc(),释放用free()。比如:
#include <stdlib.h> /* 要加上该头文件 */
int size = 10*sizeof(int);
int* pInt = (int*)malloc(size);
表示在堆中,分配长度为size的内存,将分配到的那段内存,标识成一系列int型数据,并将这段内存的地址,赋值给一个int型指针pInt,这样,通过pInt就可以控制这段内存了。
我们知道在栈中,可以通过数组,也能达上述的效果,如下:
int arr[10];
他们是有区别的:
1、 在效率上,前者(指pInt那段内存)是通过系统在整个堆空间中搜索到一段合适的内存,然后把这段内存分配给pInt,而后者只是在临近的位置分配这样大小的内存,这样少了搜索过程,后者显示效率高得多。
2、 在大小上,前者总共能分配的内存接近2GB,可以说很大了,而后者,其栈总的大小才1MB,所以其分配的大小不可能超过1MB,确切来说,是不能超过1M-分配前栈的大小。换句话说,如果要分配的空间超过1M的话,只能选择前者。
3、 在作用范围上,前者的内存地址可以用一个指针表示,假如这个指针是全局变量的话,则一直可以控制这块内存了,事实上,只要这块内存不被释放,那么在程序任何地方,它只要知道该内存的地址,则可以控制它。后者在退出函数或其作用域后,该段内存就被收回了。
4、 在“3、”中,似乎感觉堆很好,但隐藏了一个重要的麻烦,那就是内存释放,因为堆的内存释放是需要手工进行的。如果一不小心,用完后,我忘记释放,那么结果会怎样呢?事实上这段内存则不会被再用到,直到程序结束,比如我申请了200M的内存,没释放,这种浪费还是很可观的。
针对于他们的区别,我们可以有一个结论:
同时满足:临时性,小的(不超过1M),更快的内存分配用栈,(其实第3条“更快”由于现代机器够快,两种方式都会满足),否则用堆。
这些是栈和堆的区别,在实际工作中非常重要,请充分理解,不理解的话就背下来,这在面试时会经常考到。
如果堆分配不成功的话,则返回NULL。
前面说过,针对于某段在堆中分配的内存,如果不再需要使用了,则应该释放。这个释放用free();
如下:
int* pInt = (int*)malloc(size);
/* 针对于pInt做一些操作 */
free(pInt);
静态区域:
该区域主要存储全局变量和静态变量。该区域内存储的变量在程序的整个运行期间都存在,不会像栈那样,运行完某个函数,该函数内定义的普通变量就被弹出栈,其地址空间就会被收回,也不像那堆那样,用free就被系统收回。
所以定义了一个全局变量或静态变量,其存储在内存中那块区域,是自程序启动到程序结束前都是固定的,不会有别的变量占用这块内存。
全局变量:只要在任何一个函数外声明的变量就是全局变量,在任何地方都可以被访问到。
静态变量:
声明类似于如下:
static int static_value = 0;
1、 最前面一定要static,表明它是静态变量.
2、 一定要赋值初值,实际上这个赋值过程是在程序一启动时,就运行了,而不是在进入到某个函数时,才执行。
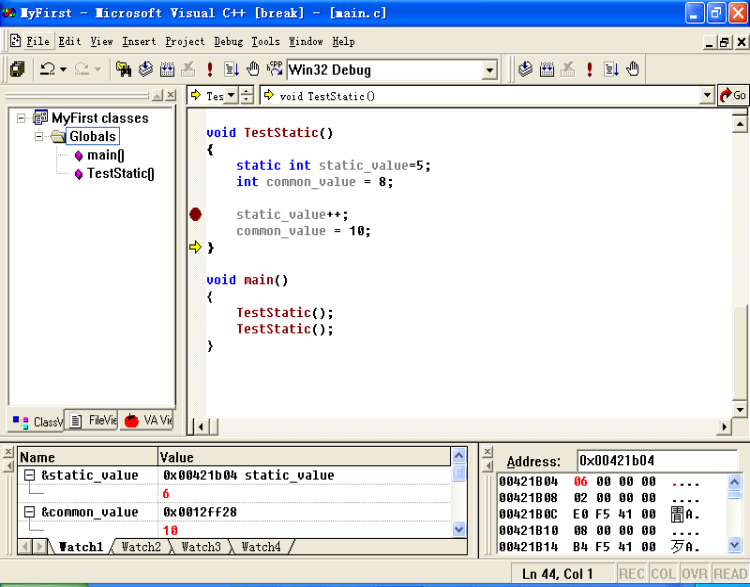
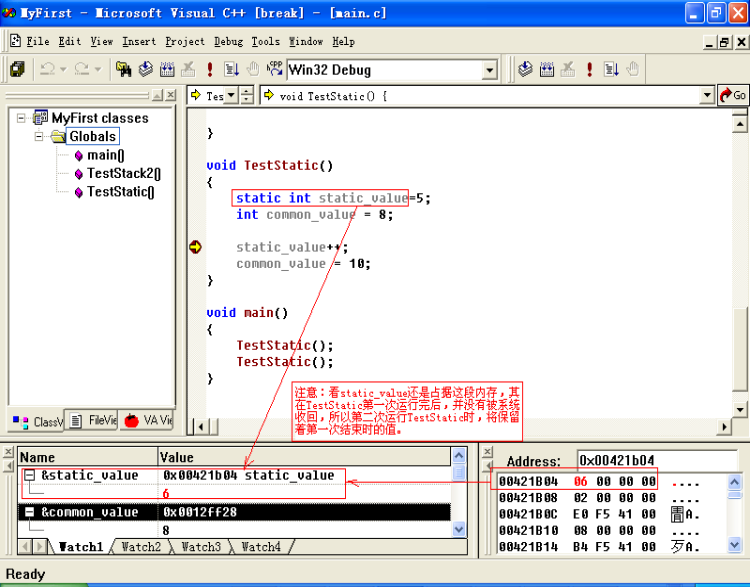
其实我们可以这样认为:静态变量就是全局变量,只是其访问的范围比较有限,只能在定义它的函数中访问。见如下程序:
void TestStatic()
{
static int i=5;
i++;
}
void main()
{
TestStatic();
TestStatic();
}
运行第一个TestStatic时。
其变化如图所示:
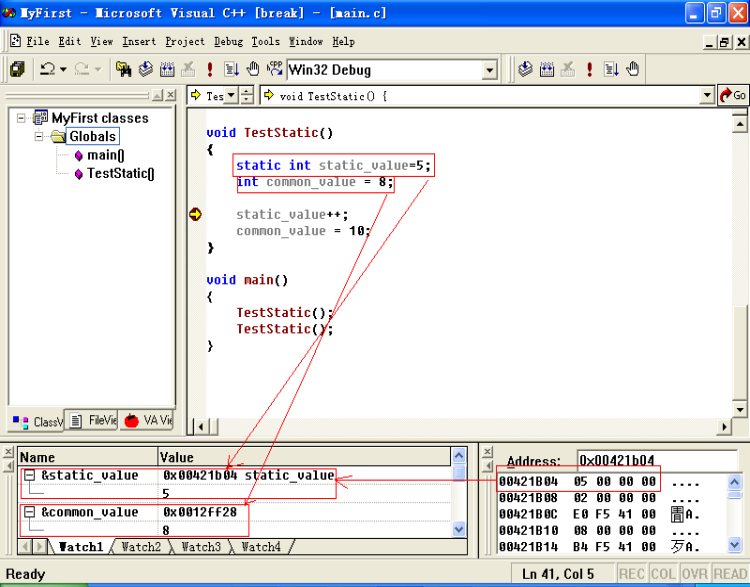
运行第二个TestStatic()时,如图所示:
数据区域:
一些存储常量的地方:比如:
