







k8s:是一个用于自动化部署、扩展和管理容器化应用程序的开源系统
官网:https://kubernetes.io/k8s和compose的区别(两者都是容器编排工具)
1,compose是docker公司推出的,k8s是CNCF推出的
2,compose只能在一台宿主机上编排容器,k8s可以在很多台机器上编排容器

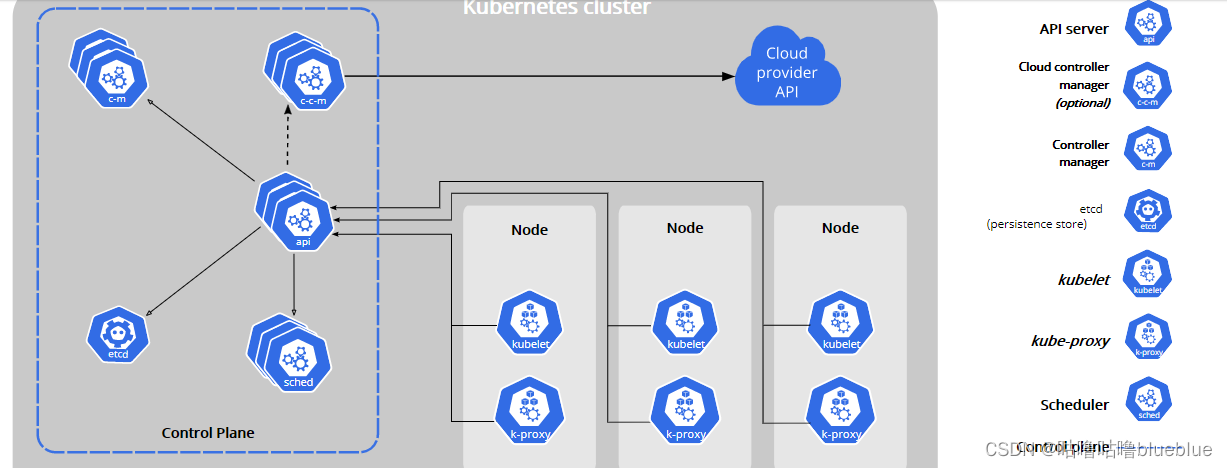
一个kubernetes集群包含两种类型的资源
Master:调度整个集群,运行执行管理功能的pod的地方
Node:负责运行应用,真正的container app运行在node节点服务器上,运行业务pod的地方--》真正干活的
----------------------------------
kubelet:
一个在集群中每个节点上运行的代理,它保证容器(containers)都运行在pod中,负责调本机的docker或containerd容器运行时软件去启动pod(直接跟容器引擎交互实现容器的生命周期周期管理)
-----------------------------------
kube-proxy
是集群中每个节点上运行的网络代理,实现kubernetes服务概念的一部分(写入规则到iptables,ipvs实现服务映射访问的)
coredns:可以为集群中的svc创建一个域名ip的对于关系解析
dashboard:给k8s集群提供一个B/S结构访问体系
INGRESS CONTROLLER:实现七层代理
fedetation:提供一个可以 跨集群中心多k8s同
k8s经典面试题:
一、k8s由哪些组件组成
控制平面组件(control plane components):实现k8s控制功能的软件,控制平面组件有很多个软件,控制组件相当于管理层(党中央),对整个集群进行调度、管理、控制、数据存储等,集群的全盘信息,都在控制平面组件里
- kube-apiserver:API服务器是kubernetes控制面的组件,该组件公开了kubernetes API,API服务器是kubernetes控制面的前端,其他node服务器或者master访问的入口;可以通过API获取整个集群的信息(Node是由一个Master暴露的kubernetes API与Master通信)
- etcd:兼具 一致性和高可用性的键值数据库,可以作为保存kubernets所有集群数据的后台数据库
- kube-scheduler:决定调度哪些pod到具有的哪些节点上运行(在k8s里最小的单元不是容器而是pod)(将pod和容器理解为豌豆荚和里面的豆子,pod里面可以包含很多容器,因为们在一个命名空间所以都共享一个ip地址 )
cloud-controller-manager:一个 Kubernetes 控制平面组件, 嵌入了特定于云平台的控制逻辑。 云控制器管理器(Cloud Controller Manager)允许你将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来;可以和aws,阿里云,华为云,google云等通信。管理这些云上的资源
5.kube-controller-manager:是控制平面的组件 ,维持副本期望数目; 负责运行控制器进程。
从逻辑上讲, 每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译 到同一个可执行文件,并在同一个进程中运行
scheduler是负责安排到那个节点上,而cm是负责在整个节点上怎么去做
1.节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应 2.任务控制器(Job controller): 监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成 3.端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod) 4.服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌二、pod启动的流程
三、k8s里有哪些控制器
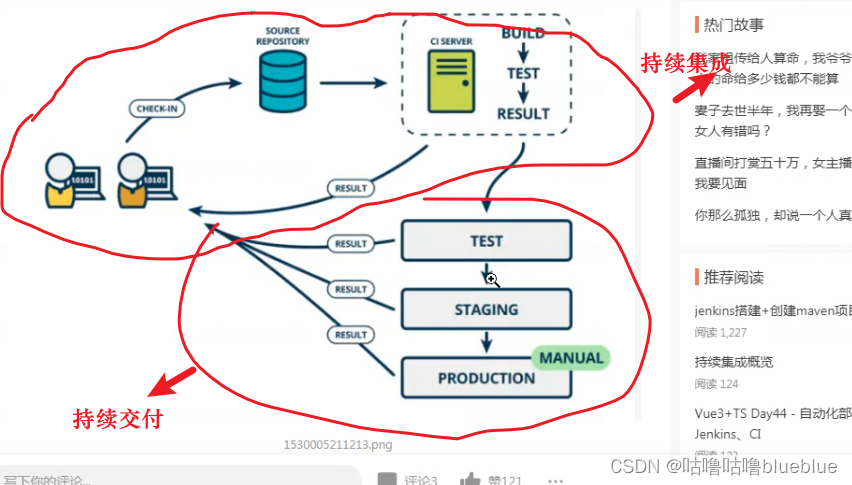
CI/CD--持续交付和持续集成
参考文档: https://www.jianshu.com/p/2b7813f7a5e8持续集成(Continous Intergration,CI):是持续地编译、测试、检查和部署源代码的过程
持续集成及自动化部署工具:Jenkins
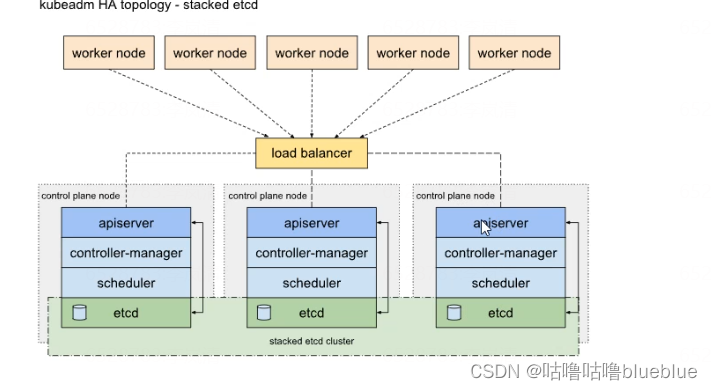
部署k8s的集群环境
安装方式:
1,二进制安装
2,kubeadm工具自动安装
3,minikube
部署参考文档: https://www.cnblogs.com/zhangcz/p/15058492.html https://www.cnblogs.com/double-dong/p/11483670.html实验环境:一个master2-3个node
集群的架构
单master多node
多master多node--高可用(load balance给apiserver做负载均衡)
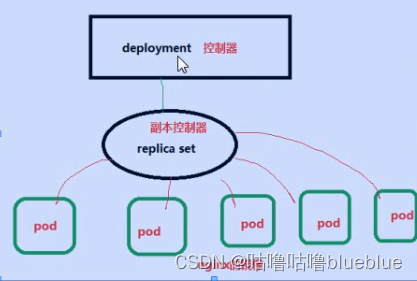
Deployment --部署控制器(帮助去node节点上起pod)
--作用就是监控pod副本的数量,如果某个node节点挂了,这个节点上的pod也会挂了,这个时候,副本控制器就会在节点上启动新的pod,数量总数达到副本控制器当时设置的数量

