







AutoEncoder 学习笔记
前言
AutoEncoder 作为神经网络里的一类模型,采用无监督学习的方式对高维数据进行特征提取和特征表示,其目的是重构输入(最小化输入和输出之间的差异),而不是在给定输入的情况下预测目标值。
AutoEncoder 简介

上面这张图很好的描述了 AutoEncoder 的工作原理,首先是一个数据输入,它可以是图片或是一串序列,就像上图描述的一样,一幅图片经过一个 Encoder 网络之后,得到了 Compressed representation ,也就是我们所谓的这个图像的「特征」,之后将得到的「特征」再次输入到 Decoder 网络中,获得图像的输出,将「特征」还原成了图片。

我们可以假设图中的网络是这样的,输入经过全连接层得到 Feature 之后再次进入全连接层,得到最后的输出。
可以预见的是,我们的通过这个网络得到的输出必然是有「损失」的,因为我们是经过「压缩」图像,然后再「还原」图像,许多的细节在这个过程中丢失了。
和许多网络一样,我们这么做的目的无非是为了提取特征。
AutoEncoder 模型实现(PyTorch)
下面我们通过一个例子来实现 AutoEncoder,在这个例子中,我们通过一个「异常检测」的例子来进行说明。
模型实现
假设我们现在有 n 天的时序数据,需要从这 n 天的时序数据中寻找异常点。
import numpy as np
import pandas as pd
import torch
import torch.nn.functional as F
from torch import nn, optim
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
一般的,首先进行数据预处理,归一化,将值压缩到 0-1 之间。
# data: List[DataFrame]
data = get_data()
dataset = []
scaler = MinMaxScaler()
for daily in data:
x = scaler.fit_transform(daily['Total'].values.reshape(-1, 1))
dataset.append(x.flatten())
dataset = torch.tensor(dataset, dtype=torch.float32).to(device)
接下来就是定义网络结构,你可以参考之前的网络结构图,下面的代码都是一些基本操作,全连接,Dropout,ReLU;当然,你需要保证 encoder_input 和 decoder_output ,encoder_output 和 decoder_input 的维度是一致的。
class AE(nn.Module):
def __init__(self, input_size):
super(AE, self).__init__()
self.encoder = nn.Sequential(nn.Linear(input_size, 24), nn.Dropout(0.5), nn.ReLU(True),
nn.Linear(24, 10), nn.Dropout(0.5), nn.ReLU(True))
self.decoder = nn.Sequential(nn.Linear(10, 24), nn.ReLU(True),
nn.Linear(24, input_size), nn.Sigmoid())
def forward(self, input):
en_out = self.encoder(input)
de_out = self.decoder(en_out)
return de_out, en_out
然后设置 criterion 和 optimizer。
model = AE(72).to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
对于 Loss 的计算,我们这样考虑,在监督学习中,我们往往将模型的输出和对应的 Label 进行对比,然而在无监督学习中,AE 中我们只需要对比 input 和 output。具体来说每次的输入是 1 天的时序数据,然后最小化 input 和 output 之间的误差即可。
for e in range(200):
for d in dataset:
out, feature = model(d)
loss = criterion(out, d)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if e % 10 == 0:
