 归并分治解决逆序对
归并分治解决逆序对





摘要
本篇章利用分治思想,把大问题划分多个相似或相同的小问题,通过解决小问题从而达到解决大问题的目的,利用归并解决,上一篇是利用快速排序来解决,对于归并和快速排序不清楚的可以去看我的数据结构精讲中的排序章节,这里简要说明一下归并和快排的区别
他们都是利用了分治的思想,但是快排是在分治的过程当中边分边解决问题,一般来说对于算法题目分治后只需要递归处理 “包含目标元素” 的一侧子数组,另一侧直接舍弃。对于排序分的过程就是解决排序问题的过程,最后自然得到有序数组。
对于归并,是先分后解决,分治后需要递归处理两侧子数组,再通过 “合并” 操作将两侧有序子数组合成完整有序数组。分是铺垫,真正的排序工作在 “合并” 阶段集中完成。
快速选择像 “找快递”:按区域划分后,只去目标快递所在的区域查找,其他区域直接忽略,效率更高但只关注单个目标。
归并排序像 “整理书架”:先分区域整理小堆书籍,再把所有整理好的小堆合并成完整的有序书架,需要处理全部内容。
例题讲解
leetcode912.排序数组
本题主要是复习归并排序算法

代码
class Solution {
public:
vector<int> tmp;
vector<int> sortArray(vector<int>& nums) {
int n=nums.size();
tmp.resize(n);
mergerSort(nums,0,n-1);
return nums;
}
void mergerSort(vector<int>&nums,int left,int right){
if(left>=right) return;
//1.选择中间数
int mid=(right+left)>>1; //这里右移表示/2
//2.递归左右区间
mergerSort(nums,left,mid);
mergerSort(nums,mid+1,right);
//3.合并排序
int cur1=left,cur2=mid+1;
int i=0;
while(cur1<=mid&&cur2<=right){
tmp[i++]=nums[cur1]<=nums[cur2]?nums[cur1++]:nums[cur2++];//前置++
}
while(cur1<=mid) tmp[i++]=nums[cur1++];
while(cur2<=right) tmp[i++]=nums[cur2++];
//放回原数组
for(i=left;i<=right;i++){
nums[i]=tmp[i-left];
}
}
};
注意:
我们选择left+right直接/2是因为left+right题目给的数据不会超出范围,如果超过范围我们还需要防止,使用left+(right-left)/2这种在二分那里为了避免越界的做法
此处我们是选择一个全局的变量来存储我们归并过程中的数组,然后再拷贝,我们也可以使用每次递归进去创建的数组,也就是栈数组,随着递归才创建,此时时间复杂度会变高,创建也是耗时的,所以为了减少时间复杂度我们创建了一个全局的数组,这样就不需要再每次递归的时候才创建
leetcode170.交易逆序对的总数

题目解析
前一个数大于后一个数就需要统计,如果是=就不需要,依次统计出有多少对,然后返回即可
算法原理讲解
暴力算法:枚举每一对,然后检查是否是前一个大于后一个即可,时间复杂度O(n^2)
分治-归并:归并时会自动划分左右区间,这样就天然的给我们准备了一个前和后的关系,只需要比较前面的是否大于后面的即可,所以合并过程当中我们需要排降序(这里排升序也行,看你怎么计算怎么比较怎么统计)
如果前一个大于后一个,那说明都大于右边区间的所有数,此时统计一下即可
如果前一个小于等于后一个,说明没有前面的都不会大于后面的这一个,此时不需要统计
为什么这样可以,因为使用归并的时候你就已经划分了数组,分为前后/左右了,所以你递归下去排序某一边根本不影响另一边,也就是你的相对顺序是对的,你只是改变了左区间里面的顺序,不影响和右区间的相对顺序,还是一前一后
代码
class Solution {
public:
int count = 0;
vector<int> tmp;
int reversePairs(vector<int>& record) {
// 使用归并排降序,然后比较
int n = record.size();
tmp.resize(n); // 防止后续访问的时候野指针
mergerSort(record, 0, n - 1);
return count;
}
void mergerSort(vector<int>& nums, int left, int right) {
// 递归出口
if (left >= right)
return;
// 选择中间数
int mid = (left + right) >> 1;
// 递归左右区间
mergerSort(nums, left, mid);
mergerSort(nums, mid + 1, right);
// 合并过程排降序,注意count的结果
int cur1 = left, cur2 = mid + 1, i = 0;
while (cur1 <= mid && cur2 <= right) {
if (nums[cur1] <= nums[cur2]) {
// 左边最大的小于右边最大的,不处理count
tmp[i++] = nums[cur2++];
} else {
// 左边最大的大于右边最大的
count += right - cur2 + 1;
tmp[i++] = nums[cur1++];
}
}
// 如果某一边全部放完了count不需要处理,只需要放到tmp
while (cur1 <= mid)
tmp[i++] = nums[cur1++];
while (cur2 <= right)
tmp[i++] = nums[cur2++];
// 拷贝
for (i = left; i <= right; i++) {
nums[i] = tmp[i - left];
}
}
};
leetcode315.计算右侧小于当前元素的个数

