






这是一个充满趣味的故事。在这里,你要支付约45min的宝贵时间,将会收获:
- 深入理解分布式限流:获得一个经过深思熟虑和仔细设计的实现,你将成为解决分布式限流问题的专家;
- 分析问题的通用框架:跟随小懵一起,深入到实际问题的解决过程,你将得到解决复杂问题的一般性思路和方法;
- 很多有趣问题和答案:方案落地过程,出现了很多意外和有趣的问题,你将一同参与问题的发现和解决;
- 奇思妙想的设计技巧:各种设计小技巧,以技术极客的视角来看各种问题,这将会为你未来解决技术问题提供弹药;
那么,让我们开始吧!
背景[5min]
小懵是一位非常负责的研发同学,他主要负责安全风控平台部的算法工程工作,日常需要保证机审平台调用模型服务的稳定性,不能出P2及以上的事故。
但是这两年由于美丽国的制裁导致卡资源非常紧张,原来能用钱解决的问题现在都是问题了。模型服务经常因流量上涨触发服务告警,但又没有卡资源来快速扩容。系统整体稳定性堪忧,小懵非常慌张。
于是,小懵找到了公司内部的小初、大高、老顶、太究来帮忙解决这个问题。

人物:小懵
特点:很负责,偶尔会懵逼
薪资:24,000

人物:小初
特点:初级研发,会写代码
薪资:12,000

人物:大高
特点:高级研发,很会写代码
薪资:42,000

人物:老顶
特点:顶级研发,善解疑难杂症
薪资:83,000

人物:太究
特点:究极研发,很会删代码
薪资:未知
小初的解决方案 —— 基于redis的分布式限流[5min]
小懵找到了小初,希望小初可以帮忙解决下这个问题。
小初整体分析了下系统架构。发现模型服务的整个链路是由机审发起,中间通过一个模型网关进行调度,再发起对模型服务的请求。大部分模型服务是用GPU部署的,很贵且不好扩展。而模型网关是Java开发的,跑在CPU上,好改也便宜。
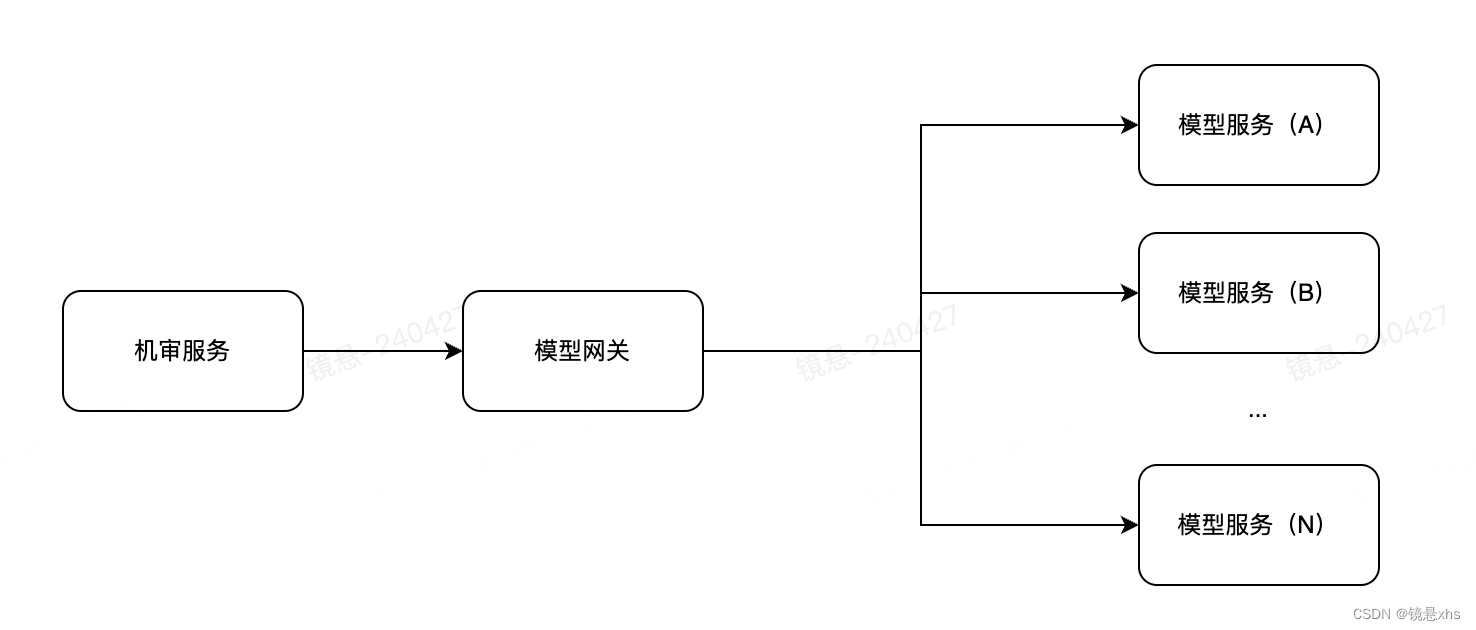
小初觉得,既然模型服务难以扩展,那我们可以在模型网关上开发些功能,将模型服务保护起来。他想了想,觉得限流应该可以帮助到小懵,应对这种风险。
