









一、简单的SQL示例
--在电脑的命令提示行写入以下的代码!!
mysql -u root -p
密码为123456
--注意: 语句以 ; 或 \g 为结束符号!!

mysql -h localhost -P 3306 -u root -p123456
 ```mysql
```mysql
–查看数据库的版本
select version();
–查看当前的MySQL服务器中有哪些数据库
show databases;
```mysql
--使用koki数据库
use koki;
--创建表格
create table t_stu(
sid int,
sname varchar(100),
gender char
);
--查看表结构
desc t_stu;
--插入记录
INSERT INTO t_stu VALUES(1,'张三','男');
INSERT INTO t_stu VALUES(2,'李四','男');
INSERT INTO t_stu VALUES(3,'王五','男');
--查看记录
SELECT * FROM t_stu;
--修改记录
update t_stu set sname ="张三" where sid =1;
--删除记录
DELETE FROM t_stu WHERE sid = 1;
--查看表中剩余的记录
SELECT * FROM t_stu;
二、错误ERROR :没有选择数据库就操作表格和数据
| 若出现ERROR 1046 (3D000): No database selected |
|---|
| 解决方案一:就是使用“USE 数据库名;”语句,这样接下来的语句就默认针对这个数据库进行操作 |
| 解决方案二:就是所有的表对象前面都加上“数据库.” |
三、命令行客户端的字符集问题
mysql> INSERT INTO t_stu VALUES(1,'张三','男');
ERROR 1366 (HY000): Incorrect string value: '\xD5\xC5\xC8\xFD' for column 'sname' at row 1
--原因:服务器端认为你的客户端的字符集是utf-8,而实际上你的客户端的字符集是GBK
--查看所有字符集
show variables like 'character_set%';
解决方案,设置当前连接的客户端字符集“SET NAMES GBK;”
--设置当前连接的客户端字符集
set names gbk;
--查看所有字符集
show variables like 'character_set%';
注意:关于SQL的关键字和函数名等不区分大小写,但是对于数据值是否区分大小写,和字符集与校对规则有关。
_ci(大小写不敏感),_cs(大小写敏感),_bin(二元,即比较是基于字符编码的值而与language无关)
四、把服务器和系统的utf8字符编码改成gbk编码
--在命令行通过以下方式获取MySQL Server服务版本的信息
C:\Users\Administrator>mysql -V
C:\Users\Administrator>mysql --version
--登录后,通过以下方式查看当前版本信息:
mysql> select version();
--查看当前mysql数据库管理软件支持的存储引擎:
SHOW ENGINES;
--查看默认存储引擎和当前选择的存储引擎:
SHOW VARIABLES LIKE '%storage_engine%';
--查看所有字符集:
SHOW VARIABLES LIKE 'character_set_%';
--设置当前连接的客户端字符集:
SET NAMES GBK;
--查看所有字符集和校对规则
show character set;
--查看GBK和UTF-8字符集的校对规则
show collation like 'gbk%'; --collation为校对的意思
show collation like 'utf8%';
/*注意
:utf8_unicode_ci和utf8_general_ci对中、英文来说没有实质的差别。
utf8_general_ci 校对速度快,但准确度稍差。
utf8_unicode_ci 准确度高,但校对速度稍慢。
如果你的应用有德语、法语或者俄语,请一定使用utf8_unicode_ci。一般用utf8_general_ci就够了。*/
--查看服务器的字符集和校对规则
show variables like '%_server';
--查看和修改某个数据库的字符集和校对规则
--法一:
use 数据库名;
show variables like '%_database';
--法二:
show create database koki;
--修改数据库的字符集和校对规则:
alter database 数据库名称 default character set 字符集名称 【collate 校对规则名称】;
--例如:
alter database ceshi_db default character set utf8 collate utf8_general_ci;
--修改数据中的服务器的字符编码变成gbkutf8
alter database koki default character set utf8 collate utf8_general_ci;
/*注意:修改了数据库的默认字符集和校对规则后,原来已经创建的表格的字符集和校对规则并不会改变,如果需要,那么需要单独修改。*/
--查看字符集:
show create table 数据库中的表名;
--如果要查看校对规则:
show table status from koki like '%数据库中的表名%';
--修改某个表格的字符集和校对规则:
--修改表的默认字符集:
alter table 表名称 default character set 字符集名称 【collate 校对规则名称】;
--例如:
alter table users default character set gbk collate gbk_chinese_ci; --gbk为中国的标准字符编码
--把表默认的字符集和所有字符列(char,varchar,text)改为新的字符集:
alter table 表名称 convert to character set 字符集名称 【collate 校对规则名称】;
--例如:
alter table users convert to character set utf8 collate utf8_general_ci;--utf8为国际的标准字符编码
