







方案1:使用浏览器的开发者功能,打印输出
1.使用浏览器打开指定文章的界面
2.按下快捷键"F12",打开开发者工具窗口
3.跳转到"Console"控制台选项栏,输入以下代码:
(function(){ $("#side").remove(); $("#comment_title, #comment_list, #comment_bar, #comment_form, .announce, #ad_cen, #ad_bot").remove(); $(".nav_top_2011, #header, #navigator").remove(); $(".p4course_target, .comment-box, .recommend-box, #csdn-toolbar, #tool-box").remove(); $("aside").remove(); $(".tool-box").remove(); $("#toolBarBox").remove(); $("main").css('display','content'); $("main").css('float','left'); $("body").css('min-width',0); $("#mainBox").css('width','90%'); $(".main_father.clearfix.d-flex.justify-content-center").css("width","90%"); $(".option-box").remove(); window.print(); })();其中"$(".main_father.clearfix.d-flex.justify-content-center").css("width","90%");"的90表示输出文件中内容的百分比,酌情调整即可,输入完成之后敲回车。
4.输入保存的路径,名字,点击确定即可
方案2:利用Python脚本
此部分源于Python爬虫-CSDN博文存为HTML/PDF文档_Tr0e的博客-CSDN博客
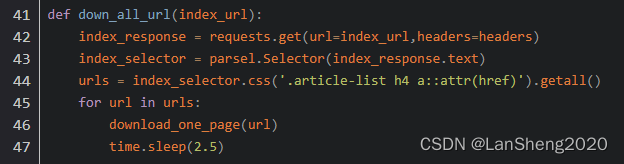
在文章中的最终代码处的第44行代码依照文章的方法按照实际情况做个修改
最终的代码如下:
import pdfkit import requests import parsel import time import re import os src_html = ''' <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Document</title> </head> <body> {content} </body> </html> ''' headers = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36' } def change_title(name): pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |' new_title = re.sub(pattern, "_", name) # 替换为下划线 return new_title def download_one_page(page_url): response = requests.get(url=page_url, headers=headers) html = response.text selector = parsel.Selector(html) title = selector.css('.title-article::text').get() title = change_title(title) # 提取标签为article 的内容 article = selector.css('article').get() # 保存HTML文档 with open(title + '.html', mode='w+', encoding='utf-8') as f: f.write(src_html.format(content=article)) #print('%s.html 已保存成功' % title) # 将HTML转换成PDF config = pdfkit.configuration(wkhtmltopdf=r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe') pdfkit.from_file(title+'.html', title+'.pdf', configuration=config) #print('%s.pdf 已保存成功' % title) os.remove(title + '.html') #print('%s.html 已删除成功'% title) def down_all_url(index_url): #cnt = 0 index_response = requests.get(url=index_url,headers=headers) index_selector = parsel.Selector(index_response.text) #print("test print 1") urls = index_selector.css('.baidu_pl p a::attr(href)').getall() #这里根据原文章教程利用开发环境工具替换key元素 #print("test print 2") for url in urls: #cnt = cnt+1 #print("file cnt = ",cnt) download_one_page(url) time.sleep(0.1) if __name__ == '__main__': print("Files begin saving...") down_all_url('xxx') #这里"xxx"替换实际的专栏总列表链接 print("All files has been saved in PDF filetype.") """ 参考:https://bwshen.blog.csdn.net/article/details/119784779 在源代码的基础上添加了特殊字符的替换,因为有一些文章会有一些特殊字符,可能导致Python运行报错。 导入的模块应该事先安装好,pdfkit软件也需要单独下载安装好。 作者:LanSheng2020 """















 1005
1005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