此题和170一样的,统计的结果放到数组当中返回即可,代码上稍加修改一下即可
注意:
难点就在于:我们在排序的过程当中会改变原始数组,所以一开始我们要存元素:原始下标的对应关系,否则你在递归合并的过程当中会改变原数组导致下标变换,进而导致统计的对数会乱加到不同的位置上,至于你最后返回的数组会出错
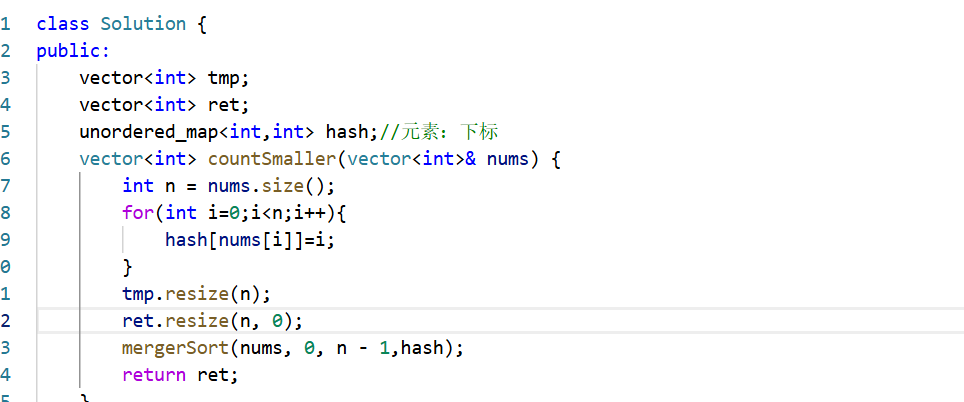
如果这里是弄一个hash的话就会出错,因为有相同元素,相同元素遍历到后面会覆盖前面的相同元素的下标,就导致了所有的相同元素共用一个下标,导致全部加在一起
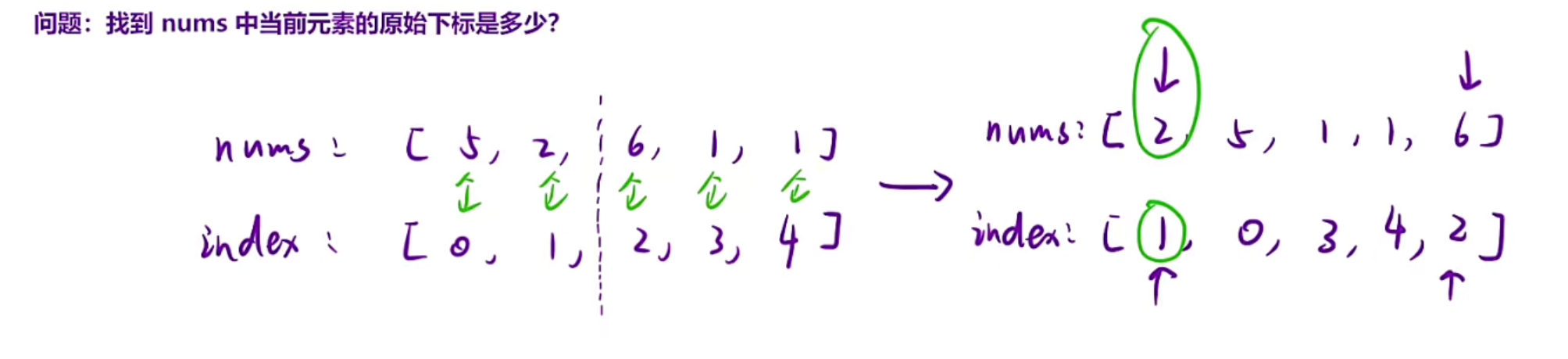
我们要额外开辟一个数组,然后如果nums数组的元素进行了排序,index数组也要跟着移动,也就是绑定移动,要移动就同时移动
我们还需要额外开辟一个数组也就是tmp2,tmp2的作用就是辅助index数组的变换
tmp1的作用是辅助nums的变换
最后两个都需要进行拷贝变换
简单来说就是你的nums变换的时候,index也要跟着变换,下标就是正确的了,ret数组一直存结果cur1和cur2指向哪,nums的元素对,index的下标也对
代码
class Solution {
public:
vector<int> tmp1; // 辅助ret
vector<int> tmp2; // 辅助index变换更新
vector<int> ret; // 存结果
vector<int> index; // 存下标
vector<int> countSmaller(vector<int>& nums) {
int n = nums.size();
index.resize(n);
tmp1.resize(n);
ret.resize(n, 0);
tmp2.resize(n);
for (int i = 0; i < n; i++) {
index[i] = i;
}
mergerSort(nums, 0, n - 1);
return ret;
}
void mergerSort(vector<int>& nums, int left, int right) {
// 递归出口
if (left >= right)
return;
// 选择中间数
int mid = (left + right) >> 1;
// 递归左右区间
mergerSort(nums, left, mid);
mergerSort(nums, mid + 1, right);
// 合并过程排降序,注意count的结果
int cur1 = left, cur2 = mid + 1, i = 0;
while (cur1 <= mid && cur2 <= right) {
if (nums[cur1] <= nums[cur2]) {
// 左边最大的小于右边最大的,不处理count
tmp2[i] = index[cur2];
tmp1[i++] = nums[cur2++];
} else {
// 左边最大的大于右边最大的
tmp2[i] = index[cur1];
int count = right - cur2 + 1; // 统计当前次数
ret[index[cur1]] += count;
tmp1[i++] = nums[cur1++];
}
}
// 如果某一边全部放完了count不需要处理,只需要放到tmp
while (cur1 <= mid) {
tmp2[i]=index[cur1];
tmp1[i++] = nums[cur1++];
}
while (cur2 <= right) {
tmp2[i]=index[cur2];
tmp1[i++] = nums[cur2++];
}
// 拷贝
for (i = left; i <= right; i++) {
index[i]=tmp2[i-left];
nums[i] = tmp1[i - left];
}
}
};
leetcode493.翻转对