创建一个命名空间(一个命名空间就相当于一个帮派,用来做隔离)
kubectl create namespace sc查看有哪些pod
kebectl get pod查看pod的详细信息
kubectl get pod -o wide查看有哪些节点
kebectl get node显示资源的详细信息
kubectl describle在pod的容器上执行命令
kubectl exec
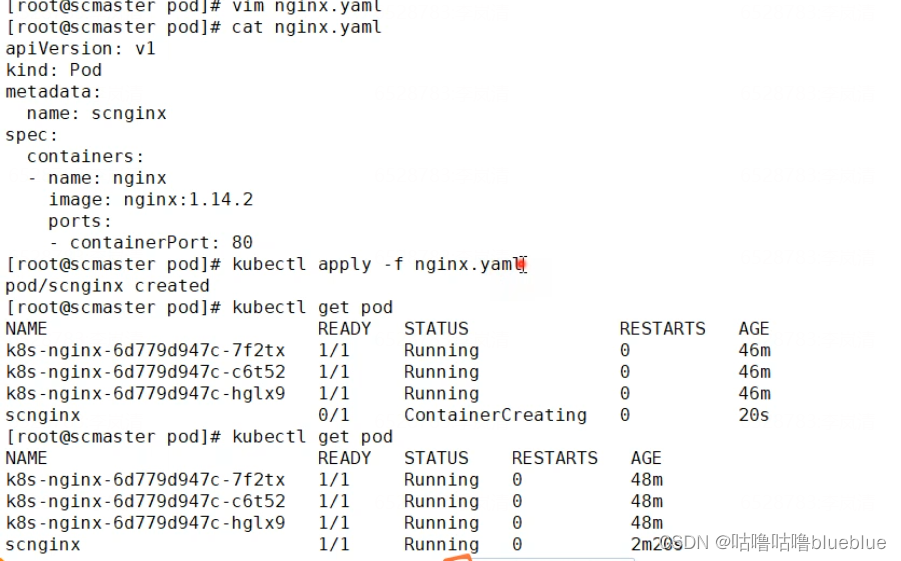
deployment 控制器:专门负责在k8s里安装部署pod
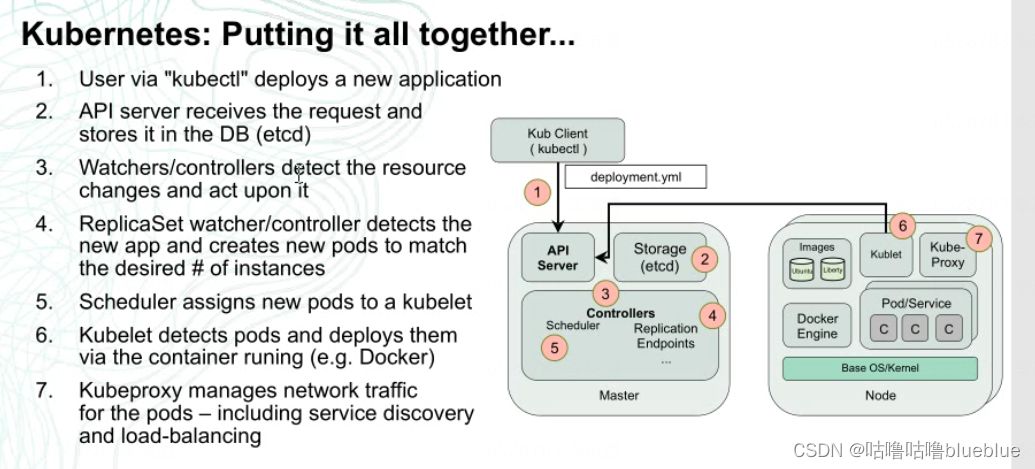
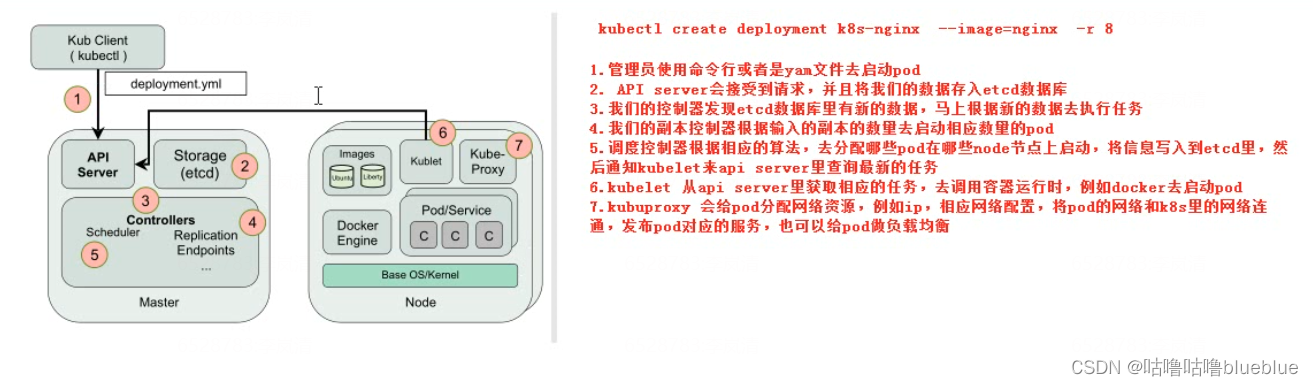
kubectl create deployment k8s-nginx --image=nginx -r 8 kubectl create deployment--创建部署控制器 k8s-nginx--控制器的名字 --image=nginx--指定控制器启动pod使用的镜像 -r 8--启动8个nginx的pod查看pod分布在哪些节点上 kubectl get pod -o wide创建pod
--启动pod
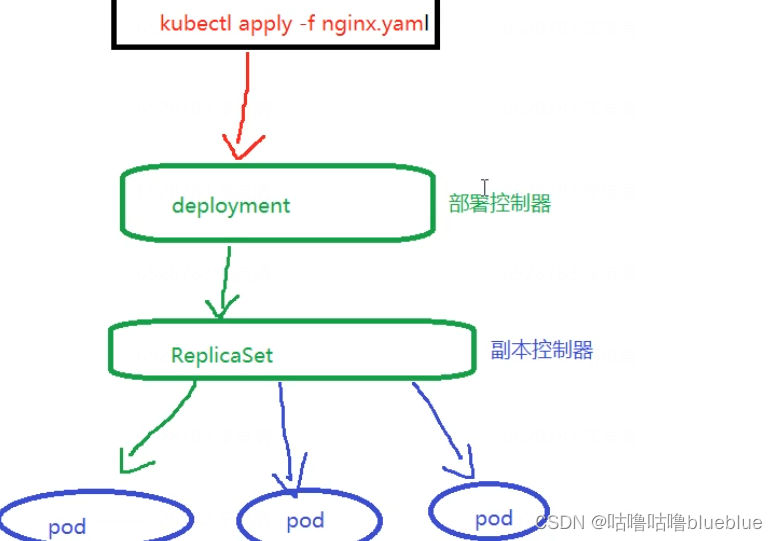
首先我们一般通过命令或者yaml文件去起pod,以nginx为例,yaml'文件里是镜像文件,版本端口等信息; 之后他访问k8s将参数传给k8s的apiserver,同时写到etcd数据库,之后部署控制器就会发现etcd里有数据变化,就会读取信息,调用repicate控制器去起多少个副本的配置,生成的配置也会写道etcd数据库里去,这时候scheduler就会从数据库读取,将pod调度到不同的节点上去 节点上的kubelet会访问apiserver和etcd数据库,就会领取属于自己节点上的任务,之后起pod,之后再调用kube-proxy连网,允许别人访问问题:kubelet是定期主动访问apiserver知道哪些pod需要启动,还是scheduler主动去停止kubelet去访问apiserver? etcd数据库发生变化,那些控制器是怎么知道的,是其他程序通知的还是去定期检查的?

探针
探针类型:
检测机制


-------------------------------------------------------------------------------------
yml中数组的格式:
一个yaml文件中使用三个短横杠(---)隔开表示两段不同的配置

资源管理方式:
kubectl --help可以查看详细的操作命令kubectl api-resources--查看资源类型, kubectl api-resoruces -o wide可以查看你的k8s提供的api和版本信息 kubectl api-versions--打印当前k8s集群支持的所有api********命令式对象配置
****************声明式对象配置
使用apply命令和配置文件去操作kubernetes的资源
问题:kubectl可以在节点上运行嘛?
答: kubectl的运行式需要配置的,配置文件时$HOME/.kube,如果想要在node节点上也使用这个命令,只需要将master上$HOME/.kube复制到node节点上
scp -r $HOME/.kube node1:HOME/ node1:HOME/--这里是指拷贝到node1节点上HOME/目录