char* p = “abcdefg”;
这里p也是有值的,不过一般都不会这么写。正确的方法是
char p[] = “abcdefg”;
常用操作内存的库函数:
要控制内存,主要有复制、设值、比较等操作,共对应库函数如下:
1、复制
void *memcpy( void *
dest
, const void *
src
, size_t
count
);
表示将地址为src,长度为count的一段内存上的内容,复制到地址为dest开始的一段内存中。
2、比较
int memcmp( const void *
buf1
, const void *
buf2
, size_t
count
);
表示将以buf1开始的内存和以buf2开始的两段内存相互比较,要比较的长度为count,返回值>0,表示
buf1大,<0表示
buf2的,==0,则表示这两段内存的内存相同。

1 #include < string .h >
2 #include < stdio.h >
3 int main( void ){
4 char first[] = " 12345678901234567890 " ;
5 char second[] = " 12345678901234567891 " ;
6 int int_arr1[] = { 1 , 2 , 3 , 4 };
7 int int_arr2[] = { 1 , 2 , 3 , 4 };
8 int result;
9 printf( " Compare '%.19s' to '%.19s':\n " , first, second );
10 result = memcmp( first, second, 19 );
11 if ( result < 0 )
12 printf( " First is less than second.\n " );
13 else if ( result == 0 )
14 printf( " First is equal to second.\n " );
15 else printf( " First is greater than second.\n " );
16 printf( " Compare '%d,%d' to '%d,%d':\n " , int_arr1[ 0 ], int_arr1[ 1 ], int_arr2[ 0 ], int_arr2[ 1 ]);
17 result = memcmp( int_arr1, int_arr2, sizeof ( int ) * 2 );
18 if ( result < 0 )
19 printf( " int_arr1 is less than int_arr2.\n " );
20 else if ( result == 0 )
21 printf( " int_arr1 is equal to int_arr2.\n " );
22 else printf( " int_arr1 is greater than int_arr2.\n " );
23 }
3、设值
void *memset( void *
dest
, int
c
, size_t
count
);
表示将内存
dest,大小为count的一段内存的每个字节,全部赋值为c。一般来说,该函数用来清0。即
memset(buffer, 0, buffer_size);
这几个库函数在memory.h中声明,如果编译器提示找不到这些函数,则要include它。
内存结构知道这么多,已经差不多了。这部分内容,请仔细体会。
2、指针
前面已经说过,内存都有地址编号的,这个地址编号是从0x00000000到0xFFFFFFFF,这样我们知道了某一个地址就可以访问这段内存,以此思路,如果我们定义了一个整型变量,再将一个具体的地址编号赋值给它,是否利用这个整型变量就可以访问该段内存呢?
