







梯度下降法学习笔记
前言
梯度下降法是一个经典的优化算法,在机器学习领域非常常见,很多机器学习算法最后都归结为求解最优化问题。在各种最优化算法中,梯度下降法是最简单、最常见的一种,在深度学习的训练中被广为使用。
梯度下降法(GD)
直观解释
通俗来说,梯度就是表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在当前位置的导数。
讲到梯度下降法时,往往都会有这么一个例子:想象你站在山顶,现在你想以最快的速度下山,那么你肯定会选择最陡的路下山,走到一个位置,同样继续向着当前位置最陡峭的位置下山。简单来说,这就是所谓的梯度下降法。
但是你可能也想到了,这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。

梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。
理论推导
“沿着梯度的反方向(坡度最陡)”是我们日常经验得到的,其本质的原因到底是什么呢?为什么局部下降最快的方向就是梯度的负方向呢?
这里直接给出梯度下降算法的公式:
θ = θ 0 − η ⋅ ∇ f ( θ ) \theta = \theta_0 - \eta \cdot \nabla f(\theta) θ=θ0−η⋅∇f(θ)
如果你想要了解具体的理论推导,可以点击这里:为什么局部下降最快的方向就是梯度的负方向?
简单示例
让我们用一个具体的例子来进一步展示
假定目标函数 f ( x ) = x 2 f(x) = x^2 f(x)=x2,我们希望得到 f ( x ) f(x) f(x) 的最小值。
具体来说,我们让 x x x 从 x = 10 x=10 x=10 开始迭代 10 次,设置 η = 0.2 \eta = 0.2 η=0.2,观察 x x x 的变化。
def gd(eta):
x = 10
results = [x]
for i in range(10):
x -= eta * 2 * x
results.append(x)
print('epoch 10, x = {}, f(x) = {}'.format(x, results[-1]))
return results
results = gd(0.2)
epoch 10, x = 0.06046617599999997, f(x) = 0.06046617599999997
def show_trace(results):
n = max(abs(min(results)), abs(max(results)))
f_line = np.arange(-n, n, 0.01)
plt.figure()
plt.plot(f_line, [x**2 for x in f_line])
plt.plot(results, [x**2 for x in results], '-o')
plt.grid()
plt.show()
show_trace(results)

学习率
学习率(learning rate)决定目标函数能否收敛到局部最小值,以及何时收敛到最小值
我们同样使用上面的例子
show_trace(gd(0.05))
show_trace(gd(1.1))
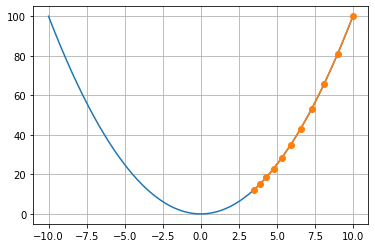
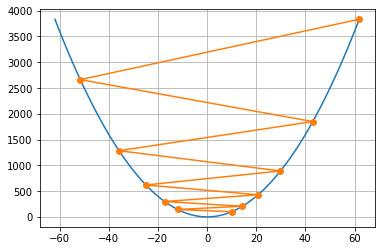
可以发现,不同学习率下的效果不尽相同:如果学习率太小,将导致 x 的更新非常缓慢;如果使用过高的学习率,则得到的解就会振荡,甚至可能发散。
多元梯度下降
在实际的应用场景中,我们面对的往往不是简单的一维情况,现实的问题往往是高维的。
现在我们考虑将 x x x 拓展到 x = [ x 1 , x 2 , … , x n ] T x = [x_1, x_2, \dots, x_n]^T x=[x1,x2,…,xn]T
因此有
∇ f ( x ) = [ ∂ f ( x ) ∂ x 1 , ∂ f ( x ) ∂ x 2 , … , ∂ f ( x ) ∂ x n ] T \nabla f(x) = [\frac{\partial f(x)}{\partial x_1}, \frac{\partial f(x)}{\partial x_2}, \dots, \frac{\partial f(x)}{\partial x_n}]^T ∇f(x)=[∂x1∂f(x),∂x2∂f(x),…,∂xn∂f(x)]T
同样的,利用泰勒展开式可以得到:
x = x 0 − η ⋅ ∇ f ( x ) x = x_0 - \eta \cdot \nabla f(x) x=x0−η⋅∇f(x)
如果你想要了解具体的理论推导,可以点击这里:为什么局部下降最快的方向就是梯度的负方向?
假定目标函数 f ( x ) = x 2 + 2 y 2 f(x) = x^2 + 2y^2 f(x)=x2+2y2。
x x x 初始位置为 [ − 5 , − 2 ] [-5, -2] [−5,−2] 迭代 20 次,设置 η = 0.1 \eta = 0.1 η=0.1,观察 x x x 的变化。
def train_2d(trainer, steps=20, f_grad=None):
"""用定制的训练机优化2D目标函数。"""
# `s1` 和 `s2` 是稍后将使用的内部状态变量
x1, x2, s1, s2 = -5, -2, 0, 0
results = [(x1, x2)]
for i in range(steps):
if f_grad:
x1, x2, s1, s2 = trainer(x1, x2, s1, s2, f_grad)
else:
x1, x2, s1, s2 = trainer(x1, x2, s1, s2)
results.append((x1, x2))
print(f'epoch {i + 1}, x1: {float(x1):f}, x2: {float(x2):f}')
return results
def show_trace_2d(f, results):
"""显示优化过程中2D变量的轨迹。"""
plt.figure()
plt.plot(*zip(*results), '-o', color='#ff7f0e')
x1, x2 = np.meshgrid(np.arange(-5.5, 1.0, 0.1),
np.arange(-3.0, 1.0, 0.1))
plt.contour(x1, x2, f(x1, x2), colors='#1f77b4')
plt.xlabel('x1')
plt.ylabel('x2')
def f_2d(x1, x2): # 目标函数
return x1 ** 2 + 2 * x2 ** 2
def f_2d_grad(x1, x2): # 目标函数的梯度
return (2 * x1, 4 * x2)
def gd_2d(x1, x2, s1, s2, f_grad):
g1, g2 = f_grad(x1, x2)
return (x1 - eta * g1, x2 - eta * g2, 0, 0)
eta = 0.1
show_trace_2d(f_2d, train_2d(gd_2d, f_grad=f_2d_grad))
epoch 20, x1: -0.057646, x2: -0.000073

