







第一章 并行编程入门
1. 线程与共享内存:
线程: 一个正在运行的程序可以由几个子程序组成,它们分别维护着自己独立的控制流,可以并发执行,这些子程序被定义为“线程(Thread)”。
2.消息传递通讯:
消息传递通信模型使我们能指定计算时可能会使用的一系列任务之间如何进行通信。任务通过发送和接收具体消息来实现数据交换。
3.不同的并行粒度:
并行粒度被定义为计算与通讯之比。并行粒度受限于应用程序算法的内在特性。选择多大的并行粒度更多取决于算法本身和其运行的硬件环境。
分块(chunking):决定分给每一个人物的数据量。
并行粒度大小相关的折中因素:
⑴细粒度的并行
①计算强度低
②没有足够的任务来隐藏长时间的异步通信
③容易通过提供大量可管理的(即更小的)工作单元来实现负载均衡
④如果粒度太细,可能使任务之间的通信和同步开销过大,这样的并行实现有可能比原始的串行算法执行速度更慢
⑵粗粒度的并行:
①计算强度高
②完整的应用可作为并行的粒度
③难以有效实现负载均衡
4.数据共享和同步:
并发程序需要共享的情况:
①某个任务的输出依赖于另一个任务产生的结果。
②需要汇集中间计算结果。
第二章 OpenCL简介:
1.OpenCL标准
OpenCL标准有Khronos联盟制定。OpenCL API是按照C API制定的,由C和C++封装而成,可在支持OpenCL的设备上运行。
2.OpenCL规范:
OpenCL规范由四个模型组成:
①平台模型:描述了协同执行单个处理器及一个或多个能执行OpenCL代码的处理器(设备)。
②执行模型:定义了在主机上如何配置OpenCL环境以及如何在设备上执行Kernel函数。
③内存模型:定义被Kernel所用的抽象内存层次(memory hierarchy)
④编译模型:定义了如何将并发模型映射到物理硬件上。
OpenCL运行时(runtime)和驱动程序将这些抽象内存空间映射到物理层。
3.Kernel和OpenCL执行模型:
Kernel是OpenCL程序在设备上实际运行的那部分代码。编程人员的目标是尽可能细粒度地表示程序中的并行性。
OpenCL C并发执行单位是一个work-item,更通俗地说在计算单元上运行的Kernel程序的每一个实例都称为work-item,多个work-item则构成work-group。
4.平台和设备:
⑴主机--设备交互:
平台模型非常接近于某些GPU的硬件模型。在平台模型中一个主机协调在一个或多个OpenCL设备上的程序执行,平台可以被看作是厂商特定的OpenCL API实现。
平台模型将一个设备定义为一系列计算单元(compute unit),每个计算单元功能独立。计算单元又进一步划分为处理部件(processing element)。
涉及的函数:
clGetPlatformIDs;
clGetPlatformInfo;
clGetDeviceIDs;
clGetDeviceInfo;
⑵执行环境
主机端请求在设备上执行Kernel之前,必须先配置好用于设备传递命令和数据的上下文。
⑶上下文
上下文(context)协调主机--设备之间的交互机制,管理设备上可用的内存对象,跟踪针对每个设备新建的Kernel和程序。
涉及的函数:
clCreateContext;
clCreateContextFromType;
⑷命令队列
命令队列(Command queue)是主机端用于向设备端发送请求的行为机制。每个命令队列值关联一个设备。
涉及的函数:
clCreateCommandQueue;
任何一个指定主机与设备之间交互的API,总是以clEnqueue字样开头并且需要一个命令队列作为参数。
如:
clEnqueueReadBuffer //请求设备将数据发往主机端
clEnqueueNDRangeKernel //请求在设备上执行Kernel
⑸事件
任何操作被作为一个命令入队到一个命令队列中,即任何一个以clEnqueue字样开头的API调用---都会产生一个事件(Event)。
事件在OpenCL中的作用:
a.表示依赖
b.提供程序剖析机制
⑹内存对象
为了将数据传输到设备上,首先必须将其封装成内存对象。
OpenCL定义了两种不同的内存对象:
①buffer对象:
类似于C语言中的数组,由malloc()或new新建.
