







Educational Codeforces Round 178 Div. 2
A题(2104A)Three Decks

老样子,懒得打字儿
-
题意:T组数据,每组有三个数,保证a<b<c,看能不能通过只减去c中一部分加到a和b中去,使得a、b、c三个数相等
-
思路:还是很好想的,首先sum必须是3的倍数,不然怎么可能相等嘛
- 但有一个地方,就是只移动c的情况下,只需要判断是3的倍数就可以吗?
- 显然不是,数据还是很良心的,第四组数据,1,5,6的和为12
- 问题很显然,5比12/3大了,两种判断方法,一种直接判断 b < = s u m / 3 b<=sum/3 b<=sum/3
- 茉莉是用的 c − b + a > = s u m / 3 c-b+a>=sum/3 c−b+a>=sum/3,呃,不知道为啥最近脑回路有点唐哈哈
-
如果用b来判断就没什么好证明的了,因为b不能减少,所以不能到达答案的状态,如果你要考虑茉莉的那个写法,请你别考虑哈哈
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#include<vector>
#include<map>
#include<iomanip>
using namespace std;
typedef long long ll;
inline ll read(){
ll w=1,mmm=0;
char ch=getchar();
while(ch<'0'||ch>'9') {if(ch=='-') w=-1;ch=getchar();}
while(ch>='0'&&ch<='9') {mmm=(mmm<<1)+(mmm<<3)+(ch^48);ch=getchar();}
return w*mmm;
}
void solve(){
ll a=read(),b=read(),c=read();
ll sum=a+b+c;
if(sum%3==0){
ll each=sum/3;
if(b>each){
printf("NO\n");
return;
}
printf("YES\n");
}
else printf("NO\n");
}
int main() {
int t=read();
while(t--)
solve();
return 0;
}
茉莉特意去写了一个用b判断的版本诶,是不是很贴心莉?
B题(2104B)Move to the End


- 题意:T组数据,每组会有n个数,然后呢,对于n的每一个i询问,在可以把数组中的任意一个数移动到最后的情况下,k个数的后缀和(后k个数)最大是多少?
- 思路:我们考虑这一步移动到底有什么作用
- 没移动前,是n到n-k+1的和,要是移动这个区间内的数,显然和不变
- 那么我们要移动1到n-k之间一个数到最后,贪心的想就是最大的一个,把前面1到n-k的最大值挪到最后,那么第n-k+1个数就被移出我们计算和的区间了
- 那么显然了,移动这一步产生的价值就是max{ a i a_i ai}- a n − k + 1 a_{n-k+1} an−k+1,i∈[1,n-k]
- 茉莉温馨提示,注意细节喔,max{ a i a_i ai}一定比 a n − k + 1 a_{n-k+1} an−k+1大吗?
- 求解每个点的前缀最大值,一遍O(n)就过了
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#include<vector>
#include<map>
#include<iomanip>
using namespace std;
typedef long long ll;
inline ll read(){
ll w=1,mmm=0;
char ch=getchar();
while(ch<'0'||ch>'9') {if(ch=='-') w=-1;ch=getchar();}
while(ch>='0'&&ch<='9') {mmm=(mmm<<1)+(mmm<<3)+(ch^48);ch=getchar();}
return w*mmm;
}
const int maxn=2e5+10;
ll mmax[maxn],a[maxn];
void solve(){
int n=read();