小初调研了下方案,发现限流有单机限流和分布式限流两种方式。顾名思义,单机限流仅看实例自身的流量,分布式限流则看集群整体的流量。结合现在要解决的问题,小初认为要保护模型服务不被打挂,仅靠单机限流是做不到的,应该在模型网关上实现分布式限流。他在网上找了些资料,整理了下整体的方案,就去找小懵了。
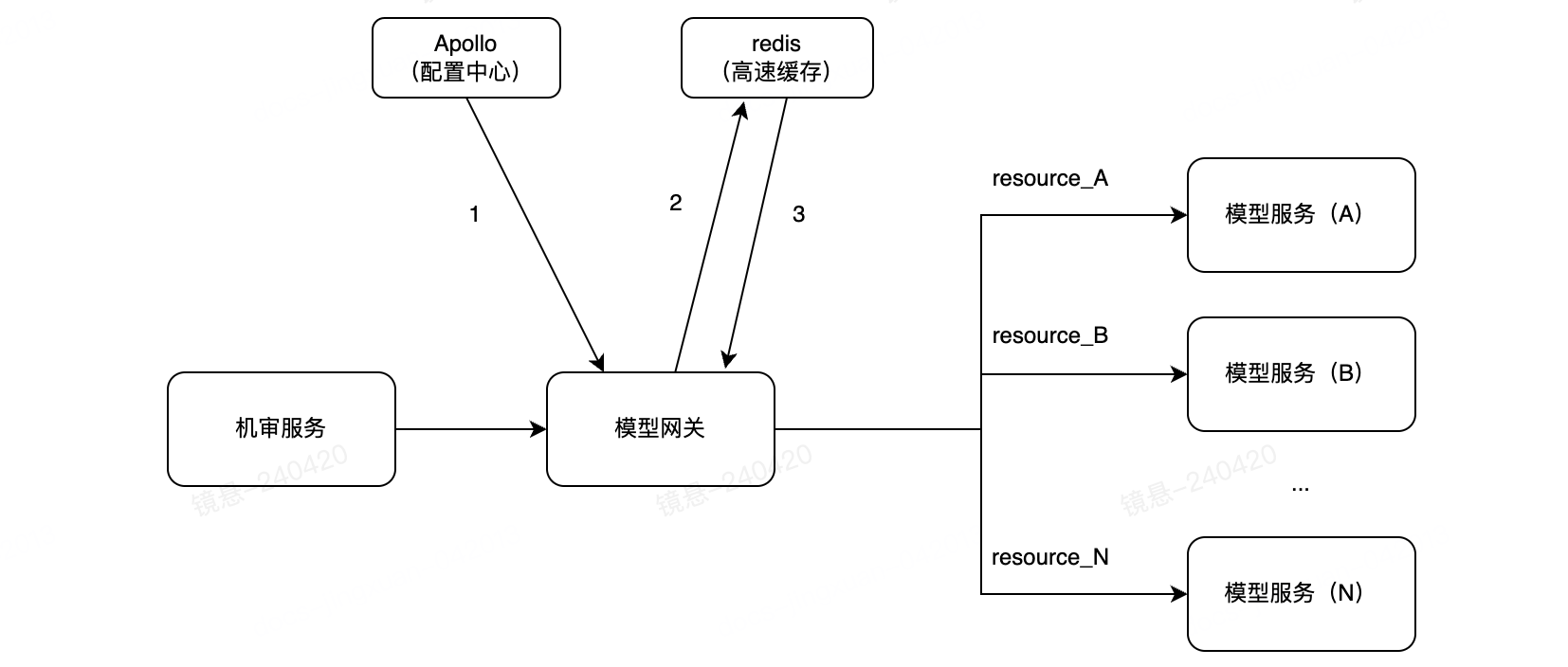
小初的方案:
- 将所有模型服务看成资源,对模型服务的调用看成是对资源的访问
- 增加配置中心,在配置中心上配置各种资源每秒钟可被访问的次数
- 增加高速缓存,通过如下方式判断是否应该去调用模型服务:
- 基于<resource_name> + <tsInSec>的形式设计key
- 每次请求模型时,通过incrAndGet的原子操作,获取当前访问次数
- 如果访问次数超过阈值,就block掉该请求;否则放行流量
小懵看了下方案,觉得非常nice,于是小初就开始开发了。两天后,小初带着自己实现的功能,约好小懵一起上线看效果。最后的结果,让他们都震惊了,redis的响应时间超过了100ms!
小初赶紧回滚了方案,觉得很难受,很受打击。他百思不得其解,说好的毫秒级响应的高速缓存,怎么就不好使了呢?小懵同样也很郁闷。
整个方案上线使用了大概... 20min吧,然后就宣告失败了。
聪明的同学,你发现redis响应时间变长的原因了吗?
大高的解决方案 —— 基于随机数和大数定理的分布式限流[10min]
小懵没办法,他又去找到了同事大高,希望大高能帮忙解决这个问题。
大高了解了下背景,也看了下小初的解决方案。他认为小初的方案本身没什么问题,同时一眼看出了redis响应时间变长的原因:热点key访问!他画了如下图将原因解释给小懵和小初:
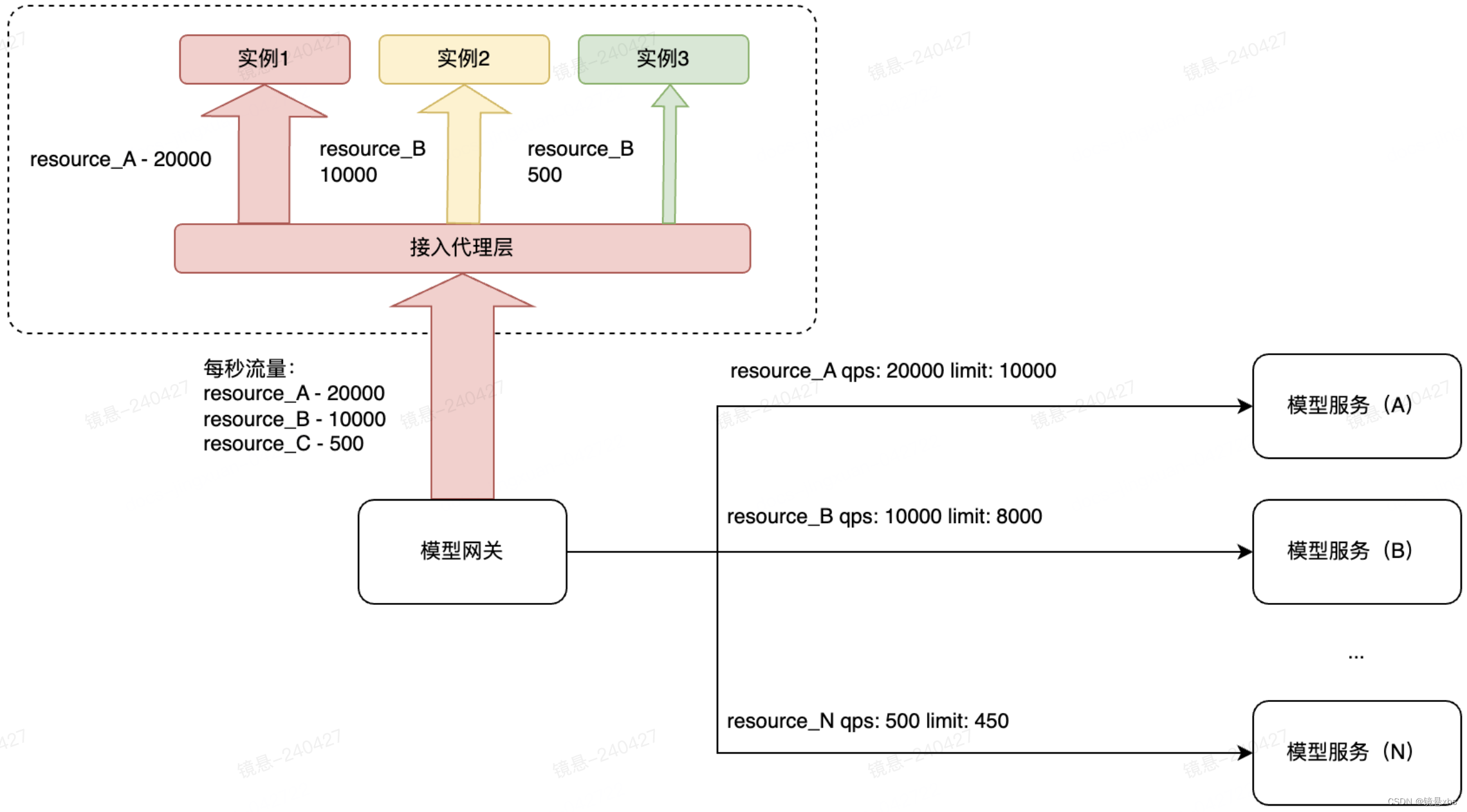
相同模型服务每秒钟生成的存储key是相同的,流量会走到redis集群的同一台实例上。当模型服务的调用量非常大时,由于redis处理请求是单线程的,就会出现大量阻塞。自然而然,响应时间也就变长了。
那么,小初的方案还能拯救下吗?