API函数
clCreateBuffer分配缓冲区,并返回一个内存对象。
buffer对象对所有与之与之关联的设备都是可见的。
涉及的函数:
clEnqueueWriteBuffer;
clEnqueueReadBuffer;
②Image对象:
image是考虑到具体设备优化而对实际数据存储进行抽象的OpenCL内存对象。
不要求所有的OpenCL设备都支持它们。应用程序使用
clGetDeviceInfo()可以查看该设备是否支持该特性。
image不能向数组对象一样直接进行引用。
image中使用格式描述符cl_image_format来表示。
涉及的函数:
clCreateImage2D;
clCreateImage3D;
⑺flush命令和finish命令:
clFlush阻塞直到命令队列中所有命令被转移出队列,这意味着这些命令已经准备就绪但无法保证执行完毕。
clFinish阻塞直到命令队列中的所有命令完成。
⑻新建一个OpenCL程序对象
OpenCL C代码(编写的代码在OpenCL设备上执行)称为程序(program),是称为Kernel的函数集合,Kernel是被调度安排到设备上运行的执行单位。
OpenCL程序在运行时通过调用一系列API进行编译,编译系统针对具体的设备进行优化。
新建Kernel的步骤:
①OpenCL源代码以字符串的形式存储。如果代码保存在文件中,则必须读到内存并存储为字符串数组。
②源代码通过调用
clCreateProgramWithSource转化为一个cl_program对象。
③使用clBuildProgram在多个支持OpenCL的设备上编译程序对象,如果编译错误,则报告错误信息。
涉及的函数:
clGetProgramInfo;
clCreateProgramWithBinary;
⑼OpenCL的Kernel:
最终阶段是通过从cl_program中抽取出Kernel,获取在设备上执行的cl_kernel对象。
kernel函数执行前需要一些参数设定,使用
clSetKernelArg函数指定每个Kernel参数,该函数接受一个Kernel对象,参数索引,大小和指针。
在所需的内存对象全部都传递到设备去Kernel参数设置之后,通过调用
clEnqueueNDRangeKernel执行Kernel。
涉及的函数:
clCreateKernel;
5.内存模型:
OpenCL采用定义一个抽象的内存模型,编程人员可以根据该模型编写代码,厂商可以映射到他们自己实际的内存硬件。
全局内存对设备上所有计算单位都是可见的。每次从主机端到设备端传输的数据都将驻留在全局内存中,反之亦然。
关键字:__global 数据类型 ; 如__global float *A;
常量内存不是专门为每种只读类型数据而设计的,而是便于所有work-item同时访问数据中的每个元素。它是全局内存的一部分,使用关键字 __constant
本地内存是高速暂存存储器(scratchpad memory),其地址空间对于计算设备是独一无二的,通常当作片上存储器。本地内存供workgroup共享,
相比全局内存,访问延迟更短,带宽更高。
私有内存只对于单个work-item可见,局部变量和非指针类型的Kernel参数默认情况下是私有的。
6.编写Kernel
Kernel以关键字__kernel开始,返回类型必须是void,必须制定指针所指向的地址空间。
buffer可以申明为全局内存(__global)或常量内存(__constant)。
image被分配到全局内存,可以选择性的访问限定符(__read_only, __write_only以及__read_write).