for(int i=1;i<=n;i++) a[i]=read();
for(int i=1;i<=n;i++) mmax[i]=max(mmax[i-1],a[i]);
ll sum=0;
for(int i=n;i>=1;i--){
sum+=a[i];
ll ans;
if(a[i]<mmax[i-1]) ans=sum-a[i]+mmax[i-1];
else ans=sum;
printf("%lld ",ans);
}
printf("\n");
for(int i=1;i<=n;i++) mmax[i]=0;
}
int main() {
int t=read();
while(t--)
solve();
return 0;
}
C题(2104C)Card Game

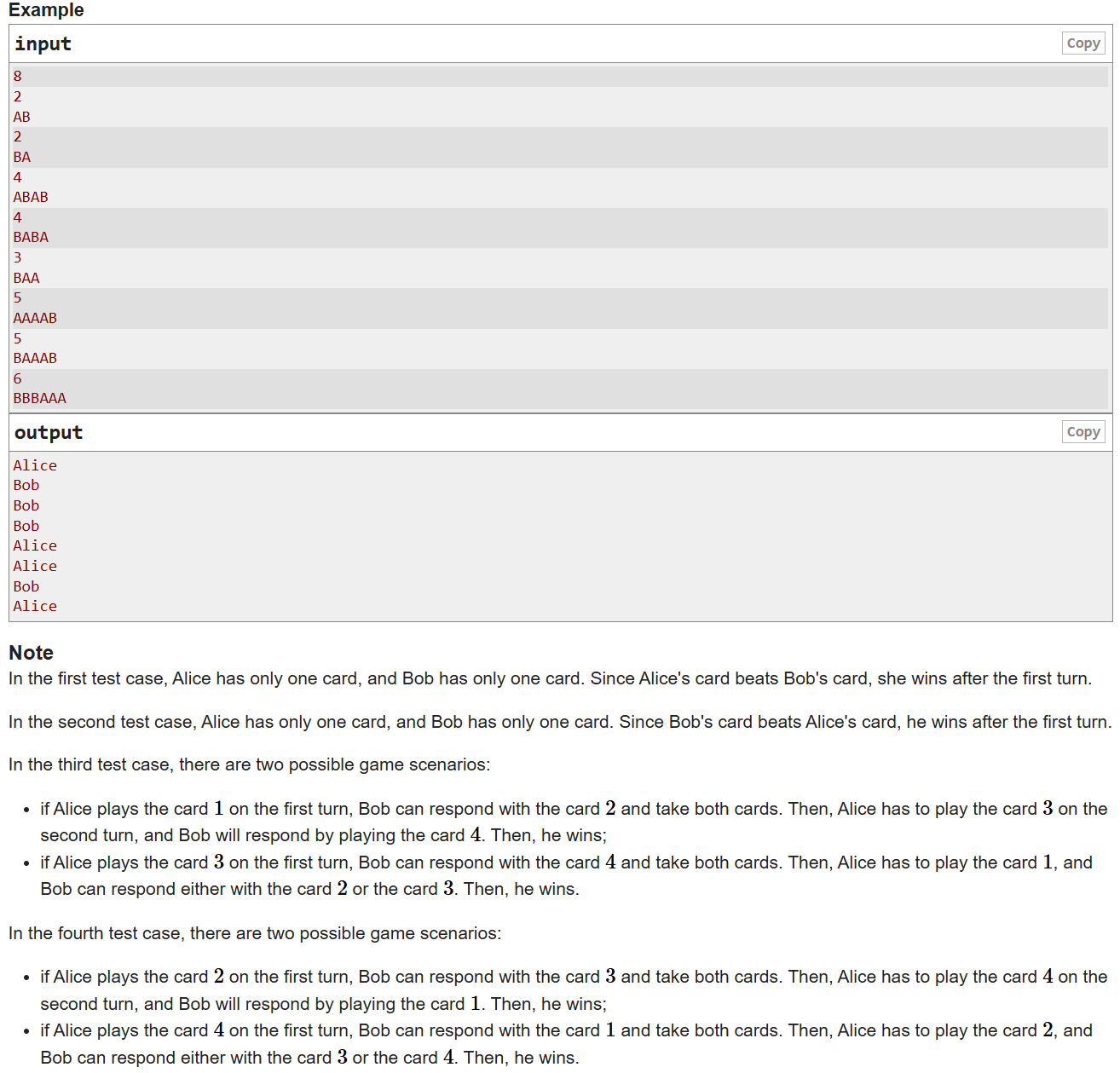
- 题意:T组数据,每组有n张牌,A表示该张牌归Alice,B表示该张牌归Bob
Alice和Bob打牌,正常来说第i张牌大于第1到第i-1张牌,除了第1张牌大于第n张牌
两张牌都归赢家,看最后谁茉有牌了谁就输了 - 其实没有那么麻烦,就是看Alice有没有先手必胜策略,只要第一把寄了,那后面的也赢不了了(在Alice眼光不呆滞的情况下哈)
- 思路:Alice先出,Bob是有优势的,显然Alice赢的机会更少,所以我们考虑Alice怎么赢
- 先把n=2干掉,n=2的时候第1张牌大于第2张,在谁手上谁就赢
- 假设一方只有一张牌的情况下,除了n=2已经讨论过的情况,那另一方是不是必赢?
- OK,这两种都讨论过了,剩下的就是Alice和Bob都有不止一张牌了,这才是博弈的精髓,呼呼
- 因为Alice先出,如果第n张牌在Bob手里,不论Alice怎么折腾一定会输,即使第1张牌在Alice手里,Bob后出,用一张除了n的牌就能赢,Alice不出第1张牌绝对输
- 所以Alice一定要有第n张牌才可以,但是第n张牌比第1张牌小,假如Alice先出这个,Bob拿第1张来Alice不是炸缸了?
- 所以其一,假如第1张牌就在Alice手里,那么Bob该如何应对呢?尽梨了,英不了.jpg
- 其二,假如第n-1张牌在Alice手里,只要Alice手里的第n张不出,那么我第n-1张牌是否也算是天下第一莉?
- 本质上是什么莉?是比n大的只有1,比n-1大的只n,其余的牌是否在Alice手里也根本就不重要,Alice先手出就处于劣势,只有手握必胜策略才能win
- Bob:成功并不是高瞻远瞩,而是你本来就站在高处,运筹帷幄,掌握未来
真掌握未来嘛,哥?
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#include<vector>
#include<map>
#include<iomanip>
using namespace std;
typedef long long ll;
inline ll read(){
ll w=1,mmm=0;
char ch=getchar();
while(ch<'0'||ch>'9') {if(ch=='-') w=-1;ch=getchar();}
while(ch>='0'&&ch<='9') {mmm=(mmm<<1)+(mmm<<3)+(ch^48);ch=getchar();}
return w*mmm;
}
const int maxn=2e5+10;
ll mmax[maxn],a[maxn];
void solve(){
int n=read();
string s;
cin>>s;
int la=0,lb=0;
for(int i=0;i<n;i++)
if(s[i]=='A') la++;
else lb++;
if(la==1){
if(n==2&&s[0]=='A') printf("Alice\n");
else printf("Bob\n");
return;
}
if(lb==1){
printf("Alice\n");
return;
}
if(s[0]=='A'&&s[n-1]=='A'||n>2&&s[n-1]=='A'&&s[n-2]=='A') printf("Alice\n");
else printf("Bob\n");
}
int main() {