如果我们根据上面推导出的公式来训练模型,那么我们每次更新 x x x 的迭代,要遍历训练数据中所有的样本进行计算,我们称这种算法叫做批梯度下降(Batch Gradient Descent,简称 BGD)
随机梯度下降(SGD)
由于批量梯度下降法在更新每一个参数时,都需要所有的训练样本,所以训练过程会随着样本数量的加大而变得异常的缓慢。随机梯度下降法(Stochastic Gradient Descent,简称 SGD)正是为了解决批量梯度下降法这一弊端而提出的。
简单来说,在 SGD 算法中,每次更新的迭代,只计算一个样本。
θ = θ 0 − η ⋅ ∇ f i ( θ ) \theta = \theta_0 - \eta \cdot \nabla f_i(\theta) θ=θ0−η⋅∇fi(θ)
每次迭代的计算成本从梯度下降的 O(n) 降至常数 O(1)
值得一提的是,随机梯度 ∇ f i ( θ ) \nabla f_i(\theta) ∇fi(θ) 是对完整梯度 ∇ f ( θ ) \nabla f(\theta) ∇f(θ) 的公正估计,因为
E i ∇ f i ( x ) = 1 n ∑ i = 1 n ∇ f i ( x ) = ∇ f ( x ) \mathbb{E}_i \nabla f_i(x) = \frac{1}{n} \sum_{i = 1}^n \nabla f_i(x) = \nabla f(x) Ei∇fi(x)=n1i=1∑n∇fi(x)=∇f(x)
另一方面,由于存在一定随机性,准确度下降,并不是每次迭代都向着整体最优化方向,但大量的更新总体上沿着减少 loss 的方向前进的,因此最后也能收敛到最小值附近。随机梯度下降的过程大概是这样的:

你可以点击这里了解 随机梯度下降的收敛性分析。
小批量梯度下降法(MBGD)
小批量梯度下降法(Mini-batch Gradient Descent,简称 MBGD)正是介于上面这两个算法之间,不使用全部样本,也不只使用一个样本,因此相对来说算法的训练过程比较快,也保证最终参数训练的准确率。在深度学习模型中广泛应用的随机梯度下降法往往指的也就是小批量梯度下降法。
具体来说,MBGD 在每次更新参数时从 n 个样本的训练集中随机选取 m 个样本,更新计算时也只用到这 m 个样本。
θ = θ 0 − η ⋅ 1 m ∑ i = 1 m ∇ f i ( θ ) \theta = \theta_0 - \eta \cdot \frac{1}{m} \sum_{i=1}^m \nabla f_i(\theta) θ=θ0−η⋅m1i=1∑m∇fi(θ)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