大高想了想,既然思路没问题,只是存在热点key导致不能用,那如果解决了热点key的问题,是不是整个方案就能用了呢?
有没有什么办法,将热点key打散呢?大高突然想起了小学二年级学过的概率论的相关知识,于是他开始在纸上写了起来……

大高和小懵简单说了下思路:既然热点key是之前方案不行的核心问题,那么可以通过增加一个可配置参数maxSize,将key打散,这样就可以缓解redis的热点key问题。
为了证明该方案有效,大高还给小懵讲了概率论和大数定理,说明随机访问在这种场景下的有效性。小懵听的更懵,情不自禁的给大高竖起了大拇指👍🏻。

又过了两天,大高版本的限流方案开发好了。再一次发版,这次发现redis的响应时间不再发生激增了,看起来热点key的问题解决了!
小懵检查了下需要限流的服务,发现确实有流量被正确限流了,一切都向着好的方向发展着。感觉马上就要胜利了!
但是一段时间之后,小懵发现,限流的阈值总是达不到,比如限流了1200,但实际到800可能就被限了。于是,小懵又去找了大高,问大高这是为啥呢?
大高看了看,发现还真是,但这是为啥呢?他们又陷入了深深的思考中……

聪明的同学,你想到了限流过早被触发的可能原因了吗?
老顶的解决方案 —— 基于集群规模探测和背压感知的分布式限流[10min]
虽然能用,但不好用。小懵依旧觉得没有得到自己最想要的结果,于是他找到了老顶,老顶是公司非常厉害的研发了。小懵希望他来帮忙看看,这个方案到底哪里出了问题。
老顶了解了下背景,看了看大高的代码,然后仔细盯着监控一言不发。时间就这样一秒一秒的过去,正当小懵感觉整个人都快窒息的时候。老顶悠悠的开口说道:
我想可能的原因如下:
- 随机打散的方式虽然解决了热点key的问题,但给整个系统也带来了比较大的随机性。这种随机性,可能会导致实际限流值偏低;
- 监控打点的数据并不是每秒都会采集,而限流是针对每秒做的决策。这种时间上的不一致,也可能导致实际限流值偏低
小懵这下懵了,甚至比大高和他说概率论和大数定理的时候更懵。他一脸无辜的看着老顶,心里想高手说的话都这么抽象吗?

老顶看了看小懵,又慢条斯理的说道:
你想啊,这个maxSize假设是1,其实就是小初的方案,解决不了热点key的问题。但如果是100,假设限流也是100,QPS也是100。逻辑上来讲应该是不触发限流的。但现在的方案,最终被放过的QPS的期望值是多少?
小懵下意识的问到是多少?
老顶说,不知道,但总归是小于100的。
小懵一脸震惊(内心OS:牛人都是这么回答问题吗?),又问道,那监控打点的那个是什么意思呢?
老顶给小懵画了张图,说道:由于超过阈值会被限掉,低于阈值的则不会补平,所以区间内放过的流量就变低了。监控取的是区间内实际放行的流量,因此从监控上看,实际限流值就会比配置的阈值要低。
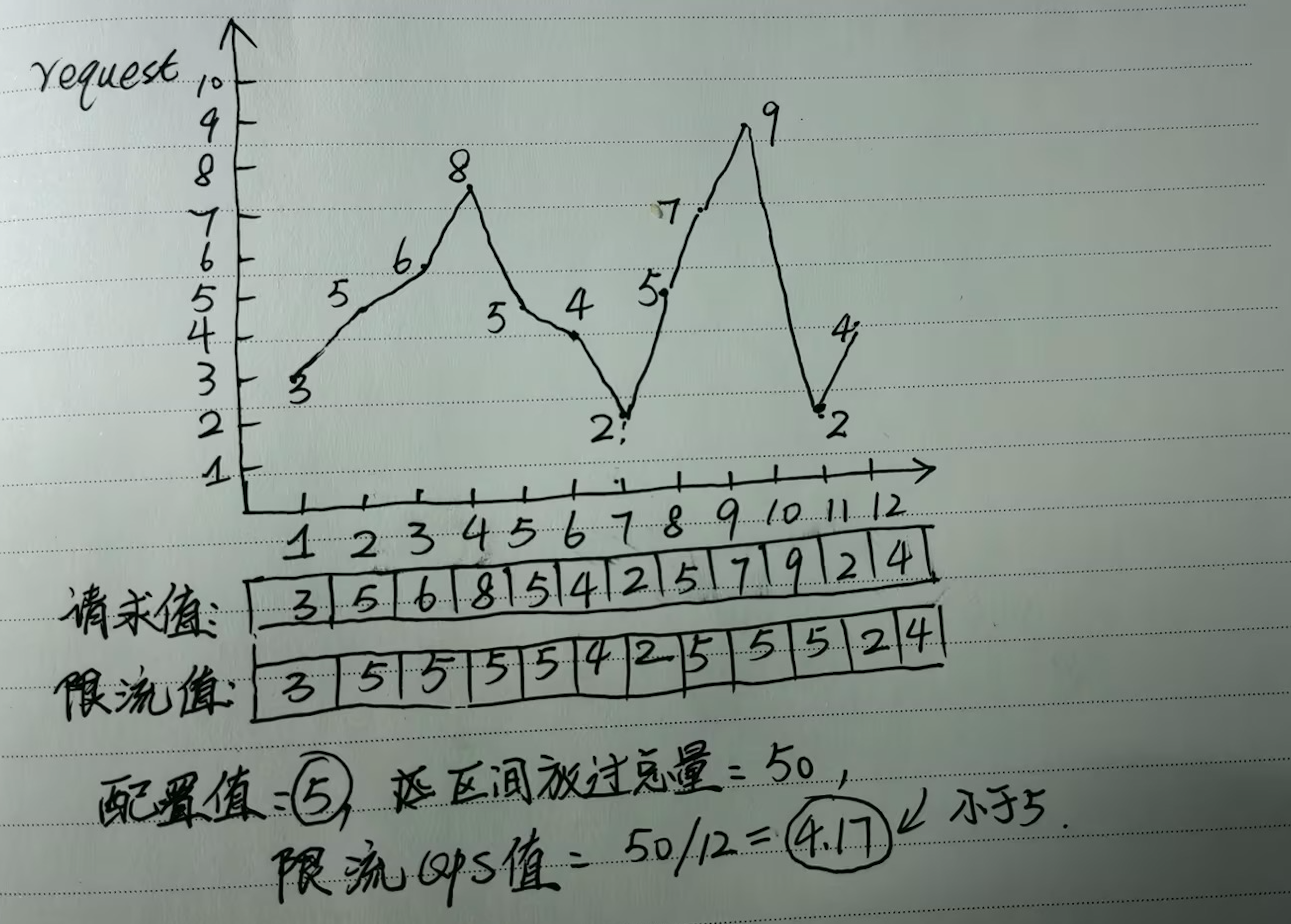
小懵问那如果限流框架可以自动补平少发的数据,是否就能让限流阈值和实际放行的阈值,在监控数据上变得一样呢?