int t=read();
while(t--)
solve();
return 0;
}
D题(2104D)Array and GCD

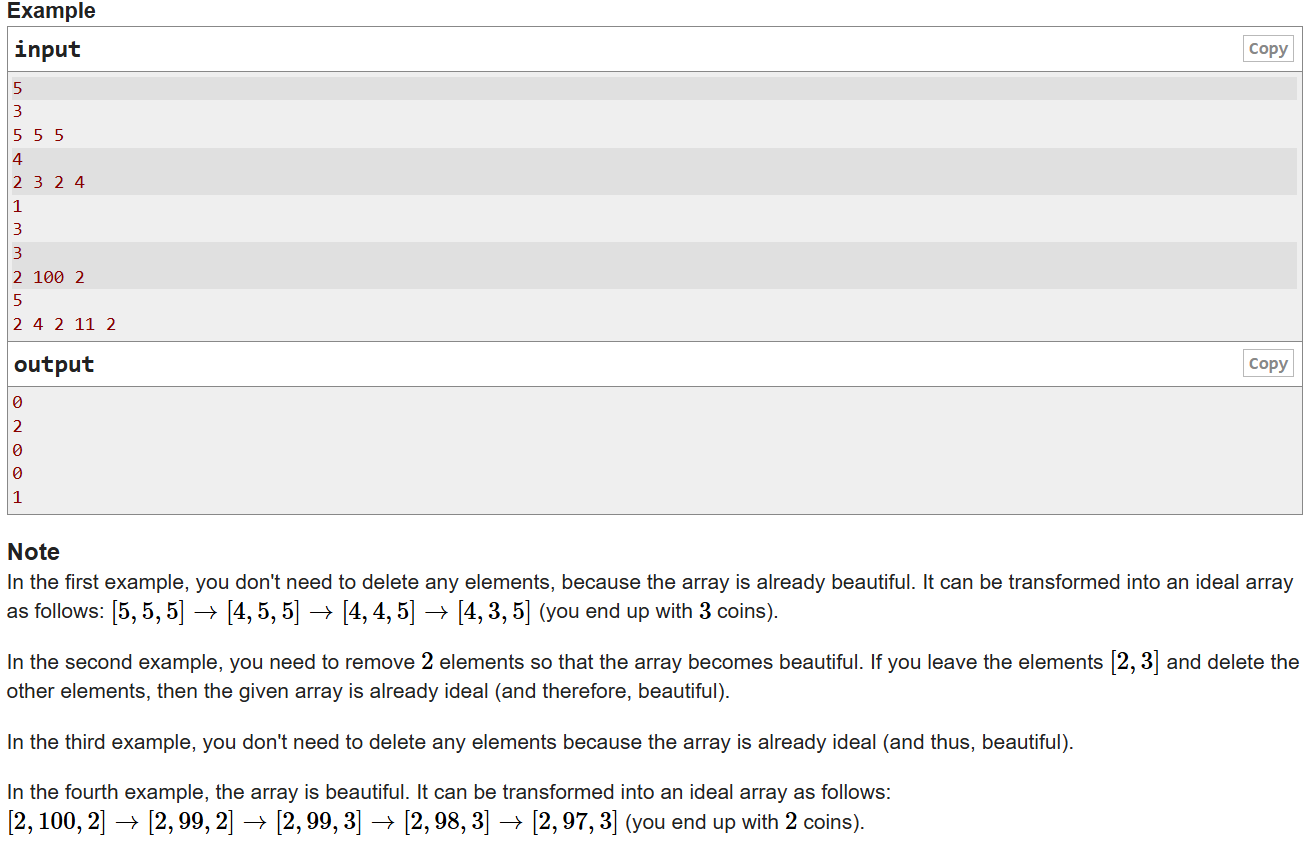
来啦,这个题很有意思
- 题意:T组数据,要通过以下操作,让数组n的数两两互质
- 花费一朵茉莉花,让某一个值加1;
- 让某一个值减1,得到一朵茉莉花;
- 每一个数都不能小于2,茉莉花最后可以有剩余
- 思路:我的天,两两互质
- 什么数组两两互质?质数组成的数组两两互质啊!
- 那就是构建一个质数数组呗,接下来考虑细节
- 先求原数组的和,如果数组的和大于等于长度为n的质数数组的和,那么就可以构造
- 显然我们希望这个质数数组的和最小,那么就更简单了,直接从2,3,5,7开整不就行了?
- 为什么是对的,保留一个合数,那么它的质因子的倍数是不能在数组里的,那么为什么不保留这个质因子?还能剩下很多茉莉花,从两个方面来说都更优,所以可以贪心
- 保留它的质因子为什么不如保留比它小的没出现过的质因子?你猜为什么叫质因子,它们不是一回事嘛
- 如果说长度为n的和构造不了,那么就减去那个原数组中最小的那个数,可以少构造一个第n大的质数
- 如此往复,直到可以构造
- 真是优美的茉莉花呀
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#include<vector>
#include<map>
#include<iomanip>
using namespace std;
typedef long long ll;
inline ll read(){
ll w=1,mmm=0;
char ch=getchar();
while(ch<'0'||ch>'9') {if(ch=='-') w=-1;ch=getchar();}
while(ch>='0'&&ch<='9') {mmm=(mmm<<1)+(mmm<<3)+(ch^48);ch=getchar();}
return w*mmm;
}
const int maxn=4e5+10;
int a[maxn];
ll sum[maxn];
int p[10000000];
const int nn=6e6;
bool isprime(int x){
if(p[x]) return 0;
for(int i=2*x;i<=nn;i+=x) p[i]=1;
return 1;
}
void init(){
int ct=0;
for(int i=2;i<=nn;i++){
if(isprime(i)){
sum[ct+1]=sum[ct]+i;
ct++;
}
if(ct==400000){
return;
}
}
}
void solve(){
int n=read();
ll tmp=0;
for(int i=1;i<=n;i++){
a[i]=read();
tmp+=a[i];
}
sort(a+1,a+n+1);
int i=0;
while(sum[n-i]>tmp){
tmp-=a[i+1];
i++;
}
printf("%d\n",i);
}
int main() {
init();
int t=read();
while(t--)
solve();
return 0;
}
现在想想这个问题,和埃氏筛欧拉筛的过程何其类似,算法,很神奇吧
E题(2104E)Unpleasant Strings

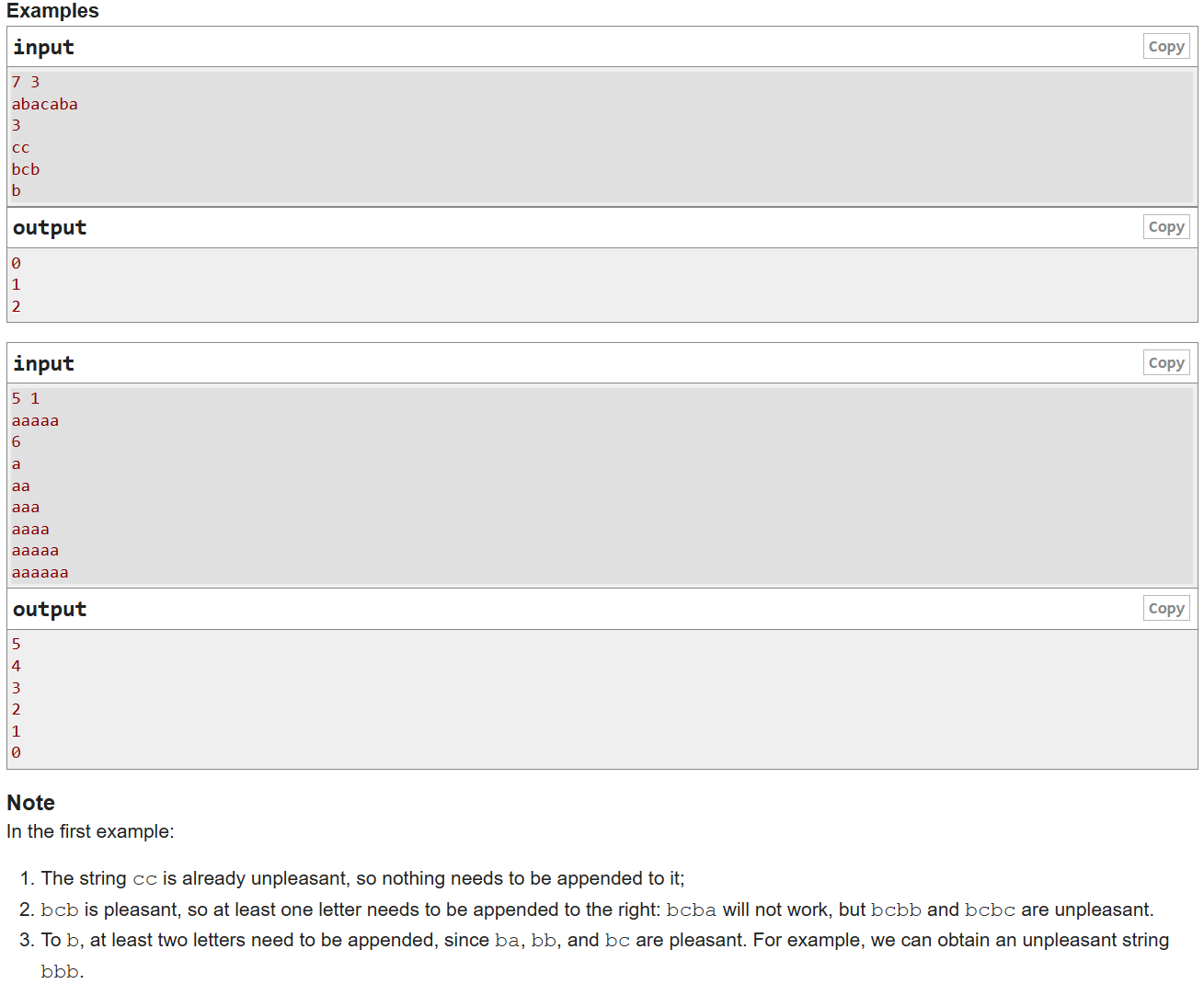
- 事先说明:E题后的都是茉莉后面自己补的,是看了题解的情况写的,只能说是把题解的思路按照自己的理解从头梳理一遍
- 题意:给一个长度为n的字符串s,串由前k个小写字母组成,q次询问,每次询问一个字符串至少需要加几个字符能够让得它不是s的子串,加的字符只能是前k个小写字母中的一个
- 思路:茉莉原来的思路就是假设当前询问的这个串作为s的子串,最后一位落到了位置i上,那么i后面的字符们的最小数量就是需要构造的字符数
- 也就是比如样例1中单个b,后面的串有acaba,有3个a,1个b,1个c
- 那么只需要添加两个b或者两个c就可以了