四、浮点型
对于浮点列类型,在MySQL中单精度值使用4个字节,双精度值使用8个字节
--float和double在不指定精度时,默认会按照实际的精度(由实际的硬件和操作系统决定)来显示
REAL就是DOUBLE ,如果SQL服务器模式包括REAL_AS_FLOAT选项,REAL是FLOAT的同义词而不是DOUBLE的同义词。
注意:在编程中,如果用到浮点数,要特别注意误差问题,因为浮点数是不准确的,所以我们要避免使用“=”来判断两个数是否相等。如果希望保证值比较准确,推荐使用定点数数据类型。
五、日期时间类型
数字值应为6、8、12或者14位长。如果一个数值是8或14位长,则假定为YYYYMMDD或YYYYMMDDHHMMSS格式,前4位数表示年。如果数字 是6或12位长,则假定为YYMMDD或YYMMDDHHMMSS格式,前2位数表示年。其它数字被解释为仿佛用零填充到了最近的长度。
一般存注册时间、商品发布时间等,不建议使用datetime存储,而是使用时间戳,因为datetime虽然直观,但不便于计算。而且timestamp还有一个重要特点,就是和时区有关。还有如果插入NULL,会自动设置为当前系统时间。
char,varchar,text区别
--char是一种固定长度的类型,varchar则是一种可变长度的类型,它们的区别是:
--char如果不指定(M)则表示长度默认是1个字符。varchar必须指定(M)。
--char(M)类型的数据列里,每个值都占用M个字符,如果某个长度小于M,MySQL就会在它的右边用空格字符补足(在检索操作中那些填补出来的空格字符将被去掉;如果存入时右边本身就带空格,检索时也会被去掉);在varchar(M)类型的数据列里,每个值只占用刚好够用的字符再加上一个到两个用来记录其长度的字节(即总长度为L字符+1/2字字节)。
--由于某种原因char 固定长度,所以在处理速度上要比varchar快速很多,但相对费存储空间,所以对存储不大,但在速度上有要求的可以使用char类型,反之可以用varchar类型来实例。
--text文本类型,可以存比较大的文本段,搜索速度稍慢,因此如果不是特别大的内容,建议使用char,varchar来代替。还有text类型不用加默认值,加了也没用。而且text和blob类型的数据删除后容易导致“空洞”,使得文件碎片比较多,所以频繁使用的表不建议包含text类型字段,建议单独分出去,单独用一个表。
哪些情况使用char或varchar更好
--一,存储很短的信息,比如门牌号码101,201……这样很短的信息应该用char,因为varchar还要占个byte用于存储信息长度,本来打算节约存储的现在得不偿失。
--二,固定长度的。比如使用uuid作为主键,那用char应该更合适。因为他固定长度,varchar动态根据长度的特性就消失了,而且还要占个长度信息。
--三,十分频繁改变的column。因为varchar每次存储都要有额外的计算,得到长度等工作,如果一个非常频繁改变的,那就要有很多的精力用于计算,而这些对于char来说是不需要的。
--MyISAM和MEMORY存储引擎中无论使用char还是varchar其实都是作为char类型处理的。
--其他像InnoDB存储引擎,建议使用varchar类型,因为对于InnoDB数据表,内部的行存储格式并没有区分固定长度和可变长度列(所有数据行都使用指向数据列值的头指针),而且主要影响性能的因素是数据行使用的存储总量,由于char平均占用的空间多于varchar,所以除了简短并且固定长度的,其他考虑varchar。
六、集合(SET)
SET和ENUM最主要的区别在于SET类型一次可以选择多个成员,而ENUM则只能选择一个。
七、特殊的****NULL值
--Null特征:
(1)所有的类型的值都可以是null,包括int、float等数据类型
(2)空字符串””,不等于null,0也不等于null,false也不等于null
(3)任何运算符,判断符碰到NULL,都得NULL
(4)NULL的判断只能用is null,is not null
(5)NULL 影响查询速度,一般避免使值为NULL
SQL
SQL:Structure Query Language结构化查询语言
SQL的语言规范
--mysql对于SQL语句不区分大小写,SQL语句关键字尽量大写
--值,除了数值型,字符串型和日期时间类型使用单引号(’’)
--别名,尽量使用双引号(“”),而且不建议省略as
--所有标点符号使用英文状态下的半角输入方式
--必须保证所有(),单引号,双引号是成对结束的
--可以使用(1)#单行注释 (2)--空格单行注释 (3)/* 多行注释 */
命名规则:
--数据库、表名不得超过30个字符,变量名限制为29个
--必须只能包含 A–Z, a–z, 0–9, _共63个字符
--不能在对象名的字符间留空格
--必须不能和用户定义的其他对象重名
--必须保证你的字段没有和保留字、数据库系统或常用方法冲突
--保持字段名和类型的一致性,在命名字段并为其指定数据类型的时候一定要保证一致性。假如数据类型在一个表里是整数,那在另一个表里可就别变成字符型了
--在命令行中的要求:
--说明:一个语句可以分开多行编写,以;或\g结束
SQL分类
SQL的分类:
DDL(Data Definition Languages):数据定义语言,这些语句定义了不同的数据段、数据库、表、列、索引等数据库对象。
主要的语句关键字包括create、drop、alter等。
DML(Data Manipulation Language):数据操作语句,用于添加、删除、更新和查询数据库记录,并检查数据完整性。
主要的语句关键字包括insert、delete、update、select等。
DCL(Data Control Language):数据控制语句,用于控制不同数据段直接的许可和访问级别的语句。 ```
## 解决数据库乱码问题
!修改字符编码](https://img-blog.csdnimg.cn/20210704200532739.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0xhbnlLZXkxMQ==,size_16,color_FFFFFF,t_70)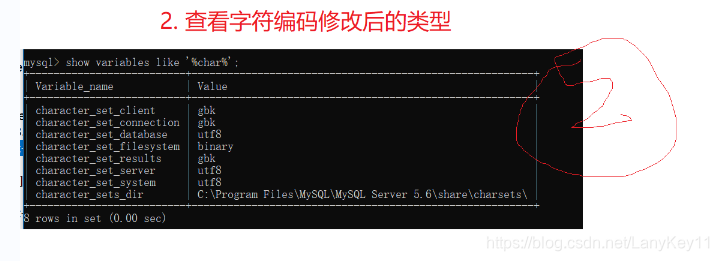















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