老顶说:是的,但是可能因为找平导致的超发带来瞬时的流量波峰,让后端的模型服务在瞬间承受过大的请求压力,这也会导致不稳定。
小懵觉得实际限流值达不到配置值是他不能接受的,但是老顶说的这个问题他也很担心。正在他纠结该怎么办的时候,这时老顶开口了:
我们做一套能找平流量,同时能感知模型背压的方案吧。如果感受到模型服务过载了,就让模型网关自动调低可放行过去的流量。
小懵觉得这个很高级,但会不会也很难(内心OS:会不会搞出P2以上故障啊)。他内心非常忐忑,又不知道该如何表达。基于对老顶技术能力的信任,他还是点了点头。
老顶花了一天的时间厘清了思路,画了张整体架构图:
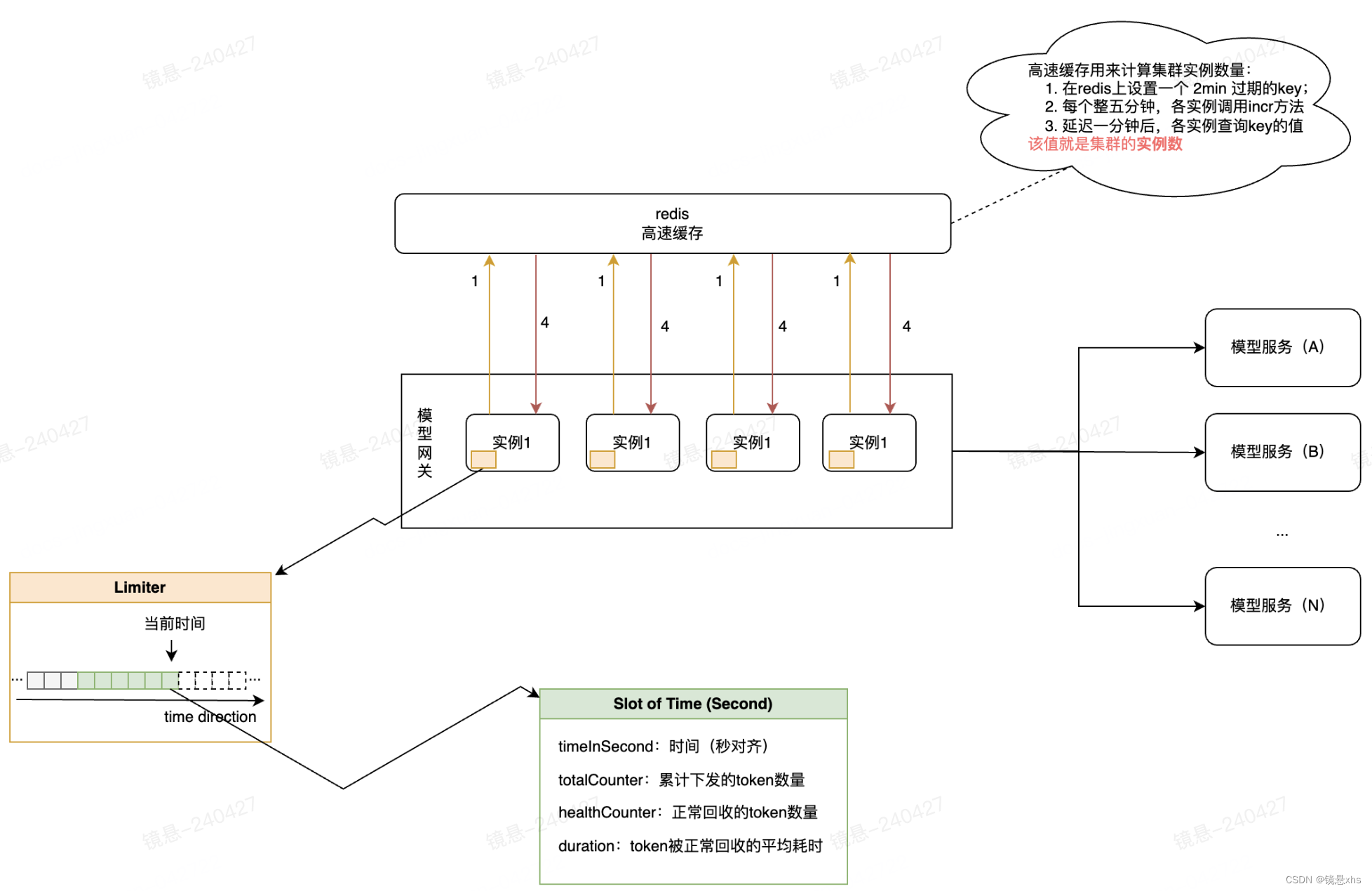
由于架构图比较抽象,老顶给小懵讲了下整体的思路:
概念调整(1):增加token的概念,token是一种访问资源的授权。当token被消耗完了,则意味着该资源在此刻不再能被访问
规模探知(2):通过在redis上使用基于时间对齐的技术,来实现探测集群规模的目的
阈值计算(3):每个实例通过配置的可放行的QPS和探测得到的集群规模scale,计算单个实例实际可放行请求量的上线Limit。$Limit = QPS / scale$
核心抽象(4):
- 增加了一个Limiter的实体,里面存储了从最近一段时间内限流组件的运行情况(窗口大小可配)。
- 增加一个Slot实体,里面存储了某一秒限流组件的运行情况
限流计算(5):每次有请求进来时,以(3)计算得到的阈值为基础,用窗口内已下发的token量动态调整该阈值,决定是否放行请求
背压感知(6):
- 增加token的release行为,请求token的调用方,负责在完成访问后主动调用release方法
- 平均耗时内释放的token被认为是正常的token,此时系统未过载
- 超过平均耗时仍然未释放则认为容量见顶了,此时Limiter负责调小可下发的token上限
小懵大概听懂了整个方案的……1%吧,但他觉得挺有道理的,于是同意了老顶的方案。

大概又过去了一个礼拜,有天老顶找到小懵说可以上线试试看了。于是又一个分布式限流的版本发到了线上,系统比预想的更稳定了,而且确实对redis的调用量降低了非常多。
可小懵惊奇的发现,限流依旧会被过早的触发。怎么说呢,原来是1200的限流,800被触发,现在嘛,大概……1000吧。你说没解决吗,确实比之前更接近了。你说解决了吗,这200的差值还在那呢!