- 但是WA掉了,给了错误测试点才知道问题,就是在数量很小的时候这个思路可能是对的,但是构造的字符可以不一样,也就是说比如上面那个例子,茉莉构造1个b,后面只剩下了a,如果构造1个c,后面还有aba,策略不对
- 那么正确的策略是什么呢?贪心,找到当前位置i添加1个字符以后可以到达的最远位置,再重复这个行为,因为选择其他的字符到达的位置(下标)不如贪心的选择,所以这个局部最优能够保证全局最优
- 所以我们需要做两件事儿,一个找到每一个子串结束时对应的下标,这个可以转换为找到当前字符的后某一个字符的下标,用nk的桶来存
- 另一个是当前位置下,添加一个字符能够到达的最远下标,你再看看上面那条?我是不是取当前字符后的每个字符的下标的最大值就行了?
- 茉莉!解决一个问题就解决了两个问题
- 值得一提的是,其实还没有完,本来以为已经足够了,但是好像数据的规模有点大,在后面每次询问的时候一次一次往后跳会超时,emm,能理解,毕竟理论复杂度有O( s u m t i ∗ n sum{t_i}*n sumti∗n),鬼知道一次跳能跳多远哈哈
- 所以我们还需要一个快速存储答案的数组,用来快速遍历,把它从已知跳1次能跳多远变成,跳几次能跳出去
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#include<vector>
#include<map>
#include<iomanip>
using namespace std;
typedef long long ll;
inline ll read(){
ll w=1,mmm=0;
char ch=getchar();
while(ch<'0'||ch>'9') {if(ch=='-') w=-1;ch=getchar();}
while(ch>='0'&&ch<='9') {mmm=(mmm<<1)+(mmm<<3)+(ch^48);ch=getchar();}
return w*mmm;
}
const int maxn=1e6+10;
int pos[maxn][30];
int ans[maxn];
int re[maxn];
char s[maxn];
void solve(){
int n=read(),k=read();
for(int i=1;i<=n;i++)cin>>s[i];
for(int j=0;j<k;j++)
pos[n+1][j]=n+1;
for(int i=n;i>=0;i--){
for(int j=0;j<k;j++){
if(!pos[i][j]) pos[i][j]=pos[i+1][j];
ans[i]=max(ans[i],pos[i][j]);
}
re[i]=re[ans[i]]+1;
int c=s[i]-'a';
if(i) pos[i-1][c]=i;
}
// for(int i=1;i<=n;i++)
// cout<<ans[i]<<" ";
// cout<<endl;
// for(int i=1;i<=n;i++)
// cout<<re[i]<<" ";
// cout<<endl;
int q=read();
while(q--){
string s;
cin>>s;
int l=s.length();
int end=0;
for(int i=0;i<l;i++){
int c=s[i]-'a';
end=pos[end][c];
// printf("tmpchar :%c , end: %d\n",char(c+'a'),end);
if(end>n) break;
}
cout<<re[end]<<endl;
}
}
int main() {
// int t=read();
// while(t--)
solve();
return 0;
}
/*
25 3
acaacaabbcbacbcbbaacaaaba
10
bcc
baccb
acaababbbcabaabcbabbacbccb
baccbabcbbac
bbcabbbbcbaaabbcbcaaba
babaccbaabccac
cabb
bcb
bcaccccbba
c
*/
re数组就是用来存跳几次能出去的,很好处理,因为我们从后往前枚举,后面的位置需要跳几次能跳出去的答案我们是知道的,只需要跳一次,看跳到那里还需要几次,就是当前位置的答案啦,递归嘛
你猜这个样例从哪儿来的莉?