答案是肯定的,但一般我们不这样做,在C语言中,引进了一个专业名词:指针
指针有两个方面的属性:
1、 指针的值就是地址编号。
2、 指针是有类型的。
对于1、的理解,你可以把指针想像成整型变量,事实上,指针的确可以和整型变量互换,比如:
char* p = (char*)(5);
int i = (int)p;
如图:
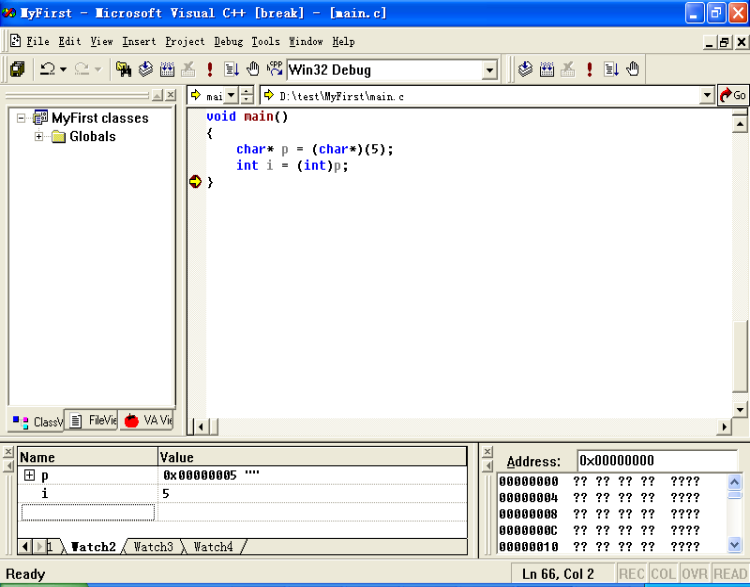
但不建议你这样做,除非,对内存已经很熟了,事实上开始地址为0x00000005的一段内存是不可以被访问的。
对于2、的理解,我们可以这样认为:描述一段内存,则必须指明其开始地址,及长度。这个指针类型,就是表示这段内存有多长,及这段内存到底是干什么用的,比如:
int vlaue = 1234;
int* p = &value;
可以这样理解p:它就是指向value所在那段内存,长度为sizeof(int),这段内存就表示一个int类型的值。
既然指针同整型变量类似,那么指针本身所占内存也是可以确定的,它的值范围在0-4G,所以用4B就够了。的确,在C语言中,32位普通PC上,任何指针都是大小都是4,比如:
char* p1;
int* p2;
struct A
{
int x;
int y;
}
A* p4;
那么
sizeof(p1)、sizeof(p2)、sizeof(p3)的值都是4B,
但
sizeof(*p1)、sizeof(*p2)、sizeof(*p3)的值应该等同于
sizeof(char)、sizeof(int)、sizeof(struct A)
/* 结构体类型应用时,要在其前面加struct */
即 1, 4, 8
这里有一点请注意:
结构A的大小,一般认为就是其成员x,y的大小之和。但有时候情况比较特殊,如
struct B
{
int x;
int y;
char z;
};
此时
sizeof(B)不是9,而是12,这是由于编译器为了考虑效率的问题,一般要将内存对齐,所以一个类型的大小通常是4或8的整数倍。这种内存对齐机制可以在编译器中设置。
这种对齐机制不要求掌握,知道有这么回事就行,面试时有可能会被问到。所以提一下。
看到这里,你应该能理解,指针其实就是一个变量,只是这个变量的值就是内存地址而已。我们知道普通变量是保存到栈中的,那么指针本身也将是保存到栈中,也是可以取地址的,甚至其地址也可以被赋值给另一个指针,这称之为指向指针的指针,比较有趣吧。
比如:
void main()
{
int i=5;
int* p = &i;
int** p2 = &p;
}
由此也可以体会指针和引用的区别
在栈中定义一个变量i,比如其地址为0x0012ff7c,大小为sizeof(int)(即4B),那么其下一个“变量”p的地址就是0x0012ff7c-4即0x0012ff78,只是这个地址存放着一个指针,该指针的值为0x0012ff7c,下面又是一个指针,其值为0x0012ff78。如图:
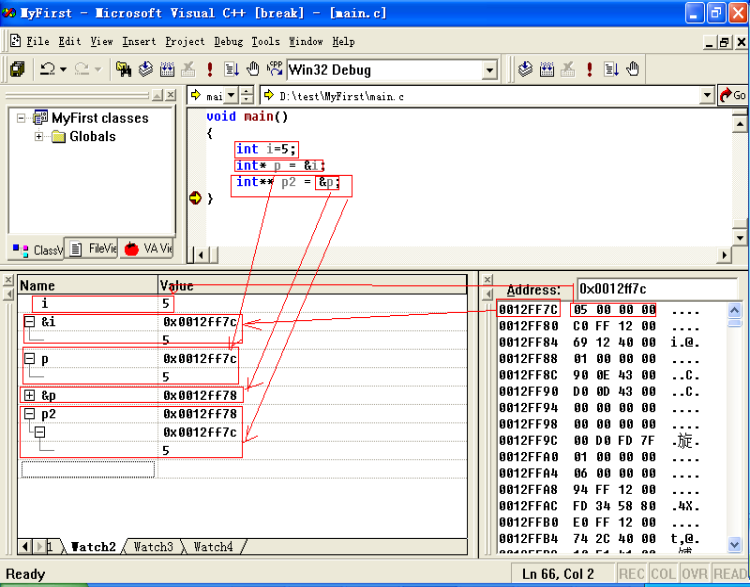
对指针的理解就是,指针就是指向内存地址,这块内存存放的内容可以是任何东西,甚至还是一个指针。
当然指向指针的指针是一个相对比较高级的话题,不理解也没关系。
前面说到,指针是有类型的,但有的时候,我们不知道其类型是什么,或者只要求知道开始的内存地址就行了,可以这样定义指针:
void* p;
表示有一个指针,它可以指向某段内存,但不知这段内存具体表示什么,也不知道其长度,即:
sizeof(*p)是无效的。
如果想要其长度,则应该另外再带上一个变量。前面的对内存操作的库函数,就是属于这种机制。
针对void*的指针有这样的特点:
void*类型的指针,可以被任何其它类型的指针赋值,比如:
int i = 5;
int* p1 = &i;
void* p2 = p1;
注意:
1、void如用于函数定义时,表示如下:
void fun(void)
{
/*
…
*/
}
表示有一个函数,没有参数,也没有返回值。其中表示没有参数时,也可以省略void。
2、因为void没有类型,不知道占用空间的大小,所以不能定义成变量,只能作为指针的类型。