小懵带着问题找到了老顶,老顶看了下监控。他感觉只能说是有改善,并不能算完全解决。那个下午,小懵觉得老顶的头发更加的白了……
正当小懵想着要么放弃吧,这样用着也行的时候。有一天,他滚动重启整个服务的时候,发现莫名奇妙触发了大规模限流。他赶紧找到了老顶,老顶在分析完现象后,终于找到了出问题的代码:
@Override
public void afterPropertiesSet() {
log.info("The key for current cluster while calculating cluster scale is: {}", clusterScaleCalculationKey);
this.tryCalculateClusterScale();
}
@Scheduled(cron = "0 0/5 * * * ?")
protected void tryCalculateClusterScale() {
log.info("Try to calculate cluster scale by key: {}", clusterScaleCalculationKey);
if (!isCalculating.compareAndSet(false, true)) {
log.info("The cluster scale is calculating, skip this time.");
return;
}
// 集群中的所有节点,在一定的周期内,随机向redis中报数,用于计算集群规模
executorService.schedule(
this::calculateClusterScale,
(long)(Math.random() * WRITING_INTERVAL_MAX_IN_SECONDS * 1000),
TimeUnit.MILLISECONDS
);
// 在固定的某一刻,集群所有节点同时向redis请求当前集群规模数
executorService.schedule(() -> {
String value = mlsysEcologyJedis.get(clusterScaleCalculationKey);
log.info("The value of cluster scale reading from redis: {}", value);
if (StringUtils.isEmpty(value)) {
log.warn("Fail to read cluster scale from redis, the value is empty, set to 0.");
clusterScale.set(0);
return;
}
clusterScale.set(Integer.parseInt(value));
}, READING_INTERVAL_IN_SECONDS * 1000, TimeUnit.MILLISECONDS);
}那一刻,小懵突然觉得,老顶的工资,会不会是给高了……
聪明的同学,你能想到限流依旧被过早触发的原因,以及滚动重启会触发大规模限流的原因吗?
太究的解决方案 —— 基于实例权重探测的分布式限流[10min]
在滚动重启触发大规模限流后,小懵很是慌张。于是他想到了公司内的神秘技术大佬太究,太究据说技术能力非常强悍,极为神秘,在公司很少能看到他真人。于是,小懵给太究发了一份邮件,详细叙述了事情的来龙去脉,并把老顶的核心代码发给了太究。他甚至悲观地请教太究,是否分布式限流就是没有办法做到精准?
老顶的核心代码:
太长了,评论区见吧没想到当天晚上凌晨,小懵就收到了太究的回复。
在回复中,太究对代码给予了较高的评价,详细论述了代码中一些好的设计思想和编程技巧:
- 恰到好处的概念抽象:方案中的Limiter和Slot两层抽象很合理,框架的结构清晰、简单;
- 内存资源的有效利用:方案需要存储每秒钟的访问数据,且数据具有明显的FIFO的特性。处理这种数据可以使用LRU的技巧,让系统自动淘汰最早的数据。但这个方案却没有采用,而是使用了更为巧妙的方法。它合理的使用了模运算的能力,使用一个常量空间的内存,保存了所有系统需要的数据。
private Slot getOrCreateSlot(long currentInSecond) {
// 通过一个常量大小的内存空间,保存了系统需要用的历史数据
int position = (int) (currentInSecond % this.windowSize);
Slot slot = window[position];
if (slot.isExpired(currentInSecond, this.windowSize)) {
slot = new Slot(currentInSecond);
window[position] = slot;
}
return slot;
}- 系统中断的合理使用:限流是基于时间的,每一条请求进来都需要调用系统函数,得到请求的处理时间。系统函数的调用,会让进程从用户态切换到内核态,造成上下文切换的损耗。为了降低系统上下文的切换损耗,方案中通过每秒钟触发一个系统中断,替代了用户态/内核态的频繁切换,这将给系统带来明显的性能提升:
public class TimeUtil {
private static final AtomicReference<Long> CURRENT_SECOND = new AtomicReference<>(System.currentTimeMillis() / 1000);
static {
ScheduledExecutorService executorService = Executors.newSingleThreadScheduledExecutor();
executorService.scheduleAtFixedRate(() -> {
CURRENT_SECOND.set(System.currentTimeMillis() / 1000);
}, 0, 1, TimeUnit.SECONDS);
}
public static long getCurrentSecond() {
return CURRENT_SECOND.get();
}
}- 并发访问的有效管理:对于Slot的访问,只有当前时间发生了秒级别的变化,才需要重新计算Slot的位置,初始化Slot的相关数据。方案在这部分使用double-check的方式,保证了锁粒度的最小化,也保证了数据访问的安全性:
Accelerator getOrUpdate() {
long currentInSecond = TimeUtil.getCurrentSecond();
// 当前时间没有发生秒级别的变化,直接返回即可
if (this.accelerator.get().getTimeInSecond() == currentInSecond) {
return this.accelerator.get();
}
// 否则,需要增加同步锁,开始更新Accelerator
synchronized (this) {
if (this.accelerator.get().getTimeInSecond() == currentInSecond) {
return this.accelerator.get();
}
this.accelerator.set(this.calcluateAccelerator(currentInSecond));
}
return this.accelerator.get();
}对于为何实际限流值没有达到配置值,以及是否有更好的办法解决这个问题。太究回复说他大体知道了问题的原因,并且保证是有方法可以解决的。他约了两天后找小懵面谈。
两天很快过去了,小懵终于见到了传说中的大佬太究。相比于老顶代码写得究竟有多好,小懵更想知道这个方案有啥问题,还有没有的救?所以小懵开口就问太究这个方案有什么问题?于是就发生了如下的对话:
小懵:这套方案有什么问题吗?