F题(2104F)Numbers and Strings
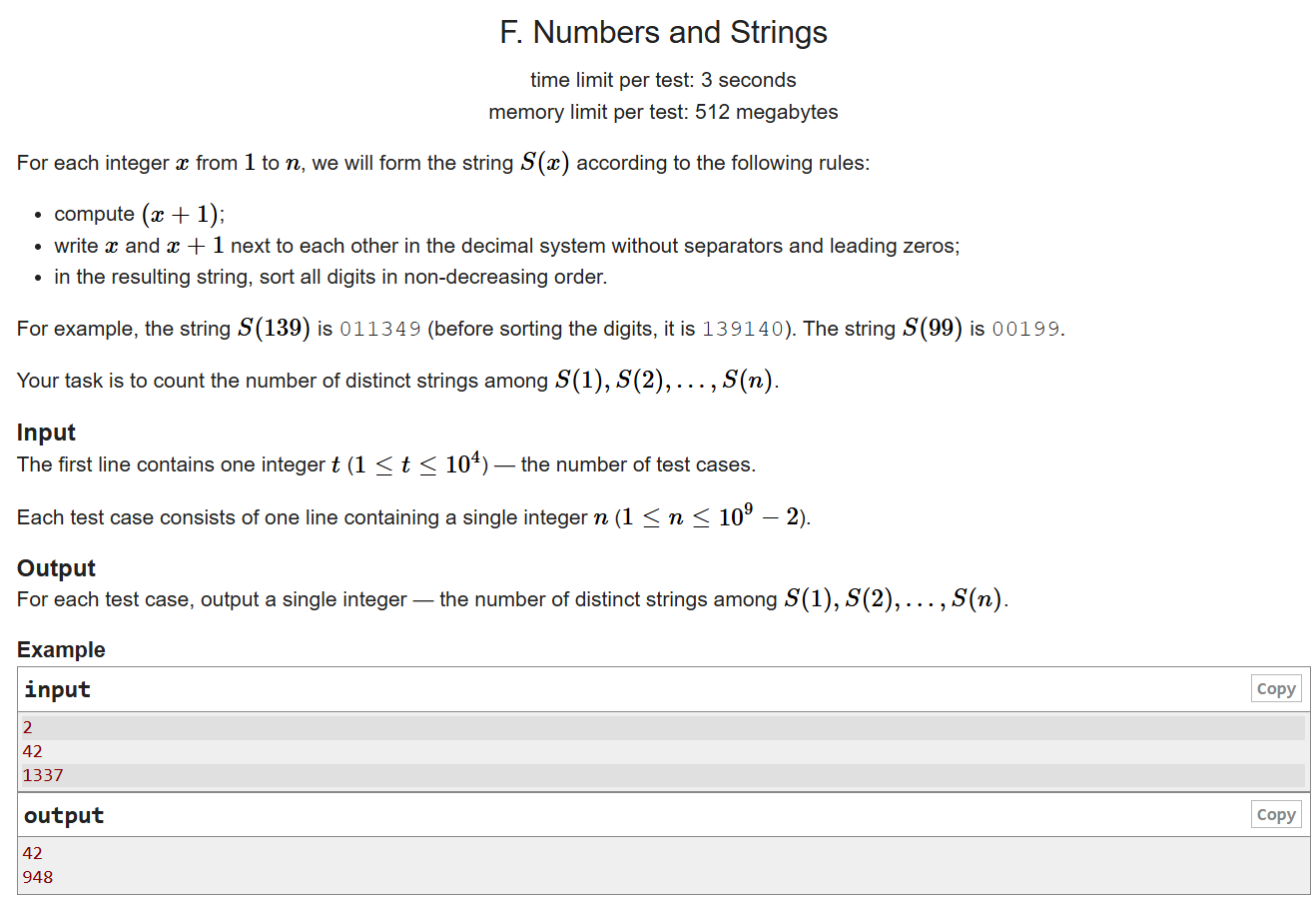
这个题太有意思了,茉莉自己看题解茉有看懂,是在请教了学长以后才理解意思
- 题意:每一个数x会生成一个字符串S(x),比如139,会先把x+1,也就是140和它写在一起,139140,然后排序变成011349,问1到n的时候会有多少个不同的S(x)
- 思路:其实一开始啥思路都没有
- 茉莉根本就没想出来什么数的S串会重复,写了一个程序跑了一遍,才恍然大明白,21y和12y的生成串S不就一样咩( y ! = 9 y!=9 y!=9),好笨一只茉莉
- 好,那么考虑抽象一下,y前面的几位是可以排列组合的,也就是我们可以把一个数分为两部分,最后一位和其余位,其余位的顺序并不影响,因为我们只需要求解生成串S的数量,所以我们只需要记得最小的生成S的那个数x就行了
- 现在我们考虑怎么快速回答求解的问题,假如我们能够得到所有的S串和它对应的最小的x的一个vector,也就是{S(x),x},如果当前n大于等于x,是不是就可以加上这种情况下的S(x)?那么假如我们的vector是有序的,按照x排序的,是不是二分就可以解决一次查询了?
- 好,所以我们需要考虑一下,怎么得到所有的S串,显然是枚举x,我们只需要最小的那个x,也就是说我们可以使得左边部分的数字非递减枚举,这个时间复杂度是可以接受的,八位数,9个空格,0-9共有10个隔板(什么意思莉,就是说左边部分的数,我们要从0开始枚举,枚举到9,假如说数字13,我们就可以认为是0跳到1的隔板在首个空隙,1跳到2和2跳到3的隔板在第一位数字后的那个空隙,3跳到4、4跳到5、…、8跳到9的隔板都在3后面,所以生成了13),十个隔板放到9个空格中去,按照隔板法的计算方法


- 这个复杂度是可以接受的,那么接下来考虑一个问题,我们从0开始枚举,但是题目中明确提到了x不能含有前导0,这个问题咋办莉?很简单,首位的0和第一位非0交换不就好了?反正我们要的只是S(x)对应的最小的x,这也是题解中提到的解决思路
- 想不到吧,还有一个问题,那就是我们知道这样枚举,当左边部分枚举完毕,加上最后一位的枚举,肯定可以把所有会重复出现的S(x)找到,那么不会重复出现的S(x)我们怎么办莉?