k8s中五种资源
Namespace:
作用:实现多套环境的资源隔离或者多租户的资源隔离;通过将集群内部的资源分配到不同的namespace中,可以形成逻辑上的‘组’,方便不同的组的资源进行隔离使用和管理(等于把不同的资源分到不同的组,不同的组的成员只能用所在组的资源)
k8s集群启动后,默认会创建几个命名空间
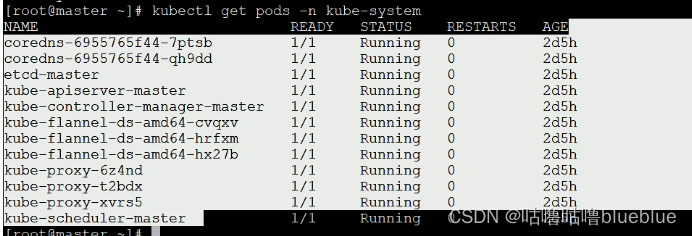
组件都在kube-system命名空间里
pod:
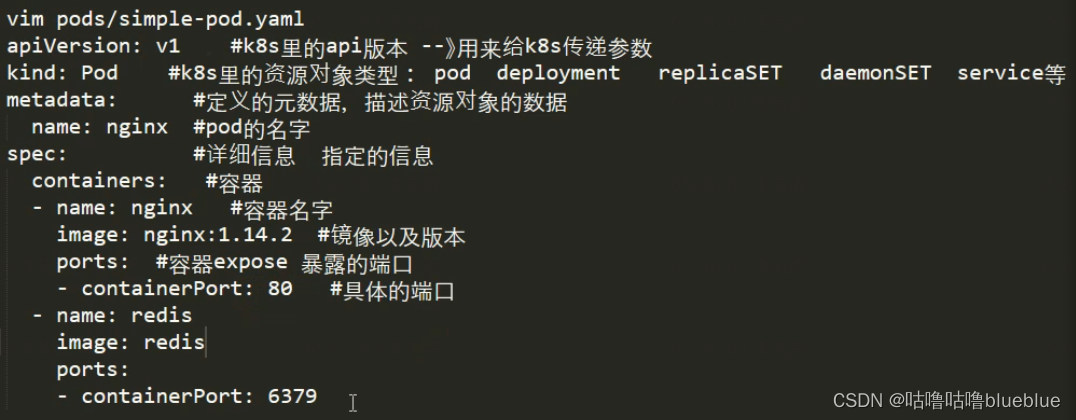
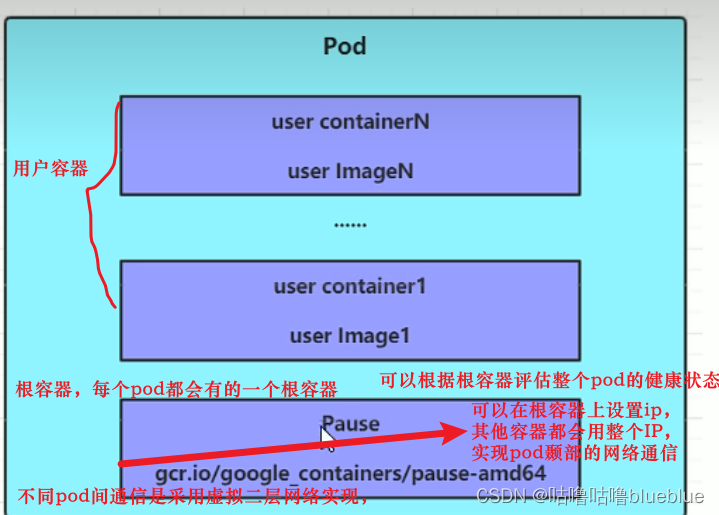
pod是k8s中进行管理的最小单位,程序要运行必须部署在容器里,而容器必须在pod中,pod可以认为是容器的封装,一个pod中可以有一个或者多个容器
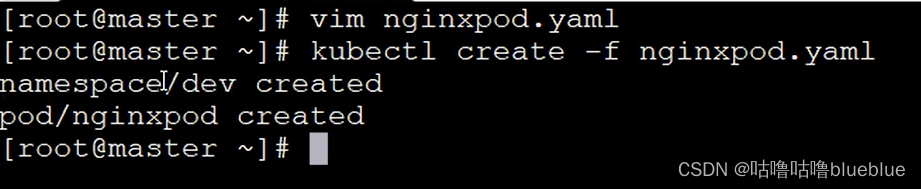
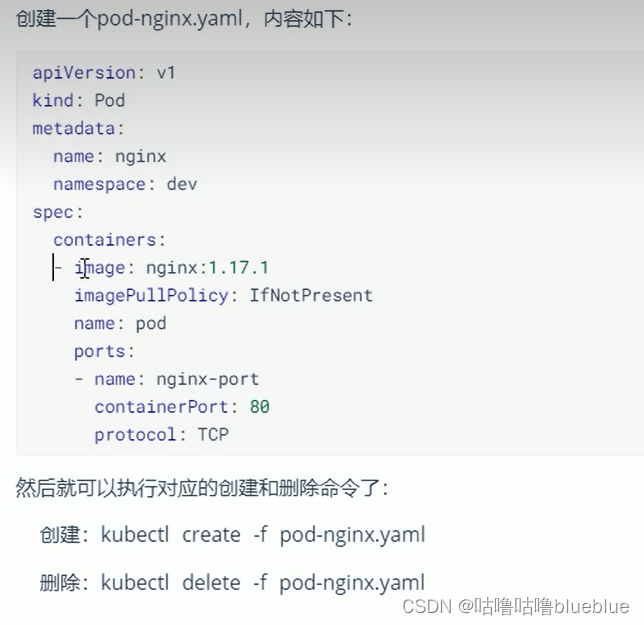
1,使用命令行起pod--不能单独起一个pod,只能利用控制器去起
2,使用yml文件起pod--可以起单独的pod
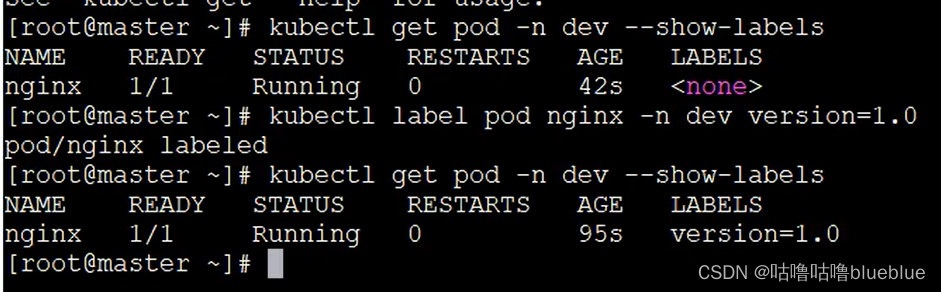
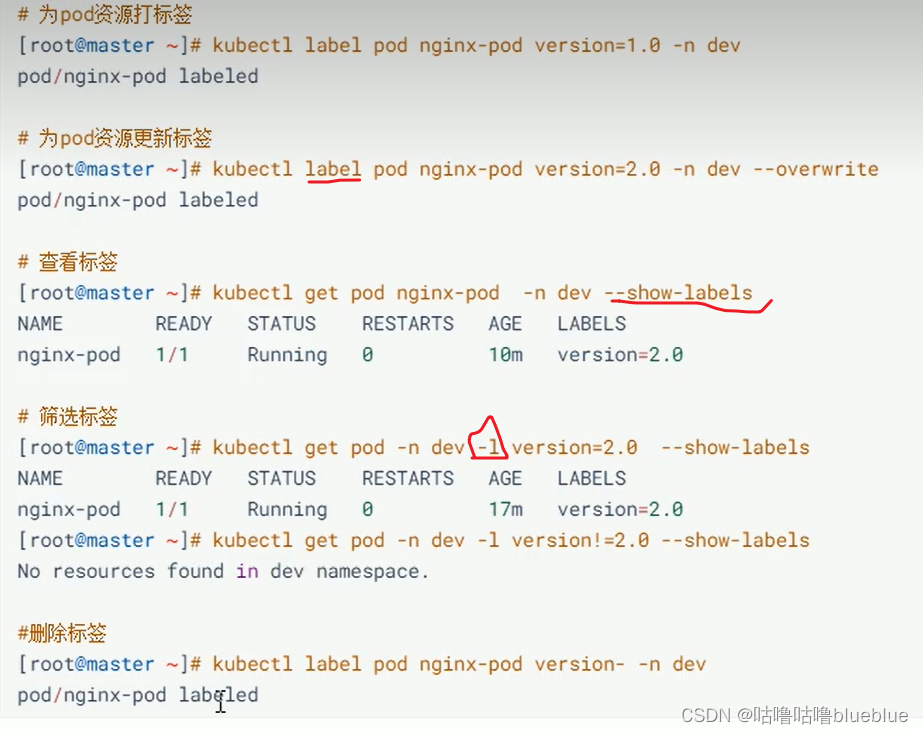
label--在资源上添加标识,对他们进行区分和选择
配置文件里打标签
deployment
在k8s中,pod是最小的控制单元,都是kubernates很少直接操控pod,一般通过pod控制器,pod控制器用于对pod的管理,确保pod资源符合预期的状态,当pod资源出现故障时,尝试创新启动或重建一个pod
kubectl create deployment k8s-nginx --image=nginx -r 8 kubectl create deployment--创建部署控制器 k8s-nginx--控制器的名字 --image=nginx--指定控制器启动pod使用的镜像 -r 8--启动8个nginx的pod
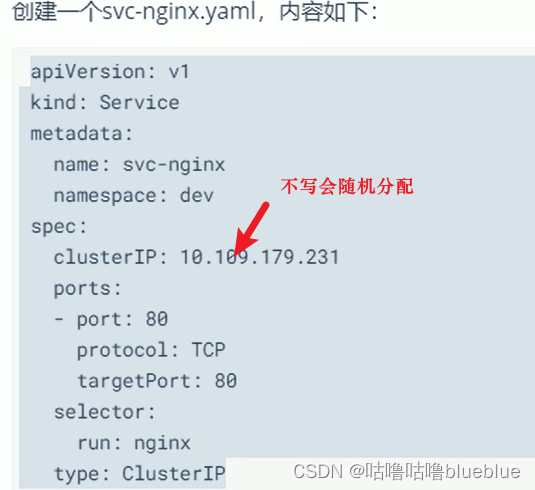
service服务(,service可以使服务被发现,service通过标签关联一组pod,为一组pod提供负载均衡能力)
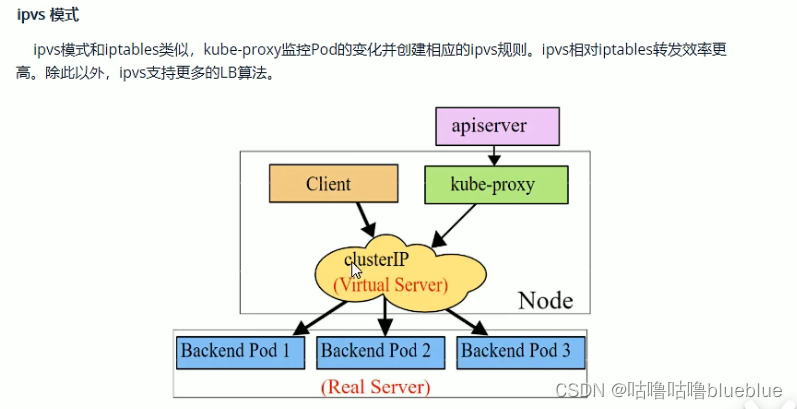
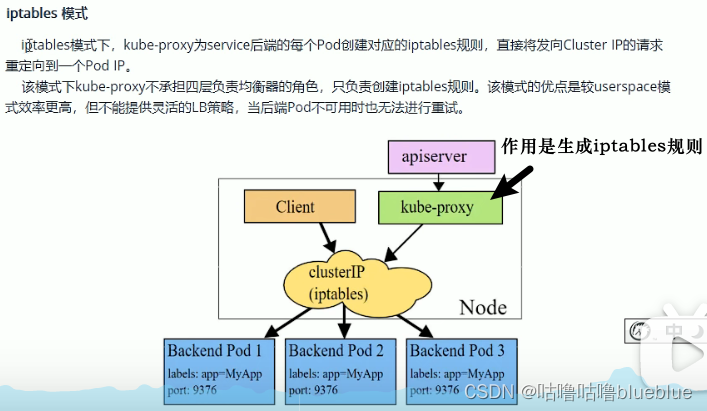
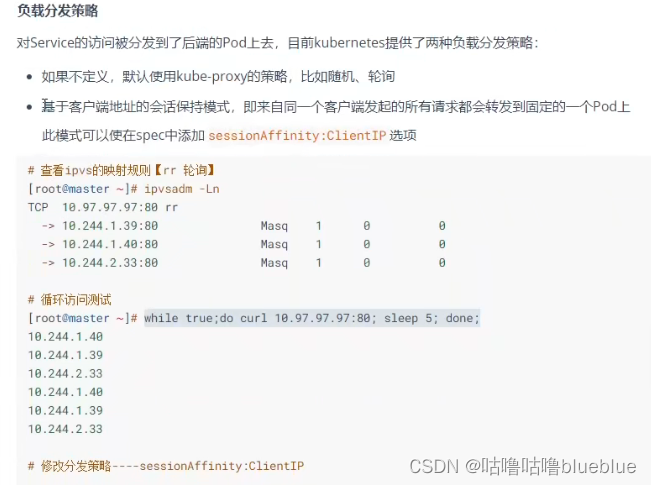
3、service是实现原理是什么 Service是由kube-proxy组件,加上iptables来共同实现的 kube-proxy通过iptable处理service的过程,需要在宿主机上设置相当多的iptables规则,如果宿主机有大量的Pod在不断的刷新iptables规则,会不断的消耗CPU资源。 IPVS模式的service,可以使k8s集群支持更多量级的pod。 开启kube-proxy的ipvs模式方法: * # yum -y install ipvasdm # 所有节点都安装 * # kubectl edit cm kube-proxy -n kube-system # 修改ipvs的模式为ipvs mode:“ipvs” * # kubectl get pod -n kube-system |grep kube-proxy |awk ‘{system(“kubectl delete pod “$1” -n kube-system”)}’ 更新kube-proxy的pod
尽管每一个pod都有自己的ip,但是没有service的话,他们就不能暴露在集群外部,service允许应用程序接收流量, 分类: ClusterIP--在集群内部ip上公开service,使得service只能从集群内访问 NodePort--使用NAT在集群中每个选定node的相同端口公开service,使用:从集群外部访问service LoadBalancer--在当前云中创建一个外部负载均衡器,并为service分配一个固定的外部ip ExternalName--通过返回带有该名称的cname记录,使用任意名称(spec中externmae指定)公开service,不使用代理