太究:先不要急着说问题。我首先看到了一个比较奇怪的地方,为什么这个方案既设计了根据配置的限流阈值去做限流,又加了背压感知,通过背压的方式调整限流值?
小懵:这有什么不对的地方吗?
太究:嗯,这里比较奇怪。如果已经可以人为设置限流阈值,为何还会导致系统有背压存在?如果已经可以通过背压动态调节放行流量了,为何又需要人为设置一个阈值呢?
小懵:额,你这么一说,确实有点奇怪……
太究:是的,这是典型的既要又要的逻辑。这两种方式虽然都会产生限流的效果,但它们彼此之间会有相互的影响。尤其是背压的引入,会导致实际限流值和设置的目标值间发生偏离。这会让整个框架的效果,变得让人难以理解。
小懵:那是这个原因导致的限流被过早触发吗?
太究:有可能,但我觉得还有一个更为重要的影响因素。
小懵:是什么?
太究:别急。我先问你,通过集群规模探测的scale和需要限制的单秒放行流量QPS,计算每个实例可以放行的流量limit,这种方式你觉得有什么问题吗?
小懵:没啥问题啊,这不就是小学除法吗?
太究:我不是这个意思。我是说,上面这个算法,认为集群中所有实例,在任何时刻都是相互独立且无差异的,这个符合现实情况吗?
小懵:你是说,集群中实例的流量是不均衡的?也就是说实例有不同的权重?
太究:对,而且这个权重可能还会一直在变化!
小懵:为什么会出现这种现象呢?
太究:可能的原因有很多。比如说,假设基础架构设计了一套通过调整实例入口流量以使各实例的CPU利用率相对均衡的框架,是不是就可能会让不同的实例间的流量不一致。性能好的实例的流量就高,性能差的实例的流量就低了?