print('Epoch: {}, Loss: {:.5f}'.format(e, loss.item()))
训练结果
完成了对模型的训练之后,我们可以简单的看一下模型的效果:
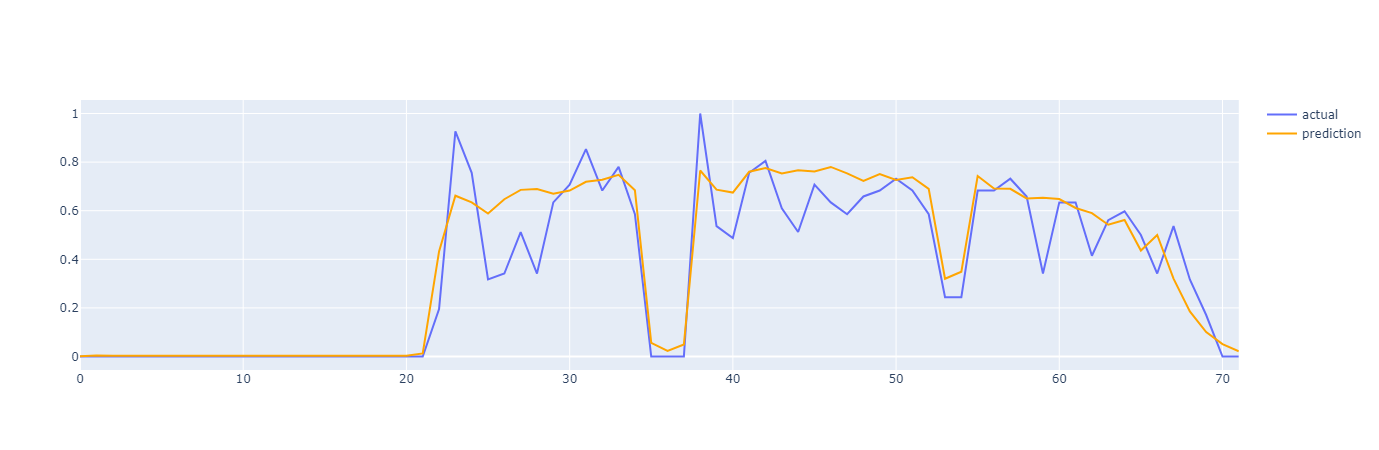
总的来说,我们还是得到了一个较为符合趋势的输出序列,接下来你可以通过计算误差,指定阈值等操作进行异常值检测,在此就不过多叙述了。
完整代码
到这里,我们就实现了一个简单的 AE 网络,完整代码如下:
import numpy as np
import pandas as pd
import torch
import torch.nn.functional as F
from torch import nn, optim
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class AE(nn.Module):
def __init__(self, input_size):
super(AE, self).__init__()
self.encoder = nn.Sequential(nn.Linear(input_size, 24), nn.Dropout(0.5), nn.ReLU(True),
nn.Linear(24, 10), nn.Dropout(0.5), nn.ReLU(True))
self.decoder = nn.Sequential(nn.Linear(10, 24), nn.ReLU(True),
nn.Linear(24, input_size), nn.Sigmoid())
def forward(self, input):
en_out = self.encoder(input)
de_out = self.decoder(en_out)
return de_out, en_out
def main():
# data: List[DataFrame]
data = get_data()
dataset = []
scaler = MinMaxScaler()
for daily in data:
x = scaler.fit_transform(daily['Total'].values.reshape(-1, 1))
dataset.append(x.flatten())
dataset = torch.tensor(dataset, dtype=torch.float32).to(device)
model = AE(72).to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for e in range(200):
for d in dataset:
out, feature = model(d)
loss = criterion(out, d)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if e % 10 == 0:
print('Epoch: {}, Loss: {:.5f}'.format(e, loss.item()))
if __name__ == '__main__':
main()
Denoising AutoEncoders
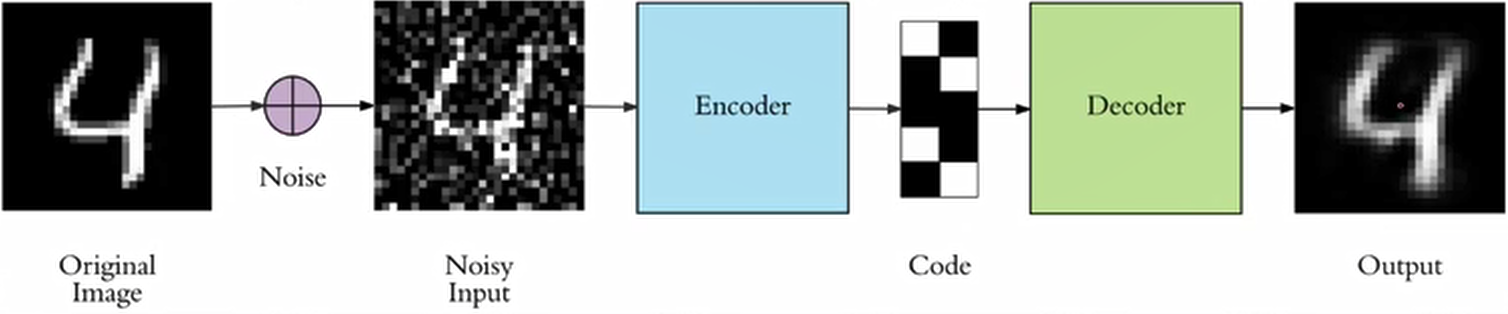
Vincent 在 2008 的论文中提出了 AutoEncoder 的改良版,简单来说就是在 input 上面加 noise(如高斯噪声,椒盐噪声),在传统 AutoEncoder 的基础上增强模型的鲁棒性。在加入噪声的情况下对模型进行训练,使得中间提取的特征更加具有鲁棒性,从而得到一个较好的输出结果。
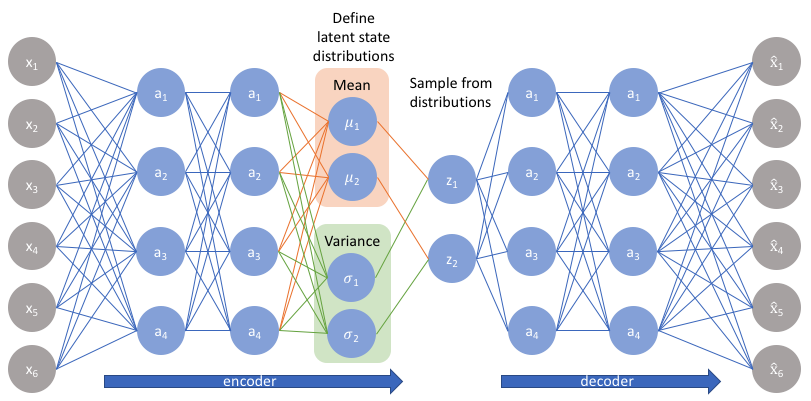
Variational AutoEncoders
Vairational AutoEncoder(VAE)是 Kingma 等人与 2014 年提出。VAE 比较大的不同点在于:VAE 不再将输入 input 映射到一个固定的抽象特征 feature 上,而是假设样本 input 的抽象特征 feature 服从(μ,σ^2)的正态分布,然后再通过分布生成抽象特征 feature。最后基于 feature 通过 decoder 得到输出。模型框架如下图所示:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