我们是否可以引申一下,要定义成变量的,其类型必须明确大小。(这是我自己的理解,未在其它书中看到类似的结论)
3、字符串处理
这是一个大家经常遇到,但又似懂非懂的主题。这里面有几个概念如下:
(1)、字符变量
(2)、字符指针
(3)、字符数组
(4)、字符串
电脑是外国人发明的,开始时他们需要显示在屏幕上字符只是字母、数字及一些标点符号,把这些字符全部加在一起,也只有100来个(哪有我们汉字,这样博大精深啊)。由于计算机都由二进制数字组成,这样,他们就规定类似于0代表A,1代表B…之类的编码规则。后来这个编码规则形成一个统一的标准,我们称之为ASCII码。
ASCII表格:

这样,字符就是和0x00-0xFF中的整数值相应,所以在C语言中,干脆把两者看成一回事。
int i = ‘a’;
char c = 0x41;
这都没问题,i的值为0x61,c的值是’A’,之所以可以这样做,是因为它们的存储方式都是一样的。如图:
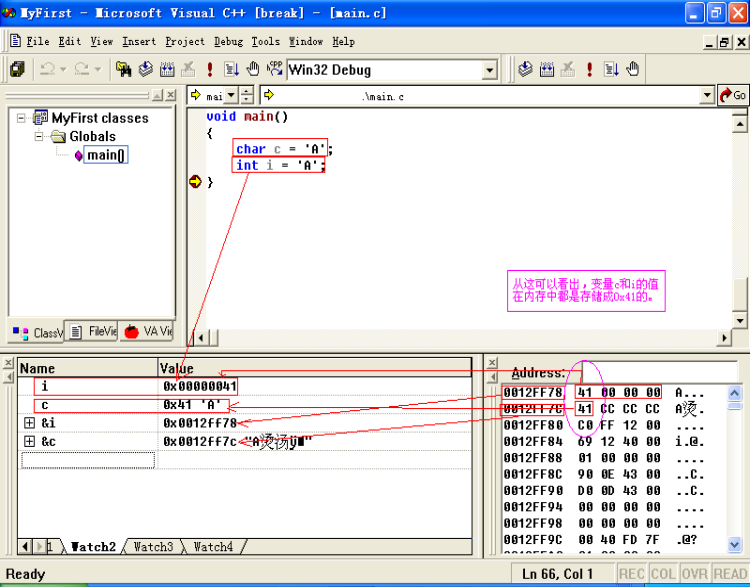
既然字符和0到127的数据是一回事,那么
1 + ‘2’的值为’3’
‘a’ + 3的值为’d’
也应该好理解了。
一个有符号位的字节能表示的大小为-128-127,所以在ASCII中,用一个字节就可以表示字符了。也就是说一个ASCII码的字符占用内存空间为1B。
一般处理字符,不可能是单个字符,而是多个字符的组合,在C语言中,称之为字符串。字符串有许多字符组成,但到底有多少个呢?在C中规定,字符串是以0结尾的,这个0是指ASCII值为0的那个字符,即NULL。比如,
字符串: “abc”
在内存中就是这样存储
61 62 63 00
/* 这里的值都是16进制 */
字符串,是许多字符连续排序在一起的。因此,可以用数组表示:
char buffer[256];
这表示定义了一个256个元素的数组,元素的类型为char型,所以该数组占用空间为256*sizeof(char),即256B
这称之为字符数组。有时定义时,可以初使化一下:
char buffer[256] = {0};
表示将buffer中每个元素的值都设置为0。
char buffer[] = “abc”;
表示将字符串”abc”连同结束符0,都赋值给buffer,即此时,sizeof(buffer)为4B
对字符串的处理,有时需要定位于一个具体的字符,用相应的指针可能更灵活,于是可以定义一个字符指针:
char* p = buffer;
表示定义一个字符指针,让其指向数组buffer的地址。
字符指针除了方便定位于每一个字符外,还有一个用途是,可以很方便地作为函数参数传递。
处理字符串主要用的函数有:
size_t strlen( const char *
string
);
表示取字符串的长度,即字符数
注意:
const:表示不改变此字符串的内容。
函数认为string是以0结尾的。
size_t不同的编译器定义可能不一样,但一般都是unsigned int类型。
有如下程序:
char str = “abc”;
sizeof(str)的值为4,见前面说明。
但strlen(str)为3,说明strlen计算时,不包括结束符0
char *strcpy( char *
strDestination
, const char *
strSource
);
将
strSource字符串的内容复制到
strDestination中去
注意:该函数假定字符串
strDestination有足够的空间容纳
strSource中的内容,否则可能会覆盖其后的内容。所以使用时要注意。
int strcmp( const char *
string1,
const char *
string2
);
表示比较两个字符串是否相等,如果返回值 >0,则
string1大,<0,则
string2大,==0 则相等
由于字符串都处于内存中,所以对字符串的赋值及比较操作,完全可以用内存操作的函数,如memcpy, memcmp等代替。
单个字符的输出,可以这样
char c = ‘a’;
printf (“%c”, c);
字符串的输出,可以这样
char str[] = “abc”;