小懵:动态调权?
太究:嗯。再比如,为了提升RPC间的调用效率,大部分RPC框架采用长链接的方式相互调用。而且在某些场景下,可能客户端会更偏向于向其中某些实例发送请求,亦或客户端会通过小窗口聚合流量批量发送。这些都会导致流量出现抖动。
小懵:!!!!
随后,太究给出了自己的解决思路:
- 取消背压感知的设计,这和最终要达到的效果之间有明显冲突
- 取消集群规模探测的设计,使用实例权重探测的方式替代它
他还画了两张图,用来诠释自己的想法。
主体架构保持和之前的基本相似,使用基于滑动窗口的设计方法,并保留了当前Slot若流量不足,则调高下一个Slot可下发token上限的设计:
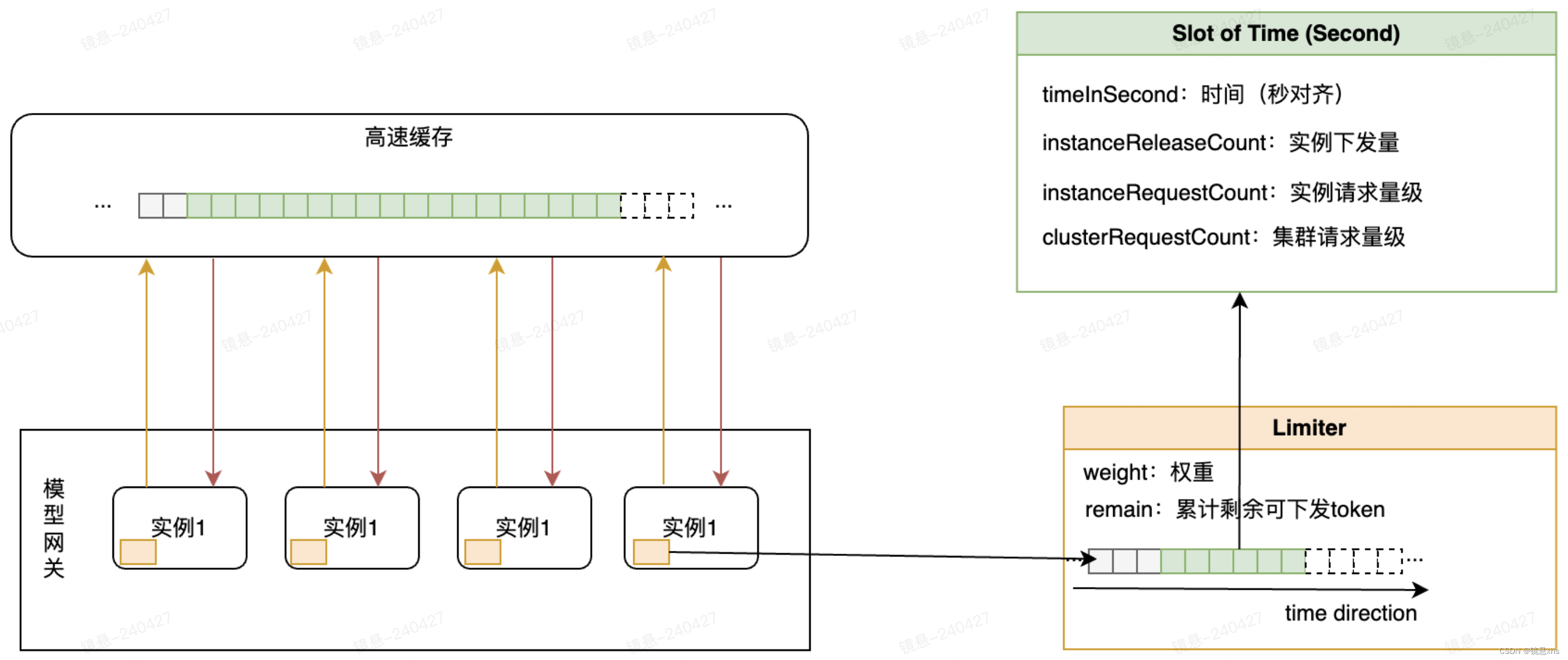
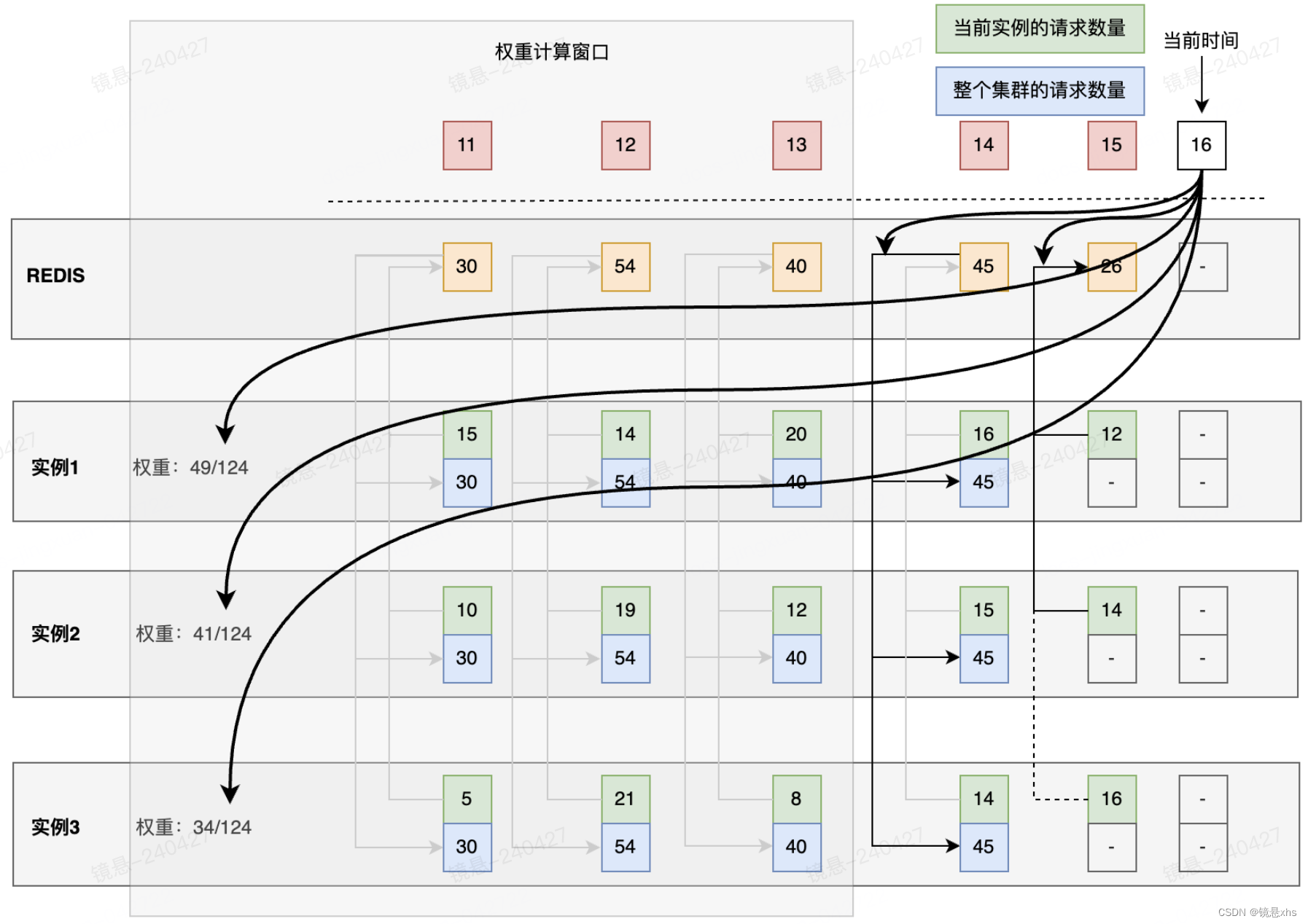
在计算每个实例可以下发的token量的设计中,使用权重探测的方式替换了集群规模感知。每隔窗口大小的时间间隔,重新计算一次权重。该权重是通过这段期间实例请求量占集群总请求量的比例计算得到的。
大概又过去了一周,太究发来了他最终修改后的代码:
太长了,评论区见吧这次小懵自己去发版了,这是分布式限流的第四个大的改版。上线后,他分别观察了下高限流和低限流两种场景,结果如下面两张图所示:
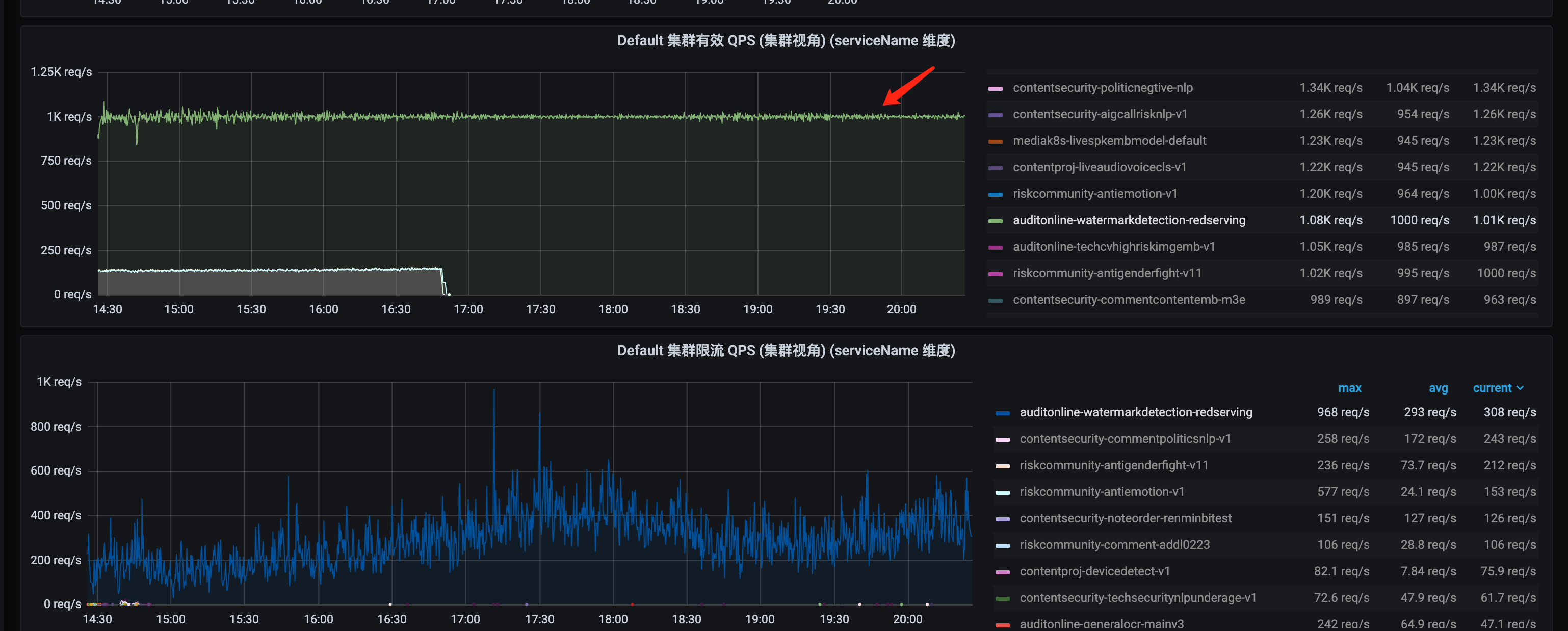
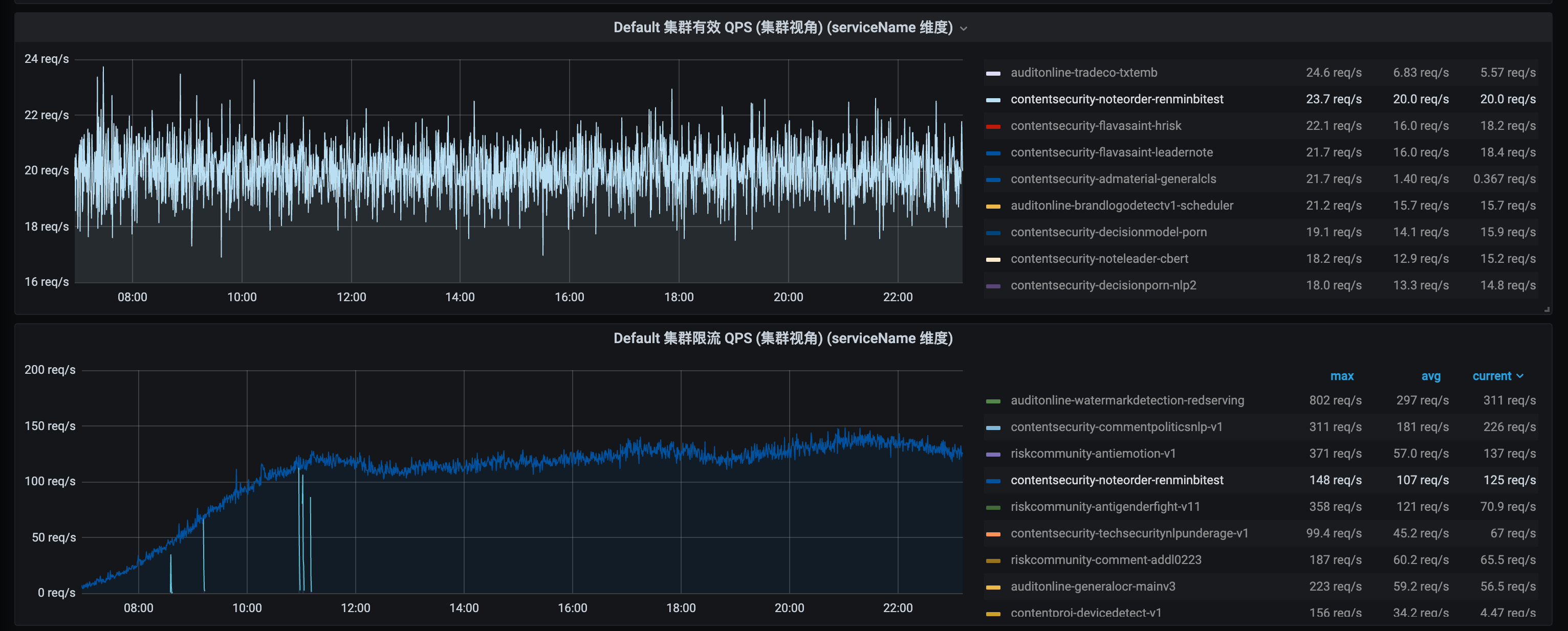
