












1.本文提出一种核Gumbel-Softmax算子,被证明可以作为具体变量的良好拟合,特别是数 据点之间的离散潜结构。新模块可以在不牺牲精度的情况下,将学习新的消息传递拓扑的算法复杂度从二次型降低到线性型。这是一个开创性的模型,成功地将图结构学习扩展到具有百万级节点的大型图。
2.本文进一步提出NODEFORMER,一种新的图网络,具有分层的消息传递,作为在潜在连接所有节点的潜在图上操作。后者通过一个新目标以端到端可微的方式进行优 化,该目标本质上追求从以节点特征和标签为条件的后验中采样最优拓扑。据我们所知,NODEFORMER是第一个将全对消息传递扩展到大型节点分类图的Transformer模型。
3.通过在不同数据集上的广泛实验证明了该模型的有效性,包括节点分类基准和图像/文 本分类,其中显示了比强大的GNN模型和SOTA结构学习方法的显著改进。此外,在现有技 术无法扩展到2M节点的大型图数据集上,将竞争对手在中等规模数据集上的时间/空间消耗 降低了高达93.1%/80.6%。

graph transformer原有的QKV的计算复杂度为O(N2)太高,所以为了加速该运算,用一个正定核函数替换了原有的计算方式

import math,os import torch import numpy as np import torch.nn as nn import torch.nn.functional as F from torch_sparse import SparseTensor, matmul from torch_geometric.utils import degree BIG_CONSTANT = 1e8 def create_projection_matrix(m, d, seed=0, scaling=0, struct_mode=False): nb_full_blocks = int(m/d) block_list = [] current_seed = seed for _ in range(nb_full_blocks): torch.manual_seed(current_seed) if struct_mode: q = create_products_of_givens_rotations(d, current_seed) else: unstructured_block = torch.randn((d, d)) q, _ = torch.qr(unstructured_block) q = torch.t(q) block_list.append(q) current_seed += 1 remaining_rows = m - nb_full_blocks * d if remaining_rows > 0: torch.manual_seed(current_seed) if struct_mode: q = create_products_of_givens_rotations(d, current_seed) else: unstructured_block = torch.randn((d, d)) q, _ = torch.qr(unstructured_block) q = torch.t(q) block_list.append(q[0:remaining_rows]) final_matrix = torch.vstack(block_list) current_seed += 1 torch.manual_seed(current_seed) if scaling == 0: multiplier = torch.norm(torch.randn((m, d)), dim=1) elif scaling == 1: multiplier = torch.sqrt(torch.tensor(float(d))) * torch.ones(m) else: raise ValueError("Scaling must be one of {0, 1}. Was %s" % scaling) return torch.matmul(torch.diag(multiplier), final_matrix) def create_products_of_givens_rotations(dim, seed): nb_givens_rotations = dim * int(math.ceil(math.log(float(dim)))) q = np.eye(dim, dim) np.random.seed(seed) for _ in range(nb_givens_rotations): random_angle = math.pi * np.random.uniform() random_indices = np.random.choice(dim, 2) index_i = min(random_indices[0], random_indices[1]) index_j = max(random_indices[0], random_indices[1]) slice_i = q[index_i] slice_j = q[index_j] new_slice_i = math.cos(random_angle) * slice_i + math.cos(random_angle) * slice_j new_slice_j = -math.sin(random_angle) * slice_i + math.cos(random_angle) * slice_j q[index_i] = new_slice_i q[index_j] = new_slice_j return torch.tensor(q, dtype=torch.float32) def relu_kernel_transformation(data, is_query, projection_matrix=None, numerical_stabilizer=0.001): del is_query if projection_matrix is None: return F.relu(data) + numerical_stabilizer else: ratio = 1.0 / torch.sqrt( torch.tensor(projection_matrix.shape[0], torch.float32) ) data_dash = ratio * torch.einsum("bnhd,md->bnhm", data, projection_matrix) return F.relu(data_dash) + numerical_stabilizer def softmax_kernel_transformation(data, is_query, projection_matrix=None, numerical_stabilizer=0.000001): data_normalizer = 1.0 / torch.sqrt(torch.sqrt(torch.tensor(data.shape[-1], dtype=torch.float32))) data = data_normalizer * data ratio = 1.0 / torch.sqrt(torch.tensor(projection_matrix.shape[0], dtype=torch.float32)) data_dash = torch.einsum("bnhd,md->bnhm", data, projection_matrix) diag_data = torch.square(data) diag_data = torch.sum(diag_data, dim=len(data.shape)-1) diag_data = diag_data / 2.0 diag_data = torch.unsqueeze(diag_data, dim=len(data.shape)-1) last_dims_t = len(data_dash.shape) - 1 attention_dims_t = len(data_dash.shape) - 3 if is_query: data_dash = ratio * ( torch.exp(data_dash - diag_data - torch.max(data_dash, dim=last_dims_t, keepdim=True)[0]) + numerical_stabilizer ) else: data_dash = ratio * ( torch.exp(data_dash - diag_data - torch.max(torch.max(data_dash, dim=last_dims_t, keepdim=True)[0], dim=attention_dims_t, keepdim=True)[0]) + numerical_stabilizer ) return data_dash def numerator(qs, ks, vs): kvs = torch.einsum("nbhm,nbhd->bhmd", ks, vs) # kvs refers to U_k in the paper return torch.einsum("nbhm,bhmd->nbhd", qs, kvs) def denominator(qs, ks): all_ones = torch.ones([ks.shape[0]]).to(qs.device) ks_sum = torch.einsum("nbhm,n->bhm", ks, all_ones) # ks_sum refers to O_k in the paper return torch.einsum("nbhm,bhm->nbh", qs, ks_sum) def numerator_gumbel(qs, ks, vs): kvs = torch.einsum("nbhkm,nbhd->bhkmd", ks, vs) # kvs refers to U_k in the paper return torch.einsum("nbhm,bhkmd->nbhkd", qs, kvs) def denominator_gumbel(qs, ks): all_ones = torch.ones([ks.shape[0]]).to(qs.device) ks_sum = torch.einsum("nbhkm,n->bhkm", ks, all_ones) # ks_sum refers to O_k in the paper return torch.einsum("nbhm,bhkm->nbhk", qs, ks_sum) def kernelized_softmax(query, key, value, kernel_transformation, projection_matrix=None, edge_index=None, tau=0.25, return_weight=True): ''' fast computation of all-pair attentive aggregation with linear complexity input: query/key/value [B, N, H, D] return: updated node emb, attention weight (for computing edge loss) B = graph number (always equal to 1 in Node Classification), N = node number, H = head number, M = random feature dimension, D = hidden size ''' query = query / math.sqrt(tau) key = key / math.sqrt(tau) query_prime = kernel_transformation(query, True, projection_matrix) # [B, N, H, M] key_prime = kernel_transformation(key, False, projection_matrix) # [B, N, H, M] query_prime = query_prime.permute(1, 0, 2, 3) # [N, B, H, M] key_prime = key_prime.permute(1, 0, 2, 3) # [N, B, H, M] value = value.permute(1, 0, 2, 3) # [N, B, H, D] # compute updated node emb, this step requires O(N) z_num = numerator(query_prime, key_prime, value) z_den = denominator(query_prime, key_prime) z_num = z_num.permute(1, 0, 2, 3) # [B, N, H, D] z_den = z_den.permute(1, 0, 2) z_den = torch.unsqueeze(z_den, len(z_den.shape)) z_output = z_num / z_den # [B, N, H, D] if return_weight: # query edge prob for computing edge-level reg loss, this step requires O(E) start, end = edge_index query_end, key_start = query_prime[end], key_prime[start] # [E, B, H, M] edge_attn_num = torch.einsum("ebhm,ebhm->ebh", query_end, key_start) # [E, B, H] edge_attn_num = edge_attn_num.permute(1, 0, 2) # [B, E, H] attn_normalizer = denominator(query_prime, key_prime) # [N, B, H] edge_attn_dem = attn_normalizer[end] # [E, B, H] edge_attn_dem = edge_attn_dem.permute(1, 0, 2) # [B, E, H] A_weight = edge_attn_num / edge_attn_dem # [B, E, H] return z_output, A_weight else: return z_output def kernelized_gumbel_softmax(query, key, value, kernel_transformation, projection_matrix=None, edge_index=None, K=10, tau=0.25, return_weight=True): ''' fast computation of all-pair attentive aggregation with linear complexity input: query/key/value [B, N, H, D] return: updated node emb, attention weight (for computing edge loss) B = graph number (always equal to 1 in Node Classification), N = node number, H = head number, M = random feature dimension, D = hidden size, K = number of Gumbel sampling ''' query = query / math.sqrt(tau) key = key / math.sqrt(tau) query_prime = kernel_transformation(query, True, projection_matrix) # [B, N, H, M] key_prime = kernel_transformation(key, False, projection_matrix) # [B, N, H, M] query_prime = query_prime.permute(1, 0, 2, 3) # [N, B, H, M] key_prime = key_prime.permute(1, 0, 2, 3) # [N, B, H, M] value = value.permute(1, 0, 2, 3) # [N, B, H, D] # compute updated node emb, this step requires O(N) gumbels = ( -torch.empty(key_prime.shape[:-1]+(K, ), memory_format=torch.legacy_contiguous_format).exponential_().log() ).to(query.device) / tau # [N, B, H, K] key_t_gumbel = key_prime.unsqueeze(3) * gumbels.exp().unsqueeze(4) # [N, B, H, K, M] z_num = numerator_gumbel(query_prime, key_t_gumbel, value) # [N, B, H, K, D] z_den = denominator_gumbel(query_prime, key_t_gumbel) # [N, B, H, K] z_num = z_num.permute(1, 0, 2, 3, 4) # [B, N, H, K, D] z_den = z_den.permute(1, 0, 2, 3) # [B, N, H, K] z_den = torch.unsqueeze(z_den, len(z_den.shape)) z_output = torch.mean(z_num / z_den, dim=3) # [B, N, H, D] if return_weight: # query edge prob for computing edge-level reg loss, this step requires O(E) start, end = edge_index query_end, key_start = query_prime[end], key_prime[start] # [E, B, H, M] edge_attn_num = torch.einsum("ebhm,ebhm->ebh", query_end, key_start) # [E, B, H] edge_attn_num = edge_attn_num.permute(1, 0, 2) # [B, E, H] attn_normalizer = denominator(query_prime, key_prime) # [N, B, H] edge_attn_dem = attn_normalizer[end] # [E, B, H] edge_attn_dem = edge_attn_dem.permute(1, 0, 2) # [B, E, H] A_weight = edge_attn_num / edge_attn_dem # [B, E, H] return z_output, A_weight else: return z_output def add_conv_relational_bias(x, edge_index, b, trans='sigmoid'): ''' compute updated result by the relational bias of input adjacency the implementation is similar to the Graph Convolution Network with a (shared) scalar weight for each edge ''' row, col = edge_index d_in = degree(col, x.shape[1]).float() d_norm_in = (1. / d_in[col]).sqrt() d_out = degree(row, x.shape[1]).float() d_norm_out = (1. / d_out[row]).sqrt() conv_output = [] for i in range(x.shape[2]): if trans == 'sigmoid': b_i = F.sigmoid(b[i]) elif trans == 'identity': b_i = b[i] else: raise