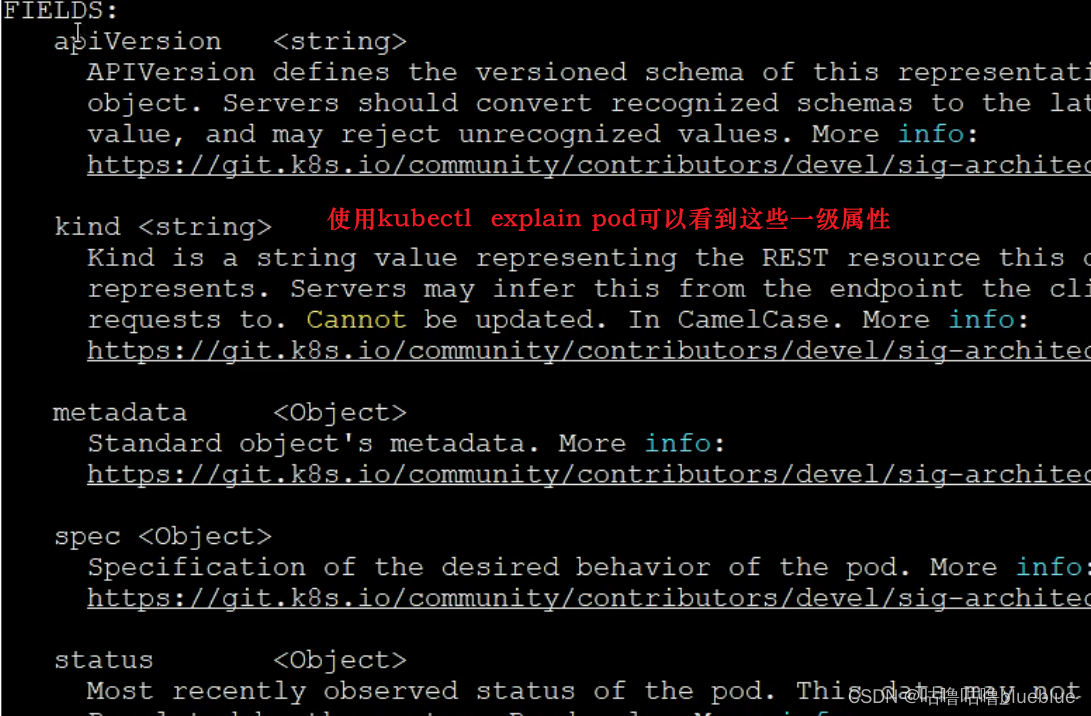
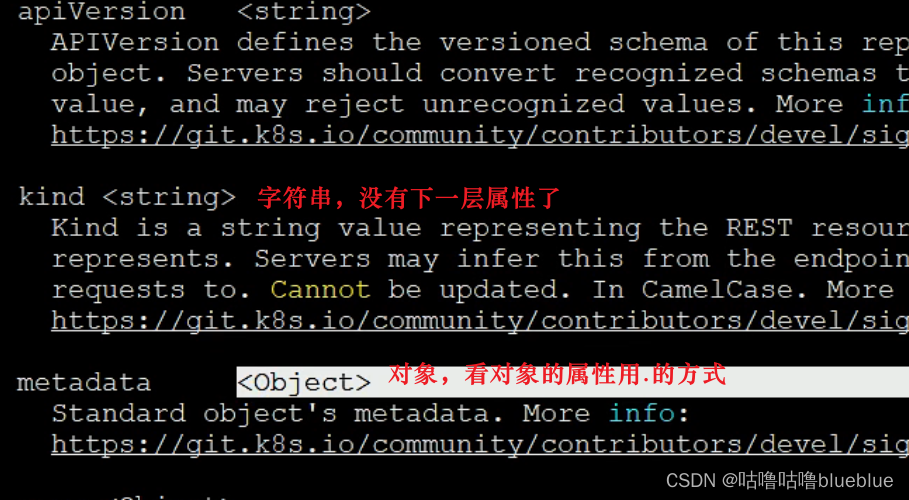
kubectl explain pod--可以查看一级属性
kubectl explain pod.metadata
三级属性
---------

镜像拉取策略: Always--总是从远程仓库拉取 IfNotPresent--本地有则使用本地镜像,本地没有就去远程仓库拉取 Never--只使用本地镜像, 默认值说明; 如果镜像的tag为具体的版本号,默认是IfNotPresent 如果镜像tag为latest,默认策略为always
command--在容器启动后执行命令进入容器内部 kubectl exec pod名 -n 命名空间 -it -c 容器名 /bin/sh环境变量(键值对组成):!!!!不推荐 ---- env: - name:'username' - value:'admin' 验证: 进入容器内部输出$username kubectl exec pod名字 -n 命名空间 -c 容器 -it /bin/sh 进入之后 echo $username如果是admin那就生效了
访问容器中的程序使用的是pod的ip和container的端口





资源限制
当一个容器使用的资源多时,可能导致其他容器无法正常启动运行
k8s提供了对内存和cpu的资源进行配额的机制,通过resources选项实现
resource有两个子选项: limits:用于限制运行时容器的最大占用资源,当容器占用资源超过limits时会被终止并重启 requests:用于设置容器需要的最小资源,当环境资源不够时,容器将无法启动