算法原理讲解
有人见到这道题可能就会想要用之前的解法一模一样的套进去,但是发现出错,这道题的解法原理和之前一样,但是有些细节要处理
因为之前是单单不叫前面一个数大于后面一个数就叫逆序对,然后同时进行排序
但是这里不是,这里是大于两倍,你不能同时排序
假设统计翻转对的同时进行排序
比如132这个数组,递归到下面时就是【1,3】【2】
左边【3,1】右边【2】
因为3<=2*2,所以不满足
tmp【2】,然后循环结束因为cur2到尾巴了
所以把cur1接到tmp后面就会变成
tmp【2,3,1】,此时数组不是一个有序的情况,就会导致后面如果还有变的元素就会出错
因为你所有的基础都来源于左边区间有序,右边区间有序才能统计
所以解决方案就是,我们先统计完翻转对之后,再排序
就是你先全部统计完,然后再使用cur1>cur2这样来排序,因为两倍会把排序搞乱
注意
一定要清楚因为比较条件改变了,原来合并数组的时候比较条件就是前一个数的一倍和后一个数的一倍进行比较,排序是这样比,逆序对也是这样比,可以边排序边找逆序对
但是这里翻转对不行,排序是一倍比一倍,但是翻转对是一倍比两倍
一定要注意这是一个坑,也是这道题的本质
class Solution {
public:
int count = 0;
vector<int> tmp;
int reversePairs(vector<int>& nums) {
int n = nums.size();
tmp.resize(n);
mergerSort(nums, 0, n - 1);
return count;
}
void mergerSort(vector<int>& nums, int left, int right) {
// 递归出口
if (left >= right)
return;
// 选择中间数
int mid = (left + right) >> 1;
// 递归左右区间
mergerSort(nums, left, mid);
mergerSort(nums, mid + 1, right);
// 合并过程统计,注意count的结果
int cur1 = left, cur2 = mid + 1;
while (cur1 <= mid && cur2 <= right) {
if ((long long)nums[cur1] > 2 * (long long)nums[cur2]) {
// 统计翻转对
count += right - cur2 + 1;
cur1++;
}
else cur2++;
}
//统计完之后再进行排序
cur1 = left, cur2 = mid + 1;
int i=0;
while(cur1<=mid&&cur2<=right){
if(nums[cur1]>=nums[cur2]){
tmp[i++]=nums[cur1++];
}
else{
tmp[i++]=nums[cur2++];
}
}
while(cur1<=mid) tmp[i++]=nums[cur1++];
while(cur2<=right) tmp[i++]=nums[cur2++];
// 拷贝
for (i = left; i <= right; i++) {
nums[i] = tmp[i - left];
}
}
};
注意:处理当中可能会*2可能会溢出,所以使用long long来比较
升序和降序本质都是一样的,只是比较统计的时候角度不一样而已,可以自行写一下
总结
如果题目符合以下任一逻辑,可优先考虑快排 / 归并的分治思路:
- 逻辑 1:问题可拆分为 “子问题独立解决,再合并结果”(归并的核心)。
- 逻辑 2:问题可通过 “分区操作,只处理部分子问题” 来缩小规模(快排递归某一区间)。
举个例子:
- 若题目是 “统计数组中所有 i<j 且 nums [i]>nums [j] 的对数”→ 归并的分治(合并时统计逆序对)。
- 若题目是 “找到数组中第 3 大的元素”→ 快速选择的分治(分区后只处理包含目标的区间)。

















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









