







 本文介绍了在SQL中如何备份数据,特别是针对MySQL数据库。讨论了CREATE TABLE + SELECT子句用于创建新表并复制符合条件的数据,以及INSERT INTO SELECT语句的使用。文章指出MySQL不支持select ... into ... from语法,并提供了正确的使用方法。
本文介绍了在SQL中如何备份数据,特别是针对MySQL数据库。讨论了CREATE TABLE + SELECT子句用于创建新表并复制符合条件的数据,以及INSERT INTO SELECT语句的使用。文章指出MySQL不支持select ... into ... from语法,并提供了正确的使用方法。
问题描述:
某打车公司将驾驶里程(drivedistanced)超过5000里的司机信息转移到一张称为seniordrivers 的表中,他们的详细情况被记录在表drivers 中,正确的sql为?
- 如果单看这道题的前部分,顺势思维,我会利用MySQL语句这样解决,创建一个新表,把符合一定条件的数据直接 copy 过去。
- 拿表 salaries 做例子。
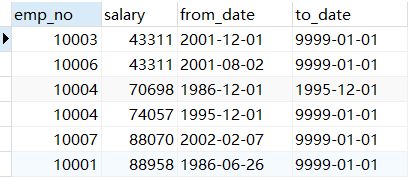
# 查看原表
SELECT * FROM salaries
ORDER BY salary;
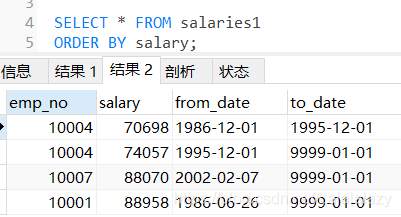
- 现在我想把工资高于 50,000 的原表信息转移到另一张表 salaries1 中,使用 MySQL语句,可以这样做:
CREATE TABLE salaries1
AS
SELECT * FROM salaries WHERE salary> 50000;
- 然而,题目下方有如下选项:
# A
insert into seniordrivers
drivedistanced>=5000 from drivers where
# B
insert seniordrivers (drivedistanced) values from drivers where drivedistanced>=5000
# C
insert into seniordrivers
(drivedistanced)values>=5000 from drivers where
# D
select * into seniordrivers from drivers where drivedistanced >=5000
-
仔细一看题目,“正确的sql为?”

-
这可难倒作为小白的我了,我之学习了MySQL啊!这个SQL是啥?跟MySQL什么关系?怎么那么像?

-
别慌,别慌!因为我们站在巨人的肩膀上!

-
SQL 是用于访问和处理数据库的标准的计算机语言。
-
这类数据库包括:MySQL、SQL Server、Access、Oracle、Sybase、DB2 等等。
-
哦哦哦,原来MySQL是一种库,SQL是一种计算机语言!

-
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
-
最后通过资料的查询与学习,总结一下:SQL语言中备份部分数据可使用
SELECT INTO语句 -
SELECT INTO从一个表中选取数据,然后把数据插入另一个表中。常用于创建表的备份复件或者用于对记录进行存档。
select * into seniordrivers from drivers where drivedistanced >=5000
- 上述代码正是所解
- 当把相同的语句放在MySQL查询中
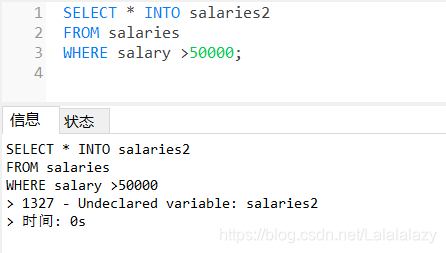
- 出现了错误:1327 - Undeclared variable: salaries2
- 未声明变量 salaries2 ,那如果我事先创建一个表 salaries2 呢?能否顺利把数据复制过来?
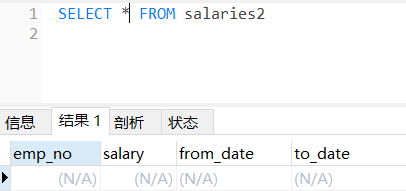
# 第一步,创建表结构,复制表 salaries
CREATE TABLE salaries2
AS
SELECT * FROM salaries
# 第二步,删除表 salaries2 的数据
DELETE FROM salaries2
# 查看表 salaries2 已经没了数据
SELECT * FROM salaries2
-
再来一次
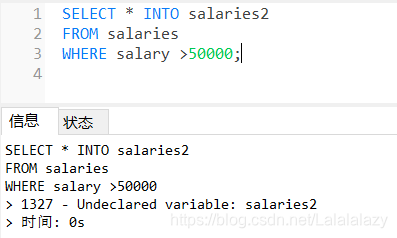
-
依然错误,其实导致这种错误的原因正是 MySQL不支持 select … into … from 这种用法。
-
其实,在 MySQL也没必要使用 select … into … from ,因为简单的 create 加 select 子句的方法就可以达到了要求!

-
但但但是,在选项上我看到了 insert into from 语句,这又有什么玄机吗?
-
INSERT INTO 语句在MySQL中用于向表格中插入新的行。顺带回忆一下吧!
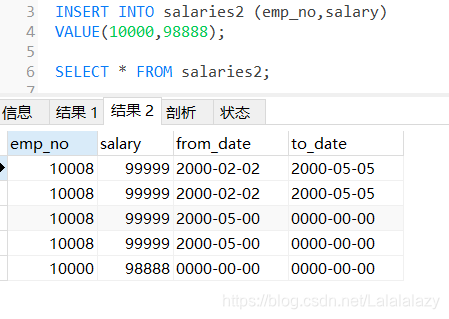
# 插入单行,所有字段对应需要给出值或者null(字段允许为null的情况)
INSERT INTO salaries2
VALUE(10008,99999,2000/2/2,2000/5/5);
# 特定字段插入数据
INSERT INTO salaries2 (emp_no,salary)
VALUE(10000,98888);
- INSERT INTO SELECT 语句
INSERT INTO salaries3 SELECT * FROM salaries WHERE salary>50000;
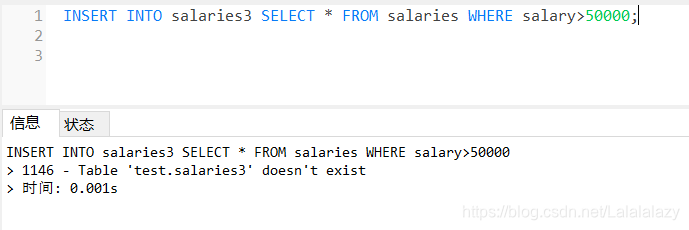
- 又双提示错误,错误提示表不存在,那如果表存在呢?

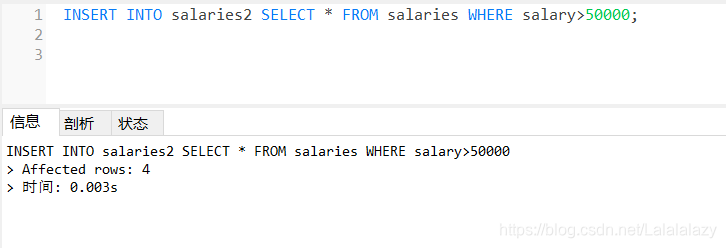
DELETE FROM salaries2;
INSERT INTO salaries2 SELECT * FROM salaries WHERE salary>50000;

总结
| SQL语句 | 表是否需要先存在 | MySQL是否支持 |
|---|---|---|
CREATE TABLE+SELECT子句 | 否 | 支持 |
select ... into ... from | 否 | 不支持 |
insert into select from | 是 | 支持 |

















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