printf (“%s”, s);
要将一个整数转换成字符串,可以这样
char str[64];
int i = 100;
sprintf(str , “%d”, i);
反过来,要将字符串转换成整型,有函数atoi,如下:
i = atoi(str);
链表:
链表都是类比于数组的。
数组在内存空间每个元素的位置都是连续的,即&a[i]+sizeof(a[i])必定与&a[i+1]相等。
比如,有任意4个数, 3, 5, 9, 2。用数组可以表示如下:
int a[4] = {3, 5, 9, 2};
这样表示有几点局限性:
1、 很明显,这是定义在栈中,前面讨论过栈最大不超过1M,如果数量很多,以致于总的需要空间超过1M,就不行了。
2、 栈中不行,可以定义在堆中,但有一点,如果是元素数量很多的数组,我要在其中某个位置插入一个元素,则插入点后面的元素都应该相应后移一位,这造成效率上的降低。
3、 不方便增加一个元素,这里定义了4个元素,如果我还要增加1个元素,这种方式则难办了。
4、 即使我事先定义一个元素数量比较大的数组,实际用到的元素可能是不确定的,这样将会造成大量内存浪费。
数组在内存存储的位置,见图:
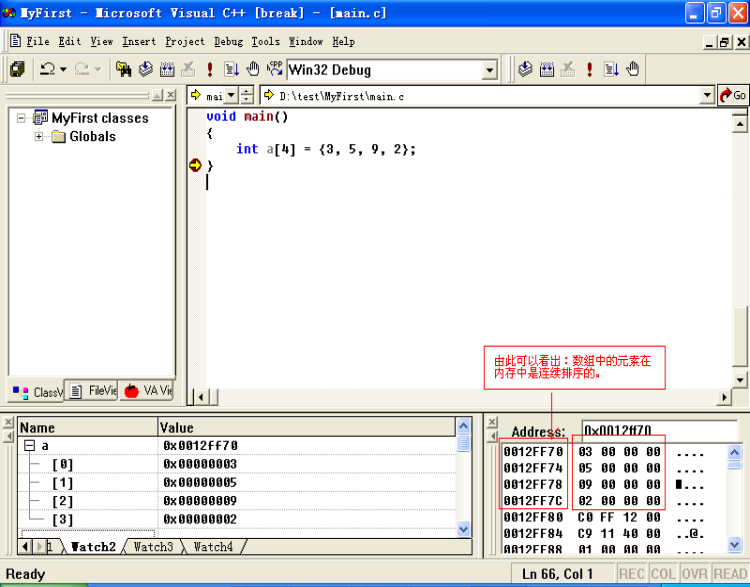
为了解决以上问题,我们可以引入链表。
在数组a中,a[1]一定是紧接排列在a[0]的后面。前面已经说过,所有的元素紧密地排一起不一定是好事,那就分开吧。这样我们就可以令a[1]不紧靠着a[0],但这又引入了一问题,以前大家做邻居的时候,拜访完a[0],找a[1]很方便,现在a[1]搬走了,怎么办?留个QQ号或地址什么的总可以吧。留给谁,当然是a[0]了。同样,a[2]也不跟a[1]做邻居了,自然也要留下地址。这样,每个元素就有两个属性了:
1、 本身的值
2、 找到下一个元素的线索
根据这样两个属性,我们可以这样定义元素
struct node
{
int
data;
struct node * next;
/* 这种定义方法,表示定义一个指针,其指向一个node类型的
结构体 */
};
前面说过,a[1]的地址由a[0]保存,那a[0]的地址由谁保存,答案是没人给他保存,所以必须记下来,我们可以用一个头指针记录元素a[0]的地址,即定义一个指针:
struct node* pHead=NULL;
那么以后,只要知道,这个pHead,就可以找到所有的元素了。
现在可以创建各个元素了
struct node* CreateNode(int data)
{
struct node* p = (struct node*)malloc(sizeof(struct node));
p->data = data;
p->next = NULL;
return p;
}
接下来,就是形成链表了,这里简单点,比如数据,已经存放在前面那个数组a中了。
node* pNode=pHead; /* 记录每一个新产生的node */
node* pTemp; /* 临时性的 */
for (int i=0; i<4; i++)
{
pTemp = CreateNode(a[i]);
if (pNode == NULL)
{ /* 第一次 */
pHead = pTemp;
}
else
{
pNode->next = pTemp;
}
pNode = pTemp;
}
到此链表组建完成,如图:
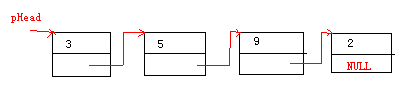
以后要遍历整个链表,可以如下:
pNode = pHead;
while(pNode != NULL)
{
printf (“%d”, pNode->data);
pNode = pNode->next;
}
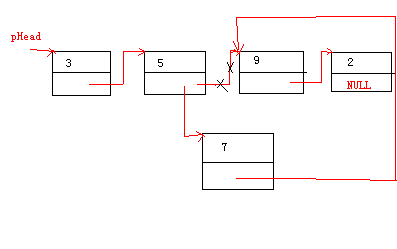
要在某个node之后,插入一个元素,如下
void Insert(struct node* pNode, int new_data)
{
struct node* p = CreateNode(new_data);
struct node* pTemp = pNode->next;