pod的生命周期
pod的5种状态 挂起(pending):apiserver已经创建了pod资源对象,但他没有被调度完成或仍处于下载镜像的过程 运行中(running):pod已经被调度到节点,并且所有容器都被kubelet创建完成 成功(succeeded):pod中所有容器都已经成功终止并且不会被重启 失败(faild):所有容器都已经终止,但是至少有一个容器终止失败,即容器返回非0值得退出状态 未知(unknow):apiserver无法正常获取到pod对象得状态信息,通常由网络通信失败所导致初始化容器:
提供主容器镜像中不具备的工具程序或自定义代码
初始化容器要先应用容器串行启动并运行完成,可用于延后应用容器的启动直至依赖解决
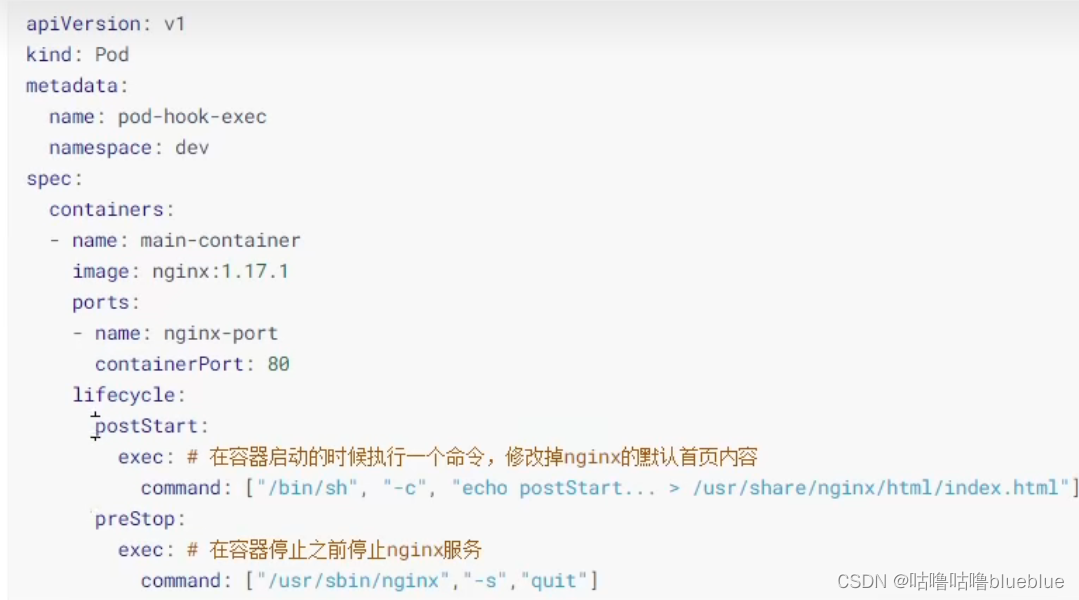
钩子函数
①容器启动后钩子(post start)、容器终止前钩子(pre stop)
post start上定义的行为会在容器启动后立即运行 运行成功则容器正常启动,反之容器启动失败 pre stop在容器被删除的时候调用 里面的代码执行成功,容器立马删除有三种方式定义动作 ①Exec命令:在容器内执行一次命令 ②tcpsocket:在当前容器尝试访问指定的socket ③HTTPGet:在当前容器中向某url发起http请求exec用的比较多
案列:
容器探测:用于检测容器中的应用实例是否正常工作,是保障业务可用性的一种传统机制,如果经过探测,实例的状态不符合预期,那么kubernetes就会将问题实例‘摘除’,不承担业务流量;
容器的存活性探测(liveness probe)、就绪性探测(readiness probe),启动性探针(startupProbe)
存活性探测(liveness probe):用于检测应用实例当前是否处于正常运行状态,如果不是,k8s会重启容器 就绪性探测(readiness probe):用于检测应用实例当前是否可以接收请求,如果不能,k8s不会转发流量 (容器可能已经启动了,但是在加载配置文件或者其他资源) livenessprode 决定是否重启容器,readinessprode决定是否将请求转发给容器 启动性探针:指示容器内的应用是否已经成功,如果提供了启动探针,则所有的其他探针都会被禁用,直至启动性探针成功为止,如果启动失败,kublet将杀死容器,而容器根据重启策略重启,
kubectl explain pod.spec.containers.livenessProbe--可以查看到livenesprobe的子属性
pod的重启策略(与containers同级)
- Always:容器失效时,自动重启该容器,默认值
- OnFailure:容器终止运行且退出码不为0时重启
- Nerver:不论怎样都不重启







pod的调度
- 自动调度:运行在那个节点上完全由scheduler经过一系列的算法得出
- 定向调度:NodeName,NodeSelector(根据标签)
- 亲和性调度:NodeAffinity、PodAffinity、PodAntiAffinity
- 污点(容忍)调度:Taints、Toleration
定向调度:
NodeName:强制将pod调度到指定name的node节点上,
NodeSelector:用于将pod调度到添加了指定标签的node节点上,通过k8s的kubernetes的label-selector实现;
给node打上标签 给node1打标签:kubectl label nodes node1 nodeenv=pro 给node2打标签:kubectl label nodes node2 nodeenv=test
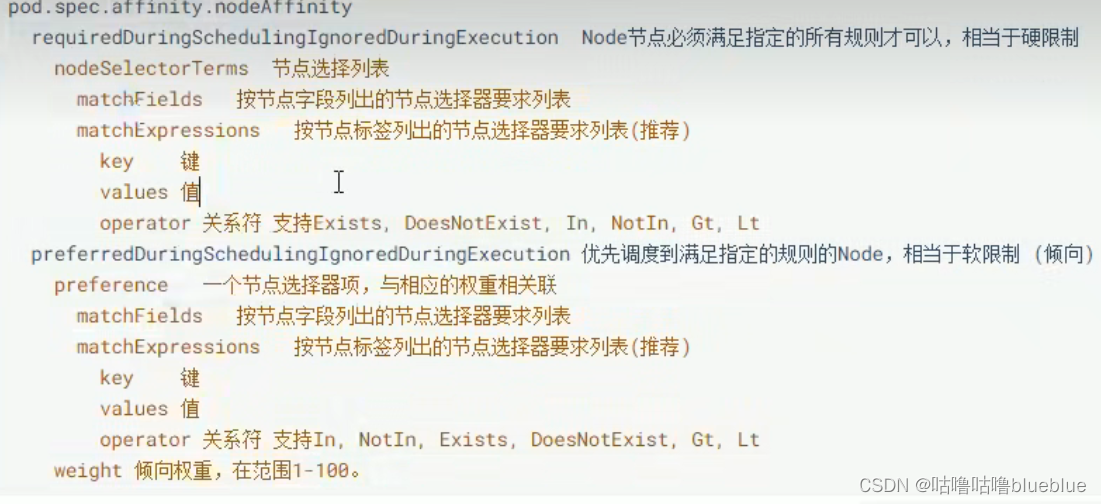
亲和性调度:
优先选择满足条件的node进行调度,如果没有,也可以调度到不满足条件的节点上,使得调度更加灵活
NodeAffinity
PodAffinity
PodAntiAffinity



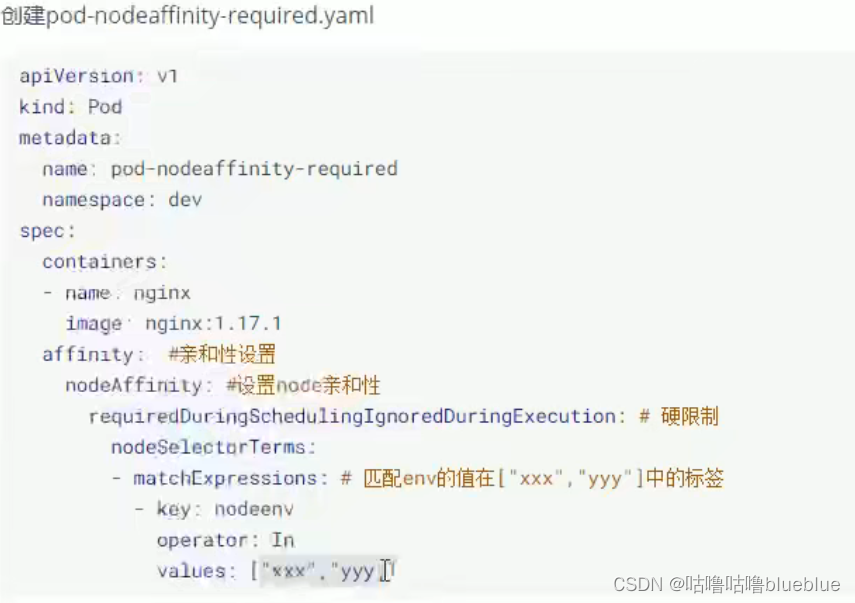


污点
在node节点上添加污点属性,决定是否允许pod调度过来,node被设置上污点之后就跟pod建立了一种相斥的关系,拒绝pod调度进来,甚至可以将已经存在的pod驱逐
污点的格式为: key=value:effect key和value是污点的标签,effect是描述污点的作用 PreferNoSchedule:kubernetes将尽量避免把pod调度到具有该污点的node上,除非没有其他节点可调度 NoSchedule:kubernetes将不会把pod调度到具有该污点的节点上,但不会影响当前node上已经存在的pod NoExecute:kubernetes将不会把pod调度到具有该污点的node上,同时也会将node上已经存在的pod驱离
#设置污点 kubectl taint nodes node1 key=value:effect #去除污点 kubectl taint nodes node1 key:effect- #去除所有污点 kubectl taint nodes node1 key- 添加污点: 为node1设置PreNoSchedule, kubectl taint nodes node1 tag=heima:PreferNoSchedule使用kubeadm搭建的集群,默认会给master节点添加一个污点标记,所以pod就不会调度到该master节点上; kubectl describe node master--可以看到有NoScheduler策略容忍
忽略污点,pod可以通过容忍忽略拒绝
容忍的详细配置项
Equal和Exists区别:
Equal必须是键值对,Exists是有这个key,不管value