小懵震惊了,这限流值和配置值终于相等了,而且整个服务非常稳定可靠。小懵很好奇,为何有如此好的效果。他又仔细阅读起了代码,不禁对太究的技术功底和代码能力产生了由衷的佩服之情。同时,他发现了一个很有意思的现象,太究的方案,对redis访问的QPS,竟然完全不受模型调用QPS的影响,它恒等于集群的实例数量,他觉得太不可思议了……
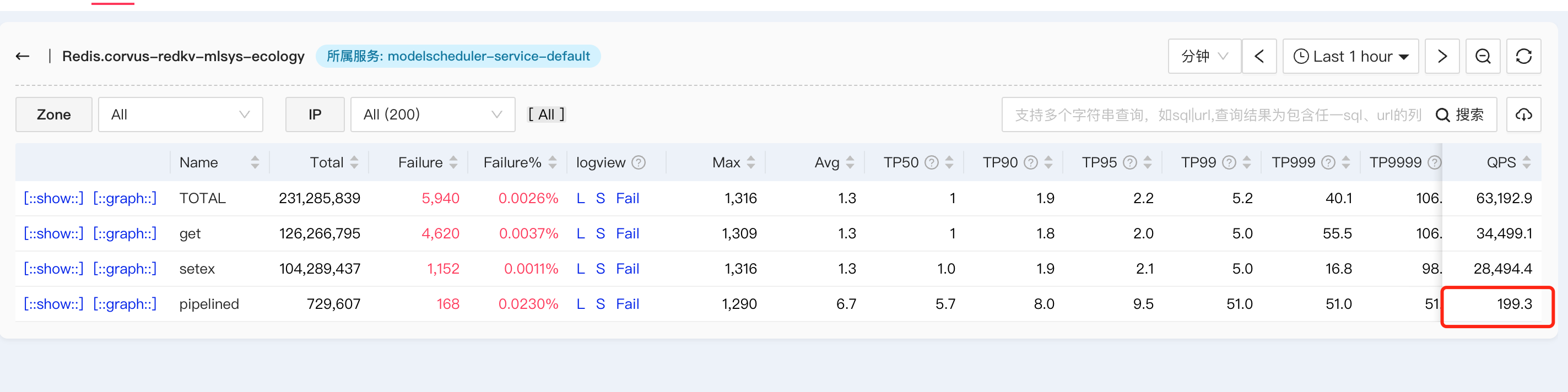
聪明的同学,你能看出来,为何对redis的访问量,等于实例数量,而和请求QPS无关吗?
总结 & 讨论[5min]
总结下最终的收获,我们终是获得了一个各方面都表现不错的分布式限流的技术方案,它有如下特点:
- 短小:一个文件,加上空行、注释,总共500行代码;
- 轻量:除了依赖一个redis做分布式缓存之外,不需要其他任何的依赖;
- 准确:无论是高阈值限流或低阈值限流,都能很好地贴合限流的目标配置值;
- 稳定:限流值相对稳定,波动小。尤其是高阈值场景下,监控图形看起来像是手绘的一根直线!
- 友好:对开发人员友好,有良好的概念抽象和编码风格,理解框架后,代码很好阅读和调试
- 资源消耗低:对Redis访问是所有方案中最小的,redis的访问QPS和集群规模成正比,不随QPS变化发生变化
感谢大家的时间,希望所有人都有所收获!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