pNode->next = p;
p->next = pTemp;
}
如图:
完整的例子代码如下:
#include <stdio.h>
#include <stdlib.h>
/* 定义一个结点 */
struct node
{
int data;
struct node* next;
};
/* 创建一个结点 */
struct node* CreateNode(int data)
{
struct node* p = (struct node*)malloc(sizeof(struct node));
p->data = data;
p->next = NULL;
return p;
}
void main()
{
struct node* pHead = NULL; /* 头指针,开始时为NULL */
struct node* pNode = pHead; /* 指向每个结点 */
struct node* pTemp;
int data;
/* 建立链表 */
while (1)
{
scanf("%d", &data); /* 输入整数,0 则表示结束 */
if (data == 0)
break;
pTemp = CreateNode(data);
if (pNode == NULL)
{
pHead = pTemp;
}
else
{
pNode->next = pTemp;
}
pNode = pTemp;
}
/* 遍历整个链表 */
pNode = pHead;
while(pNode != NULL)
{
printf ("%d ", pNode->data);
pNode = pNode->next;
}
/* 由于链表每个结点通过malloc创建,结束时,别忘记了free */
while(pNode != NULL)
{
pTemp = pNode->next;
free(pNode);
pNode = pTemp;
}
}
该例子代码,应该与复习大纲中的建立单链表功能一致。请把该段代码仔细理解,否则不要往下面看。
复习大纲中的代码及补充代码如下:
#include <stdio.h>
#include <stdlib.h>
struct link
{
int data;
struct link *next;
};
int n;
/* 统计结点总数 */
/* 创建整个链表 */
struct link *creat( )
{
/* head表示链表的头,将会作为返回值 */
/* p1, p2都表示指向某个结点 */
struct link *head, *p1, *p2;
n=0; /* 初使值为0 */
/* 要求用户输入第一个值 */
p1=p2=(struct link *)malloc (sizeof(struct link));
scanf("%d",&p1->data);
/* 注意:此处是程序流程的一个BUG,如果第一次输入的p1->data为0的话,
就直接返回head了,此时head为NULL,所以第一次malloc得到内存将无法释放,
形成内存泄漏,但如果仅是演示,则无关大雅*/
head=NULL;
while(p1->data!=0) /* 以输入是否为0作为判断条件 */
{
n=n+1; /* 结点数加1 */
if (n==1) /* 第一次,则在头中,进行记录 */
head=p1;
else /* 前一个结点中的指针,指向当前结点 */
p2->next=p1;
p2=p1; /* 跳过当前结点 */
/* 继续要求用户输入 */
p1=(struct link *)malloc (sizeof(struct link));
scanf("%d",&p1->data);
}
/* 最后一个结点中的指针,要求为NULL */
p2->next=NULL;
return(head);
}
void main()
{
struct link *head, *p, *temp;
head = creat();
/* 遍历 */
p = head;
while (p != NULL)
{
printf("%d ", p->data);
p = p->next;