- 1.在枚举左边部分的时候,每枚举一位就把当前构造的x对应的S(x)存下,这样解决了大部分问题,但是问题是解决了所有不会重复出现的S(x)吗?显然茉有,举个栗子1859,对应的串18591860(01156889)这个串,我们不会通过前面的方法枚举到,因为它不符合我们猜想的左边部分非递增,然后最后一位小于9的情况
- 2.所以回过头来看看,我们之前的那种构造有什么问题,是不是最后一位不能是9?那最后一位能是9嘛?当然可以,所以实际上我们构造数据的时候,应该把一个数x分成三部分,左边非递增的,中间一位0-8的且小于左边最后一位的,右边连续的9,之前的情况实际上就是右边连续9的个数可以为0
- emmm,其实按照正常来说严谨的逻辑,茉莉需要证明这样去构造数的过程中,会把所有的S(x)涵盖到,但是这里茉莉只提供一个很模糊的说法,任何一个数,一定可以通过交换它的某些位,达成我们构造的形式
- 若最后一位不是9,则把最后一位定为mid位,前面部分的数可以构造为全排列(0不在首位的情况下)
- 若最后一位是9,(会出现连续的9),找到前面那一位不是9的数字定为mid,左边部分可能长度为0,包括没有mid位的情况99999,我们都可以把它当做枚举左边部分的情况,就是把这个串当成一个数的左边部分的过程中把它添加到答案中去了
- 所以这样想我们是把所有情况都涵盖到的了,如果你觉得不够严谨,不妨从三个部分,每个部分是否存在来看,一共8种情况,也能想明白
- 然而,到这里,还差一步,hhhh没想到吧,还有特殊情况,比如902和299,299是我们在枚举左边部分的时候产生的,串为002399(299300),902是我们左边部分为09交换以后,mid位为2的时候产生的,串为002399(902903),这种情况下产生的重复出现S(x)是我们没有考虑到的,所以最后我们还需要去重
- 怎么去重莉?很简单,把所有产生的x和S(x)先不按照x排序,先按照S(x)排序,如果排序后,后一个元素的S(x)和前一个重复了,就不在新答案里加入了呗,这不就去重了?再在新答案里按照x排序不就好了茉?
- 诶?怎么想到滴?这就很有意思了,归功于茉莉一开始自己写的到1337的所有串茉莉都写了一遍,茉莉在看到90y的时候,发现它们构成的S(x)在前面出现过,很巧吧?茉莉估计题解也是这么发现的?算了,这与茉莉无关莉。
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#include<vector>
#include<map>
#include<queue>
#include<string>
using namespace std;
typedef long long ll;
inline ll read(){
ll w=1,mmm=0;
char ch=getchar();
while(ch<'0'||ch>'9') {if(ch=='-') w=-1;ch=getchar();}
while(ch>='0'&&ch<='9') {mmm=(mmm<<1)+(mmm<<3)+(ch^48);ch=getchar();}
return w*mmm;
}
vector<pair<string,ll>>ans1;
vector<pair<ll,string>>ans2;
inline string S(ll x){
string s=to_string(x)+to_string(x+1);
sort(s.begin(),s.end());
return s;
}
inline ll get_num(string x){
// cout<<x<<endl;
int leading_zero=0;
while(leading_zero<x.length()&&x[leading_zero]=='0') leading_zero++;
swap(x[0],x[leading_zero]);
return stoll(x);
}
inline void brute(string x,bool f){
char p='0';
for(int i=0;i<x.length();i++) p=max(p,x[i]);
if(p!='0'){
ll num=get_num(x);
string s=S(num);
ans1.push_back({s,num});
}
int len=x.length();
if(len<9){
if(f){
brute(x+'9',f);
}
else{
for(char c='0';c<='9';c++)
brute(x+c,c<x.back());
}
}
}
void solve(){
string mo="";
for(char c='0';c<='9';c++)
brute(mo+c,0);
int l=ans1.size();
sort(ans1.begin(),ans1.end());
for(int i=0;i<l;i++)
if(i==0||ans1[i].first!=ans1[i-1].first)
ans2.push_back({ans1[i].second,ans1[i].first});
sort(ans2.begin(),ans2.end());
int q=read();
while(q--){
int n=read();
ll l=0,r=ans2.size(),ans;
while(l<=r){
ll mid=(l+r)>>1;
if(ans2[mid].first<=n) l=mid+1;
else ans=mid,r=mid-1;
}
cout<<ans<<endl;
}
}
int main() {
// int t=read();
// while(t--)
solve();
return 0;
}
/*
2
42
1337
*/
和题解比较像?那茉有办法莉,因为确实是看了题解最后再重新写的,因为茉莉之前自己的思路,只到了枚举部分,看了题解以后就变成题解的形状莉,悲,所以茉莉自己会写的题一定会不看题解给大家伙讲,但是茉莉应该还是有拆开把题解讲解得更详细,逻辑也更好理解的,至少茉莉给你说的是中文不是?