pod控制器
- 自主式pod:kubernetes直接创建,删除之后就没有了
- 控制器pod :通过控制器创建的pod,删除后,控制器会帮助重启pod
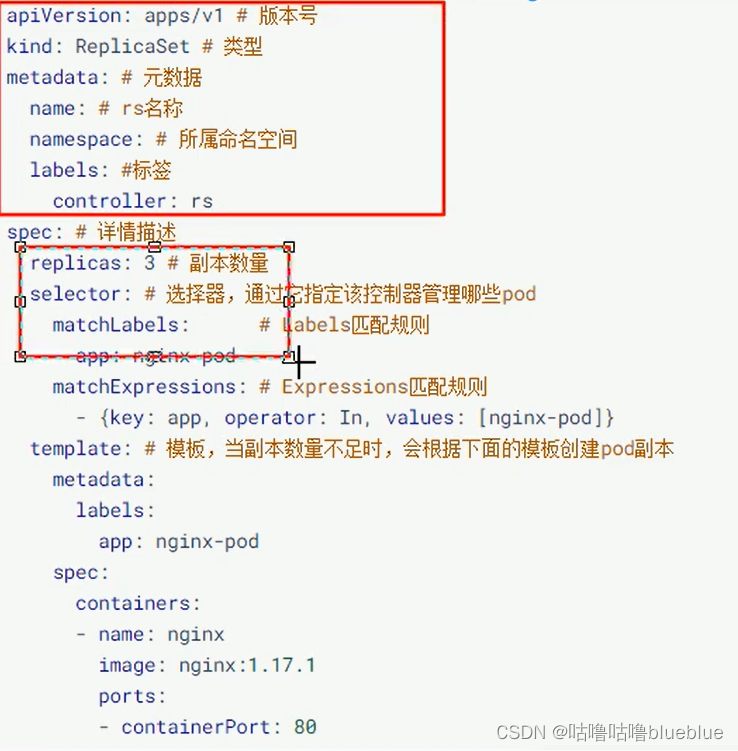
pod控制器就是管理pod的中间层,使用它之后,只需它自己想要的pod,他会创建出满足条件的pod,如果出现故障那么会重启或者重建创建控制器 replicaset:保证指定数量的pod运行,支持pod数量更新、镜像版本变更 deployment:通过控制replicaset来控制pod,支持滚动升级,版本回退 Daemonset:在集群的指定node上运行一个脚本,一般用于守护进程类的任务,适用于收集日志 Job:他创建出来的pod只有任务一完成就退出,用于执行一次性任务 Cronjob:执行周期性任务 StatefulSet:管理有状态应用 Horizontal Pod Autoscale:根据集群负载自动调整pod的数量,实现削峰填谷ReplicaSet:保证一定数量的pod能够正常运行,会持续监听这些pod的状态,一旦pod发生故障,就会重启或者重建,支持pod数量的扩容、缩容和版本镜像的升级;
查看rs kubectl get rs pc-replicaset -n dev -o wide #DESIRED:期望副本数量 #CURRENT:当前已有的副本数量 #READY:已经准备好提供服务的副本数量扩缩容----更改副本数量
方法1:
方法2:
使用kubectl scale命令,后面--replicas=n指定目标数量
kubectl scale rs pc-replicaset --replicas=2 -n dev镜像版本的升级
方法1:
使用命令kubectl edit kubectl edit rs pc-replicaset -n dev 修改里面的镜像版本信息方法2:使用命令
kubectl set image rs pc-replicaset nginx=nginx:1.17.1 -n dev删除replicaset
使用kubectl delete #在kubernetes删除rs之前,会将rs的replicasclear调整为0,等待所有的pod被删除之后,再执行RS对象的删除 kubectl delete rs rs-replicaset -n dev #如果希望仅删除rs对象而保留pod,则kubectl delete时添加--cascade=false选项

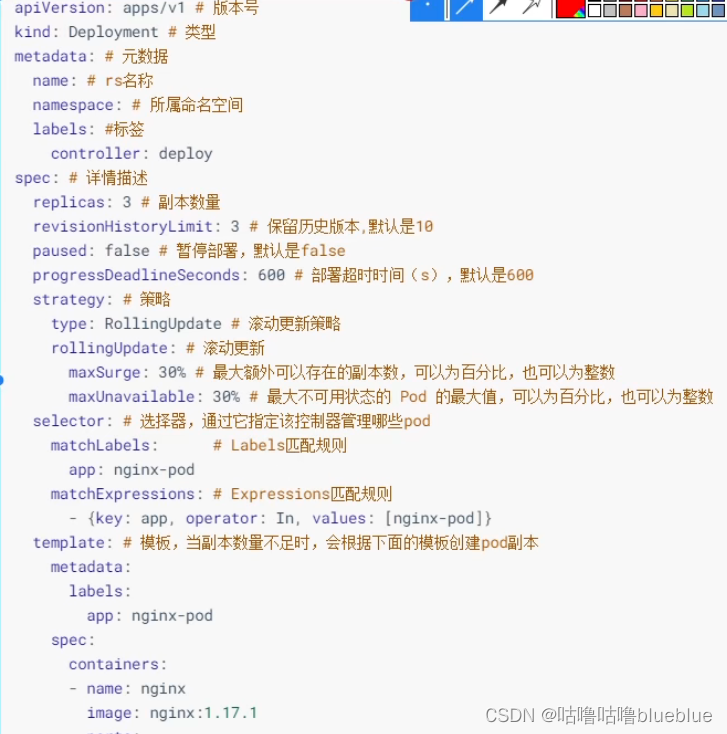
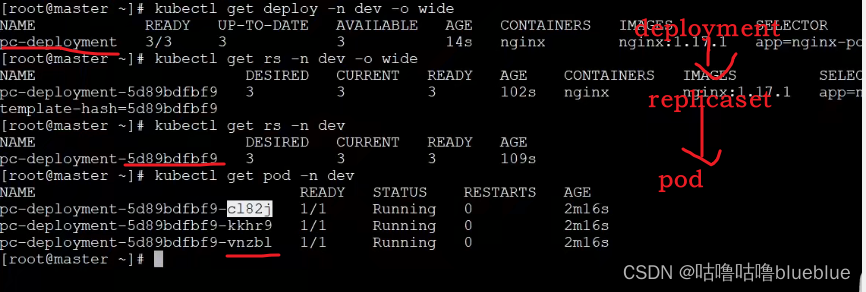
Deployment
解决服务编排问题,不是直接管理pod,而是通过管理Replicaset来间接管理pod
- 支持Replicaset的所有功能
- 支持发布的停止和继续
- 支持版本滚动变更和版本回退
扩缩容: 1,使用kubectl scale 命令 kubectl scale deploy pc-deployment --replicas=5 -n dev 2,编辑文件 kubectl edit deply pc-deplyment -n dev##deplyment的镜像更新策略(通过strategy选项来配置)
- 重建更新
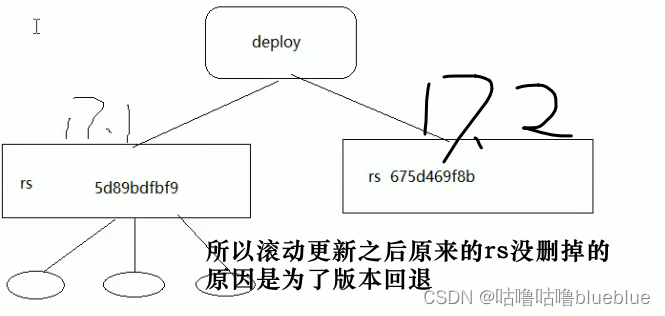
- 滚动更新(默认),
strategy:#指定新的pod替换新的pod的策略,支持两个属性 type:#指定策略类型,支持两种策略 Recreate:#在创建出新的pod之前会先杀掉所有已存在的pod RollingUpdate:#滚动更新,杀死一部分,再启动一部分,在更新过程中,存在两个版本pod rollingUpdate:#当type为RollingUpdate时生效,用于给RollingUpdate设置参数,支持两个属性 maxUnavailable:#用来指定在升级过程中不可用pod的最大数量,默认为25% maxSurge:#用来指定在升级过程中可以超过期望的pod的最大数量,默认为25%可以动态监控 kubectl get pods -n dev -w
##deployment版本回退
kubectl create -f pc-deployment.yaml --record --record可以记录下整个deployment的更新信息
kubectl rollout 选项 deploy 控制器名 -n 命名空间 rollout的子选项 status:显示当前升级状态 history:显示升级历史记录 pause:暂停版本升级过程 resume:继续已经暂停的版本升级过程 restart:重启版本升级过程 undo:回滚到上一级版本(可以使用--to-revision回滚到指定版本)
##金丝雀发布
有一批新的pod资源重建完成后立即暂停更新过程,一部分新版本的应用,主体部分还是旧版本,再筛选小部分用户请求路由到新版本pod,观察是否能按期望的那样运行,没问题之后才会将剩下的pod资源滚动更新,否则立即回滚更新操作;
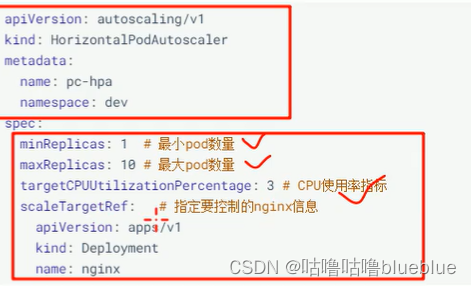
确保新的没问题之后继续更新 kubectl rollout resume deploy pc-deployment -n dev###HPA
HPA可以获取每个pod利用率,然后和HPA中定义的指标进行对比,同时计算出伸缩的具体值,最后实现pod数量的调整;
metrics-server---HPA的指标数据是通过metrics服务来获得,必须要提前安装好
##DaemonSet
保证集群中的每一个节点上都运行一个副本,一般适用于日志收集、节点监控等场景(适用于节点级别功能的pod)
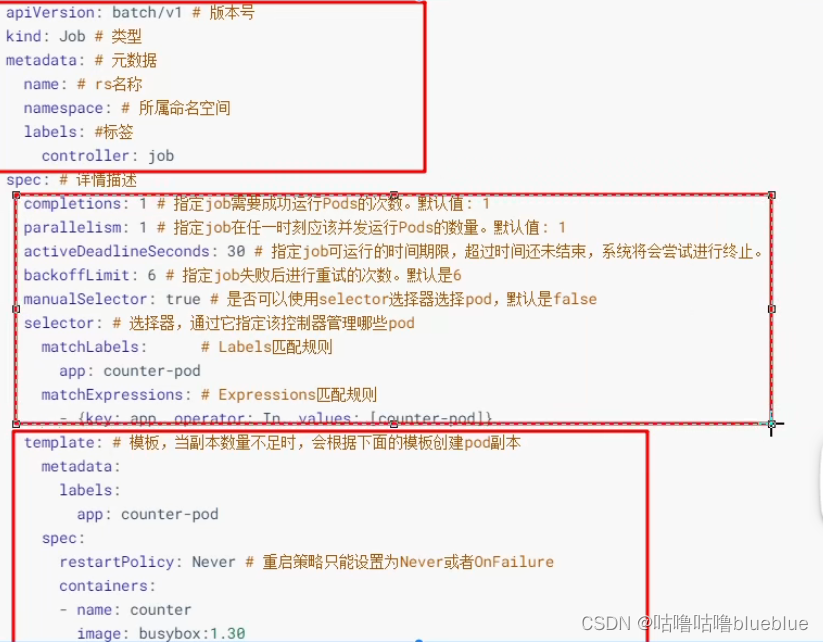
###Job
主要用于批量处理短暂的一次性任务
- 当job创建的pod执行成功结束时,Job将记录成功结束的pod的数量
- 当成功结束的pod达到指定的数量是,Job将完成执行
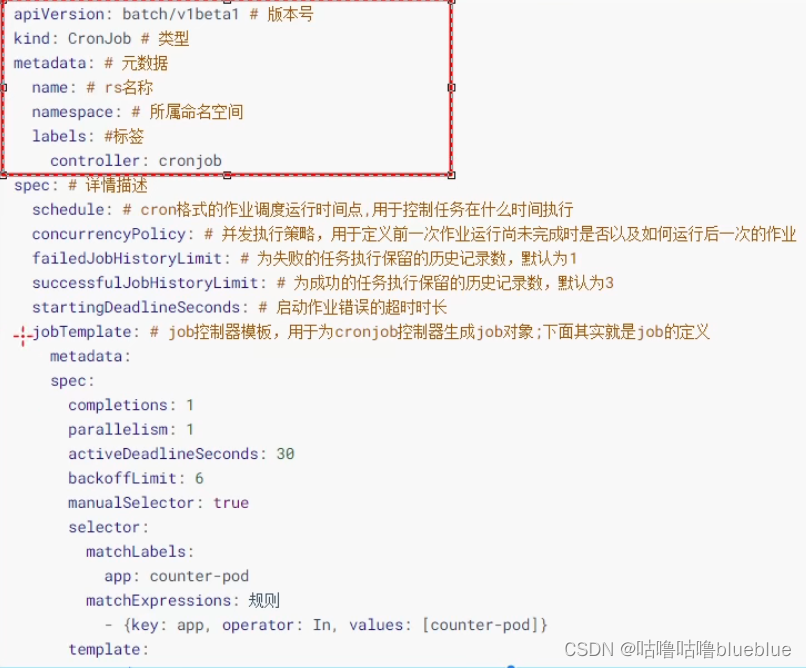
##CronJob
周期性任务,可以再特定时间反复的去运行job任务