}
printf ("\nTotle: %d\n", n);
/* 释放 */
p = head;
while (p != NULL)
{
temp = p->next;
free(p);
p = temp;
}
}
大纲中合并两个有序链表的说明如下:
struct lk
{
int data;
struct lk *next;
}
/* 将两个本身为升序的链表,合并后成为一个新的链表 */
struct lk *merge(a,b)
struct lk *a, *b;
/* 参数的表示方式,相当于
struct lk* merge(struct lk* a, struct lk*b) */
{
struct lk *c, *p;
/* 比较a,b两链表的第一个结点,取出其值小一点的结点 */
if (a->data < b->data)
{
c=a;
a=a->next;
}
else
{
c=b;
b=b->next;
}
p=c;
while (a!=NULL && b!=NULL)
{
/* 依次比较a,b中每一个结点 */
if (a->data < b->data)
{
p->next = a;
a = a->next;
}
else
{
p->next = b;
b = b->next;
}
p = p->next;
}
/* 如果a,b中有哪一个提前遍历完,则另一个剩余的部分,就被挂在新的链表中末尾 */
if (a == NULL)
p->next=b;
else
p->next=a;
/* 返回新生成的链表头 */
return (c);
}
复习大纲中的一些知识点理解
1、
如何理解当
a = 2时
a + = a
- = a
* a 结果为
- 4
a + = a
- = a
* =a 结果为
0
a /= a + a
结果为
0
解答:
针对于
a += a -= a * a ; 相当于 a += (a -= (a*a));
1、初值
a 的值为 2;
2、计算
: a * a ,==〉 2*2,结果为4;
3、计算
: a -= 4,==〉 a = a-4 ==〉 a = 2-4,结果为-2,此时 a 的值为 -2;
4、计算
: a += -2,==〉 a = a+2 ==〉 a = -2 + (-2),结果为-4,此时 a 的值为 -4;
针对于
a += a -= a *=a ; 相当于a += (a -= (a *=a));
1、初值
a 的值为 -4; (这里假设该式是在前面的式子运行完后,接着运行,但后来感觉,该式可能是独立的,与前面的式子无关,无论初值如何,不影响理解)
2、计算:
a *= a,==〉 a = a*a ==〉 a= (-4)*(-4),结果为16,此时 a 的值为 16;
3、计算:
a -= 16 ==〉a = a-16,结果为0,此时 a 的值为 0;
4、计算:
a += a; ==〉 a = a+a,结果为0, 此时 a 的值为 0; 注意: a += (a -= (a *=a)); 这种式子,恒为0。原因在于 a -= (a*=某个值); 相当于a减去自身,只不过在进行减去之前,先自我变化了一番,但不管怎么变化,都是减去自身,所以恒为0。
针对于
a /= a+a ; 相当于 a /= (a+a);
1、初值
a 的值为2;
2、计算
: a+a,结果为4;此时a的值仍为2;
3、计算:
a /= 4; ==> a = a / 4; ==> a = 2 / 4; ==> a = 0; 结果为0;
2、冒泡排序
源程序解释如下:
#include <stdio.h>
#define SIZE 10
/* 交换两数
*/
void swap(int *p1, int *p2)
{
int temp;
temp=*p1;
*p1=*p2;
*p2=temp;
}
/* 冒泡排序的算法
*/
void sort(int *array, int n)
{
int i, j;
/*
这段循环可以这样理解:
假设
n为10,则有a[0]到a[9]
第
1步,将[0,9]中最大数,沉到a[9]中
第
2步,将[0,8]中最大数,沉到a[8]中
...