G题(2104G)Modulo 3

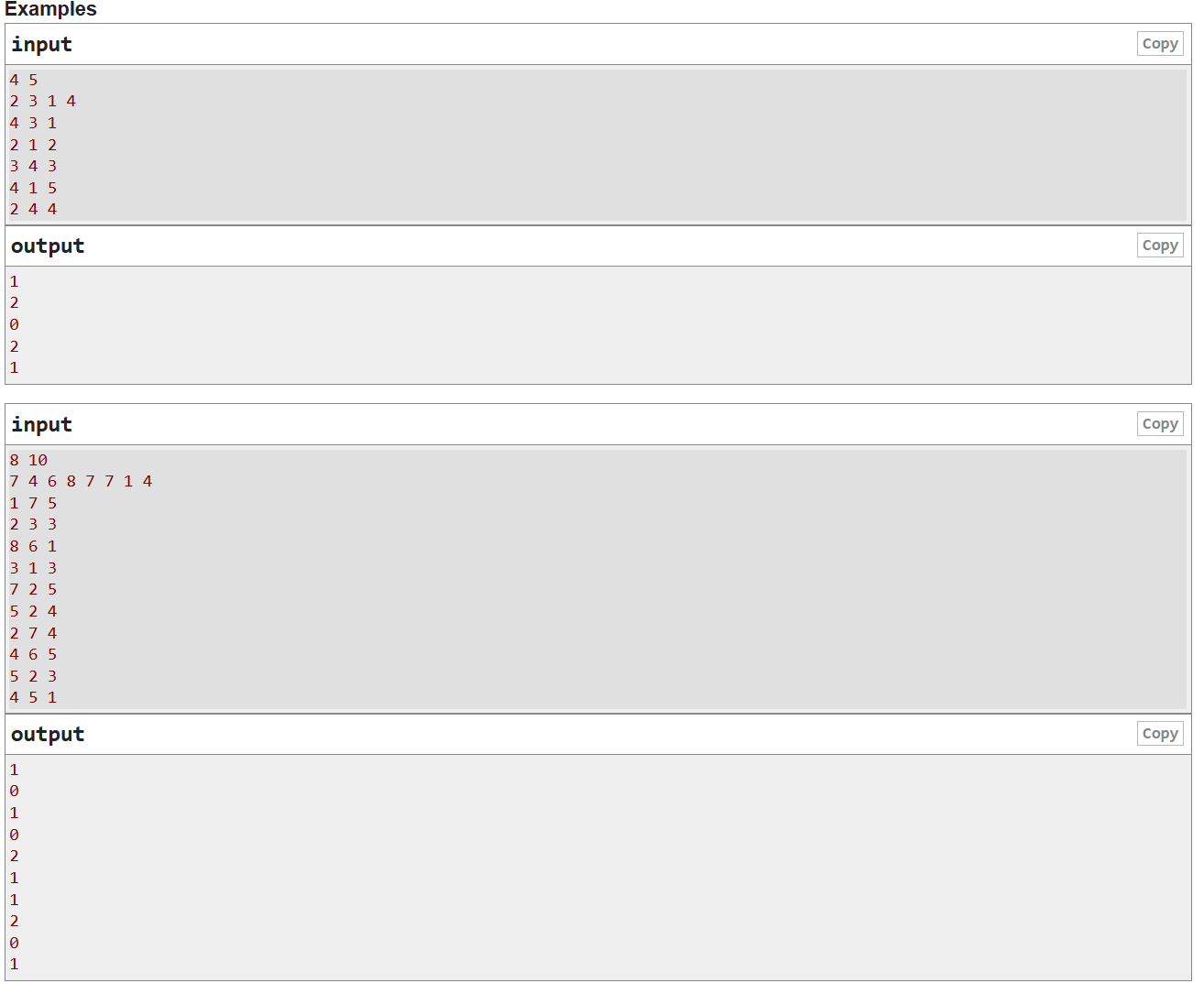
这个题,爆炸无敌难,如果不是学长恰好在旁边,茉莉连题解都看不懂
- 题意:n个点,n条边,q次询问,每次询问会更改一条边,提供k种颜色,问每次询问的时候整个图有多少种染色方案,每次染色会把当前点可达的所有点染成相同的颜色,输出方案数模3的结果
- 思路:先说说茉莉自己茉看题解的时候能够达到的地方
- 首先莉,n个点,n条边,这个性质很重要,一定至少会有一个环,因为生成一棵树需要n-1条边,多一条边就会产生环,自环也是环
- 其次,我们考虑题目说的,染色一个点,会把当前点可达的所有点都染成相同的颜色,那么我们想,什么情况下,两个点的颜色一定相同?(或者说哪些点的颜色一定相同?)那就是强联通的时候,也就是环内所有元素的颜色一定一样,我们假设强联通分量或者说环的个数为m,那么答案是不是就是 k m k^m km?
为什么不是弱联通?
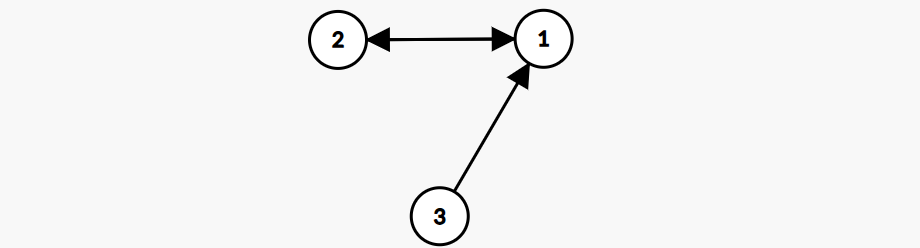
假设你给3染色,确实1和2都会染成相同的颜色,但是再给1染上不同的颜色,1和2的颜色不就和你3不一样了吗?所以看似3连接了1,但是1、2和3的颜色还是独立的
3:原来我终归还是个橘外人嘛?- 再结合题目要求模3的结果
- 若k%3==0,也就是 k = 3 ∗ k 1 k=3*k_1 k=3∗k1,那么 ( 3 ∗ k 1 ) m (3*k_1)^m (3∗k1)m%3只能等于0
- 若k%3==1,也就是 k = 3 ∗ k 1 + 1 k=3*k_1+1 k=3∗k1+1,那么 ( 3 ∗ k 1 + 1 ) m (3*k_1+1)^m (3∗k1+1)m三 1 m 1^m 1m(同余茉莉用一二三的三代替莉,呢嘻嘻)
- 若k%3==2,也就是 k = 3 ∗ k 1 + 2 k=3*k_1+2 k=3∗k1+2,那么 ( 3 ∗ k 1 + 2 ) m (3*k_1+2)^m (3∗k1+2)m三 2 m 2^m 2m三 ( − 1 ) m (-1)^m (−1)m
- 我们只需要考虑k%3==2的情况下,强联通分量的数量
( − 1 ) m (-1)^m (−1)m,所以具体而言,是m的奇偶性
那么我们又知道,m的奇偶性,是与偶环的数量相关的
因为最开始m=n,每有一个强联通分量,m-=size(强联通分量)-1
size为奇数时,-1以后根本不影响奇偶性
所以只有为偶数时,会直接改变c的奇偶性
又因为我们在有向图中且我们只有n条边,所以强联通分量等价于成环
所以其实就变化成了求偶环的数量,更具体而言,只在乎偶环数量的奇偶性
千万不要以为只能有一个环
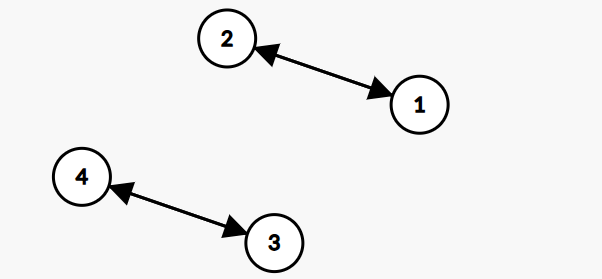
- 问题就变成了如何log的时间复杂度下解决求解每一个问询点的偶环数量的奇偶性问题
- 剩下的就是看题解并且请教了学长以后才理解了的莉,
- 转换一下问题的思路,我们考虑一下每一条边存在的时间段(也就是查询点的区间长度),维护一个线段树
向下dfs的情况下,我们可以获得每一段时间内存在的边
每有一条边我们就合并,看看是否产生环,以及产生的环是否是偶环
直到遍历到叶子结点i的时候,i这个时间点存在的所有边都被合并了,我们也得知了偶环的数量
向上回退的时候,需要撤销当前区间(叶子节点)的合并操作
由于每一个节点在一段时间(或者说一个向下遍历的过程中只会出现一次),所以我们只需要单独记录一下,就可以撤销我们对于当前区间(叶子节点)的合并操作
用线段树就可以解决每一个时间节点的偶环奇偶性的问题 - 最终题解写的线段树跟我们正常写的思路不太一样,它是严格落实左闭右开的区间来处理的,所以写法会有一点点不同,但是茉莉还是会正常写线段树的啦
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<string>
#include<cmath>
#include<vector>
#include<map>
#include<iomanip>
using namespace std;
typedef long long ll;
typedef pair<int,int> pii;
inline ll read(){
ll w=1,mmm=0;
char ch=getchar();
while(ch<'0'||ch>'9') {if(ch=='-') w=-1;ch=getchar();}
while(ch>='0'&&ch<='9') {mmm=(mmm<<1)+(mmm<<3)+(ch^48);ch=getchar();}
return w*mmm;
}
const int maxn=2e5+10;
int g[maxn];
vector<pii> tree[maxn<<2];
int last_[maxn];// last_[i] represent the last time of g[i] or an edge from i
int k[maxn];
int fa[maxn];
int rk[maxn];
int ans[maxn];
int same[maxn];// note that the length is odd or even
int* pos[maxn<<2];// for traceback, pos[i] note the ith changed variable's address
int val[maxn<<2];// for traceback, val[i] note the ith changed variable's origin value