__local限定符用来申明一段内存,供work-group中所有work-item共享。
work-item执行完成,其状态信息和使用的本地内存都是临时的,如果需要保存计算结果,必须将结果回传到全局内存。
第三章、OpenCL设备架构
1.OpenCL支持基于块并行的宽松的一致性特性,可以在串行,对称处理器(symmetric multiprocessing, SMP),多线程和单指令多数据(single instruction multiple data,SIMD)或者向量设备上相对高效的运行。
2.超长指令字(very Long instruction word,VLIW)
算术逻辑部件(arithmetic logic units ,ALU)
加速处理单元(accelerated processing unit,APU)
同时多线程(Simultaneous Multithreading,SMT)
3.性能随频率的提升及其限制:
由于功耗(以非线性的方式依赖于主频)和散热的限制,继续提高CPU的主频已经明显不现实。
4.超标量执行:
在超标量或者更广义的乱序执行设计中,CPU负责维护指令流中指令间的依赖关系并在条件具备的时候,调度指令在空闲的功能单元上执行。
5.VLIW:
VLIW是一种严重依赖编译器的提高处理器指令并行性的方法。VLIW将依赖关系分析的工作转嫁给编译器,VLIW处理器发射的每一条指令都是一条由多条可执行的指令组合而成的长指令字。该指令可以直接映射到处理器的执行流水线上。
一段简单的类似汇编指令流的乱序执行。Add a,b,c 即a=b+c;
基于上图的乱序执行图的VILW执行:
6.SIMD和向量处理:
SIMD和向量并行则是直接允许硬件指令参与数据并执行。
一个SIMD指令表示将同样的操作在多个数据元素上同时执行。
SIMD执行的优势相对于ALU来说,可以同时减少调度和指令译码部件逻辑电路的数量。
每条SIMD指令顺序调度但在多个ALU上同时执行
7.硬件多线程
在指令和数据并行之后的第三种常见并行形式是线程并行,也就是多个独立指令流的执行。
同时多线程如下图:
基于时间片芯片多线程
8.多核架构:
提高每时钟周期执行任务量最简单的方法是简单地将单核在芯片上克隆多次。最简单的情况是在缓存一致性协议的支持下通过内存共享数据,这些核的每一个都可以最大程序地独立运行。
AMD Radeon HD 6970概要示意图
AMD Radeon HD 6970 GPU的架构。设备对分为两个部分,分别有各自的wave调度器对每一部分的指令进行调度和分发执行。
24个16路SIMD核,每一路都可以运行4路VLIW指令,并包含私有的L1高速缓存和本地数据共享(Local Data Share, LDS)
NVIDIA GTX 580
NVIDIA GTX580架构。此设备有16个核,每个核上有2个16路的SIMD阵列。每个核包含一个共享内存/L1 Cache,
一组SPU阵列以执行一些复杂操作。
第四章 OpenCL基本实例
1.简单的矩阵相乘:
串行C代码:
//Iterate over the rows of Matrix A
for(int i=0;i<heightA;i++)
{
//Iterate over the columns of Matrix B
for(int j=0;j<widthB;j++)
{
C[i][j]=0;
//Multiply and accuulate the values in the current row of A and column of B
for(int k=0;k<widthA;k++)
{
C[i][j]+=A[i][k]*B[k][j];
}
}
}
由于外层两个for循环相互独立,因此可以直观的将串行实现映射到OpenCL上,也就是说,我们可以对输出矩阵的每个元素创建一个单独的
work-item。Kernel中,两个外层循环映射到一个二维的work-item集合上。
矩阵相乘中,各输出元素之间相互独立。每个work-item读取矩阵A中它需要的那行数据和矩阵B中它所需的那列数据。将读取到数据相乘之后,结果写入矩阵C中相应的位置上。
并行OpenCL代码:
//width A=HeightB for valid matrix multiplication
__kernel void simpleMultiply(
__global float *outputC,
int widthA,
int heightA,
int widthB,
int heightB,
__global float *inputA,
__global float *inputB)
{
//Get global position in Y direction
int row=get_global_id(1);
//Get global position in X direction
int col=get_global_id(0);
float sum=0.0f;
//Calculate result of one element of Maxtrix C
for(int i=0;i<widthA;i++)
{
sum+=inputA[row*width+i]*inputB[i*widthB+col];
}
outputC[row*widthB+col]=sum;
}
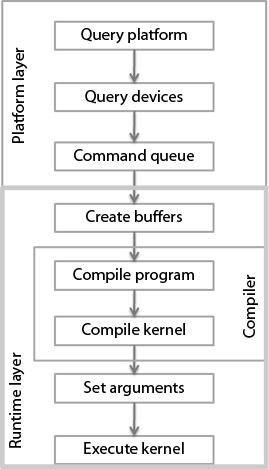
一个完整的OpenCL编程步骤















 5234
5234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









