










1. 字符编码和解码
在Java中,字符编码指的是:将字符串转换成字节数组,转换的方法是通过方法getByte()实现的,该方法可以指定编码表,也可以不指定,不指定编码表则使用默认的编码表。下面,我们将通过字符编码和解码,解决如何给字符编码以及解码。
1.1 字符编码
下面的例子,将中文字符进行编码,并指定编码表。控制台的输出结果为:
-60, -29, -70, -61,
-28, -67, -96, -27, -91, -67,
从输出结可以知道,GBK编码的中文字符,一个字符占两个字节。UTF-8编码的中文字符,一个字符占3个字节。
package com.itheima.entranceExam.blog;
import java.io.IOException;
public class encodeTest {
public static void main(String[] args) throws IOException {
String s = "你好";
//编码:将字符串变成字节数组,指定编码表为GBK
byte[] b1 = s.getBytes("GBK");
//编码:将字符串变成字节数组,指定编码表为UTF-8
byte[] b2 = s.getBytes("UTF-8");
//遍历字节数组中的元素
for(byte b : b1) {
System.out.print(b+", ");
}
System.out.println();
//遍历字节数组中的元素
for(byte b : b2) {
System.out.print(b+", ");
}
}
}1.2 解码
下面我们对1.1节中编码的中文字符进行解码,解码就是将字符转成的字节数组,从新转换成原来的字符。解码时可以指定编码表也可以不指定,不指定编码表则使用默认是编码表。
package com.itheima.entranceExam.blog;
import java.io.IOException;
public class encodeTest {
public static void main(String[] args) throws IOException {
String s1 = "你好";
//编码,指定编码表为GBK
byte[] b1 = s1.getBytes("GBK");
//解码,指定编码表为GBK
String s2 = new String(b1, "GBK");
System.out.println(s2);//输出"你好",没有乱码
}
}1.3 编码表不一致导致的问题
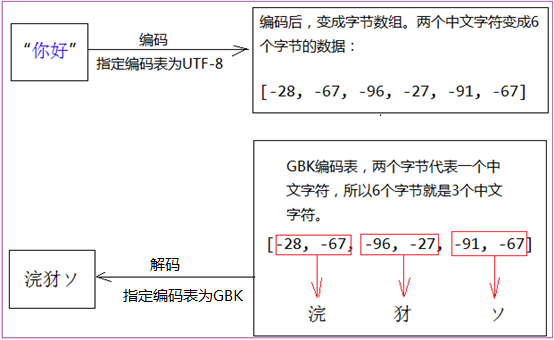
注意:当我们编码使用的编码表和解码使用的编码表不一致时,则会出现乱码。下面的例子编码时使用的编码表是UTF-8,而解码使用到编码表是GBK。将字符串"你好"使用UTF-8进行编码,解码时使用GBK,为什么输出结果是三个中文字符"浣犲ソ"?下面我们通过图片来分析:UTF-8编码中文字符串"你好",这两个中文字符串变成6个字节的字节数组。解码时使用GBK编码表,GBK编码表将字节数组中的,每两个联系的字节数组变成一个中文字符,长度为6的字节数组就变成3个中文字符,所以下面例子的2个中文字符解码后,会出现3个中文字符。
代码:
package com.itheima.entranceExam.blog;
import java.io.IOException;
public class encodeTest {
public static void main(String[] args) throws IOException {
String s1 = "你好";
//编码,指定编码表为UTF-8
byte[] b1 = s1.getBytes("UTF-8");
//解码,指定编码表为GBK
String s2 = new String(b1, "GBK");
System.out.println(s2);//输出"浣犲ソ"
}
}1.4 解决乱码问题
当编码和解码使用的编码表不一致时,会出现乱码,出现乱码该如何解决呢?
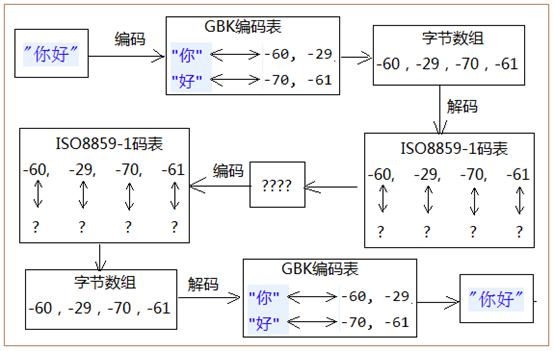
下面的例子演示:编码时使用GBK编码表,解码时使用ISO8859-1编码表,致使出现乱码,如何解决乱码吗?
下面结合图片进行说明(代码也在下面):
出现乱码的应用是,GBK编码表中一个中文字符对应两个字节数组数据,ISO8859-1是拉丁码表和欧洲码表,ISO8859-1编码表一个二进制的字节数组数据对应一个字符。所以两个中文字符GBK编码后,再使用ISO8859-1解码时会出现4个字符的乱码。解决该乱码的步骤是:
1. 将ISO8859-1解码后返回的字符串进行ISO8859-1编码,编码后返回字节数组。
2. 将上面的字节数组进行GBK解码,就能获得原来的中文字符了。
注意:编码使用GBK,解码使用UTF-8。为了解决乱码,二次编码如果使用UTF-8,解码使用GBK时,会出现问题,所以上面的方案不是在任何编码中都可以使用的。
代码:
package com.itheima.entranceExam.blog;
import java.io.IOException;
public class encodeTest {
public static void main(String[] args) throws IOException {
String s = "你好";
//编码,使用GBK编码表
byte[] b1 = s.getBytes("GBK");
//解码,使用ISO8859-1编码表
String s1 = new String(b1,"ISO8859-1");
//下面一行输出结果为:ÄãºÃ,出现乱码,因为编码和解码使用的编码表不同
System.out.println(s1);
//下面分析如何解决乱码问题
//1. 将ISO8859-1解码获得的字符串s1,使用ISO8859-1编码表进行再编码,返回字节数组
byte[] b2 = s1.getBytes("ISO8859-1");
//2. 将字节数组使用GBK字符集进行解码
String s2 = new String(b2, "GBK");
//输出结果:你好,乱码问题解决了
System.out.println(s2);
}
}2. 字符联通
2.1 字符联通问题
新建一个文本文件,在该文本文件中输入“联通”两个字符,保存并关闭文本文件。重新打开文本文件,发现文本文件中出现了乱码,如下图。
这是为什么呢?因为输入“联通”字符时,使用的是系统默认的中文编码表GBK,而文本文件是一个应用程序,它默认使用的是UTF-8编码,所以再次打开时会出现乱码。
所有当保存文本文件时,选择另存为UTF-8编码方式,就不会出现乱码了。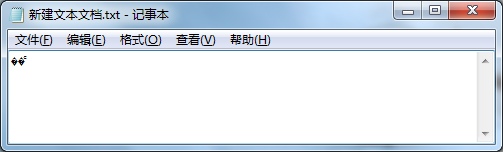
2.2 GBK和UTF-8编码识别原理
GBK编码的中文,2个字节代表一个中文。UTF-8编码的中文,3个字节代表一个中文。不论是GBK还是UTF-8,中文对应的编码都是负数,既然都是负数,那么怎么知道只读3个字节或者只读2个字节作文中文呢?
下面通过图片分析:
转换流读取方法是一次读取一个字节,两个字节变成一个中文字符。而FileReader的read方法是一次读取两个字节,返回一个中文。但是如果数据是UTF-8编码出来的数据,使用GBK解码时会出现乱码。而且在UTF-8编码表中,有可能2个字节代表一种字符,有可能3个字节代表一个中文。那如何知道读取两个字节还是3个字节呢?
其实UTF-8的编码表都添加一个标识头信息。根据该标识头信息,就知道一次读取1个字节,还是2个字节或者是3个字节。在IO包下的DataInputStream下有UTF-8标志头说明信息,下面一节讲解UTF-8的格式,来说明标志头信息的作用。