int cnt_af;// for traceback, note cnt_be ~ cnt_af note the changed varible's
void treebuild(int tmp,int l,int r,int le,int ri,pii p){
// printf("tmp: %d, l: %d, r: %d, le: %d, ri: %d ",tmp,l,r,le,ri);
// cout<<"pii: "<<p.first<<" "<<p.second<<endl;
if(le>ri) return;
if(l==le&&r==ri){
tree[tmp].push_back(p);
return;
}
int mid=(l+r)>>1;
treebuild(tmp*2 ,l,mid,le,min(mid,ri),p);
treebuild(tmp*2+1,mid+1,r,max(le,mid+1),ri,p);
}
void traceback(int cnt_be){
while(cnt_af>cnt_be){
cnt_af--;
(*pos[cnt_af]) = val[cnt_af];
}
}
void insert(int &x,int y){
pos[cnt_af] = &x;
val[cnt_af] = x;
cnt_af++;
x=y;
}
pii findfa(int tmp){
// printf("finding father: tmp:%d , fa[tmp]: %d\n",tmp,fa[tmp]);
if(fa[tmp]==tmp) return {tmp,0};
pii re=findfa(fa[tmp]);
return {re.first , re.second ^ same[tmp]};
}
pii merge(int x,int y){
// printf("Mergeing: %d to %d\n",x,y);
pii rex=findfa(x),rey=findfa(y);
int fax=rex.first,fay=rey.first;
int d1=rex.second,d2=rey.second;
if(fay==fax){
return {1, d1 ^ d2};
}
if(rk[fax]>rk[fay]) swap(fay,fax);
// fa[fax]=fay;
insert(fa[fax],fay);
// same[fax]=d1 ^ d2 ^ 1;
insert(same[fax], d1 ^ d2 ^ 1);
// rk[fay]=rk[fay]+rk[fax];
insert(rk[fay], rk[fay] + rk[fax]);
return {0,0};
}
void dfs(int tmp,int l,int r,int t_mo){
// printf("tmp: %d, l: %d, r: %d, t_mo: %d\n",tmp,l,r,t_mo);
int cnt_be=cnt_af;
for(int i=0;i<tree[tmp].size();i++){
int x=tree[tmp][i].first;
int y=tree[tmp][i].second;
pii re=merge(x,y);
bool f=re.first;
int c_o=re.second;
// if this merge generate a new circle
// 如果是偶环,c_o为1,t_mo取反,若为奇环,c_o为0,t_mo不变
if(f) t_mo^=c_o;
// cout<<"After Merging: "<<re.first<<" "<<c_o<<" t_mo: "<<t_mo<<endl;
}
if(l!=r){
int mid=(l+r)>>1;
dfs(tmp*2 ,l,mid,t_mo);
dfs(tmp*2+1,mid+1,r,t_mo);
}
else{
ans[l] = k[l] %3;
if(ans[l]==2) ans[l]=t_mo +1;
}
// cout<<"back"<<endl;
traceback(cnt_be);
}
void solve(){
int n=read(),q=read();
for(int i=1;i<=n;i++){
g[i]=read();
last_[i]=1;
}
for(int i=1;i<=q;i++){
int x=read(),y=read();
k[i]=read();
treebuild(1,1,q,last_[x],i-1,{x,g[x]});
g[x]=y;
last_[x]=i;
}
for(int i=1;i<=n;i++){
treebuild(1,1,q,last_[i],q,{i,g[i]});
fa[i]=i;
rk[i]=1;
}
dfs(1,1,q,n&1);
for(int i=1;i<=q;i++){
cout<<ans[i]<<endl;
}
}
int main() {
// int t=read();
// while(t--)
solve();
return 0;
}
/*
4 5
2 3 1 4
4 3 1
2 1 2
3 4 3
4 1 5
2 4 4
*/
其中那个same数组,黑白染色用的,说的通俗一点就是记录到根节点的长度,长度为偶数就为0,长度为奇数就为1
就是酱紫啦,五一期间还在写博客的茉莉真是勤奋呀
送给茉莉一朵茉莉花~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