第
n步,将[0,0]中最大数,沉到a[0]中
*/
for (i=1; i<=n-1; i++)
for (j=0; j<=n-i-1; j++)
{
if(array[j] > array[j+1]) /* > 表示升序,否则表示降序
*/
swap(&array[j], &array[j+1]);
}
/* 我喜欢这样写,便于记忆
*/
/*
for (i=0; i<n; i++)
for (j=0; j<i; j++)
{
if(array[j] > array[j+1])
swap(&array[j], &array[j+1]);
}
*/
}
main()
{
int i, a[SIZE];
/* 输入
10个数 */
for (i=0; i<=SIZE-1; i++)
scanf("%d", a+i);
/* 测试
*/
/*
a[0] = 10;
a[1] = 70;
a[2] = 20;
a[3] = 14;
a[4] = 60;
a[5] = 19;
a[6] = 20;
a[7] = 256;
a[8] = 23;
a[9] = 86;
*/
sort(a, SIZE);
/* 输出
*/
for (i=0; i<=SIZE-1; i++)
printf("%d\n", a[i]);
}
1、 关于静态变量
其可运行源码如下:
#include <stdio.h>
long f(n)
int n;
{
static x=2;
if (n==0)
return (1);
else
{
x=x*n;
return(x);
}
}
main()
{
/*
printf("%d\n",f(0)+f(1)+f(2)+f(3));
等同于下面式子
*/
int f0, f1, f2, f3;
f0 = f(0); /* 运行前:
x为2,运行后:x为2,f0为1 */
f1 = f(1); /* 运行前:
x为2,运行后:x为2,f0为2 */
f2 = f(2); /* 运行前:
x为2,运行后:x为4,f0为4 */
f3 = f(3); /* 运行前:
x为4,运行后:x为12,f0为12 */
printf("%d\n",f0+f1+f2+f3);
}
2、 关于变量作用域,其源码如下:
#include <stdio.h>
int x=4;
void a();
void b();
void c();
void d(x);
main()
{
int x=6; /* 此处,内部的
x将外部的x给屏蔽掉了 */
printf("x in main is %d\n", x); /* x为
6 */
a();
b();
c();
d(x); /* 相当于
d(6) */
x++; /* 运行后
x为7 */
a();
b();
c();
d(x); /* 相当于
d(7) */
printf("x in main is %d\n", x); /* x为
7 */
}
void a()
{
int x=25; /* 此处,内部的
x将外部的x给屏蔽掉了 */
printf("x in a is %d\n", x); /* x永远为
25 */
}
void b()
{
static int x=50; /* 此处,内部的
x将外部的x给屏蔽掉了
并且是静态的,所以这句话,在程序启动时
就已经运行了,而不是到运行函数时再运行的。
*/
printf("x in b is %d\n", x++); /* 先取
x,再将x自增,这个x在下次运行该函数时,是有用的 */
}
void c()
{
x *=10; /* 用的全局变量
*/
printf("x in c is %d\n", x);
}
void d(int x)
{
printf("x in d is %d\n", ++x); /* 用的参数
x,先将其自增,再取值 */
/*
相当于
x += 1;
printf("x in d is %d\n", x);
*/
}
3、 关于
&& ||及++问题
(1)、
C语言中无bool型的变量,其思想用整数代替
0 表示
false,同时false用0表示
非
0表示true,同时true用1表示,比如关系,比较运行符返回的结果。
如
:
if (2)
{
printf (“true”);
}
else
{
printf (“false”);
}
将会输出
true
(2)、
||及&&均从左往右计算
0 && 任何表达式,结果为
0。其中任何表达式将不再计算。
非
0 ||任何表达式,结果为1。其中任何表达式将不再计算。
(3)、
++a: 表示先自增,再取值
a++:
表示先取值,再自增
总之,什么在前面,就先做什么。
如
:
int a = 10;
int b = ++a; /* 此时
a 为11,b为11 */
a = 10;
int c = a++; /* 此时
a 为11,c为10 */
大纲中可运行程序如下:
#include <stdio.h>
void main()
{
int a,b,c,d,m,n, result;
a = 1;
b = 2;
c = 2;
d = 4;
m = 1;
n = 1;
result = (m = a>b) && (n = c>d);
/*
1、执行:
m = a>b ==> m = 1>2 ==> m=0
2、执行:
0 && (n = c>d),其结果为0,则(n = c>d)不执行,
所以
n 仍为1;
*/
printf ("m = %d, n = %d\n", m, n);
a = 3;
b = 5;
result = a++ || b++;
/*
先取
a,再将其加1,==> 3 || b++ 其结果为1,所以 b++ 不执行
此时
a为4,b为5
*/
printf ("a = %d, b = %d\n", a, b);
a = 0;
b = 5;
result = a++ && b++;
/*
先取
a,再将其加1,==> 0 && b++ 其结果为0,所以 b++ 不执行
此时
a为1,b为5
*/
printf ("a = %d, b = %d\n", a, b);
}
其输出:
m = 0, n = 1
a = 4, b = 5
a = 1, b = 5

















 3649
3649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