2.3 UTF-8编码格式
在IO包下找到DataInputStream,找到UTF-8修改版,就可以看到UTF-8的格式信息,如下。
一个字节代表一个字符:一个字节的8位数据中,头尾数据为0,表示该一个字节代表一个字符,如下图:

两个字节代表一个字符:第一个字节的前3位是110,第2个字节的前2位是10,说明两个字节代表一个字符,如下图:
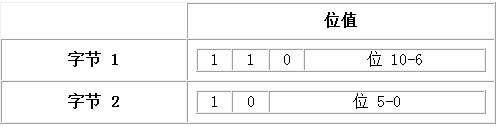
三个字节代表一个字符:第1个字节的前4位是1110,第2个字节的前2位是10,第3个字节的前2位是10,说明三个字节代表一个字符。如下图:

2.4 分析UTF-8的编码格式以及“联通”问题产生的原因
下面我们通过代码例子,分析2.3节中的UTF-8的编码格式,并且分析2.1节中字符联通问题产生的原因。
package com.itheima.entranceExam.blog;
import java.io.IOException;
public class encodeTest {
public static void main(String[] args) throws IOException {
String s = "联通";
//GBK编码
byte[] buf = s.getBytes("GBK");
//变量字节数组
for(byte b : buf) {
//&255 是为了去掉前面的数据,只保留后面8位二进制数据,因为一个字节占8为
System.out.println(Integer.toBinaryString(b&255));
}
}
}11000001
10101010
11001101
10101000
下面通过图片分析该输出结果的中隐含的UTF-8编码格式,已经字符联通问题原因:
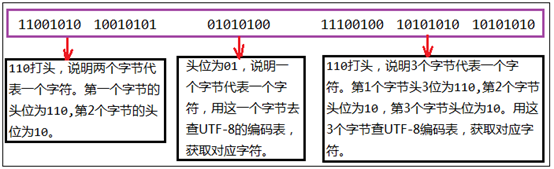
分析字符联通产生的原因:
上面代码中,中文字符使用GBK编码,但是编码后的的二进制数据正好和UTF-8格式吻合:第1个字节110开头,说明两个字节代表一个字符(110打头的代表第1个字节,10打头的代表第2个字节)。所以文本编辑器把这些字符("联通")去查UTF-8编码表,解码成了UTF-8对应的字符,所以显示的结果会出现问题。这就是2.1节问题产生的原因。
如果在文本文件中输入中文 " 你联通 " ,保存文本文件并关闭。再次打开后,就不会出现2.1那样的问题,因为中文 " 你 "在编码表中对应的二进制数据不符合UTF-8的格式,所以编辑器使用GBK解码,后面的 " 联通 "当然也使用GBK解码,所以不会出现2.1的问题:














 56万+
56万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