service--四层路由的负载
service对提供同一个服务的多个pod进行聚合,并且提供一个统一的入口地址,通过访问service的入口地址就能访问到后面的pod服务
service在很多情况下只是一个概念,真正起作用的是kube-proxy服务进程,每个node节点上都会运行一个kube-proxy服务进程,当创建service的时候会通过api-server向etcd写入创建的service的信息,kube-proxy会监听service的变化,将最新的service信息转化为对应的访问规则(真正起作用的是kube-proxy)
kube-proxy支持的三种工作模式:
##service的资源清单
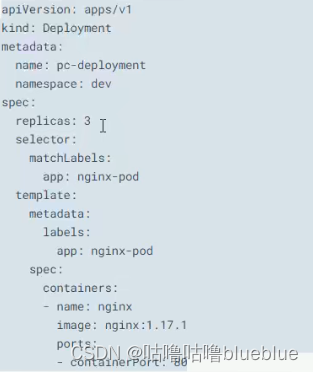
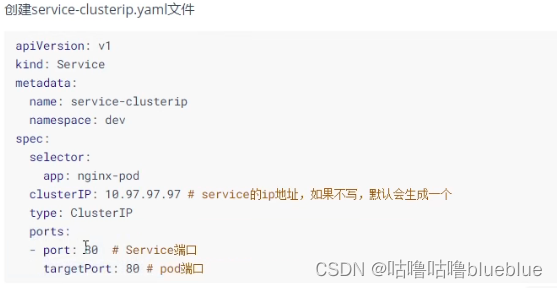
service类型 ClusterIP:默认值,是kubernetes系统自动分配的虚拟ip,只能在集群内部访问 NodePort:将service通过指定的node上的端口暴露给外部,通过这个方法就可以在集群外部访问服务,(nodeip:nodeport) LoadBalancer:使用外接负载均衡器完成到服务的负载分发,需要外部云环境支持 ExternalName:把集群外部的服务引入集群内部,直接使用先创建deployment,起三个nginx副本
创建ClusterIP类型的service
#Headliness类型的service
可以自己来控制负载均衡策略,不会分配clusterip只能通过service的域名进行查询
将clusterIP配置成None就行
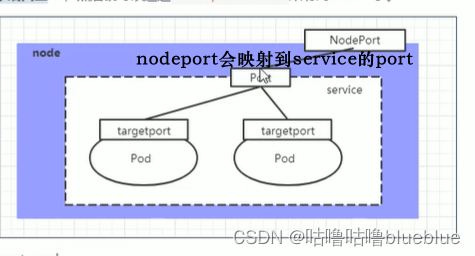
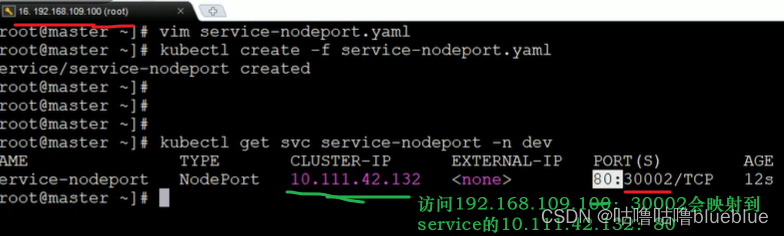
##NodePort类型的service
可以将service暴露给集群外部使用,原理是将service的端口映射到node节点上的一个端口,然后可以通过NodeIP:NodePort来访问service
#LoadBalancer类型的service
与nodeport类似,都是向外部暴露一个端口,区别在于LoadBalancer会在集群外部再来做一个负载均衡设备,外部服务发送到这个设备上的请求会被设备负载转发到集群中
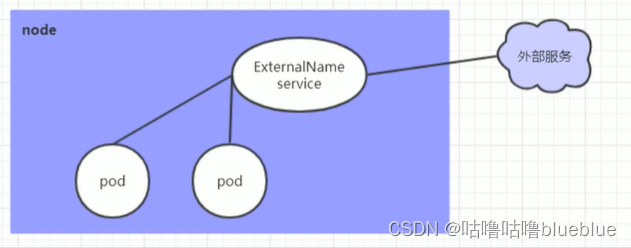
#ExternalName类型的service
用于引用集群外部的服务,通过externalname属性指定外部一个服务的地址,然后再集群内部访问这个service就可以访问到外部的服务







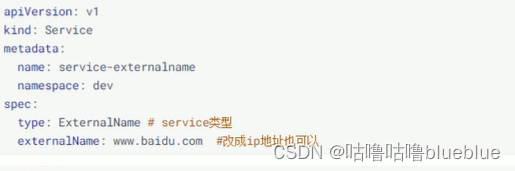
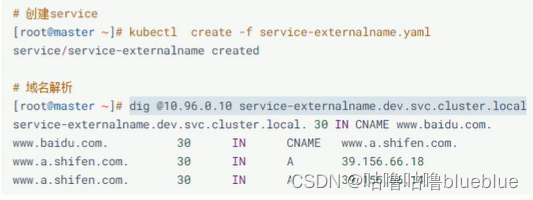
Ingress介绍
相当于一个七层的负载均衡器,只需要一个nodeport或者一个lb就可以满足暴露多个service的需求
Ingress 公开了从集群外部到集群内服务的 HTTP 和 HTTPS 路由。 流量路由由 Ingress 资源上定义的规则控制。7层负载均衡的工具
搭建ingress环境