NotImplementedError value = torch.ones_like(row) * b_i * d_norm_in * d_norm_out adj_i = SparseTensor(row=col, col=row, value=value, sparse_sizes=(x.shape[1], x.shape[1])) conv_output.append( matmul(adj_i, x[:, :, i]) ) # [B, N, D] conv_output = torch.stack(conv_output, dim=2) # [B, N, H, D] return conv_output class NodeFormerConv(nn.Module): ''' one layer of NodeFormer that attentive aggregates all nodes over a latent graph return: node embeddings for next layer, edge loss at this layer ''' def __init__(self, in_channels, out_channels, num_heads, kernel_transformation=softmax_kernel_transformation, projection_matrix_type='a', nb_random_features=10, use_gumbel=True, nb_gumbel_sample=10, rb_order=0, rb_trans='sigmoid', use_edge_loss=True): super(NodeFormerConv, self).__init__() self.Wk = nn.Linear(in_channels, out_channels * num_heads) self.Wq = nn.Linear(in_channels, out_channels * num_heads) self.Wv = nn.Linear(in_channels, out_channels * num_heads) self.Wo = nn.Linear(out_channels * num_heads, out_channels) if rb_order >= 1: self.b = torch.nn.Parameter(torch.FloatTensor(rb_order, num_heads), requires_grad=True) self.out_channels = out_channels self.num_heads = num_heads self.kernel_transformation = kernel_transformation self.projection_matrix_type = projection_matrix_type self.nb_random_features = nb_random_features self.use_gumbel = use_gumbel self.nb_gumbel_sample = nb_gumbel_sample self.rb_order = rb_order self.rb_trans = rb_trans self.use_edge_loss = use_edge_loss def reset_parameters(self): self.Wk.reset_parameters() self.Wq.reset_parameters() self.Wv.reset_parameters() self.Wo.reset_parameters() if self.rb_order >= 1: if self.rb_trans == 'sigmoid': torch.nn.init.constant_(self.b, 0.1) elif self.rb_trans == 'identity': torch.nn.init.constant_(self.b, 1.0) def forward(self, z, adjs, tau): B, N = z.size(0), z.size(1) query = self.Wq(z).reshape(-1, N, self.num_heads, self.out_channels) key = self.Wk(z).reshape(-1, N, self.num_heads, self.out_channels) value = self.Wv(z).reshape(-1, N, self.num_heads, self.out_channels) if self.projection_matrix_type is None: projection_matrix = None else: dim = query.shape[-1] seed = torch.ceil(torch.abs(torch.sum(query) * BIG_CONSTANT)).to(torch.int32) projection_matrix = create_projection_matrix( self.nb_random_features, dim, seed=seed).to(query.device) # compute all-pair message passing update and attn weight on input edges, requires O(N) or O(N + E) if self.use_gumbel and self.training: # only using Gumbel noise for training z_next, weight = kernelized_gumbel_softmax(query,key,value,self.kernel_transformation,projection_matrix,adjs[0], self.nb_gumbel_sample, tau, self.use_edge_loss) else: z_next, weight = kernelized_softmax(query, key, value, self.kernel_transformation, projection_matrix, adjs[0], tau, self.use_edge_loss) # compute update by relational bias of input adjacency, requires O(E) for i in range(self.rb_order): z_next += add_conv_relational_bias(value, adjs[i], self.b[i], self.rb_trans) # aggregate results of multiple heads z_next = self.Wo(z_next.flatten(-2, -1)) if self.use_edge_loss: # compute edge regularization loss on input adjacency row, col = adjs[0] d_in = degree(col, query.shape[1]).float() d_norm = 1. / d_in[col] d_norm_ = d_norm.reshape(1, -1, 1).repeat(1, 1, weight.shape[-1]) link_loss = torch.mean(weight.log() * d_norm_) return z_next, link_loss else: return z_next class NodeFormer(nn.Module): ''' NodeFormer model implementation return: predicted node labels, a list of edge losses at every layer ''' def __init__(self, in_channels, hidden_channels, out_channels, num_layers=2, num_heads=4, dropout=0.0, kernel_transformation=softmax_kernel_transformation, nb_random_features=30, use_bn=True, use_gumbel=True, use_residual=True, use_act=False, use_jk=False, nb_gumbel_sample=10, rb_order=0, rb_trans='sigmoid', use_edge_loss=True): super(NodeFormer, self).__init__() self.convs = nn.ModuleList() self.fcs = nn.ModuleList() self.fcs.append(nn.Linear(in_channels, hidden_channels)) self.bns = nn.ModuleList() self.bns.append(nn.LayerNorm(hidden_channels)) for i in range(num_layers): self.convs.append( NodeFormerConv(hidden_channels, hidden_channels, num_heads=num_heads, kernel_transformation=kernel_transformation, nb_random_features=nb_random_features, use_gumbel=use_gumbel, nb_gumbel_sample=nb_gumbel_sample, rb_order=rb_order, rb_trans=rb_trans, use_edge_loss=use_edge_loss)) self.bns.append(nn.LayerNorm(hidden_channels)) if use_jk: self.fcs.append(nn.Linear(hidden_channels * num_layers + hidden_channels, out_channels)) else: self.fcs.append(nn.Linear(hidden_channels, out_channels)) self.dropout = dropout self.activation = F.elu self.use_bn = use_bn self.use_residual = use_residual self.use_act = use_act self.use_jk = use_jk self.use_edge_loss = use_edge_loss def reset_parameters(self): for conv in self.convs: conv.reset_parameters() for bn in self.bns: bn.reset_parameters() for fc in self.fcs: fc.reset_parameters() def forward(self, x, adjs, tau=1.0): x = x.unsqueeze(0) # [B, N, H, D], B=1 denotes number of graph layer_ = [] link_loss_ = [] z = self.fcs[0](x) if self.use_bn: z = self.bns[0](z) z = self.activation(z) z = F.dropout(z, p=self.dropout, training=self.training) layer_.append(z) for i, conv in enumerate(self.convs): if self.use_edge_loss: z, link_loss = conv(z, adjs, tau) link_loss_.append(link_loss) else: z = conv(z, adjs, tau) if self.use_residual: z += layer_[i] if self.use_bn: z = self.bns[i+1](z) if self.use_act: z = self.activation(z) z = F.dropout(z, p=self.dropout, training=self.training) layer_.append(z) if self.use_jk: # use jk connection for each layer z = torch.cat(layer_, dim=-1) x_out = self.fcs[-1](z).squeeze(0) if self.use_edge_loss: return x_out, link_loss_ else: return x_out

在上面的代码中,步骤很清楚

下图所示:
训练的流程:
data.x经过一层全连接得到特征表示z0(第0层的特征表示),经过本文nodeformer的计算方式,残差连接得到z1,重复上述步骤一直到zL,最后经过mlp得到预测的y值;
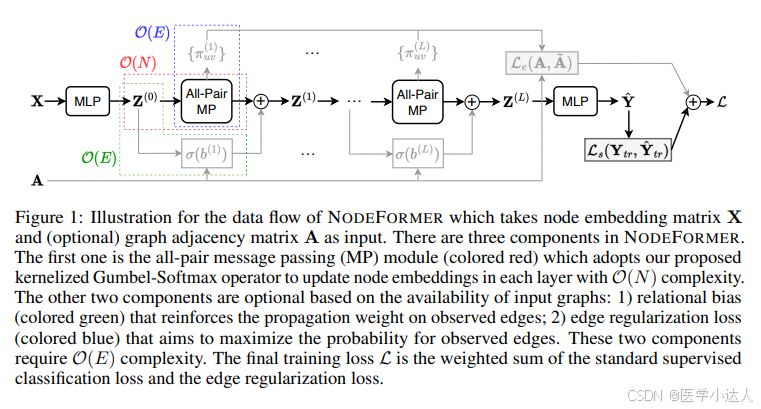
本文的主要优势:就是在计算attention的时候,用新方法替换了原有的QKV计算,是原有O(N2)的复杂度降低为O(N)

loss分为两部分:第一部分为标签预测损失,第二部分就是edge正则化损失。
个人测评:通过实现该方法,感觉这个edge正则化损失作用不大。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