数据存储
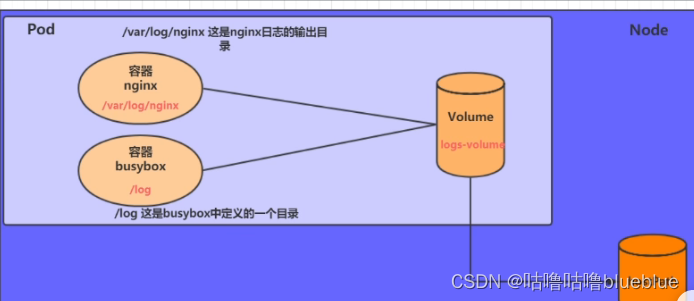
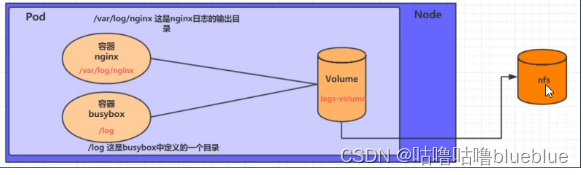
容器的生命周期可能会很短,会被频繁创建和销毁,在销毁后容器中的数据也会被清除,那么为了数据的持久化保存,就引入了卷的概念
volume是pod中能够被多个容器访问的共享目录,被定义在pod上,然后被一个pod里的容器挂载到具体的文件目录下,kubernetes通过volume实现同一个pod中不同容器之间的数据共享和数据持久化存储问题,volume的生命周期不与pod中单个容器的生命周期相关,当容器终止或者重启时,volume中的数据也不会丢失
kubernetes中的volume支持多种类型 简单存储:EmptyDir、HostPath、NFS 高级存储:PV、PVC 配置存储:ConfigMap、Secret##EmptyDir
是最基础的volume类型,一个EmptyDir就是host上的一个空目录
EmptyDir是在pod被分配到Node时创建的,初始内容为空,无需指定宿主机上对应的目录文件,因为kubernetes会自动分配一个目录,当pod销毁时,EmptyDir中的数据也会被永久删除,适用于临时空间:用于某些应用程序运行所需的临时目录,无需永久保存
和一个容器需要从另一个容器中获取数据的目录
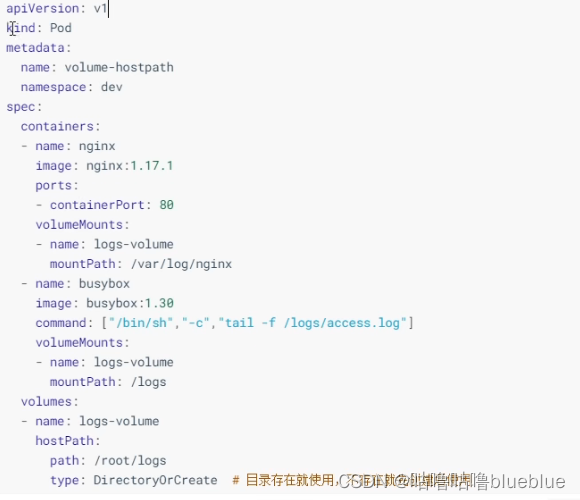
#HostPath
将node上一个实际目录挂到pod中,供容器使用,就可以保证pod销毁了之后数据依旧可以保存在node主机上
缺点:当所在的节点挂掉了,pod一般由控制器创建,node挂掉,pod也会挂掉,那么控制器会在别的节点上重新创建一个pod,那么HostPath读不到新的pod的数据
创建的时候看pod在那个节点上,那这个卷就在那个节点上type的值: DirectoryOrCreate:目录存在就使用,不存在则创建后使用 Directory:目录必须存在 FileOrCreate:文件存在则使用,不存在则创建后使用 File:文件必须存在 Socket:unix套接字必须存在 CharDevice:字符设备必须存在 BlockDevice:快设备必须存在##NFS
单独的网络存储系统 ,将pod中的存储直接连接到NFS系统上,无论pod在节点怎么转移,只要node跟NFS对接没有问题,数据就可以成功访问
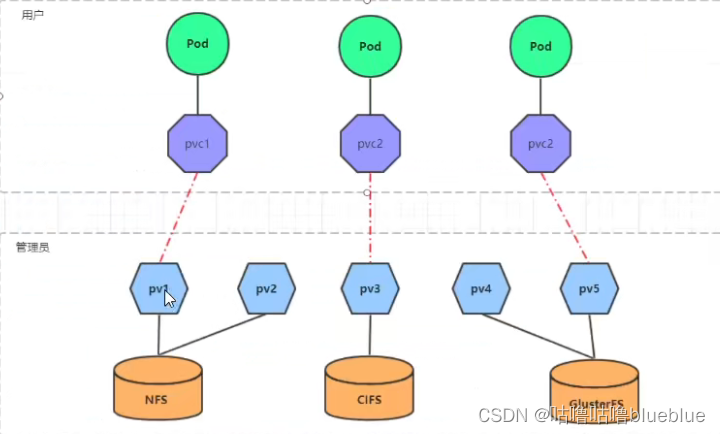
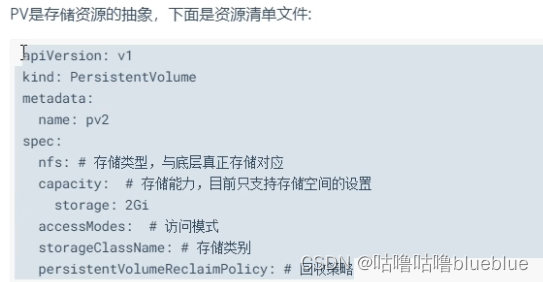
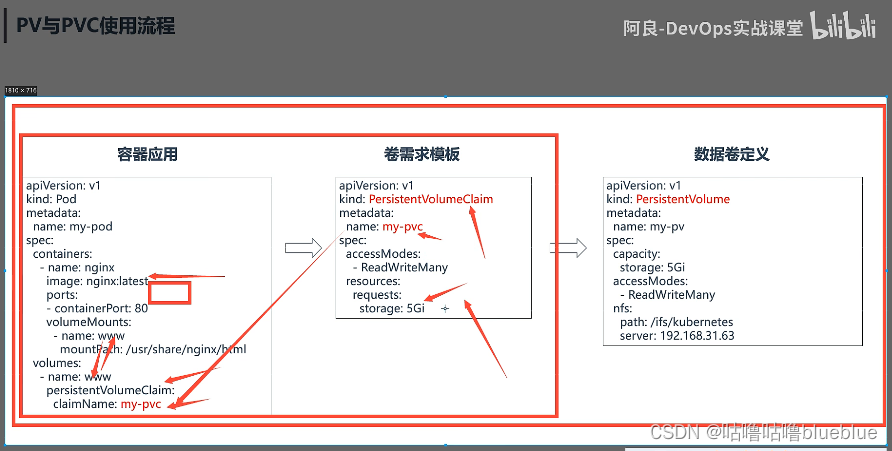
##pv
是持久化卷的意思,是对底层的共享存储的一种抽象,一般pv由kubernetes管理员进行配置和创建,与底层具体的共享存储技术有关,并通过插件完成与共享存储的对接
##pvc
持久卷声明的意思,是用户对存储需求的一种声明,pvc其实就是用户向kubernetes系统发出的一种资源申请
###ConfigMap
用来存储配置信息的
进入容器 kubectl exec -it pod-configmap -n dev /bin/sh 然后进入/configmap/config cd /configmap/config 查看info more info 可以看到映射成功,每个configmap都映射成了一个目录 key--》文件 value--》文件中的内容 此时如果更新configmap中的内容,容器中的值也会动态更新##secret
用于存储敏感信息,例如密钥,证书等(与configmap区别在于,configmap是明文保存。secret是密文保存)










安全认证
##认证管理
确认客户端的身份
HTTP Base认证:通过用户名+密码的方式认证; 将用户名:密码用BASE64算法进行编码后的字符串放在HTTP请求中的HEADER Authorization域里发送给服务端,服务端收到后进行解码,获取用户名和密码,然后进行身份认证 HTTP Token认证:通过一个token来识别合法用户; 一个token对应一个用户名,当客户端发起api调用请求时,需要在http header里放入token,api server接到token之后会跟服务器中保存的token进行对比,然后进行用户身份认证 HTTPS证书认证:基于CA根证书签名的双向数字证书认证方式
##授权管理
授权管理发生在认证成功之后,通过认证就能知道请求用户是谁,之后kubernetes根据事先定义的授权策略决定用户是否由权限访问;
每个发送到apiserver上的请求都带上了用户和资源的信息,比如发送请求的用户,请求的路径,请求的动物,授权就是根据这些信息和授权策略进行比较,如果符合则认为授权通过
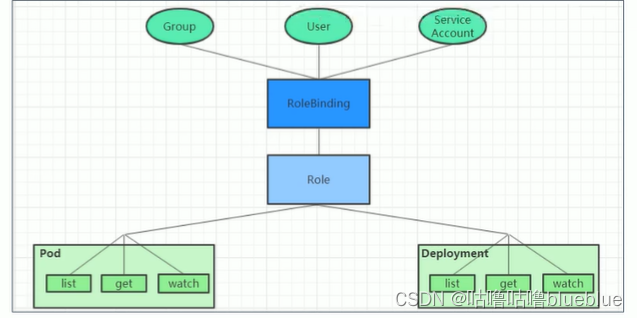
授权策略 AlwaysDeny:拒绝所有请求 AlwaysAllow:允许接收所有请求, ABAC:基于属性的访问控制,使用用户配置的授权规则对用户请求进行匹配和控制 Webhook:通过调用外部REST服务对用户进行授权 Node:是一种专用模式,用于对kubelet发出的请求进行访问控制 RBAC:基于角色的访问控制,就是给哪些对象授予哪些权限 有三个部分:对象:user,groups,serviceaccount 角色:代表一组定义在资源上的可操作动作的集合 绑定:将定义好的角色跟用户绑定在一起RBAC:
##准入控制:
通过认证和授权之后还要结果控制处理。apiserver才会处理这个请求




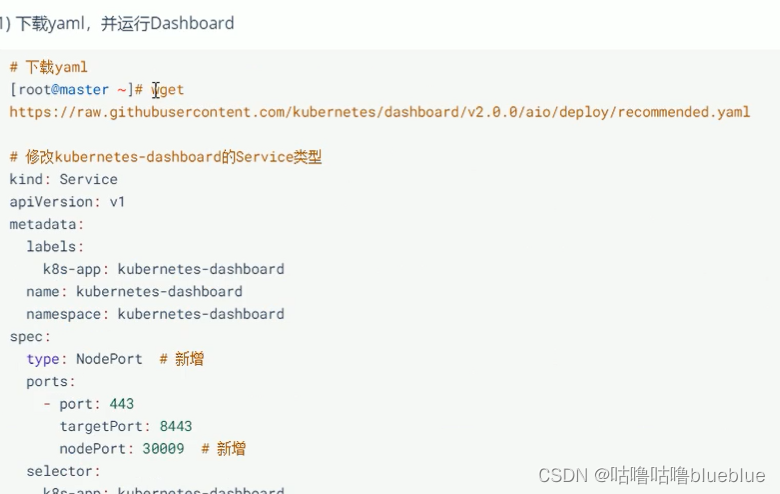
DashBoard
基于web的用户界面,用户可以使用dashboard部署容器化的应用也可以监控应用的状态,执行故障排查以及管理kubernetes中各种资源
!使用kubeadm安装的kubernetes默认是没有安装dashboard的















 8630
8630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









